개인스터디
QCC 3회차
기본적으로 데이터 조회할때 limit을 둬서 돌리면 좋다고 하심
(데이터 수가 많으니까)
문제 1 ) 임직원 로그인 빈도 분석 🟡
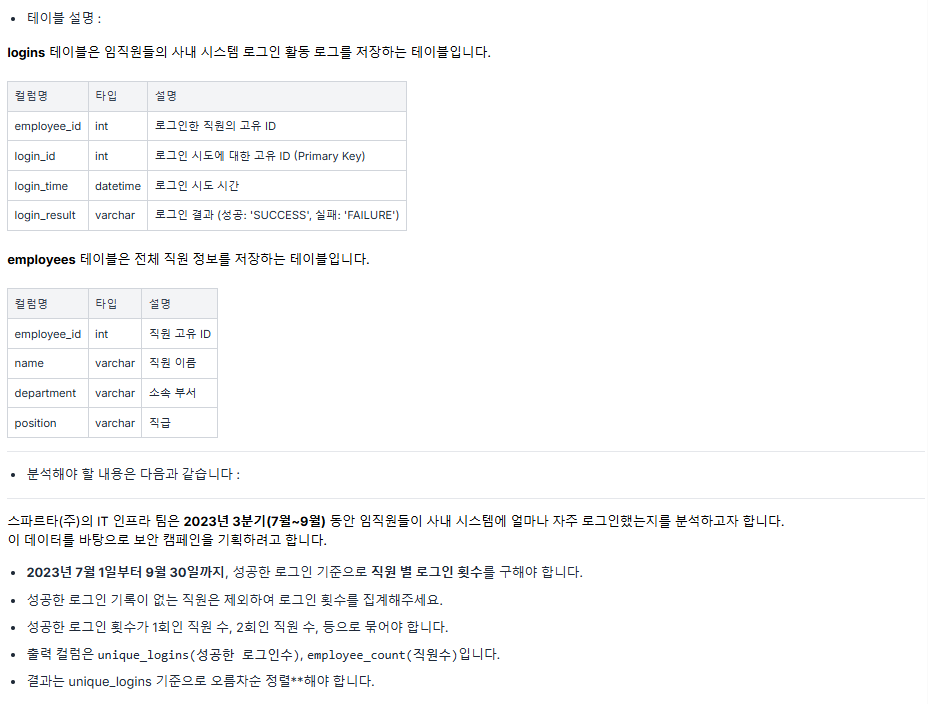
풀이
WITH success_logins AS(
SELECT employee_id,
COUNT(*) AS login_count
FROM logins
WHERE login_time BETWEEN '2023-07-01' AND '2023-09-30' -- 🟡
AND login_result = 'success'
GROUP BY employee_id
)
SELECT login_count AS unique_logins,
COUNT(*) AS employee_count
FROM success_logins
GROUP BY 1
ORDER BY 1오답인 이유
SELECT min(login_time),max(login_time)
FROM logins
WHERE login_time BETWEEN '2023-07-01' AND '2023-09-30'로그인 시간 확인해봤을때 9/30까지 포함이 안 된다 😂 이런 실수를 하다니
1️⃣ 해설
SELECT logins, count(1) employees
from (
select employee_id, count(distinct login_id) logins
from logins
where login_result = 'SUCCESS'
and date_format(login_time, '%Y%m') between '202307' and '202309'
group by employee_id
)a
group by logins
order by logins문제 2 ) 세 번째로 높은 급여를 받는 직원 🟢
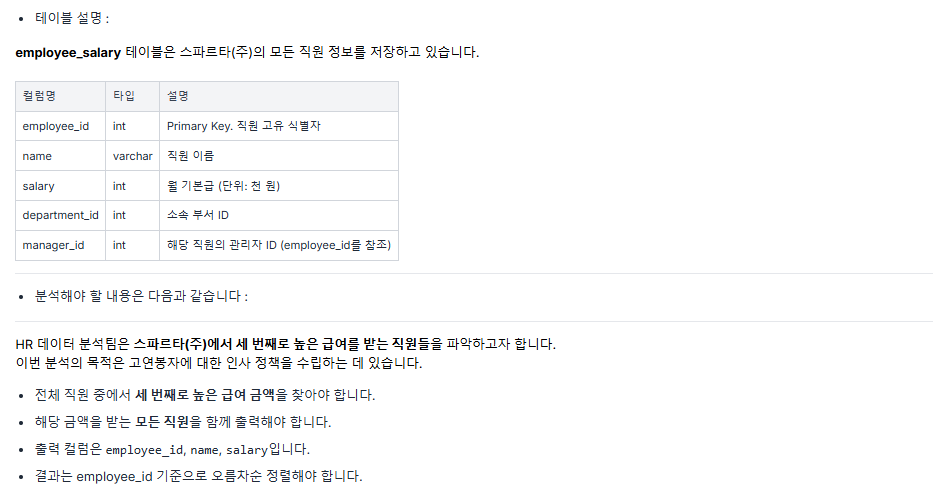
풀이
WITH ranked AS
(SELECT *,
DENSE_RANK() OVER(ORDER BY salary DESC) AS salary_rnk
FROM employee_salary
)
SELECT employee_id, name, salary
FROM ranked
WHERE salary_rnk = 3
ORDER BY employee_id2️⃣ 해설
select employee_id, name, salary
from employee_salary
where salary = (
select distinct salary
from employee_salary
order by 1 desc
limit 1 offset 2
)
order by employee_id offset은 처음 보는 것 같다
문제 3 ) 부서 간 메시지 비율 계산 🟢
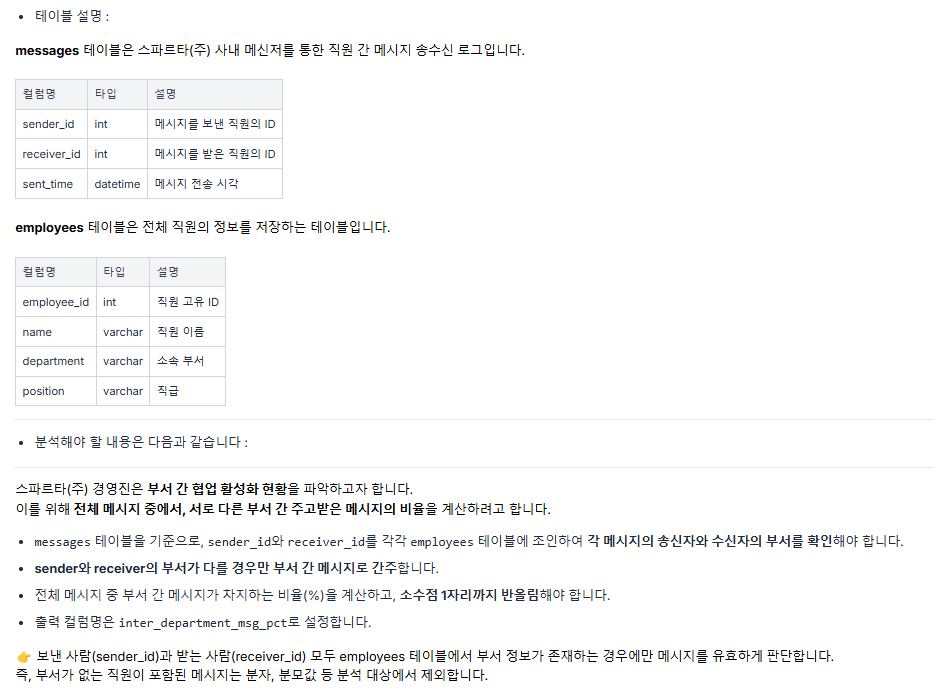
풀이
SELECT ROUND(SUM(CASE WHEN sender.department != receiver.department THEN 1 ELSE 0 END) * 100 / COUNT(*), 1) AS inter_department_msg_pct
FROM messages m
