팀스터디
아티클스터디
선정 아티클
개인 요약
-
엑셀 > 데이터의 기록과 관리가 목적
-
RDBMS와의 공통점
- 파일, 시트, 표의 개념 및 구조 = DB, 테이블, 행과 열
- 관계형
- 파일, 시트, 표의 개념 및 구조 = DB, 테이블, 행과 열
-
차이점
- 마우스 클릭과 단축키 vs 명령어
- 사용자에게 모든 권한 vs 권한 제한
-
주요포인트 : 우리는 이미 엑셀로 데이터를 다루고 있다
인사이트
- 누구나 할 수 있는 것으로 소개하면서 동시에 전혀 경험해보지 않은 무엇인 것처럼 소개한다’는 부분에 공감이 되었습니다. 그렇다고 회사에서 했던 업무 내용을 ‘데이터분석가’로서의 포트폴리오로 쓸 수 있냐고 하면 잘 모르겠습니다.
- 그렇게 생각해보면 어느 정도 경계가 분명한 것 같은데, 데이터를 좀 더 전문적이고 고급진(?) 스킬을 활용해 해석하는 것만이 데이터 분석가일까요? 생각할 거리를 던져준다는 점에서 좋은 아티클인 것 같습니다.
팀원 공통 인사이트
엑셀과 RDMBS의 공통점과 차이점을 알게 되었다!
개인스터디
통계야 놀자 2회차
✅ 이번 수업에서 배우는 것
용어정리
| 용어 | 설명 |
|---|---|
| 변수 | 측정 가능한 대상의 속성 (예: 나이, 성별, 클릭 여부 등) |
| 독립변수 | 원인이 되는 변수 (설명변수) ex) 버튼 색상 |
| 종속변수 | 결과가 되는 변수 (반응변수) ex) 클릭 여부 |
| 모수 | 모집단의 대표값 (평균, 비율 등) |
통계적 실험
"모든 까마귀는 검정색이다" 라고 말하고 싶지만,
세상 모든 까마귀를 확인할 수 없음
표본을 보고 모집단을 추론
이 과정이 통계적 실험!
정의
어떤 목적을 가지고 데이터를 수집 → 관찰 → 결론 도출
목적
전수조사 불가능한 현실에서, 진실에 가까운 추론 하기
흐름
가설 세우기 → 실험 설계 → 데이터 수집 → 추론 → 결론
A/B테스트
대표적인 실험 설계 방식
1️⃣ 고객 니즈 파악
2️⃣ 최소 투자 최대 이익 창출(ROI상승)
예시
- A버튼: 파란색
- B버튼: 빨간색
→ 누가 더 많이 클릭하나?
목적
- UI/UX 개선 → 이탈 감소
- 전환율 증가 → 뭐가 효과 있었는지 알 수 있음
- 매출 증가 → 충성도 & 반복 구매로 이어짐
주요지표
가입률, 재방문율, CTR, CVR, ROAS, eCPM
- CTR 노출 대비 클릭률
- CVR 클릭 대비 전환율, 구매전환율
- ROAS 캠페인 비용 대비 캠페인 수익
- eCPM 1,000회 광고 노출당 얻은 수익
주의사항
- 적절한 표본 수 확보 (적으면 의미 없음)
- 하나의 변수만 변경 (두 개 이상❌)
- 실험군/대조군 무작위로 나누기
- 정해진 기간 동안만 테스트
- 의미 해석에 유의
- 적절한 분석 방법 선택
- 분석 방법 비교

- 분석 방법 비교
가설검정
실험이 끝난 뒤 통계적으로 의미 있는가 를 따지는 것
귀무가설(H₀)
버릴 것을 예상하는 가설
차이 없다 (기존 그대로)
대립가설(H₁)
귀무가설에 대립하는 명제
차이 있다 (변화 있음)!
