ASAC 07기 : 24.12.12 웹 개발 개념 및 동작 방법 - 백엔드 편
ASAC

백엔드 웹 개발 : 클라이언트가 필요로하는 데이터를 반환하는 API
백엔드 개발자가 API 개발 시 고려해야할 것들
클라이언트가 원하는 다양한 데이터를 1. 어떻게 2. 잘 반환할까?
- 어떻게 = 방법론 (요청-응답을 처리하는 방법) : REST API, GraphQL, Queue, WebSocket, SSE 등
- 잘 = 속도 + 가용성 (요청-응답의 속도 및 대량 트래픽 커버)
- 데이터 조회를 위한 데이터베이스 내 쿼리 수행 시 쿼리 효율에 따른 소요시간 축소
- 대량 트래픽에 기인한 데이터베이스 조회 시, 부담 축소 및 속도 향상을 위한 로컬 / 글로벌 캐시 도입
- 대량 트래픽에 따른 다중 데이터베이스 접속 시 동시성 처리
- “유치원 어린이 여러분! 한줄로 서세요!”
백엔드 : 데이터 관리 = 데이터에 대한 모든 것 CRUD
결제하기 버튼을 누르면 결제를 위한 정보를 조회하고, 실제 결제가 되었다는 사실을 저장
- “저, 어제 구매한 상품이 오늘 도착하지 않았는데요.” → “네? 그런게 있었나요?” →
“야, 이 새끼야!” - “저, 어제 구매한 상품이 오늘 도착하지 않았는데요.” → “네, 잘 저장되어 있네요. 보내드릴게요”
- “저, 어제 구매한 상품에 대한 배송지를 변경하고 싶습니다.” → “어떤 구매건이고, 어떤걸로 바꿀것인가요?”
- 어떤 구매건이고 (URL) : https://aaron.com/payments/13/update (구매한 결제 정보에 대한 ID)
- 누누히 강조하지만 컴퓨터 혹은 웹 상에서 모든 정보를 지정하는 방법은 무조건 ID
- 어떤걸로 (변수) : Path Variable, Query Parameter 혹은 JSON 형태의 Request Body
- 바꿀것인가요 (Method) : POST
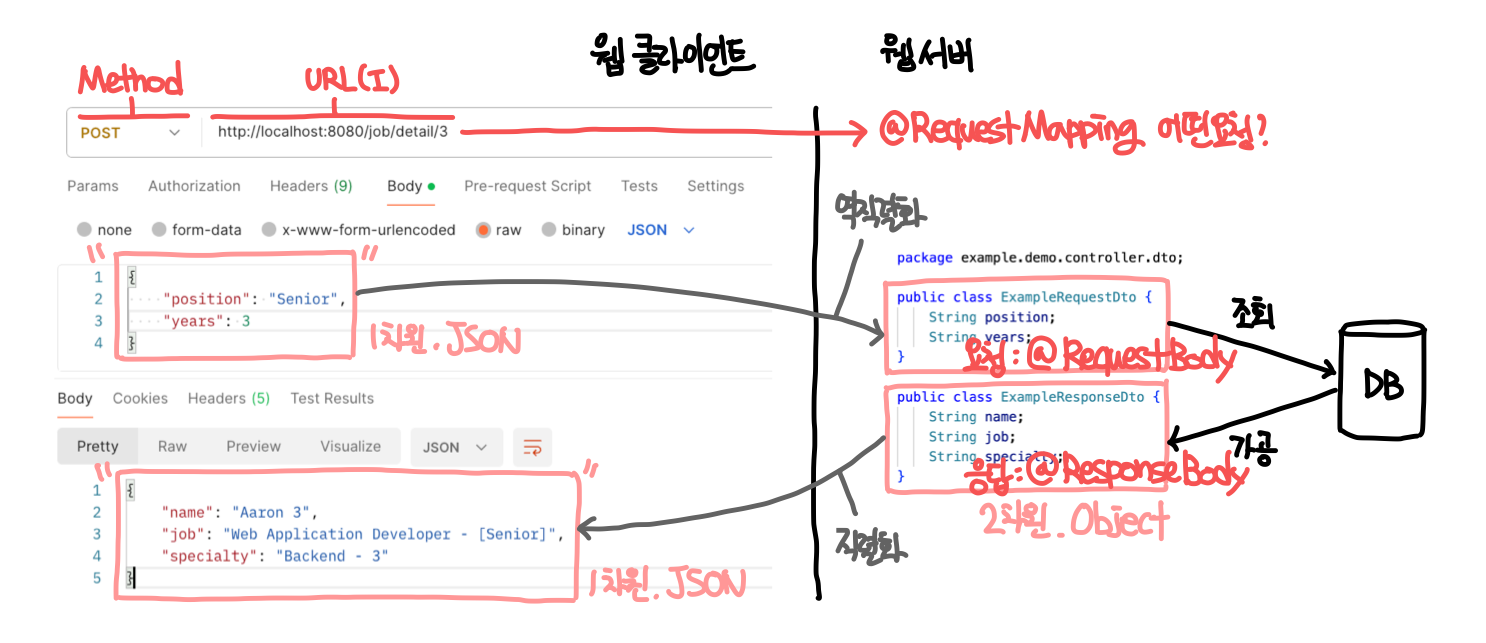
직렬화와 역직렬화의 필요성

- 백엔드 언어만으로 직접 웹 서버를 만들면 어떤 고통이 발생하는가?
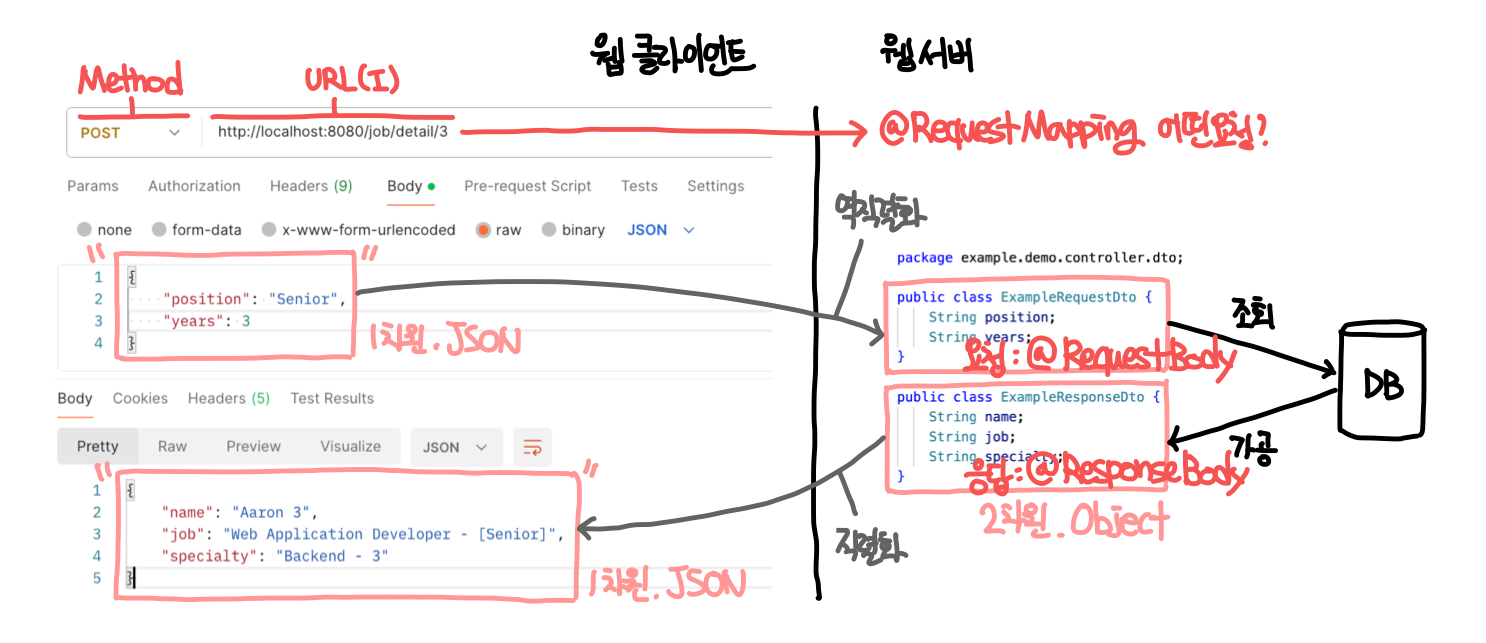
- 어떤 요청이 들어왔는지 일일히 확인해야한다 : 요청 매핑 = RequestMapping
- JSON 형태로 오는 Request 요청 데이터를 객체로 받기 위해 역직렬화 필요 = MessageConverter
- 객체인 Response 반환 데이터를 JSON 으로 반환하기 위해 직렬화 필요 = MessageConverter
직렬화 / 역직렬화 : 외부 데이터 형태와 내부 데이터 형태 사이의 변환
- 외부 : REST API 를 통해 광활한 네트워크를 떠돌아다니는 모든 데이터는 문자열(JSON)로 전송됨
- 내부 : 백엔드 프로그래밍 언어로 개발한 웹 서버에서 모든 데이터는 객체(Object)로 다뤄짐
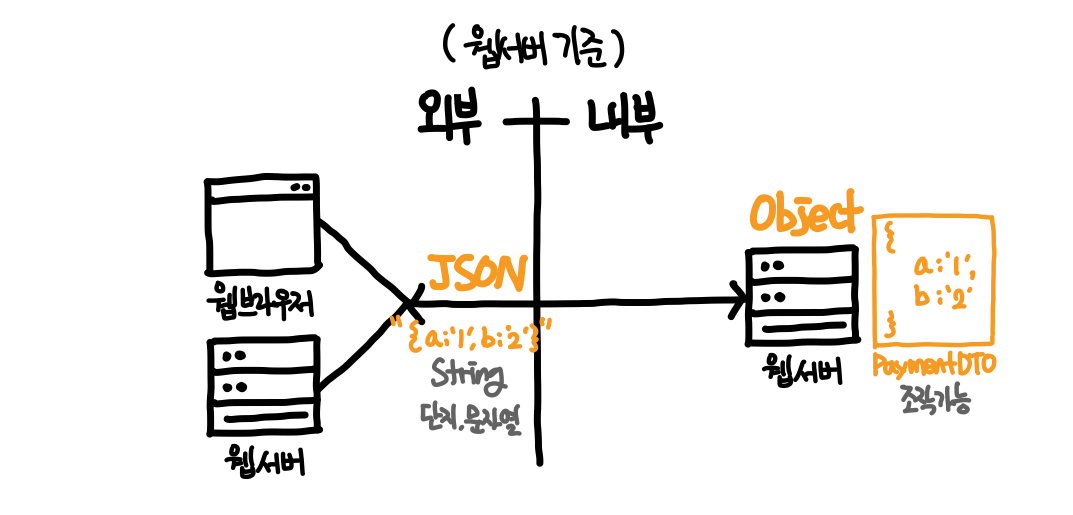
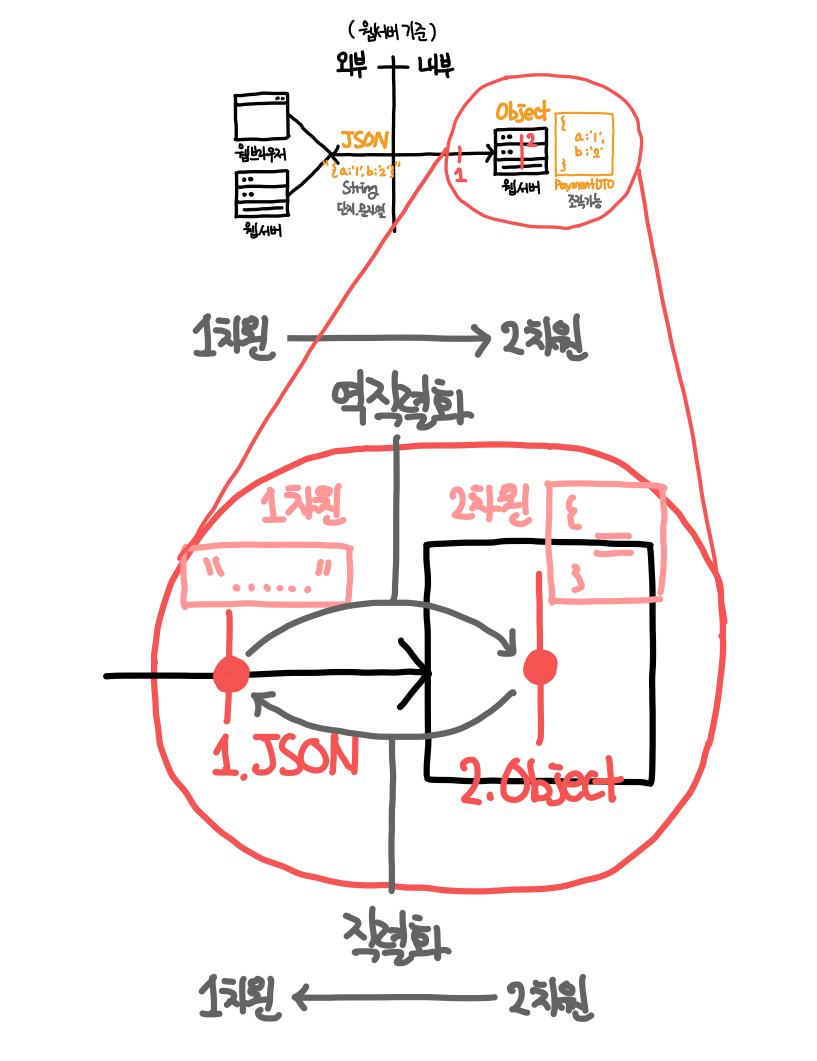
- 응답 : Java 객체(2차원) → HTTP Response Body JSON(1차원, String) : Serialization 직렬화
- 요청 : HTTP Request Body JSON(1차원, String) → Java 객체(2차원) : Deserialization 역직렬화
- 3가지의 웹 클라이언트(웹 브라우저, Postman, CURL) 중 Postman 을 기준으로 조금 더 상세히 살펴보기
웹 어플리케이션 프레임워크 등장과 원리 : 웹 서버 개발에 필요한 모든걸 제공
백엔드 프레임워크를 사용하는 이유
- 개발 생산성 향상 : 기본 구조와 기능을 제공하여 개발 시간과 노력 절약
- 코드 재사용 : 공통 기능을 위한 컴포넌트를 제공하여 코드의 효율적인 공유, 수정, 재사용
- 개발 과정 간소화 : 미리 정의된 구조와 도구를 제공하여 개발 과정 표준화
- 보안 : 많은 프레임워크에서 기본적인 보안 기능 제공
- 확장성 : 애플리케이션의 성장과 변화에 대응할 수 있는 확장성 제공