JOIN employees sender ON m.sender_id = sender.employee_id
JOIN employees receiver ON m.receiver_id = receiver.employee_id3️⃣ 해설
SELECT round(sum(if(se.department <> re.department, 1,0)) * 100 / count(1), 1) AS inter_department_msg_pct
FROM messages m
JOIN employees se
ON m.sender_id = se.employee_id
JOIN employees re
ON m.receiver_id = re.employee_id문제 4) 임직원 로그인 빈도 분석 🔴
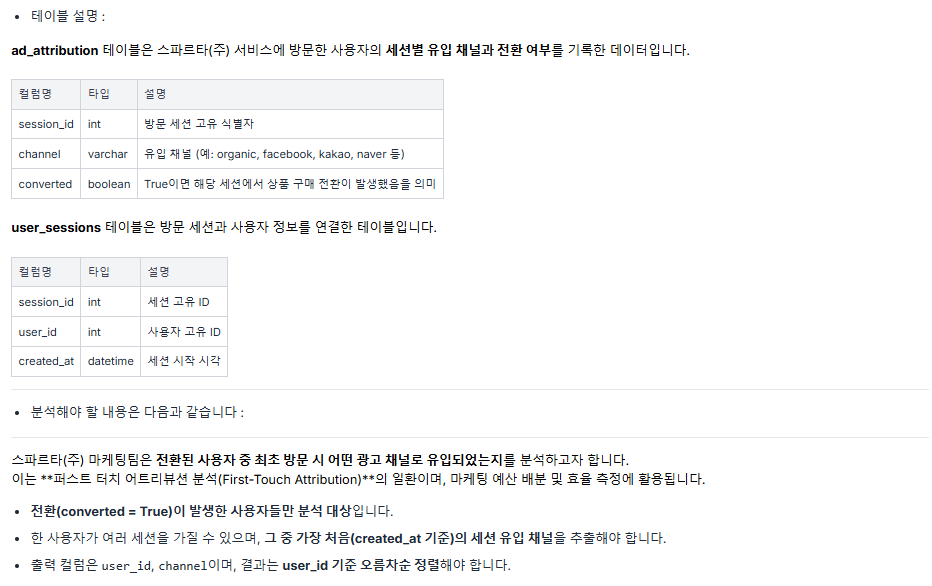
풀이
WITH converted AS(
SELECT DISTINCT user_id
FROM user_sessions s
JOIN ad_attribution a ON s.session_id = a.session_id
WHERE a.converted = 1
)
SELECT s.user_id,
s.session_id,
a.channel
FROM user_sessions s
JOIN ad_attribution a ON s.session_id = a.session_id일단 전환된 유저 ID 구하는 거까진 했는데, 처음 유입한 세션 구하는 거에서 막혔다🥲
converted를 어떻게 활용해야할지 고민하다가 시간이 끝남
4️⃣ 해설
select us.session_id, ad.channel
from
( select *, row_number() over(partition by user_id order by created_at) rn
from user_sessions
) us
join ad_attribution ad
on us.session_id = ad.session_id
where rn = 1
and us.user_id in
(select distinct user_id
from ad_attribution aa
join user_sessions us
on aa.session_id = us.session_id
where converted = TRUE
)
order by user_id
-- 중복 체크
-- group by 1,2
-- having count(1) > 1(+) WITH로 풀어보기
-- 전환된 유저ID 구하기
WITH converted AS(
SELECT DISTINCT user_id
FROM user_sessions s
JOIN ad_attribution a ON s.session_id = a.session_id
WHERE a.converted = 1
),
first_sessions AS (
SELECT s.user_id, s.session_id,
ROW_NUMBER() OVER (PARTITION BY s.user_id ORDER BY s.created_at) AS rn
FROM user_sessions s
WHERE s.user_id IN (SELECT user_id FROM converted)
)
SELECT f.user_id, a.channel
