딥러닝
1.[딥러닝] weight initialization

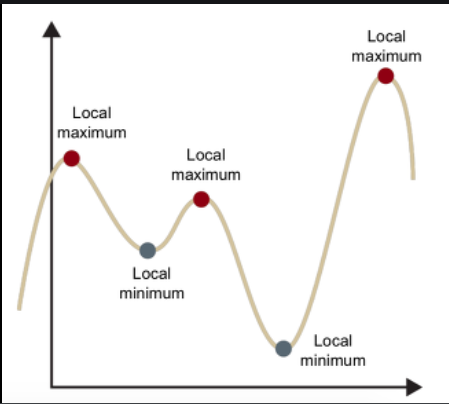
중요할 것 같지 않게 느껴지지만 초기 가중치 설정은 매우 중요하다.초기 가중치를 잘못 설정한다면 local minimum에 수렴할 가능성이 커지거나 gradient vanishing / exploding 혹은 학습이 제대로 이루어지지 않을 수도 있다.0으로 초기화시만약
2.Optimizer
optimizer란 머신러닝에서 backpropagation으로 기울기를 구하여 이를 이용해 가중치를 갱신시키는 것이다.optimizer의 방식에는 여러가지가 있지만 그 중 몇가지만 살펴보도록 하자.1\. Gradient DescentParameter를 W라고 뒀을 때
3.Batch Normalization

이전 게시글에서 가중치 초기값 설정에 대해 알아봤다. 각층의 분포에 따라 학습이 원활하게 수행된다는 것을 알 수 있었다.그런데 학습을 진행하다보면 분포가 계속 바뀐다. 이로 인해 성능에 악영향을 끼칠 수 있다. 그래서 Batch Normalization을 사용하여 적당
4.그레디언트 클리핑
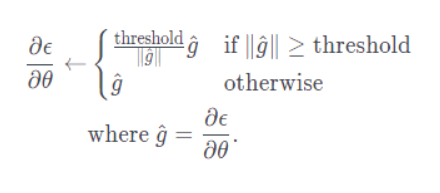
그레디언트 클리핑은 굉장히 간단하다.이름에서부터 유추가 가능한데 그레디언트가 일정 임계값을 넘어가면 clipping을 해주는 것이다.보통 gradient의 L2 norm을 나눠주는 방식을 이용한다.임계값은 gradient가 가질 수 있는 최대 L2 norm을 의미하고
5.Nesterov Momentum

keras의 SGD optimizer를 사용하던 중 nesterov라는 옵션이 궁금해졌다.tensorflow 공식 홈페이지에 들어가 확인했더니 아래를 보니 설명이 나와있었고 기존의 SGD와 momentum은 다뤄봤던 터라 이해하는데 어렵지 않았다.하지만 nesterov
6.엔트로피
엔트로피는 정보를 나타내기 위한 최소 평균 자원량을 의미한다.'ㄱ', 'ㄴ', 'ㄷ', 'ㄹ'을 컴퓨터에서 사용하는 이진수로 나타낸다고 해보자4개니까 0, 1, 10, 11로 나타낼 수 있다사용 빈도수는 'ㄹ', 'ㄷ', 'ㄴ', 'ㄱ'의 순으로 많다고 할 때, 'ㄹ'