웹 어플리케이션 프레임워크가 제공하는 기능
- RequestMapping : 어떤 요청에 따라 어떤 메서드(함수 혹은 로직)을 수행할 것인지
- Thread 관리 : 요청을 처리하기 위한 Thread 할당 및 관리, 데이터베이스 접속을 위한 Thread 할당 및 관리
- 데이터베이스 동시성 제어 : 대량 트래픽 발생 시 데이터베이스 조작에 대한 각 요청들 간의 동시성 제어
- Serialization / Deserialization : 요청, 응답 시 어플리케이션의 객체와 클라이언트의 JSON 사이 변환
- Security : CORS 규칙 등에 대한 보안 관련 정의 및 처리
- Authentication / Authorization : 매 요청마다 해당 요청이 권한에 맞게 요청한건지 보안 처리
Interface 인터페이스
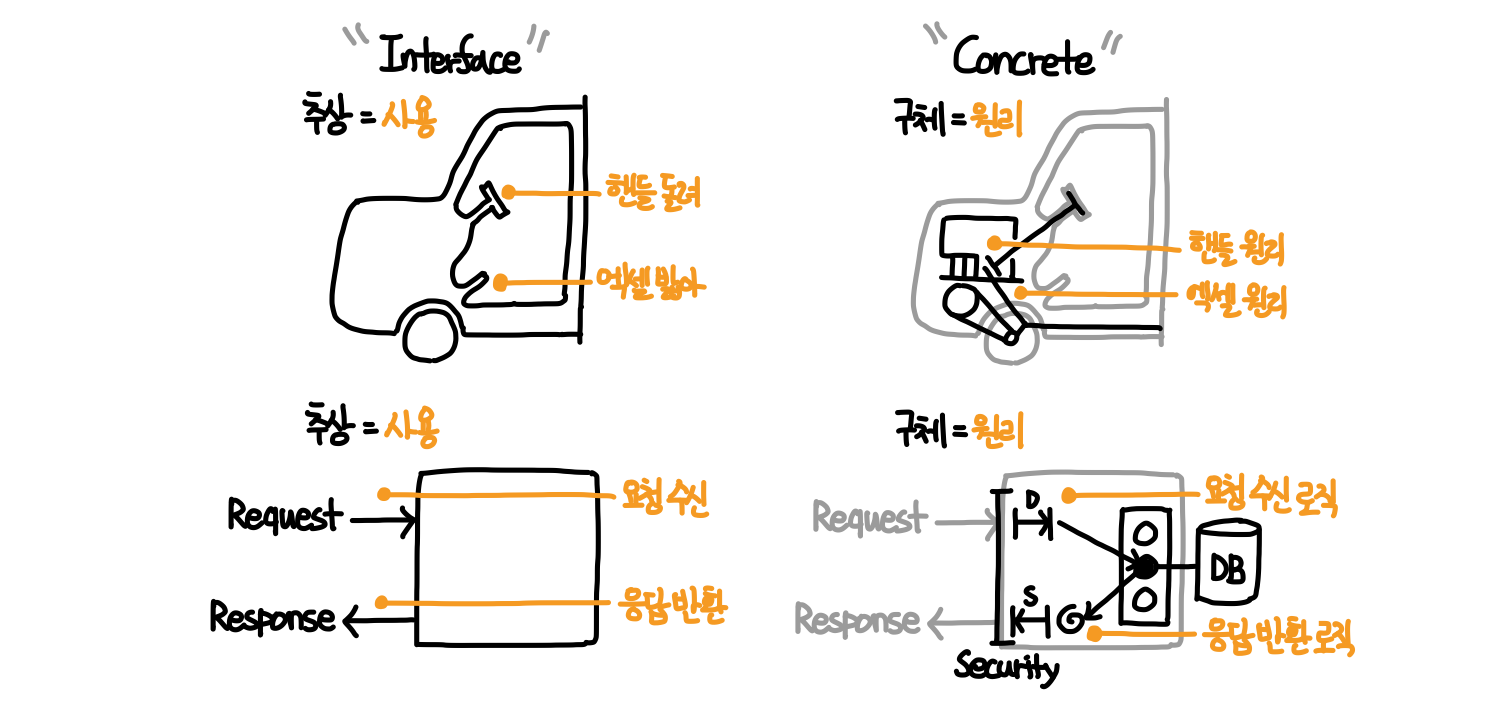
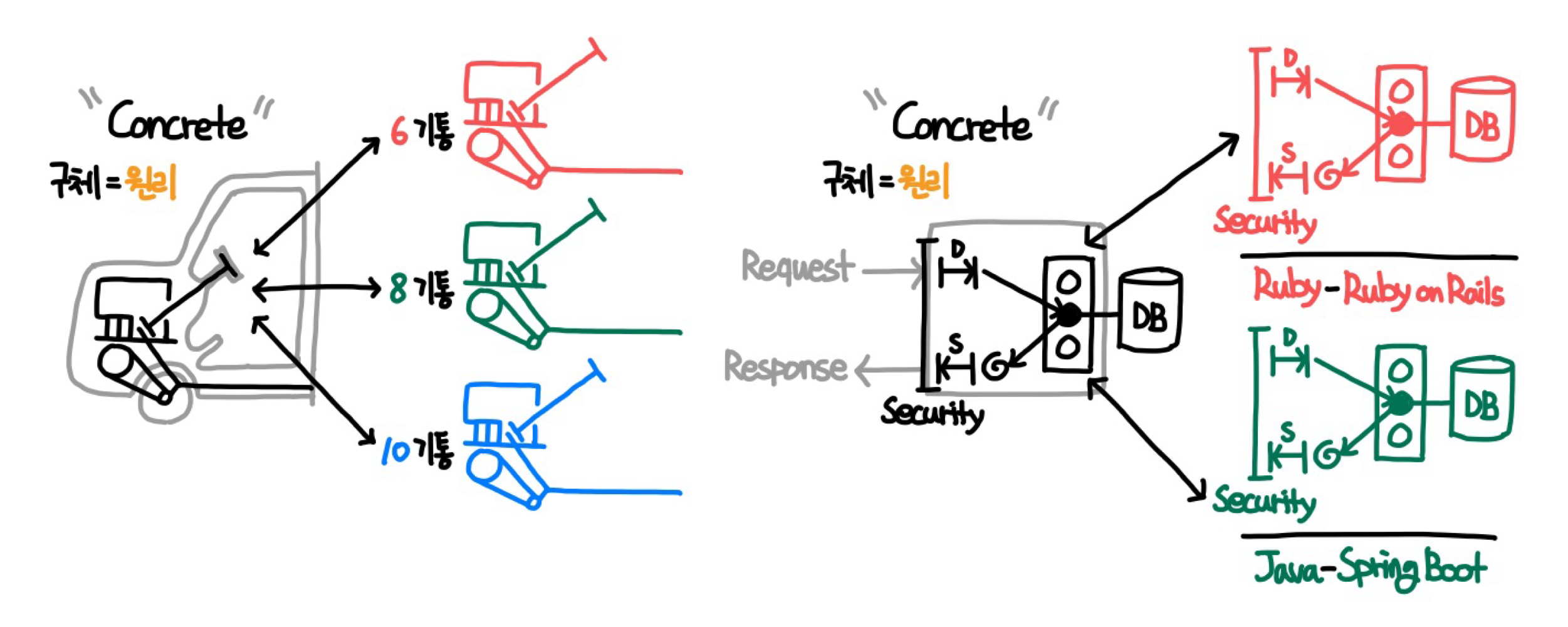
- 추상 = 사용 : “분식점 아저씨 라면 끓여주세요”
- 구체 = 원리 : “아저씨, 라면이라는것은 말이죠.. 그렇게 끓이는게 아니에요.” →
“이 새끼가?“- 일반적인 유저는 프로그램(어플리케이션)이든, 자동차든, 식당에서 음식을 먹든 원리를 생각하지 않음
- 인터페이스는 유저 입장에서 사용 만 하면 되기때문에, 그 내부의 원리(구체)는 언제든지 뒤바뀌어도 됨
API (Application Programming Interface) : 어플리케이션 사용 위한 인터페이스
프로그램(어플리케이션) 혹은 웹 서버에서 어떤 요청을 보내면 어떤 응답을 받을 수 있는지에 대한 스펙
- 추상 = 사용 스펙 : 프로그램(어플리케이션) 혹은 웹 서버 사용법 (어떤 요청 시 → 어떤 응답 반환)
- “화나면 뭅니다.” = 저에게 화나는 요청 시 → 물어버리는 응답을 반환합니다.
- 구체 = 상세 로직 : 어떤 요청 시 → 어떤 응답을 반환하기 위한 방법은 많고, 유저는 신경 쓸 필요 없음
- 좌측의 Postman 에 적힌 “어떤 요청 시 → 어떤 응답을 반환”하는지 여부가 API 라 볼 수 있음
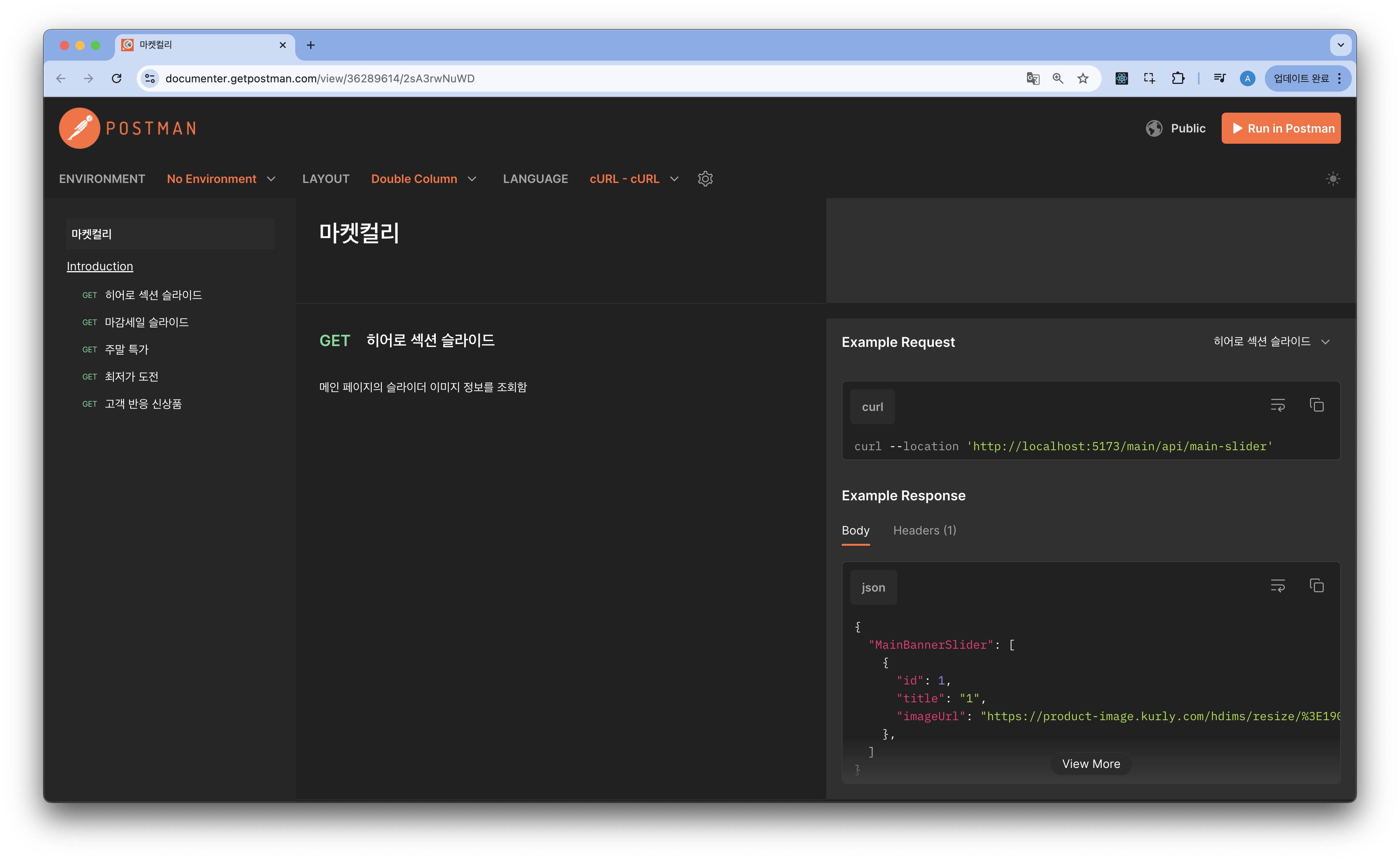
- 실제로 API 는 내부 구현이 어떻게 되어있는지는 전혀 상관하지 않고, 다음의 요청을 보내면 아래 결과를 받는다는 것만 알려줌
라이브러리 vs. 프레임워크 → 프레임워크 = 라이브러리 집합
쉽게 말하자면 라이브러리와 프레임워크의 차이는 단수와 복수라 할 수 있고,
좀 더 정확하고 기술적으로 얘기해보자면, 개발의 제어권이 어디에 있는가로 구별됨
- 라이브러리 : 단일 문제 해결을 위한 단일 도구 = “뭐가 필요해? 자, 이거 가져가”
- 프레임워크 : 다수 문제 해결을 위한 도구 집합 = “네가 뭘 좋아할지 몰라서, 모든걸 다 준비했어”
- 다수의 라이브러리 제공 : 개발에 필요한 라이브러리들을 한데 묶어, 개발 편의성 제공
- 다수의 인터페이스 제공 : 개발을 위한 껍데기를 제공할뿐 필요한것은 직접 구현 혹은 라이브러리 교체
Library 라이브러리
라이브러리는 상세 구현체를 제공하고, 개발자는 필요한 기능 사용을 위해 라이브러리를 가져와 코드와 합침
- 개발자는 자신의 코드와 라이브러리가 합쳐지도록 개별 설정 및 코딩 필요
- 고-통 : 개발자의 역량에 따라 라이브러리가 기존 어플리케이션 코드에 제대로 합쳐지지 않을 가능성
- 즉, 개발자는 라이브러리 사용에 대한 책임과 모든 제어권을 가짐 : 흐름 제어권 = 개발자 몫
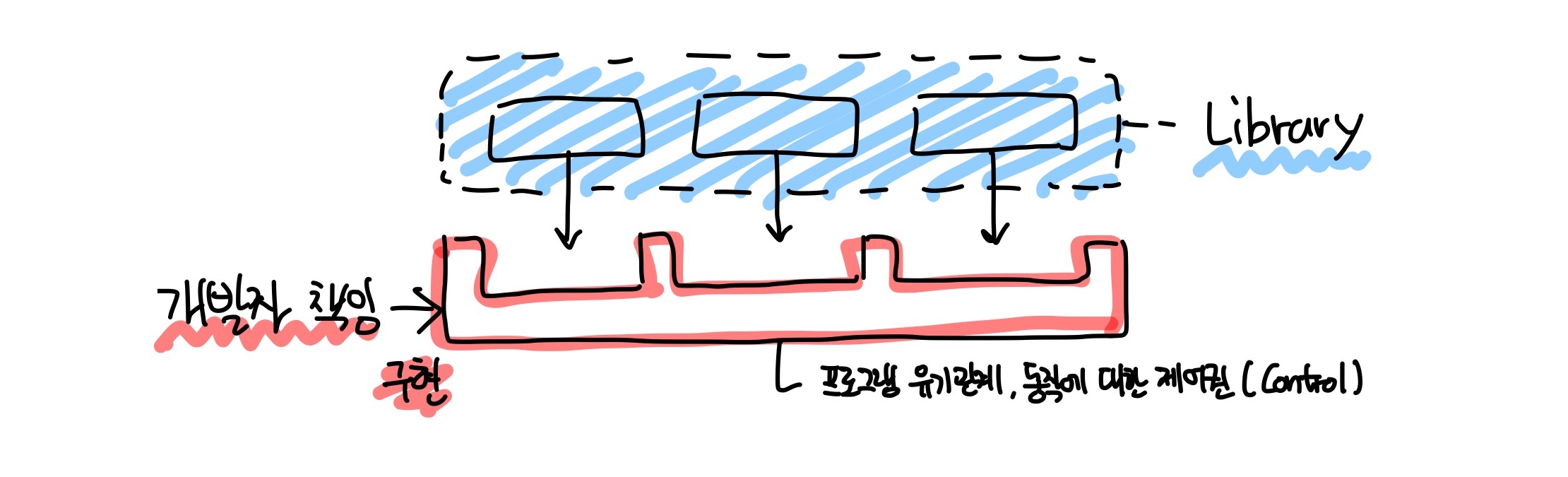
- 라이브러리는 상세 구현체를 제공하고, 개발자는 라이브러리를 어떻게 설정, 사용할지 기존 로직과의 연결에 대한 제어권 가짐
Framework 프레임워크
프레임워크는 껍데기만 주어질 뿐 상세 구현체는 개발자가 직접 개발하거나, 다른 라이브러리들을 가져와 꽂음
- 꽂음 : 프레임워크는 라이브러리를 편하게 바꿔쓸 수 있도록 공통 인터페이스 제공
- 편-안 : 개발자 역량에 상관없이 쓰고싶은 라이브러리가 있다면, 그냥 가져다가 꽂기만하면 만사 해결
