학습목표
- 단어 유사도 분석을 할 수 있다
- 유사도 개념을 이해 할 수 있다
- 워드임베딩 개념을 이해하고 활용 할 수 있다
유사도(Similarity)
💠 Euclidean Distance
- 피타고라스의 정리를 기반으로 두 점의 거리를 계산하는 알고리즘
- 거리 값이 가까울수록 유사하다고 판단한다
- 희소한(sparse)한 데이터에서는 잘 동작하지 않음
- Data scale에 민감하게 동작한다
- 두 점이 가까우면 추첨, 가깝지 않으면 비추천
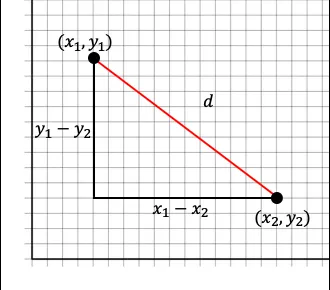
# 유클리디언 유사도 공식
# 피타고라스 정의를 이용한 공식
import numpy as np
def euclidean_sim(A, B):
return ((A-B)**2).sum()**0.5
doc1 = np.array([0,1,1,1])
doc2 = np.array([1,0,1,1])
doc3 = np.array([3,0,3,3])
# doc2과 doc3는 같은 단어를 사용하나 빈도만 다르다.
# 같은 단어를 사용하는 문서일 경우 유사할 확률이 큰데,
# 1-2의 유사도와 2-3의 유사도를 비교했을 때 1-2이 높은 이유?
# [주의] 다른 단어를 사용하지만 빈도수가 같다고 유사도가 더 높게 나타날 수 있다.
# 데이터 스케일에 민감하다.
print('문서 1과 문서2의 유사도 :',euclidean_sim(doc1, doc2))
print('문서 1과 문서3의 유사도 :',euclidean_sim(doc1, doc3))
print('문서 2와 문서3의 유사도 :',euclidean_sim(doc2, doc3))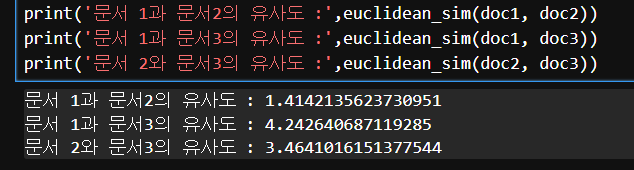
💠 Cosine Similarity
- 두 벡터 사이 각도의 코사인으로 유사성을 계산
- -1~1 사이의 값을 가짐
- 문장의 길이, 단어의 빈도수 등에 덜 민감하게 동작
- 방향성을 중요시하는 유사도
- 방향이 같다면 유사하다 하고, 방향이 다를수록 유사하지 않다
- 둘의 사잇각이 적으면 적을수록 유사하다.
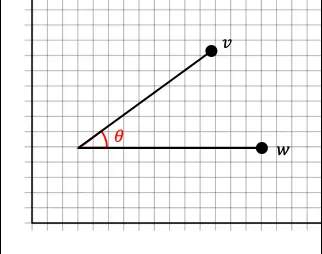
# 코사인 유사도 공식
import numpy as np
from numpy import dot
from numpy.linalg import norm
def cos_sim(A, B):
return dot(A, B)/(norm(A)*norm(B))
doc1 = np.array([0,1,1,1])
doc2 = np.array([1,0,1,1])
doc3 = np.array([3,0,3,3])
print('문서 1과 문서2의 유사도 :',cos_sim(doc1, doc2))
print('문서 1과 문서3의 유사도 :',cos_sim(doc1, doc3))
print('문서 2와 문서3의 유사도 :',cos_sim(doc2, doc3))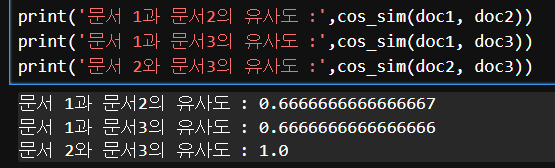
💠 워드임베딩(Word Embedding)
- 인공지능 학습을 이용해서 단어를 수치화 하는 기법
- 지정된 벡터공간에 단어의 정보를 표현하는 숫자를 이식한다
- (빈도 (BOW, TF-IDF)를 이용한 유사도 측정은 순서를 고려하지 않음 그래서 필요한 워드임베딩)
▶ Word2vec 모델을 사용
- 문장이 구성될 때 근처에 배치된 단어끼리는 관련이 있다.
