이전 게시글에서 가중치 초기값 설정에 대해 알아봤다. 각층의 분포에 따라 학습이 원활하게 수행된다는 것을 알 수 있었다.
그런데 학습을 진행하다보면 분포가 계속 바뀐다. 이로 인해 성능에 악영향을 끼칠 수 있다. 그래서 Batch Normalization을 사용하여 적당하게 분포하도록 강제하자는 것이다.
먼저 BN을 사용함으로서 얻을 수 있는 효과를 알아보자
1. 학습속도 개선
2. 가중치 초기값에 영향이 덜하다.
3. 오버피팅이 억제된다.
4. learning rate를 높게 해도 비교적 잘 동작한다.
그럼 어떻게 적용을 하는 것일지 알아보자

위의 그림처럼 먼저 표준 정규분포를 만드는 공식처럼 평균이 0, 표준편차가 1인 분포로 만들고 평균이 표준편차가 인 분포로 바꿔주는 것이다.
(은 분모가 0이 되는 것을 방지하기 위함이다.)
, 는 학습할 수 있는 변수로 최적의 분포를 학습에서 찾아간다고 보면 된다.
단, Test시에는 mini batch의 평균과 분산을 사용할 수 없기 때문에, 고정적인 평균과 분산을 사용하는데, 미니 배치의 이동 평균을 사용하여 해결한다. 분산은 불편 추정량으로 만들어주기 위해 m / (m - 1)을 곱해 보정한다.
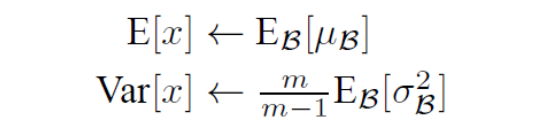
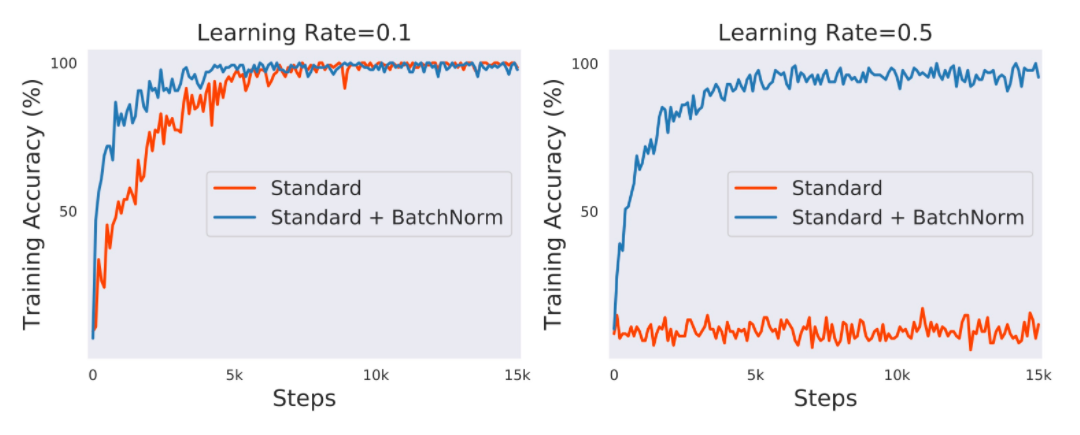
batch_size가 크면 클 수록 training set을 더 잘 표현하고 적을수록 training set을 더 잘 표현하지 못 할 수 있다. 그로인해 noise가 포함되어 일반화에 효과가 있을 수 있지만, GPU환경 등에 따라 너무 적은 batch size를 사용하게 될 경우 문제가 될 수 있다.
참고로 CNN에서는 커널 하나는 같은 , 를 공유한다.
보통 BN적용 위치는 activation 함수 통과전에 적용한다.