- 즉, 프레임워크는 라이브러리 사용에 대한 책임과 모든 제어권을 가짐 : 흐름 제어권 = 프레임워크 몫
- IoC (Inversion of Control, 제어권의 역전) : 개발, 흐름 제어권이 개발자에서 프레임워크로 이동
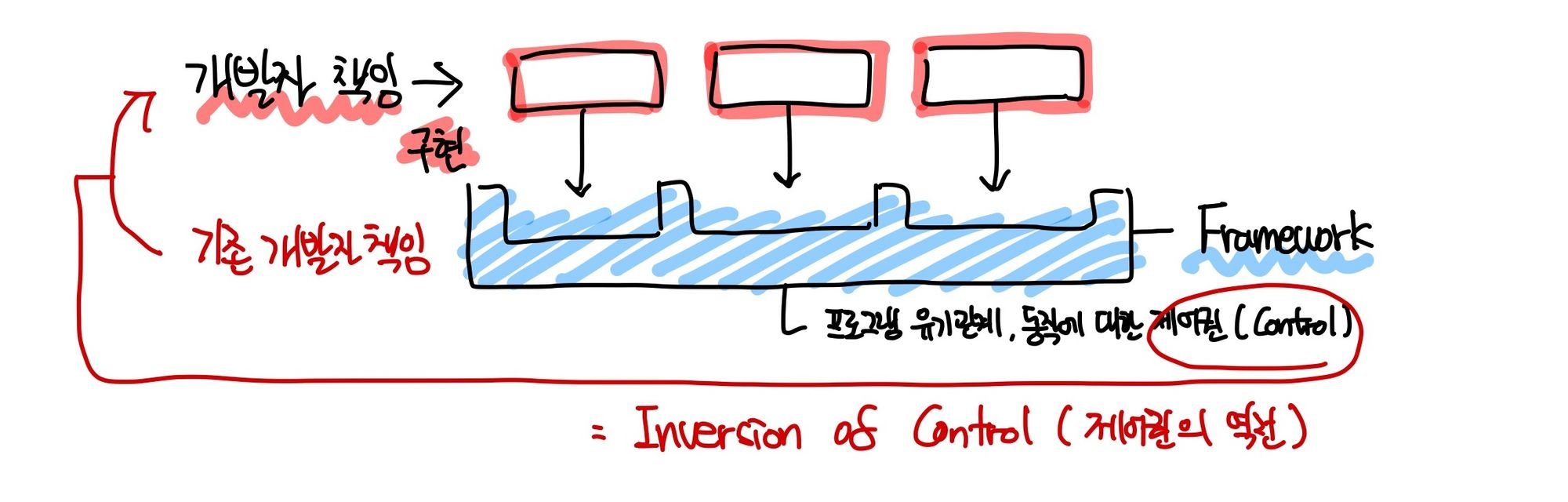
- 프레임워크는 모듈화를 통해 함수 모든 로직의 연결에 대한 제어권을 제공하고, 개발자는 각 모듈의 상세 구현체만 신경쓰면 됨
프레임워크 사용의 고통 : 무한한 자유도
- 다수의 라이브러리 제공 : 설정이 너무 다양한데, 뭘 만져야하는거지? 잘못 만지면 망가지지 않을까?
- 다수의 인터페이스 제공 : 어떻게 사용해야하지? 어떻게 동작하는거지? 하, 공부할거 진짜 너무 많네..
웹 어플리케이션 프레임워크 동작 원리
1️⃣ Package Manager : 라이브러리 버전 관리
웹 어플리케이션 프레임워크는 아래의 2가지를 제공
- 다수의 라이브러리 제공 : 개발 편의성을 위한 다양한 라이브러리 제공
- 다수의 인터페이스 제공 : 개발을 위한 껍데기를 제공할뿐 필요한것은 직접 구현 혹은 라이브러리 교체
많은 수의 라이브러리가 필요하기에 1. 어떤 라이브러리를 사용하고, 2. 어떤 버전을 사용할지 관리 필요
- 결과적으로, 프레임워크 사용 시 라이브러리에 대한 버전 관리를 위한 Package Manager 가 필요
- Javascript 는 npm 사용
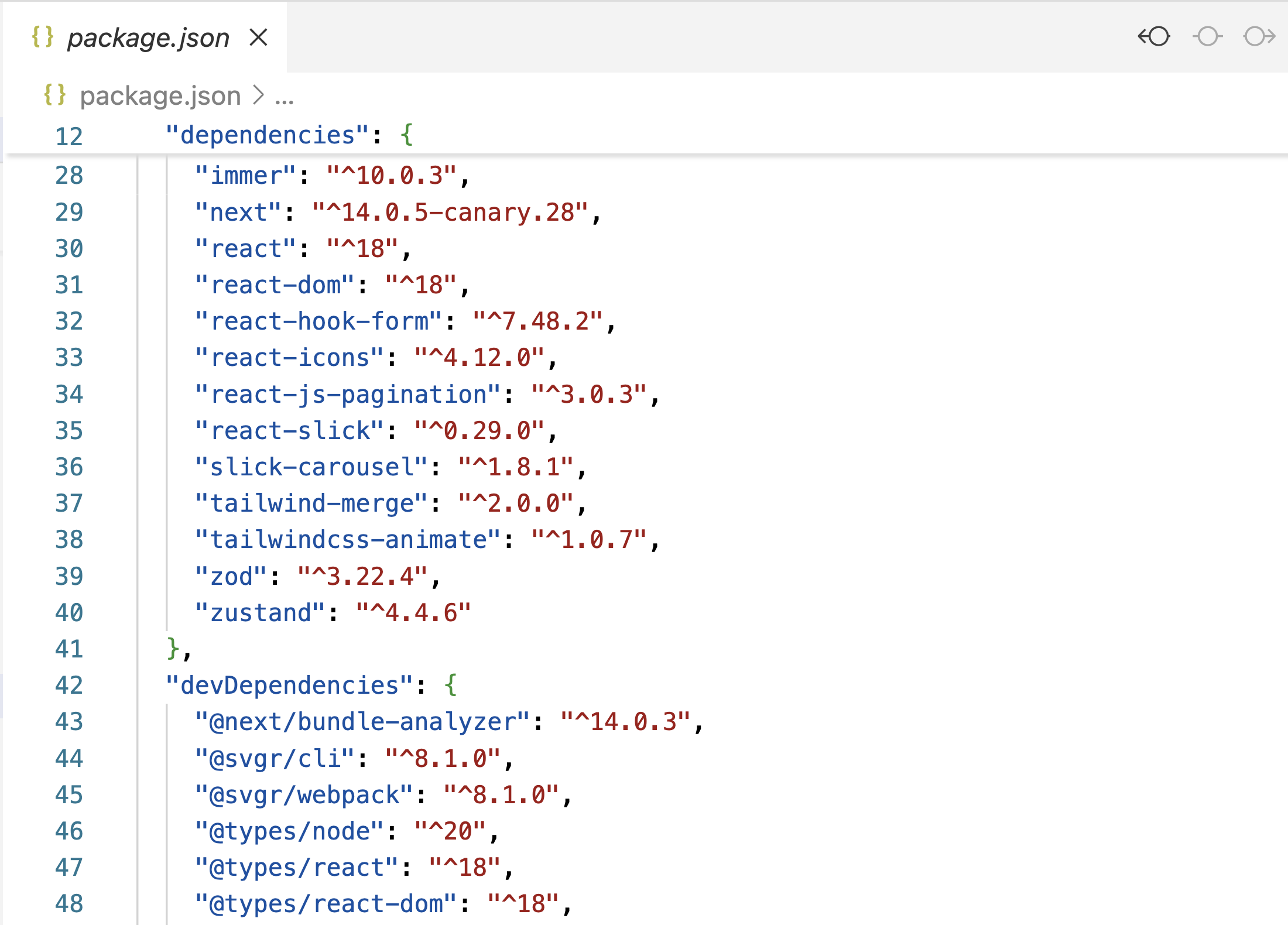 Javascript 의 Package Manager 중 하나인 npm ex) package.json
Javascript 의 Package Manager 중 하나인 npm ex) package.json
- Python 은 pip 사용
- Ruby 는 bundler 사용
- Java 는 Maven 혹은 Gradle 사용
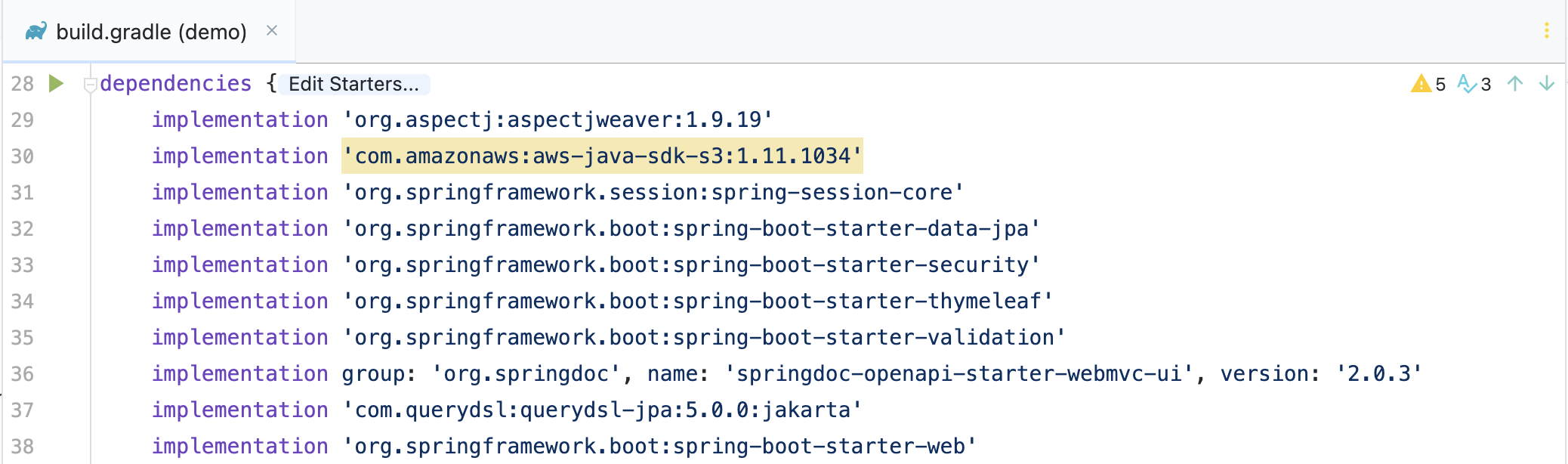 Java 의 Package Manager 중 하나인 Gradle ex)
Java 의 Package Manager 중 하나인 Gradle ex)build.gradle
2️⃣ Database : 데이터 조회 및 조작
CRUD = 데이터 조회 및 조작 : Create, Read, Update, Delete
- 동적 데이터를 저장하는 저장소이기에 데이터를 식별할 때는 무조건 ID 를 사용할 것
- 동적 데이터이기에 데이터는 매번 바뀌지만, 데이터가 바뀌더라도 고유의 ID 로 일관적인 조회 가능
- 데이터 식별을 이름 으로 하였다면, Aaron 이 Baron 으로 개명되었을때 조회 실패
- 데이터 식별을 ID 로 하였다면, Aaron 이 Baron 으로 개명되어도 여전히 ID 1번으로 조회 성공
3️⃣ Transaction : 대량 트래픽이나, 다수 요청이 데이터베이스에 접근 → 동시성 제어
단일 데이터베이스에 다수 접근이 충돌나지 않게 번호표를 주고, 순서대로 처리
- 다수의 웹 서버에서 (대량 트래픽) → 단일 데이터베이스에 접속 시, 충돌 (서로 데이터베이스 쓰겠다고 싸움)
- 하나의 웹 서버에서 다수의 요청이 → 단일 데이터베이스에 접속 시, 충돌 (서로 데이터베이스 쓰겠다고 싸움)
운영체제 개요 및 프로그램(어플리케이션) 동작 원리
하드웨어 : 어플리케이션(소프트웨어)이 구동되는 머신
- 내부 자원 : CPU + Memory
- 외부 자원 (입출력) : 네트워크 IO, 저장장치 IO, 마우스/키보드
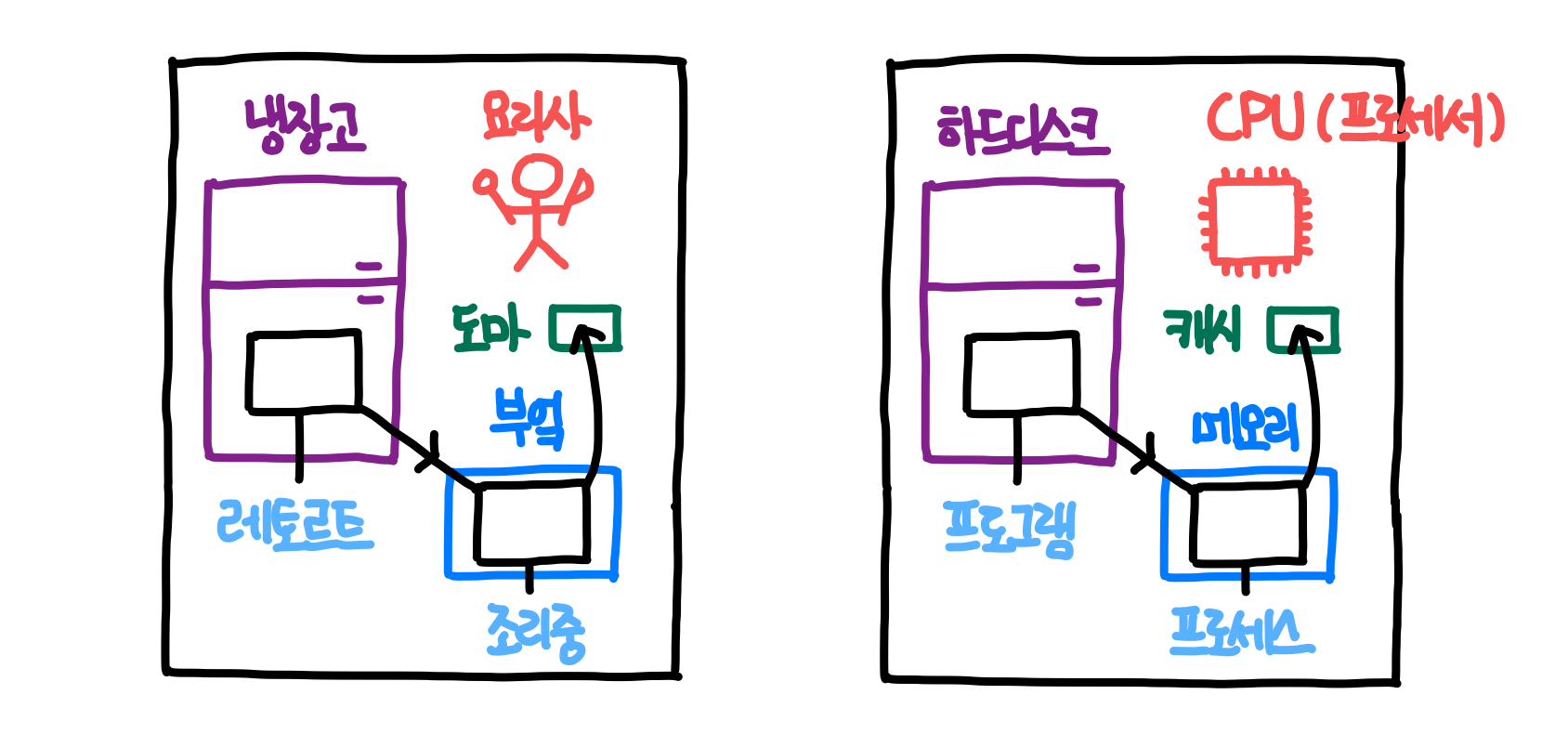
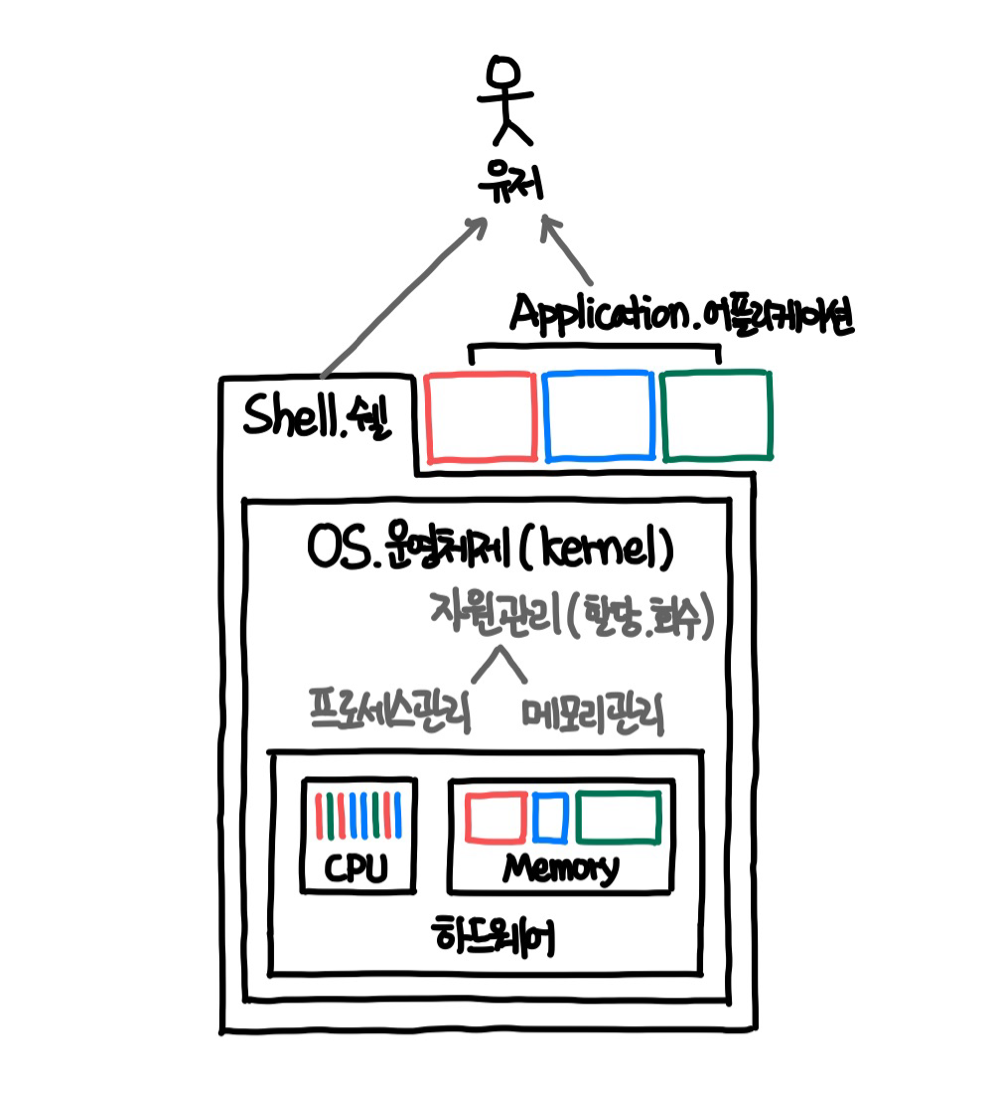
소프트웨어 : 시스템 소프트웨어(OS) + 응용 소프트웨어
- 시스템 소프트웨어 = OS 운영체제 : 아래 응용 소프트웨어에게 하드웨어 제공
- CPU 자원관리 : Scheduling Algorithms 스케줄링 알고리즘
- First-Come, First-Served (FCFS) scheduling
- Short-Job-First (SJF) scheduling