FROM first_sessions f
JOIN ad_attribution a ON f.session_id = a.session_id
WHERE f.rn = 1
ORDER BY f.user_id Standard 3,4회차
윈도우 함수(Window Function)
→ 시계열 데이터 분석할때 자주 씀
→ 전에 뭐였는지, 평균이 얼마였는지, 누적으로 얼마나 쌓였는지
🟥 Shift
데이터를 앞/뒤로 밀기
문법
DataFrame.shift(
periods=이동할기간,
freq=선택 매개변수,
axis=연산 축 방향,
fill_value='결측치대체값'
) df.shift(1) # 한 칸 아래로 (과거 데이터)
df.shift(-1) # 한 칸 위로 (미래 데이터)
df.shift(3, freq='D') # 3일 단위 이동🟧 Rolling
지정된 구간(윈도우) 안의 평균, 합 계산
문법
DataFrame.rolling(
window= 계산할 창 크기→이전 값 부족하면 Nan,
min_periods=계산할 최소 크기(기간),
center=계산을 중간 행에서 할지 결정,
win_type=가중치를 넣어 계산할 경우,
on=시계열 데이터가 있을때 기준 적용,
axis=연산 축 방향,
closed=연산이 닫히는 방향,
method='single')df.rolling(window=3).mean() # 3일 평균
df.rolling(window=3).sum() # 3일 누적합
df.rolling(window=3, center=True).mean() # 가운데 기준🟩 Expanding
처음부터 현재까지 누적 연산
문법
df.expanding(
min_periods=연산 수행 최소갯수,
axis=연산 축 방향,
method='single' 한 줄씩 수행
'table' 전체 테이블 수행).추가메서드()df.expanding().mean() # 누적 평균
df.expanding().sum() # 누적 합상관관계
두 변수 간 관련성 확인
상관계수는 -1 ~ 1 사이
+1강한 양의 관계 (비례)0관련 없음-1강한 음의 관계 (반비례)
⚠️ 인과관계와 다름
🟥 연속형 ↔ 연속형
피어슨 상관계수(Pearson)
df.corr(method='pearson')
- 상관계수
0.9 ~ 1.0매우 강함0.7 ~ 0.9강함0.5 ~ 0.7약간 있음0 ~ 0.5거의 없음
🟧 연속형 ↔ 범주형(이분형)
Point-Biserial Correlation
이분형 변수를 0과 1로 바꾼 다음에 피어슨 상관계수처럼 계산
from scipy.stats import pointbiserialr
r, p = pointbiserialr(df['binary'], df['value'])
r상관계수0.9 ~ 1.0매우 강함0.7 ~ 0.9강함0.5 ~ 0.7약간 있음0 ~ 0.5거의 없음
pp-value- 0.05보다 작으면 유의미
⚠️ p-value도 같이 봐야함
r = 0.4 / p = 0.0001 → 상관 있음 (신뢰 가능)
r = 0.4 / p = 0.2 → 우연일 가능성 있음
🟩 연속형 ↔ 범주형(3개 이상)
ANOVA (분산분석)
from scipy.stats import f_oneway