!pip install gensim
import pandas as pd# 데이터로딩
data = pd.read_csv("./data/naver_shopping.txt", delimiter="\t", header=None)
data# 문장에서 명사와 형용사만 추출하기
from kiwipiepy import Kiwi
kiwi = Kiwi() # 형태소분석기 객체 생성🥝 품사 태그
https://github.com/bab2min/Kiwi?tab=readme-ov-file#%ED%92%88%EC%82%AC-%ED%83%9C%EA%B7%B8
from tqdm import tqdm# 명사, 동사, 형용사 추출 (NNG, VV, VA)
total = [] # 형태소로 분리된 문장이 들어갈 리스트
for doc in tqdm(data[1]) : # 전체데이터 반복
rs = kiwi.tokenize(doc) # 형태소로 분리
temp = []
for token in rs : # 한 문장에서 쪼개진 토큰을 확인
if token.tag in ['NNG', 'VV', 'VA'] :
temp.append(token.form) # 단어토큰 리스트에 추가
total.append(" ".join(temp)) # 전체리스트에 추가# 피클 파일로 저장해놓기
import pickle
with open("./naver_morphs.pkl", "wb") as f :
pickle.dump(total,f)from gensim.models import Word2Vecw2v = Word2Vec(window=3, # 인접된 단어의 영역을 결정하는 수
min_count=5, # 학습 단어로 결정하기 위한 최소 등장 횟수
vector_size=50, # 학습을 통해 임베딩할 단어의 숫자 크기(정보량)
sg=1, # 학습방법(딥러닝때 설명 듣기)
sentences=[doc.split(" ") for doc in total]) # 학습시킬 문장택배 = w2v.wv.get_vector("택배") # 원하는 단어 넣기
배송 = w2v.wv.get_vector("배송") # 원하는 단어 넣기
민트 = w2v.wv.get_vector("민트") # 원하는 단어 넣기 cos_sim(택배, 배송)cos_sim(택배, 민트)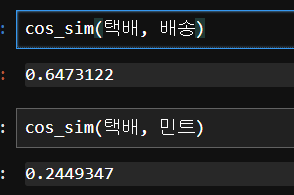
w2v.wv.most_similar("배송", topn=20)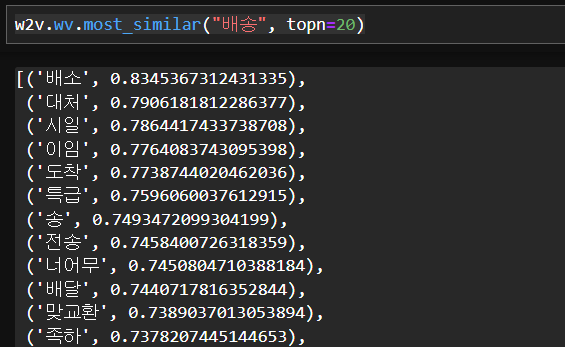
# 네트워크 그래프 시각화
!pip install pyviskeyword = "배송"
rs = w2v.wv.most_similar(keyword, topn=20)from pyvis.network import Network
from IPython.display import HTMLnet = Network(notebook=True)
net.add_node(keyword) # 메인 키워드 노드 추가
for word, sim in rs :
net.add_node(word) # word2vec을 이용해 도출한 연관단어 추가
net.add_edge(word,keyword, value=sim) # 메인키워드와 연관단어의 연관성을 연결
net.show('my_gragh.html')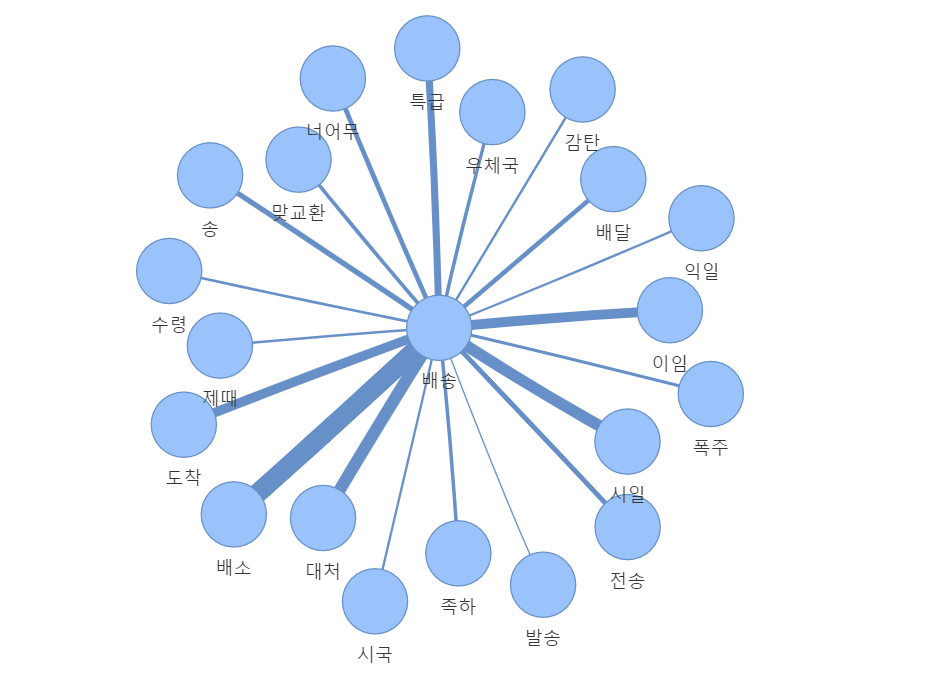

Hello, World!