- Round Robin (RR) scheduling
- Priority scheduling
- Multilevel Queue scheduling
- Multilevel Feedback Queue scheduling
- CPU 자원관리 : Scheduling Algorithms 스케줄링 알고리즘
- 응용 소프트웨어 = 어플리케이션 = 프로그램
- Shell 쉘 : 유저가 커널을 직접 다루기는 너무 어려워 응용 소프트웨어로 간편한 제어 및 사용 제공
- Kernel 커널 : 운영체제의 핵심부로 컴퓨터 자원들을 관리하는 역할
- 그 외 모든 응용 소프트웨어 : 우리가 다운받고, 설치해서 사용하는 모든 것
- Shell 쉘 : 유저가 커널을 직접 다루기는 너무 어려워 응용 소프트웨어로 간편한 제어 및 사용 제공
프로그램, 프로세스와 스레드
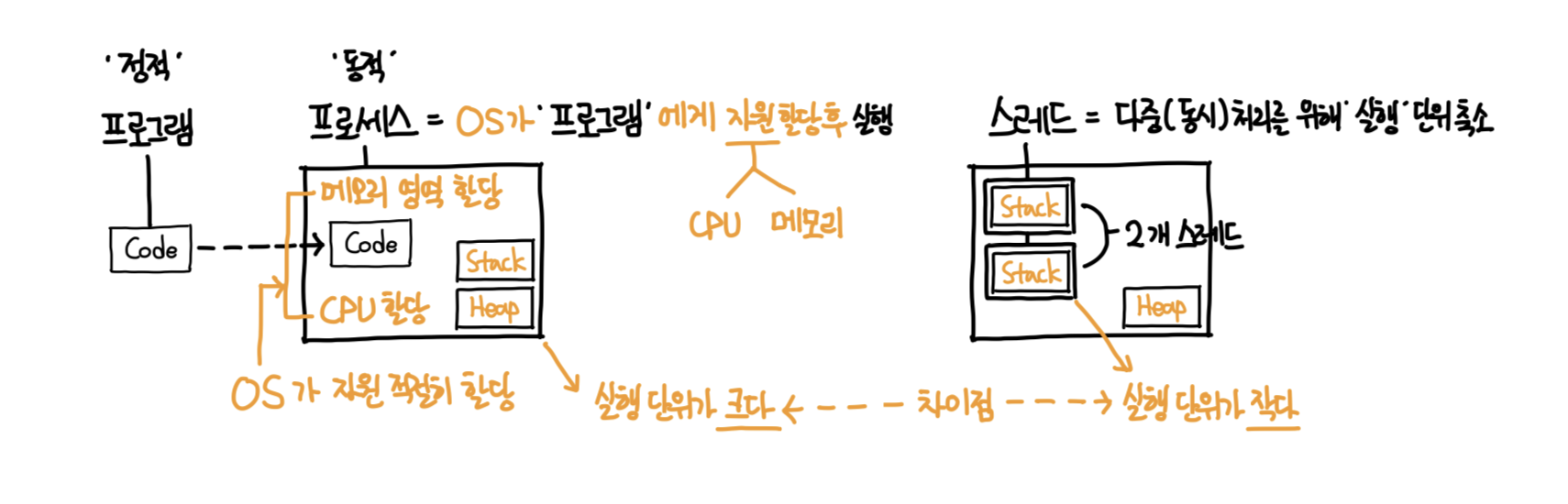
- 프로세스 = 실행 단위가 크고 + 한개의 프로그램에 한개의 프로세스만 존재
- 스레드 = 실행 단위가 작고 + 한개의 프로그램 (한개의 프로세스) 내 수많은 스레드가 존재 가능
- 스레드마다 프로그램 카운터(실행 위치) + 명령어 레지스터(실행 함수) + 스택 영역(실행 변수) 보유
- 심화 : 프로세스/스레드 간 임계구역(Critical Section) 내 충돌 경쟁상태(Race Condition) 와 해결
- 비유 : 카페에 있는 단 하나뿐인 화장실에 수많은 카페 고객(사람)들이 접근
- 스레드 = 수많은 카페 고객(사람)
- 임계구역(Critical Section) = 단 하나뿐인 화장실
- 경쟁상태(Race Condition) = 동시성 문제 : 임계구역(화장실)에 두 사람(스레드)이 동시 사용
- 임계구역(화장실)에서 발생하는 경쟁상태(화장실에 여러명이 한번에 들어감)의 해결 방법?
- 동기화(Synchronization) = 동시성 제어 = 여러 스레드가 하나의 단일 자원에 동시에 접근
- 동기화(Synchronization) 기법의 종류로 2개의 타입
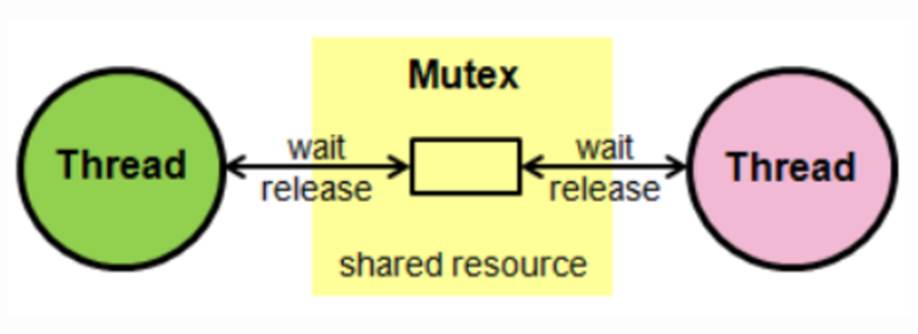
- Mutex 상호배제 : Lock 혹은 Key 방식 = 0 잠금, 1 열림
- 동기화 대상 1개 = 접근 가능한 스레드 1개 = 변기칸이 1개
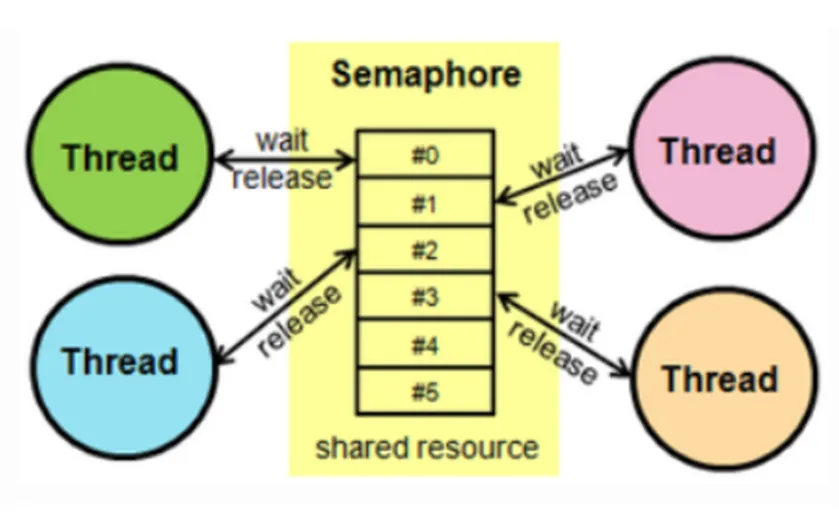
- Semaphore 세마포어 : Counter 방식 = 1, 2, 3, 4 넘버링
- 동기화 대상 N개 = 접근 가능한 스레드 N개 = 변기칸이 N개
- Mutex 상호배제 : Lock 혹은 Key 방식 = 0 잠금, 1 열림
- 비유 : 카페에 있는 단 하나뿐인 화장실에 수많은 카페 고객(사람)들이 접근
운영체제 위 어플리케이션 동작 원리
운영체제는 커널 부팅 직후 초기화 프로세스를 시작 = 시스템에 필요한 프로세스가 자동으로 실행되는 단계
- 초기화 프로세스 (초기화 시스템명 : init 혹은 현대에는 systemd)
- 커널 부팅이 끝나면 (운영체제가 하드웨어의 모든 기능을 제어하게 되었을 때)
- 초기화 시스템은 구성 파일을 읽고 구성 상태에 따라 서비스와 프로세스를 시작
- 초기화 프로세스는 모든 프로세스의 시작점이자 가장 첫 프로세스이기 때문에 1번 PID가 부여 (pid = 1)
- 초기화 시스템 (Linux Service and Daemon Management) 종류와 그 둘의 차이
리눅스 내 pstree 로 확인해보면, systemd 인지 init 인지 확인 가능
- 과거 : SysVInit (프로세스명 init) ← Unix 에서 사용
- `service (start / stop / restart)` ← /etc/init.d
- 한번만 수행 후 종료 → 이후 개별 프로세스 추적 불가One of the main characteristics of this init system is that it is a start-once process and does not track the individual services afterward.