f_oneway(df[df['group']=='A']['value'], ...)- F 값
< 1무의미1 ~ 3거의 무의미3 ~ 10조건부 유의미10 ~ 50유의미> 50거의 확실한 유의미>= 100확실한 유의미
⚠️ p-value도 같이 봐야함
f = 150 / p = 0.0001 → 매우 큰 차이+유의미
f = 150 / p = 0.2 → 큰 차이처럼 보이지만 신뢰불가
f = 5 / p = 0.01 → 차이는 크지 않지만 유의미
🟦 범주형 ↔ 범주형
Cramer's V 사용
# 범주형 변수 숫자로 바꾸기 (예: 성별 → 0, 1)
from sklearn.preprocessing import LabelEncoder
# 카이제곱 통계량 기반으로 Cramer's V 계산하기 위한 함수 사용
from scipy.stats import chi2_contingency
# Cramer's V는 공식 함수가 없어서 사용자 정의 함수로 계산함
- 크레머 V 계수
0 ~ 0.1: 무시 가능0.1 ~ 0.2약함0.2 ~ 0.4보통0.4 ~ 0.6강함0.6 ~ 0.8매우 강함0.8 ~ 1.0거의 완전한 상관관계
☑️ 요약
Window Function
df.shift(1) # 한 칸 뒤로(전날 데이터 보기)
df.rolling(3).mean() # 최근 3일 평균
df.expanding().sum() # 지금까지 누적합
shift시간 흐름 없이도 적용 가능 (그냥 인덱스 기준)rolling윈도우 크기만큼만 계산 (이전 값 부족하면 NaN)expanding은 무조건 누적이라 NaN 적음
타입별 분석방법
| 변수 조합 | 방법 | 라이브러리 |
|---|---|---|
| 연속 ↔ 연속 | 피어슨(Pearson) | df.corr() |
| 연속 ↔ 범주(2개) | Point-Biserial | scipy.stats.pointbiserialr() |
| 연속 ↔ 범주(3개 이상) | ANOVA | stats.f_oneway() |
| 범주 ↔ 범주 | Cramer's V | chi2_contingency + 사용자 정의 함수 |
ANOVAPoint-Biserial모두 p-value 같이 봐야 유의미한지 판단 가능!
코드카타
SQL - 조회수가 가장 많은 중고거래 게시판의 첨부파일 조회하기
SQL - 주문량이 많은 아이스크림들 조회하기
일기
- SQL
코드카타 66-67✅QCC 3회차✅ - Python
코드카타 41-42❌ - 통계
세션 1-2회차 복습✅ - 수준별학습
스탠다드 3-4회차✅베이직 1회차 문제🔼
QCC 만점 받기가 이번 주 목표였는데 중간중간 서버도 터지고 내 멘탈도 터지고 예.. 1번문제는 맞을 수 있었는데 사소한 거에서 틀리고, 4번문제는 다 풀지도 못해서 아쉬웠따
집중도 잘 안 돼서, 통계 1-2회차 세션 들으면서 복습하다가 수준별학습 들으러 갔당 오늘 배운 것 중에 젤 어려운 건 아무래도 롤링.. 아롤리롤린롤린..
베이직반 알고리즘 문제도 지금 푸는 중인데 생각보다 어렵다 하하 쉬운 게 하나 없구나
주말에 WIL 쓰면서 벨로그 요약해놓은 거 한번씩 다 읽어봐야지
아무튼 오늘은 금요일이니까~ 푹 쉬어야지 이번 주도 고생 많았따😶🌫️