유의수준 α
신뢰수준의 반대 개념
귀무가설이 맞을때 잘못 기각할 확률
= 귀무가설이 맞을 확률
- 범용적 기준
- 0.05 (5%) - 보통 사용
- 0.01 (1%)
- 0.10 (10%)
*95% 신뢰도를 기준으로 한다면 (1 - 0.95)인 0.05값이 유의수준!
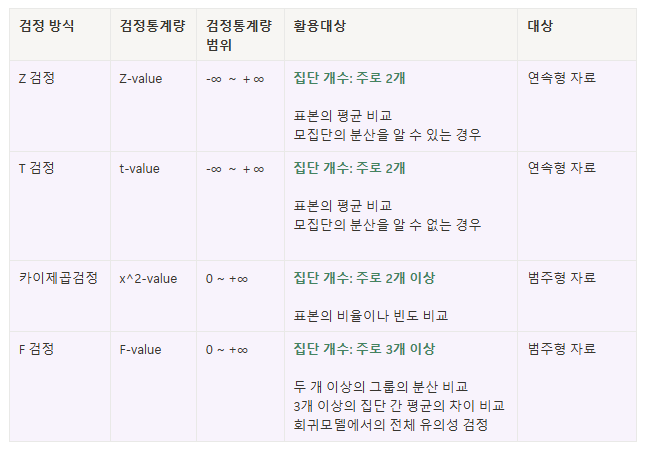
검정통계량 & p-value
| 항목 | 검정통계량 (Z, t 등) | p-value |
|---|---|---|
| 정의 | 귀무가설을 채택 또는 기각하기 위해 사용하는 확률변수 | 그 검정통계량이 나올 확률 값 |
| 역할 | 표본이 얼마나 극단적인지 수치로 표현 | 극단적인 결과가 우연히 나올 확률 |
| 형태 | 보통 Z값, t값, F값, χ²값 같은 수치 | 0 ~ 1 사이의 확률 값 |
| 활용 | 이 수치를 기반으로 p-value 계산 | p-value < 유의수준(0.05) → 대립가설 채택 |
📌 정리
극단적이다 = 평균에서 멀리 떨어졌다
- 검정통계량
- 평균 근처 → 평범한 결과 (귀무가설 유지)
- 평균 멀리 → 드문 결과 (귀무가설 기각 가능성 ↑)
- p-value
- p < 0.05 → 우연 아님! 대립가설 채택 (차이 있다)
- p ≥ 0.05 → 우연일 수도! 귀무가설 유지 (차이 없다)

오늘도 동진님께 감사를..^^
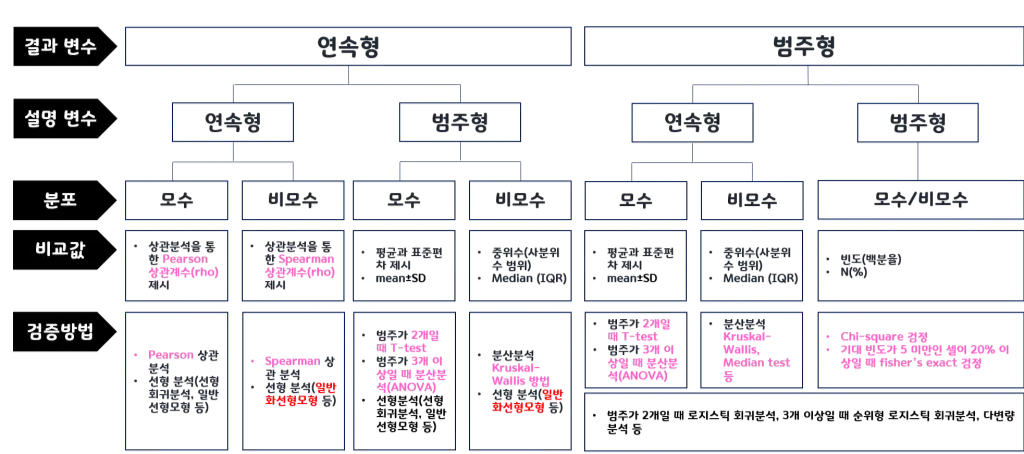
검정방식
☑️ 요약
- 데이터 분석가는 데이터의 종류에 따라 적절한 분석 기법을 선택해야 함
- 대표적인 방법론이 A/B 테스트
- 현행데이터탐색 → 가설설정 → 유의수준설정 → 실험 → 해석
- 귀무가설 차이가 없다, 변화 없음
대립가설 차이가 있다, 변화 있음 - 유의수준(α) 신뢰도 반대 개념, 오류 허용범위
일반적으로 0.05(5%) 사용 - p-value
어떤 사건이 우연하게 발생할 확률
Standard 1,2회차
Long Format vs Wide Format
Long Format
- 하나의 행에 여러 속성이 펼쳐져 있음
- 예시) 사람 A의 키, 몸무게, 혈압이 한 줄에 다 있음
- 주로 Long Format > Wide Format으로 바꾸는 작업을 많이 하게 될 것
| 이름 | 키 | 몸무게 | 혈압 |
|---|---|---|---|
| A | 170 | 60 | 120 |
Wide Format
- 행이 많아지고, 속성을 나눠서 기록
- 분석/시각화용 데이터에서 자주 사용
| 이름 | 항목 | 값 |
|---|---|---|
| A | 키 | 170 |
