💡 Tree Ensemble model
앙상블 모델은 학습 방법에 따라 배깅(Bagging)과 부스팅(Boosting)으로 나뉜다.
배깅은 지난 번 랜덤포레스트에 대해 공부할 때 자세히 포스팅 했으니 확인해보면 된다.
배깅의 대표적인 모델이 랜덤포레스트 였다면, 부스팅의 대표적인 모델은 AdaBoost, Gradient Boost 등이 있다. Gradient Boost의 변형 모델로 XGBoost, LightGBM, CatBoost가 있으며, 실제로도 많이 사용되는 방법이다. 오늘은 XGBoost에 대해서만 배웠는데, 나머지는 점차 공부해서 포스팅 할 계획이다.
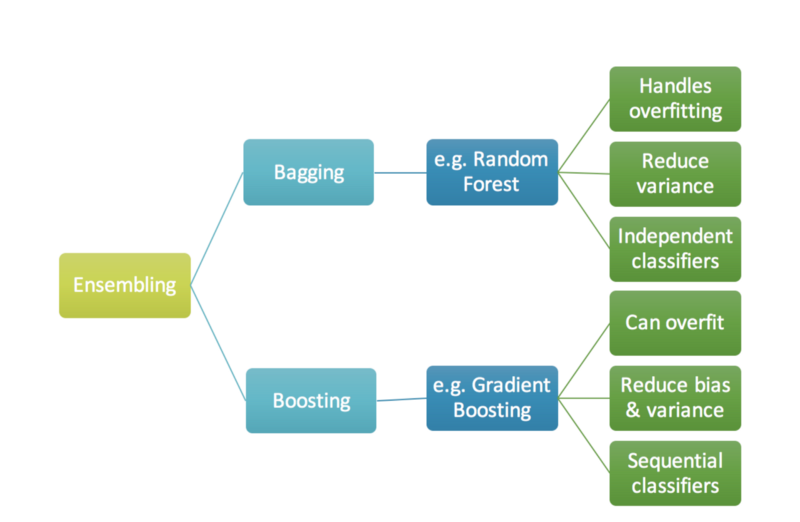
분류문제를 풀기 위해서는 트리 앙상블 모델을 많이 사용한다.
- 트리모델은 non-linear, non-monotonic 관계, 특성간 상호작용이 존재하는 데이터 학습에 적절하다.
- 한 트리를 깊게 학습시키면 과적합을 일으키기 쉽기 때문에, 배깅(Bagging, 랜덤포레스트)이나 부스팅(Boosting) 앙상블 모델을 사용해 과적합을 방지한다.
- 랜덤포레스트의 장점은 하이퍼파라미터에 상대적으로 덜 민감한 것인데, 그래디언트 부스팅의 경우 하이퍼파라미터 셋팅에 따라 랜덤포레스트 보다 더 좋은 예측 성능을 보여줄 수도 있습니다.
⭐ Boosting(부스팅)
부스팅은 앙상블 기법 중 하나로 가중치를 통해 학습하는 방식이다. 처음 모델의 예측 결과에 따라서 데이터의 가중치가 부여되고 이것이 또 다음 모델에 영향을 주는 방식으로 보면 된다.
😶🌫️ Bagging vs Boosting
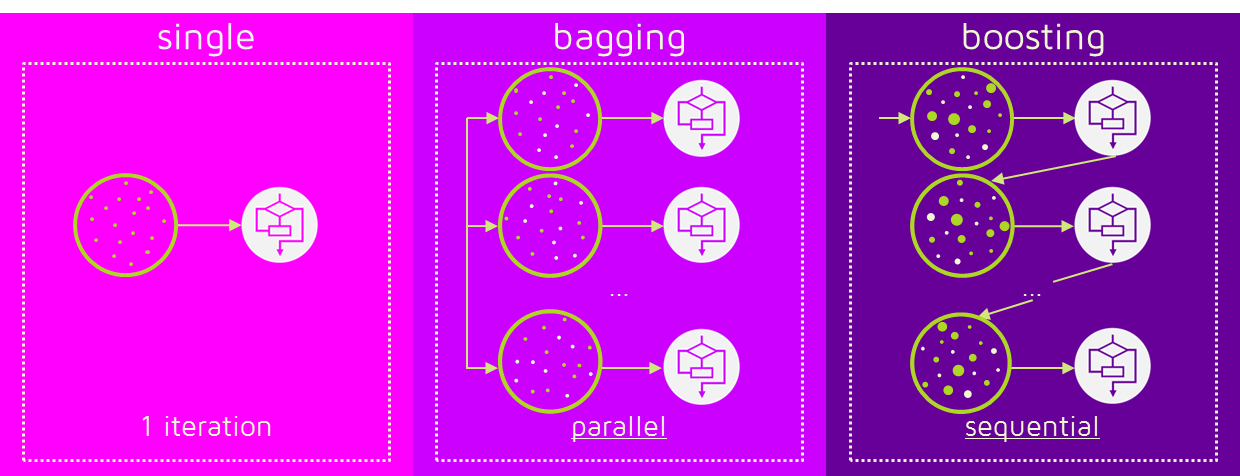
배깅은 독립적인 각각의 트리들이 병렬(parallel)로 학습해서 그 결과를 aggregate한다.