- 현대 : SystemD (데몬 프로세스명 systemd) ← Linux Distributions(Ubuntu 등) 에서 사용
- `systemctl (start / stop / status / restart)` ← /etc/systemd/system/.service
- 한번 수행 후 계속 Daemon 형태로 떠있어서 이후 개별 프로세스 추적 가능SystemD continues to run as a daemon process after the initialization is completed. Additionally, they are also actively tracking the services through their cgroups
Daemon 데몬
- 프로세스 내 2가지 종류 : Foreground Process (부모 O) + Background Process (부모 X)
- 우리도 모르게 동작 중인 Background Process 를 리눅스에서는 Daemon 이라 칭함
- 예시로, 끝에 d 가 붙는 프로세스들 모두 데몬을 뜻함 : sshd, httpd, mysqld
컴파일과 인터프리팅 : 어플리케이션 개발 및 구동
프로그램이 동작하는 기본 원리를 짚자면, 기계어가 머신에서 (해석되어) 실행되는것

- 기계어를 프로그램(정적)이라고 하고, CPU 및 메모리가 할당되어 실행되면 프로세스(동적)
- Compile 컴파일 과정 : Java 코드 (.java) ⇒ Bytecode (.class) - 자바 컴파일러(Javac)를 통해
- Compiler 컴파일러 = 자바 컴파일러(Javac)
- C, C++ 코드 (.c .cpp) ⇒ 기계어(Binary Code) - GNU 컴파일러(GCC)를 통해
- GCC = GNU 컴파일러 모음 (GNU Compiler Collection ← GNU C Compiler)
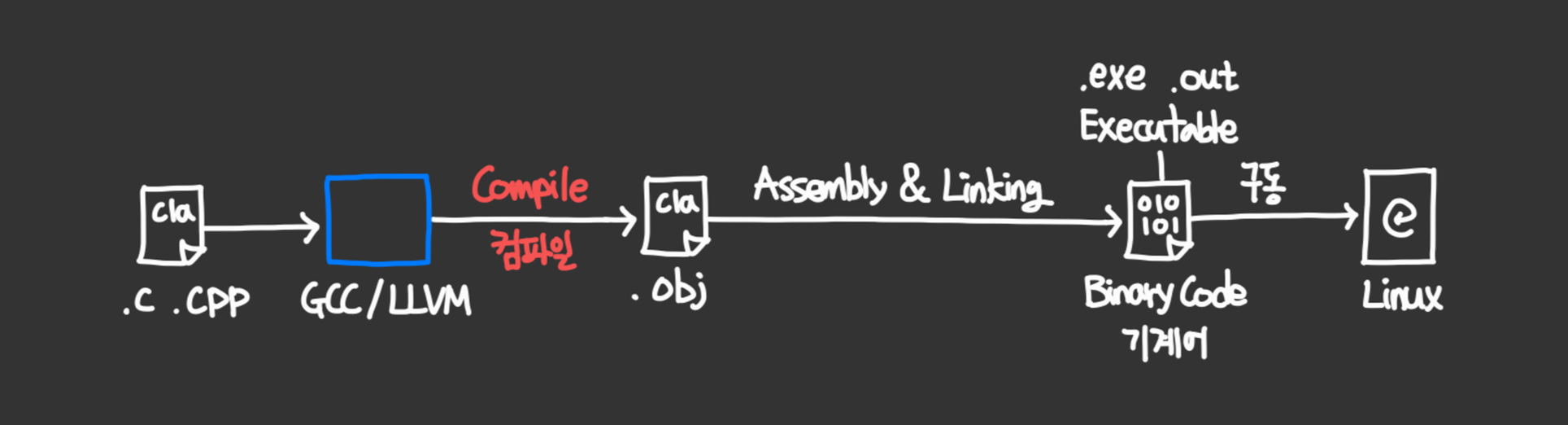
- C 언어는 어떤 머신에 구동할지 컴파일 단계에서 옵션을 주어 머신에 맞는 기계어를 컴파일(생성)
- C, C++ 코드의 경우 컴파일러(GCC/LLVM)를 통해 기계어(Binary Code) 변환 직후 머신 동작
- Runtime 런타임 과정 : Bytecodes (.class) ⇒ 기계어(Binary Code) - 자바 엔진(JVM)을 통해
- Interpreter 인터프리터 = 자바 엔진(JVM)
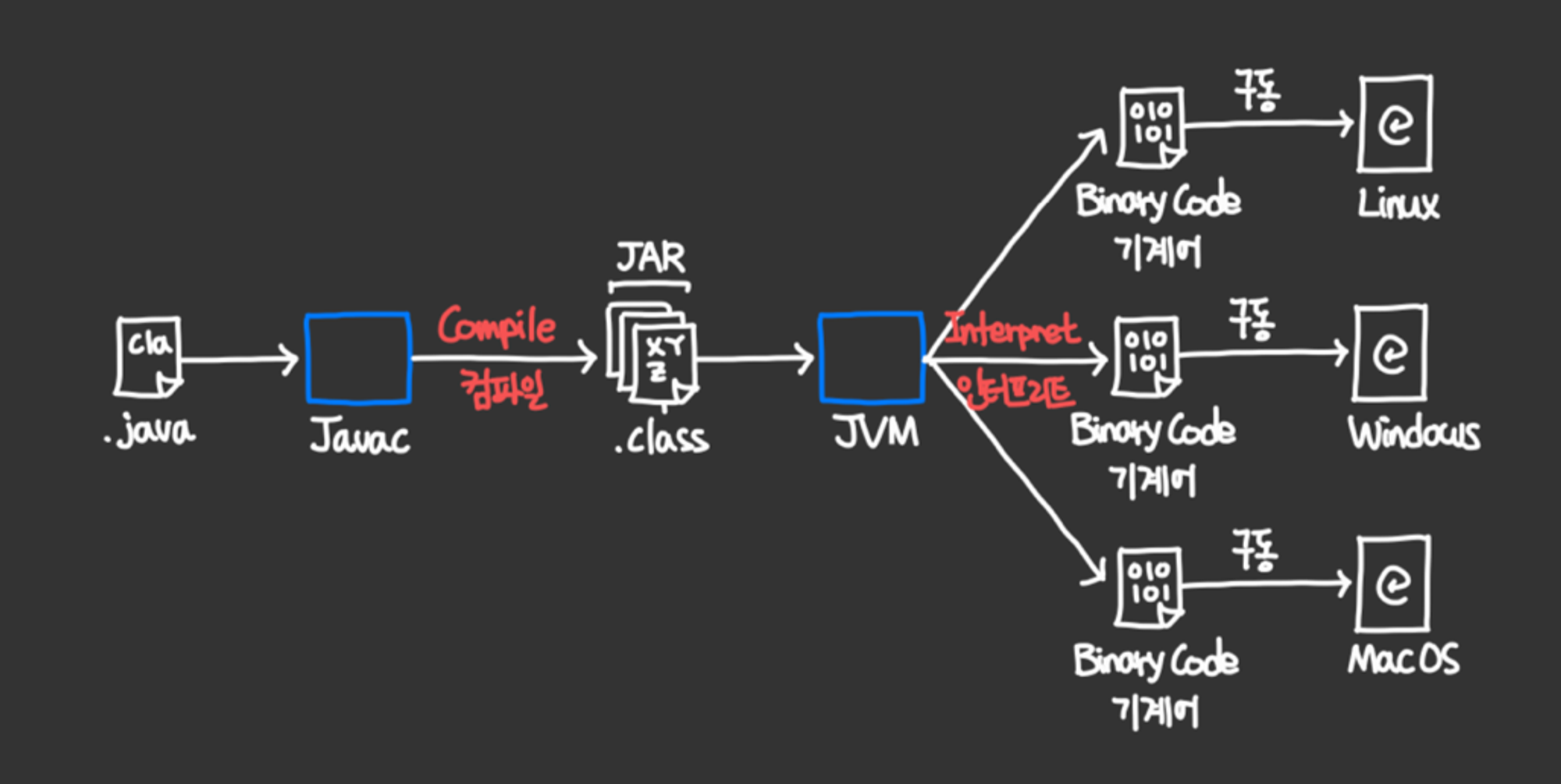
- Java 코드는 컴파일 단계에서 단일 바이트코드 생성 후 JVM 이 머신에 맞춰 기계어로 인터프리팅 후 실행
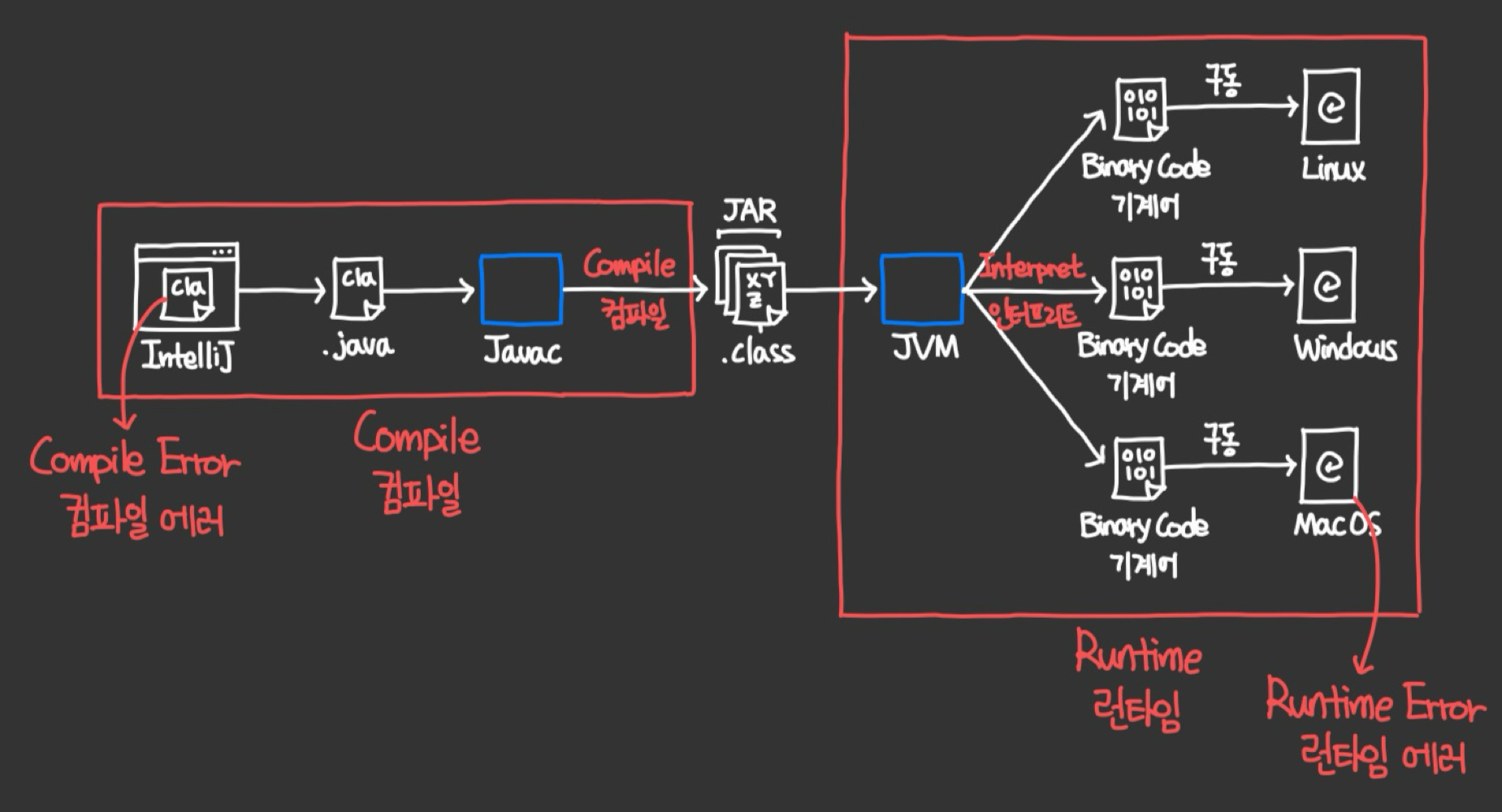
- Intellij 에서 컴파일 시 인지되는 문법 오류 등을 발생시키는걸 컴파일 에러라 하고, 실제 동작중에 발생하는 에러는 런타임 에러
Compiler vs. Interpreter
- Compiler 컴파일러 : 프로그램 전체를 스캔해 한 번에 기계어로 번역하여 실행 전 파일로 저장하는 것
- Compile 과정에서 일어나 실행 전 오류 파악이 가능하며 실행 속도가 빠름
- Interpreter 인터프리터 : 프로그램 실행 시 한 번에 한 문장씩 기계어로 번역 그 과정에서 오류를 발생시키는 것
- Runtime 과정에서 일어나 메모리 사용이 적으며 프로그램 수정이 빈번할 때 유리
Non-Blocking 연속성 & Asynchronous 동시성
1. 연속성 = Blocking vs Non-Blocking
일반적으로 CPU 가 멈추는 걸 의미
- Blocking : 하나의 작업이 간간히 방해받으며 수행
- 방해 : 주기적인 프로그램 실행 상태를 확인하는 등
- Non-Blocking : 하나의 작업이 어떠한 방해도 받지않고 수행
2. 동시성 = Synchronous vs Asynchronous
일반적으로 병렬처리를 의미
- 동기 Synchronous : 앞선 작업이 완료되어야 그 다음 작업을 수행
= 작업이 완료될때까지 하던 작업 멈추고 대기- 비동기 Asynchronous : 앞선 작업이 완료되든말든 그 다음 작업을 수행
= 작업이 완료되든말든 하던 작업 그대로 진행
- 작업이 완료되면, 완료되었다는 응답을 받음 : **Callback**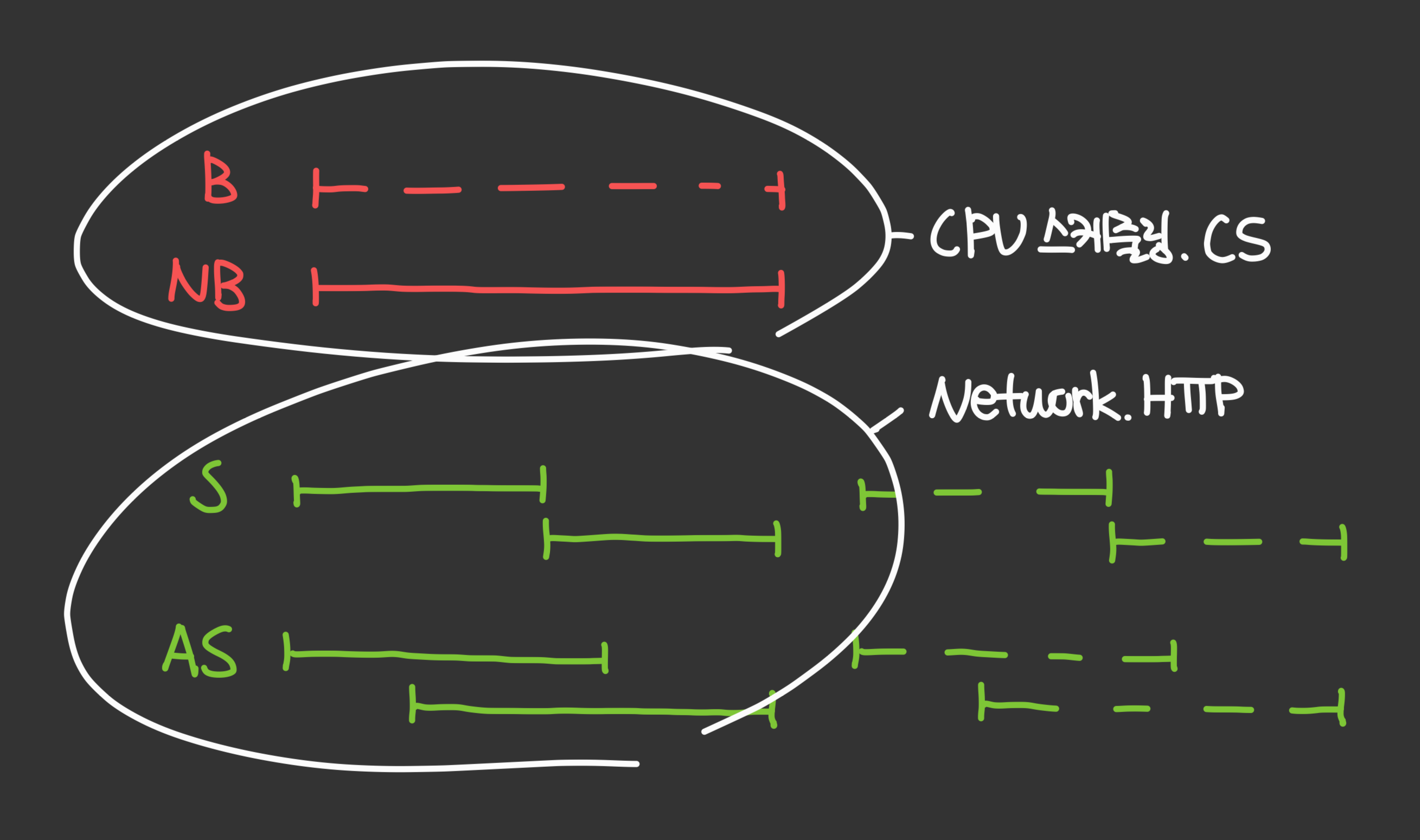
Infrastructure : 서버의 구성 : 물리 서버 vs 가상 서버
우리가 만든 웹 어플리케이션을 구동시키려면 서버가 필요한데, 그 서버를 어떻게 구축/구성해야할까?