| A | 몸무게 | 60 |
| A | 혈압 | 120 |
✅ 함수 요약
| 함수명 | 변환 방향 | 설명 |
|---|---|---|
| melt() | Wide → Long | 컬럼을 행으로 녹임 |
| stack() | Wide → Long | 컬럼을 인덱스로 이동 |
| unstack() | Long → Wide | 인덱스를 컬럼으로 이동 |
| .T (transpose) | 행 ↔ 열 | 전체 테이블 전치 |
🟥 Transpose (.T)
df.T- 행/열 위치 바꿈
- 구조 살필때 유용
- head만 출력해서 전치 후 살펴보는 식
- 데이터 크면 느려질 수 있음!
🟧 Pivot Table
pd.pivot_table(
df,
index='A', # 축
columns='B', # 열
values='C', # 값
aggfunc='sum' # or mean, count 등 연산방식
)groupby느낌인데 더 표처럼 보기 좋음- 다양한 집계 가능(
sum,mean,count,max,min, ...)
🟨 Melt
데이터 프레임 재구조화 메서드1
df.melt(
id_vars=['기준 컬럼'],
value_vars=['녹일 컬럼1', '녹일 컬럼2'],
var_name='항목',
value_name='값'
)- 컬럼을 녹여서 Long Format으로 변환
- 피봇 형태의 테이블을 기존 형태로 풀어주는 것
🟩 Stack
데이터 프레임 재구조화 메서드2
df.stack(level=-1, dropna=True)
# level : stack을 수행할 인덱스 레벨 지정 > 마지막 인덱스 레벨 사용
# dropna : 스택 수행 결과에서 결측값 제거 여부- 컬럼들을 인덱스로 밀어넣음
- 멀티인덱스가 생김
- 동시에는 불가
🟦 Unstack
데이터 프레임 재구조화 메서드3
df.unstack(level=-1, dropna=True)- 인덱스를 컬럼으로 다시 펼침
stack의 반대동작- 동시에는 불가
코드카타
Python - 최대공약수와 최소공배수
Python - 3진법 뒤집기
SQL - 헤비 유저가 소유한 장소
일기
- SQL
코드카타 64-65✅ - Python
코드카타 39-40✅ - 통계
세션 1회차 복습✅세션 2회차✅기초강의 3주차❌ - 수준별학습
스탠다드 1-2회차✅

우수 TIL에 선정되었습니다💟
와하하 앞으로도 열심히 써야지 500포인트 너무 달고~~
수업 하루에 세 개 들으려니까 좀 힘들었다
내일 QCC 대비하려면 SQL 코드카타 좀 더 풀고 자야하는데 힘이 너무 빠져서 조금만 쉬었다가 풀어야지.. 😅
내일 QCC 만점 받아보자 파이팅‼️