- 물리 서버 (온프레미스) : 기업의 요구사항에 맞춰 직접 중소형 데이터센터를 구축 및 유지보수 비용 발생
- 단독주택 : 집주인의 요구사항에 맞춰 처음부터 끝까지 집짓기
- 가상 서버 (클라우드 서버) : 이미 구축된 초거대 데이터센터에서 사용할 부분만 온디맨드 임대
- 오피스텔 : 이미 구축된 초거대 거주단지에 임대(전월세)로 살기
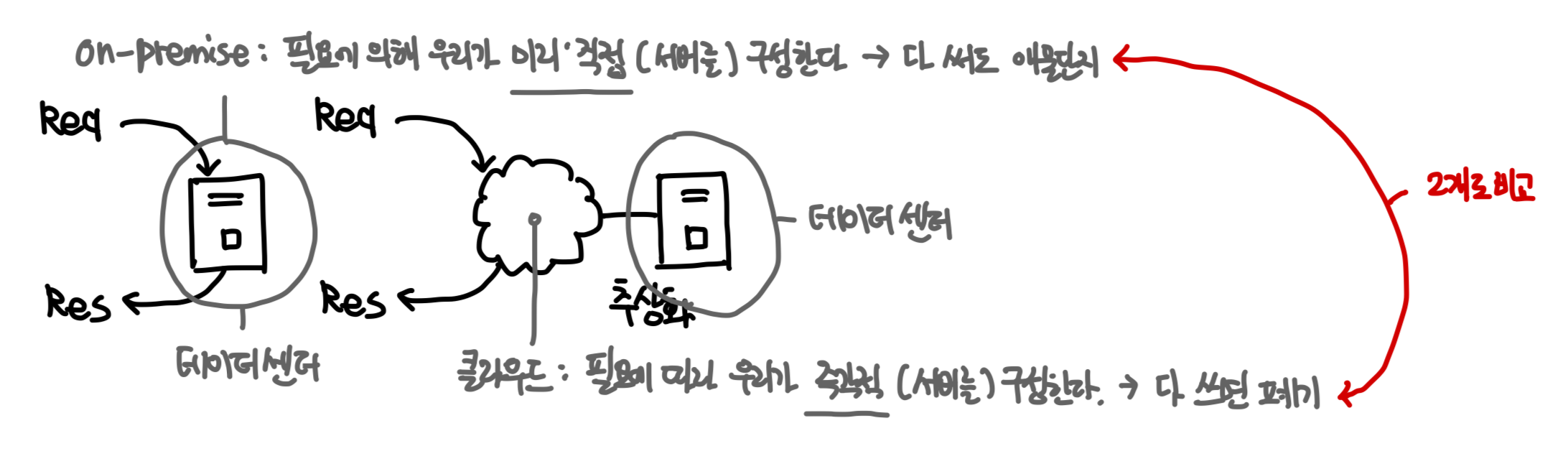
1️⃣ 물리 서버 (데이터센터, On-Premise)
데이터센터 구축에 따른 (1) 고정 비용 + (2) 직접 운영과 관리
- 물리 서버 호스팅 업체 : 카페24 - 물리 데이터센터의 수많은 서버 중 일부를 대여 (라떼 국산 AWS)
- AWS 가 없던 호랑이 담배피던 시절에는 서버에 뭔가를 배포하려고하면 카페24 호스팅이 필요
- 월세처럼 매달 서버 비용을 지불하여 서비스를 유저들에게 제공하였었는데, 매번 트래픽 초과시 에러

- 물리 서버 단점 : 아래 호스팅 업체를 쓰지 않는다면, 직접 서버를 조립하고, 서버 배치할 장소 물색 등
- 건물 유지비용, 서버 구매비용, 유지보수 등
- 다수 서버 (컴퓨팅 시스템을 위한 하드웨어 : 데스크탑 조립해서 GPU 없이 사용)
- 네트워킹 장비 (다수 서버를 권역별, 용도별로 나누어 네트워크 IP 할당, Private / Public 설정)
- 장소 (물리적 장소 ~= 건물, 요즘같이 전월세 비싼시절에 비용 문제)
- 한번 구매, 설정하면 수요에 상관없이 계속 보유, 관리필요 (feat. 우리집 디아4 용 비싼 컴퓨터)
- 전원 (전기 시스템) 및 냉방 공급 (전기가 불안정하면 일부 서버 혹은 서버 모두가 문제 발생)
- 백업 시스템
- 운영 인력
- 건물 유지비용, 서버 구매비용, 유지보수 등
2️⃣ 가상 서버 (클라우드 서버, Cloud Server)
데이터센터 임대에 따른 (1) 온디맨드 비용 + (2) AWS 가 대신 운영 및 관리
- 가상 서버 (클라우드 서버) 호스팅 업체 : AWS, Azure - 수많은 클라우드 서버 중 일부를 대여
- 아래 그림은 물리 서버를 썼을때 최대 피크에 해당하는 서버 구축으로 낭비되는 자원이 너무 많음
- 클라우드는 피크에 해당하는 비용만 지불하면 되어서 낭비되는 자원에 따라 낭비되는 비용 미발생
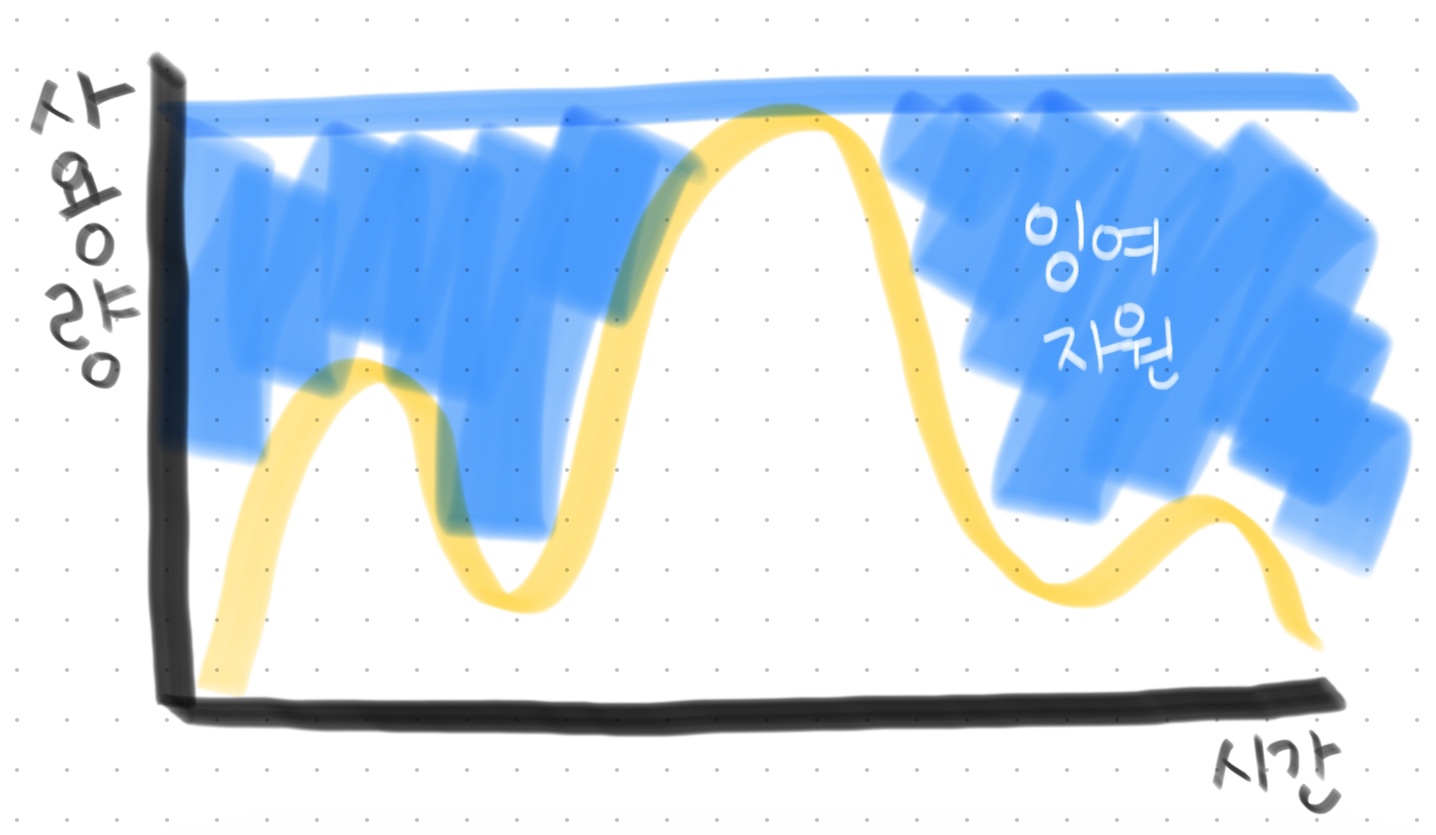
- 가상 서버 (클라우드 서버) 장점
- 매우 간편한 설정 : 필요에 따라 원하는 네트워크 및 서버 구축을 몇초안에 완료
- 몇 번의 클릭으로 리소스 확보 가능
- 고정되지 않은 유동적인 비용
- 필요할때만 쓰고 비용을 지불하니까 비용 절감
- 매우 간편한 설정 : 필요에 따라 원하는 네트워크 및 서버 구축을 몇초안에 완료
3️⃣ 서버리스 Serverless
물리적 서버든 클라우드 서버든 서버들을 구매하지 않고도 작업을 수행할 수 있는 것
- 물리적 서버 나 클라우드 서버 나 시간에 따른 과금 (서버가 계속 떠있으니까 = 구동되고있으니까)
- Serverless 는 서버가 존재하지 않기 때문에 시간이 아닌 요청 횟수에 따른 과금
- 요청이 들어오면 기존에 떠있는 서버가 받아서 처리하는게 아니라
- 요청이 들어오면 처리를 위해 먼저 서버를 만들어서 → 수행하고 → 서버를 죽임
- 과금이 적게 들 것 같지만, 과금이 진짜 오지게 많이 듦 → 사용에 있어 경제성 계산이 꼭 필요
- 사용 예시로는 가장 가깝게는 Vercel 을 통해 Next.js 배포 시 모든것이 Serverless 로 돌아감
- 다른 예시로는 백엔드 서버 로직 중 호출 횟수가 적은데, 자원이 생각보다 큰 작업의 경우 Serverless 로 처리
- 웹 서버에게 필요로 하는 Memory 자원은 100MB 인데 웹 서버 작업 중 이미지 관련 로직(함수)을 써야하는 Memory 자원은 1GB 라면 웹 서버에서 해당 로직을 수행하기 위해 하루에 단 몇 번의 호출을 위해 1GB Memory 로 배포
- 그래서 이미지 작업만 Serverless Function (1GB Memory) 으로 수행한다면 웹 서버는 불필요하게 높은 자원으로 배포할 필요가 없음
- 그래서 이미지 작업만 Serverless Function (1GB Memory) 으로 수행한다면 웹 서버는 불필요하게 높은 자원으로 배포할 필요가 없음
- 웹 서버에게 필요로 하는 Memory 자원은 100MB 인데 웹 서버 작업 중 이미지 관련 로직(함수)을 써야하는 Memory 자원은 1GB 라면 웹 서버에서 해당 로직을 수행하기 위해 하루에 단 몇 번의 호출을 위해 1GB Memory 로 배포
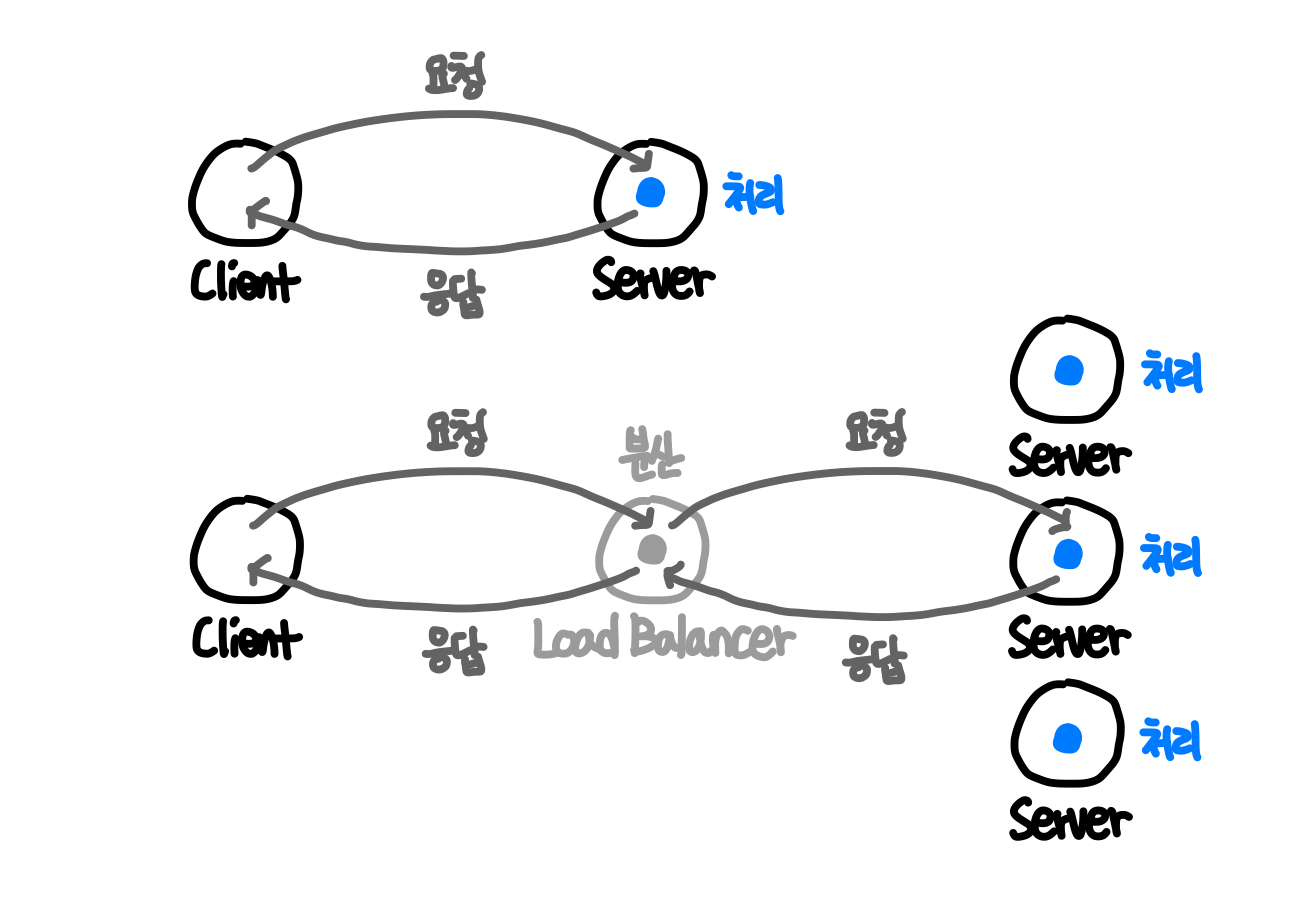
Load Balancer : 대량 트래픽에 의한 서버 부담 분산
트래픽 분산
가장 기초적으로 단 한개의 웹 서버를 통해 우리의 웹 어플리케이션 서비스를 제공하는 경우 두 문제가 발생
- 대량의 트래픽이 한개의 웹 서버에 집중되는 경우
- 한개의 웹 서버가 트래픽을 감당하지 못해 터짐 → 수직적 확장 혹은 수평적 확장이 필요
- 새 버전의 웹 어플리케이션을 배포 시
- 새로운 웹 서버에 배포하는 경우 IP 가 변경
- 기존의 웹 서버에 배포를 하더라도 기존 버전을 정지하고 새 버전을 구동하는 동안 유저는 사용 불가
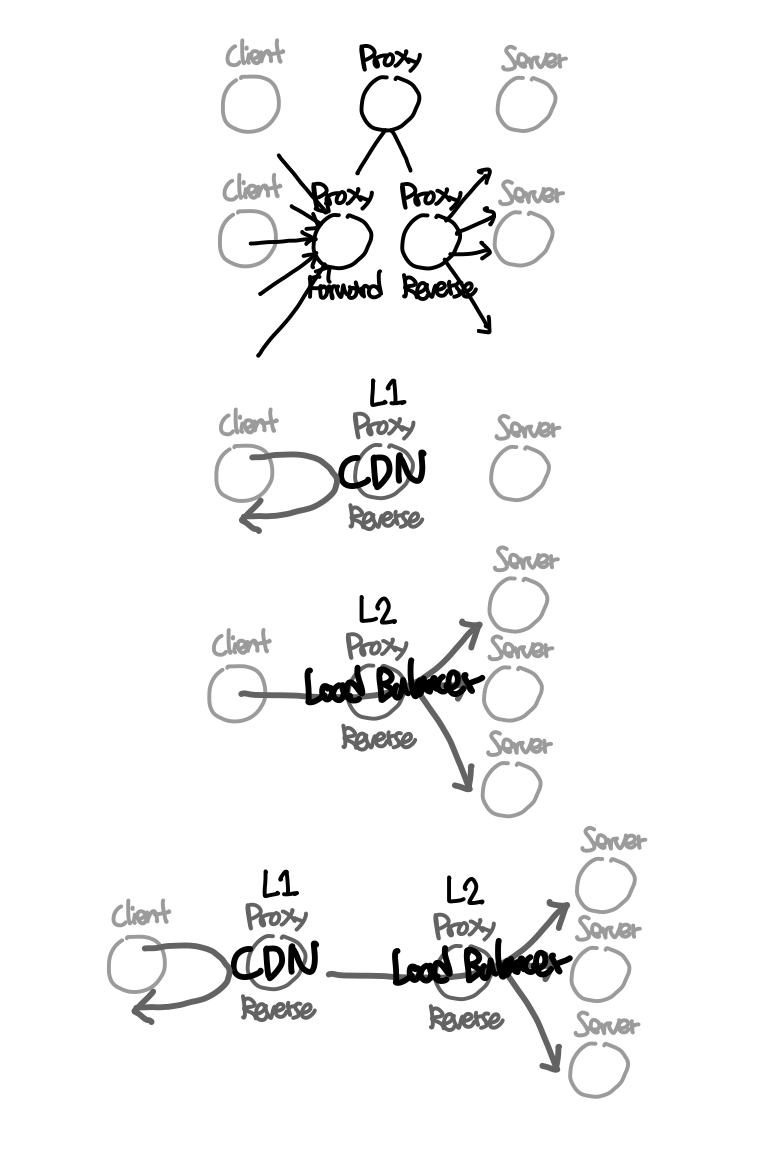
CDN = L1 Reverse Proxy
CDN → 캐싱 + 지역성 해결
- 캐싱 : 요청에 따른 응답을 중간 저장한 뒤 동일 요청 시 저장값 반환
- 원본 데이터를 가진 웹 서버에 문제가 생기면 CDN 가 대신 응답을 반환하여 고가용성 보장
- CDN : 고가용성을 보장해주는 버퍼의 역할
- 원본 데이터를 가진 웹 서버에 DDoS 공격이 가해지는것을 CDN 이 대신 방어
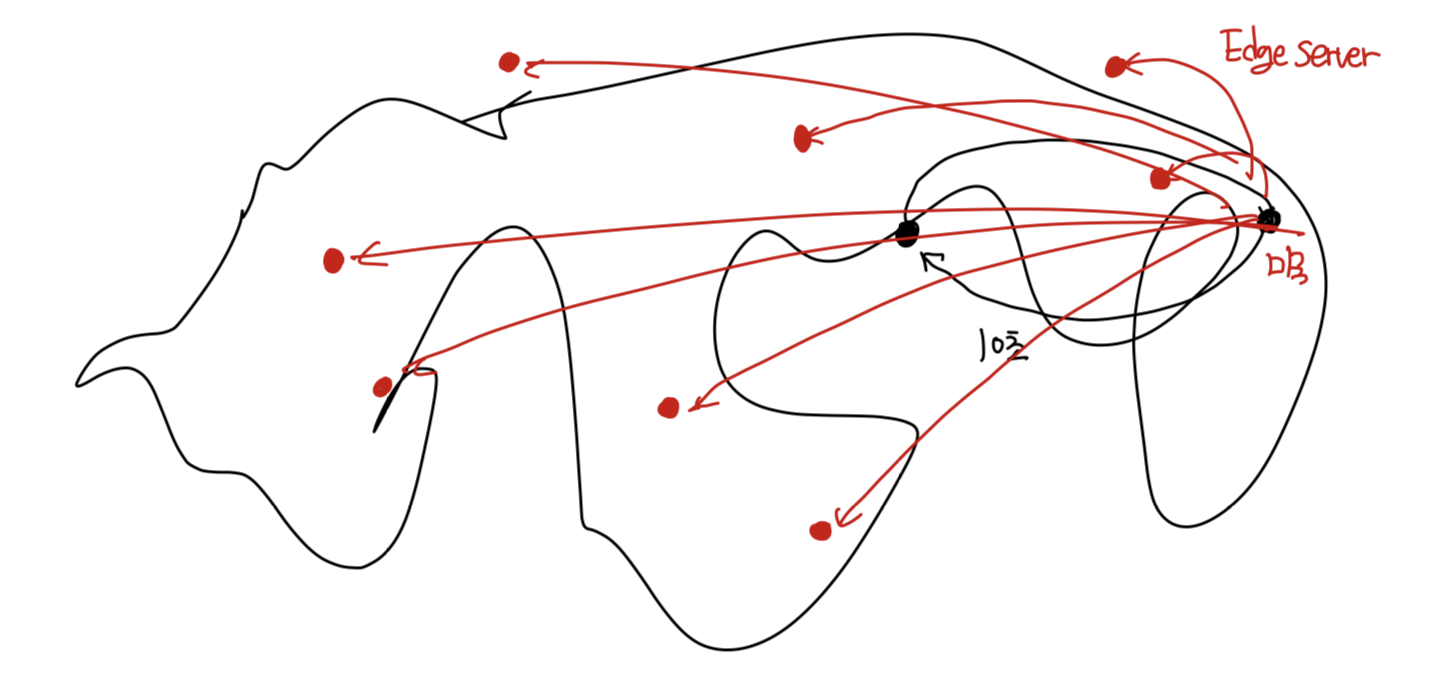
- 지역성 해결 : HTTP Resource 제공 서버와 클라이언트가 멀리 떨어진 경우 클라이언트에 가까운 곳에 저장
- 한국 웹 브라우저에서 미국 웹 서버로부터 응답을 받으려면 긴 응답시간
- 전세계적으로 캐시 서버를 곳곳에 두어 캐시 서버 내 응답 데이터를 캐싱(저장)한다면 속도 개선
- 캐시 서버로 동작하는 만큼 원 서버에 문제가 생기면 CDN 이 False Tolerance 즉, 장애 허용을 해주기도 함
Load Balancer = L2 Reverse Proxy
로드밸런서를 웹 서버의 앞단에 두고, IP 를 부여한 뒤 웹 클라이언트가 해당 로드밸런서를 호출하게 하면
- 로드밸런서는 앞단의 모든 웹 클라이언트의 요청을 받아, 뒷단의 모든 웹 서버에게 요청 분산
- 배포 이슈 해결 : 클라이언트는 고정된 IP 의 로드밸런서만 호출하기에 웹 서버가 몇 개든 죽든말든 노상관
- 트래픽 이슈 해결 : 아무리 많은 요청이 들어와도 로드밸런서 뒷단에 서버 수만 늘리면 가능 (수평적 확장)
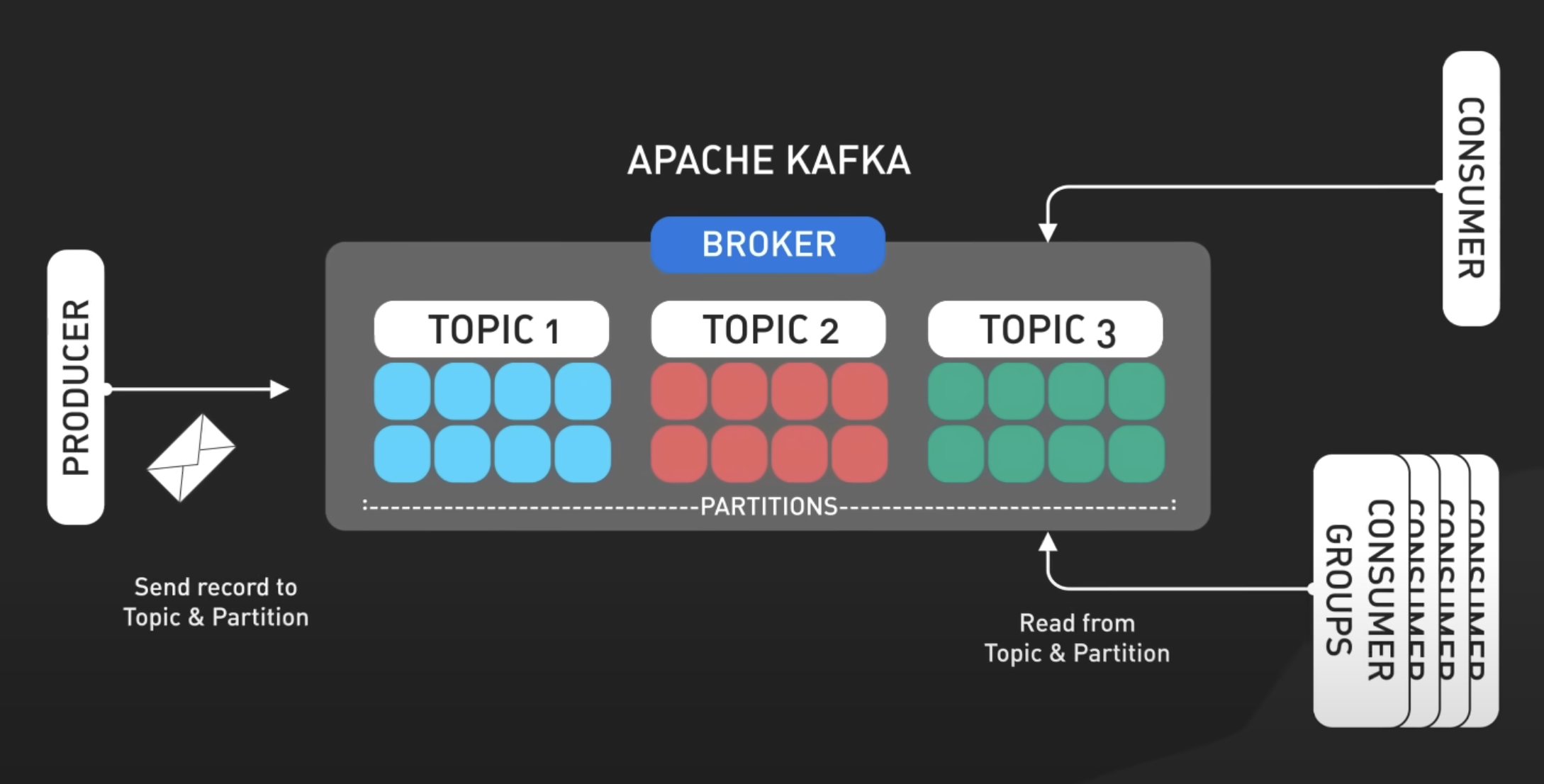
메세지 큐를 통한 요청 트래픽에 대한 비동기 처리
로드밸런서를 통해 웹 서버 개수를 늘려 트래픽에 대응하는 것 → 요청들을 동기적으로 처리
실시간으로 동기적 처리가 필요한 것이 아니라면 비실시간으로 비동기로 처리 방법도 존재
- 모든 요청들을 가운데에 한 바구니(메세지 큐)에 담아놓고
처리자(서버)가 처리할 여유가 생겼을 때 바구니에 담긴 요청을 하나씩 가져가 처리메시지 큐(Message Queue) 통신 방식은 중간에 메세지 큐를 두고 Producer/Consumer 를 가짐
- Producer : 메세지(요청)를 발행
- Queue : 메세지를 저장하는 버퍼
- Consumer : 메세지(요청)을 처리

- 메시지 큐(Message Queue) 장점
- Asynchronous 비동기 : Queue 라는 메세지를 저장하는 버퍼(임시 저장소)가 있기 때문에 나중에 처리 가능
- Resilience 탄력성 : Consumer 서비스가 다운되거나, 문제가 생겨도 다시 살아나서 메세지를 소비만하면 됨 (Fault Tolerance)
- Scalable 확장성 : Producer 가 많아져도, Consumer 가 적어도 서비스를 원하는대로 확장 가능
- Loosely Coupled 낮은 결합도 : Consumer 와 분리되어 있어 Consumer 에 문제가 생겨도, 구현체가 바뀌어도 상관 없음 (Decouple Sender and Receive)
- Guarantees 보장성 : Queue 안에 있는 모든 메시지는 Consumer 서비스에서 처리됨을 보장
결국 서버의 수가 아무리 적어도, 많은 요청들을 다 처리할 수 있다는 것
→ 로그나 매트릭과 같이 실시간 처리가 필요하지 않은 빅데이터 수집이나 분석 작업에 적합
- 유명한 메세지 큐 서비스로는 Kafka, RabbitMQ, AWS SQS 가 존재 → 각각의 차이
- Kafka : Topic 기반으로 메세지들을 나누어담고, 메세지는 실제론 소비되는것이 아니라 오프셋만 변경
- Queue 는 Broker 집단의 Cluster 로 동작되며, Broker 집단은 Zookeeper 로 관리
- 장기적으로는 Non-Persistence Messaging 이기에 개별 저장소에 연결하여 백업 필요
- RabbitMQ : AMQP, Stomp, MQTT 프로토콜을 지원하며, 메세지는 실제로 소비되면 바로 삭제
- 다중 노드를 통한 Load Distribution 으로 High Availability 보장
- AWS SQS : 자체적으로 메세지를 추적할 수 있는 콘솔 제공
- Kafka : Topic 기반으로 메세지들을 나누어담고, 메세지는 실제론 소비되는것이 아니라 오프셋만 변경
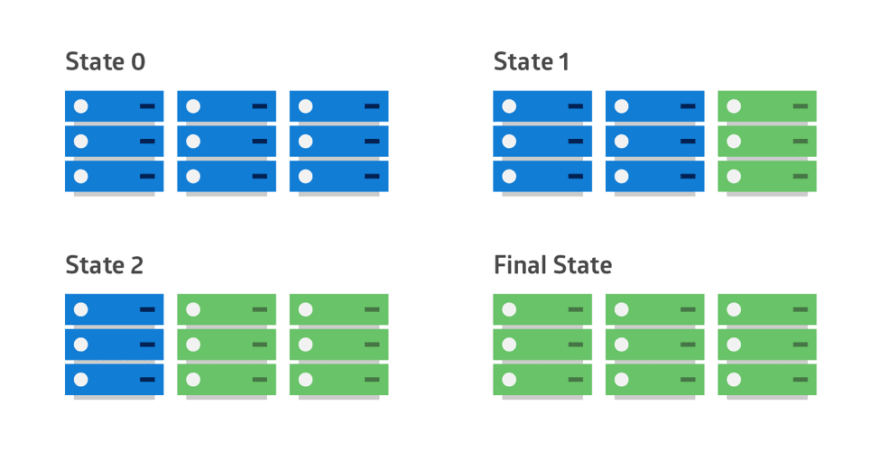
다수 트래픽에 대한 안정성/가용성 SRE(Site Reliability Engineer) 을 위한 다양한 배포 방법
배포의 종류 : Rolling / Canary / Blue-Green 방식
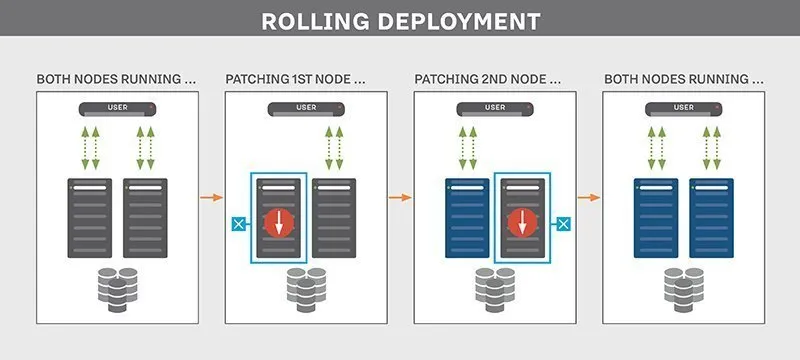
1️⃣ Rolling 배포 방식
: 구버전 하나 죽이고 → 신버전 하나 살리고 → 반복 | 버전 간 트래픽이 섞임 (비의도적)
- + Rolling with Additional Batches 방식 : 트래픽에 대한 기존 인스턴스 수(Capacity) 유지 (출처)
- + Immutable 배포 방식 : 그룹(후에 배울 ASG)을 기준으로 구버전 / 신버전 구별 및 배포, 전환 (출처)
이미 갖고있는 인스턴스 수 안에서 점진적 배포라 추가 비용발생이 없으나,
인스턴스에 트래픽이 몰리는 문제
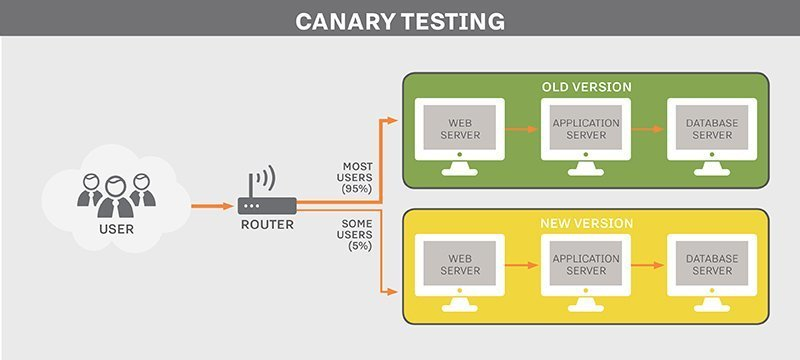
2️⃣ Canary 배포 방식
: 까나리카노 신버전 테스트 후 → 신버전 전체 전환 | 버전 간 트래픽이 섞임 (의도적, 테스트의 목적)
버전 간 트래픽이 섞이는 특징 덕분에 : A/B 테스트나 성능 테스트에 굉장히 용이
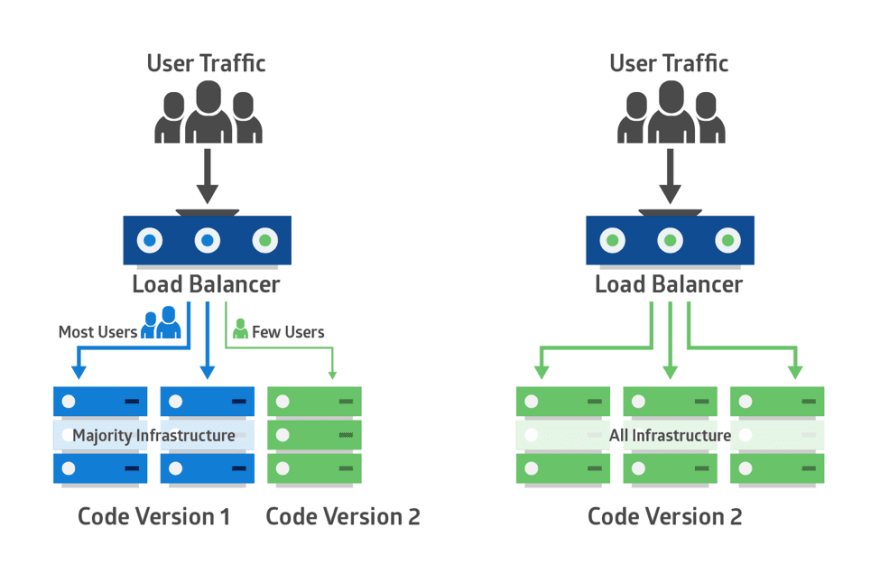
3️⃣ Blue-Green 배포 방식
: 그룹을 기준으로 구버전 / 신버전 구별하며, 문제 발생 시 즉시 롤백이 가능
일반적으로 Canary + Blue-Green 방식을 합쳐 배포하며, Blue-Green 이 Canary 개념을 내포하기도함
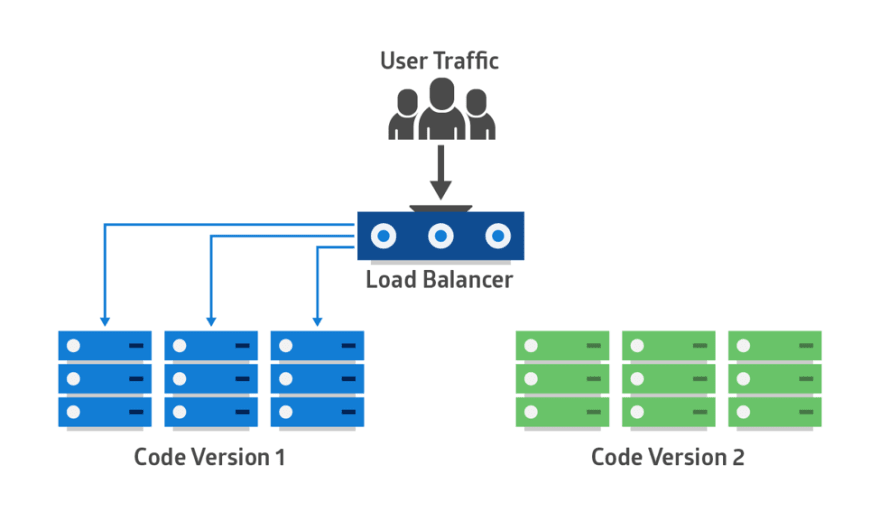
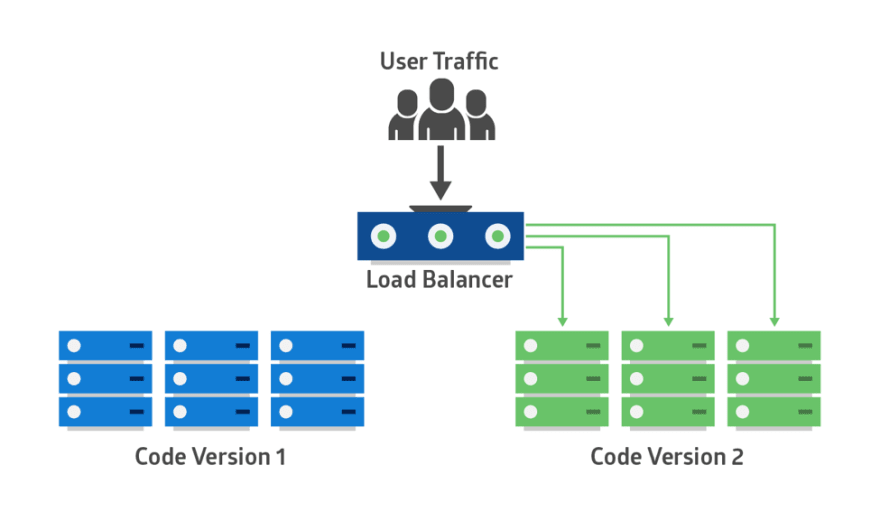
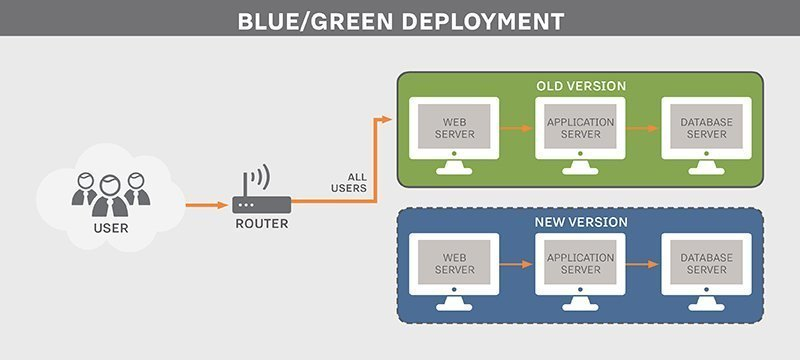
Canary + Blue-Green 방식을 합친 배포 사례
빅테크 기업에서는 Canary 배포 + Blue-Green 배포 두 전략의 각 장점만 합쳐 혼합 사용