반면에 부스팅은 약분류기를 하나 만든 후 이 트리의 잘못된 값에 가중치를 부여하고, 다음 트리에서 더 잘 분류할 수 있도록 순차적(sequential)으로 학습하는 방식이다. 잘못된 데이터에 가중치를 주면서 연달아 학습하기 때문에 학습속도가 느리고 overfitting risk가 존재한다.
결국 배깅은 분산을 낮추는데 포커스가 있다면, 부스팅은 편향을 낮추는데 집중한다고 볼 수 있다.
그렇다면 언제 어떤 방법을 사용해야 할까? 답은 직면한 문제에 따라 선택해야 한다. 낮은 성능이 문제인 경우는 부스팅을, overfitting이 문제인 경우는 배깅을 선택하는 것이 좋다.
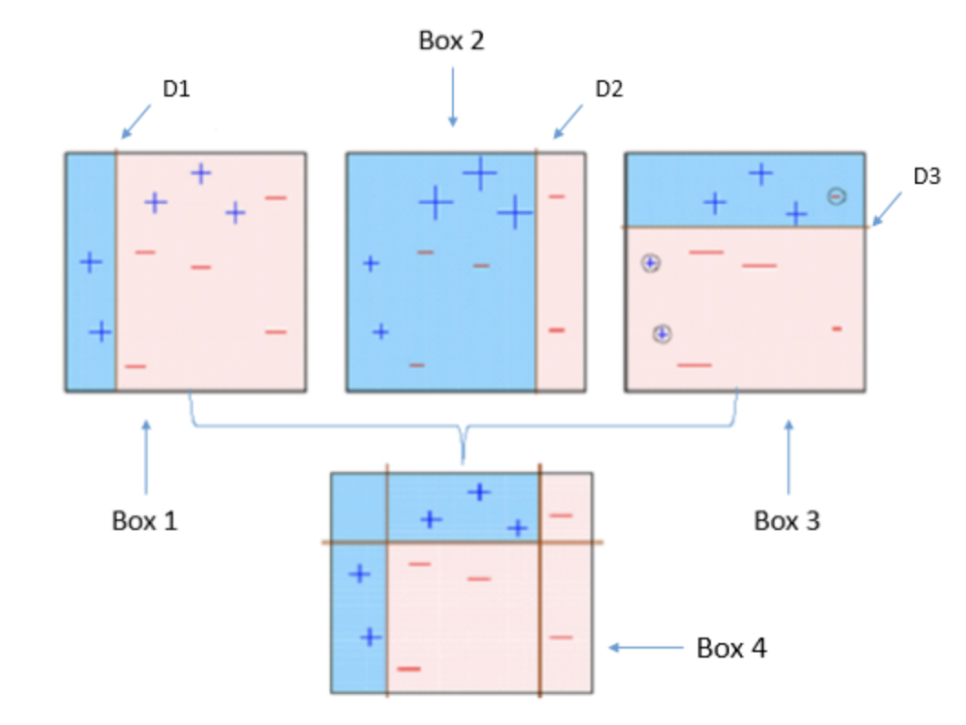
✍️ AdaBoost
Adaboost는 잘못 학습된 데이터에 가중치를 주어 이후 모델을 만들 때 그 값을 관측하는데 더 집중하는 방법이다.
아래 그림에서 Box1의 학습 결과 (+) 3개가 (-)로 잘못 관측 된 것을 확인할 수 있다. 이 값에 가중치를 주어 다시 학습을 시킨것이 Box2이다. 그러나 또 (-) 3개가 잘못 관측이 되었고, 이에 가중치를 더한 뒤 다시 학습시킨 것이 Box3이다.
이러한 방법을 반목해서, 모델을 결합 한 뒤 Box4와 같은 성능이 좋은 모델로 발전시키는 것이 AdaBoost이다.
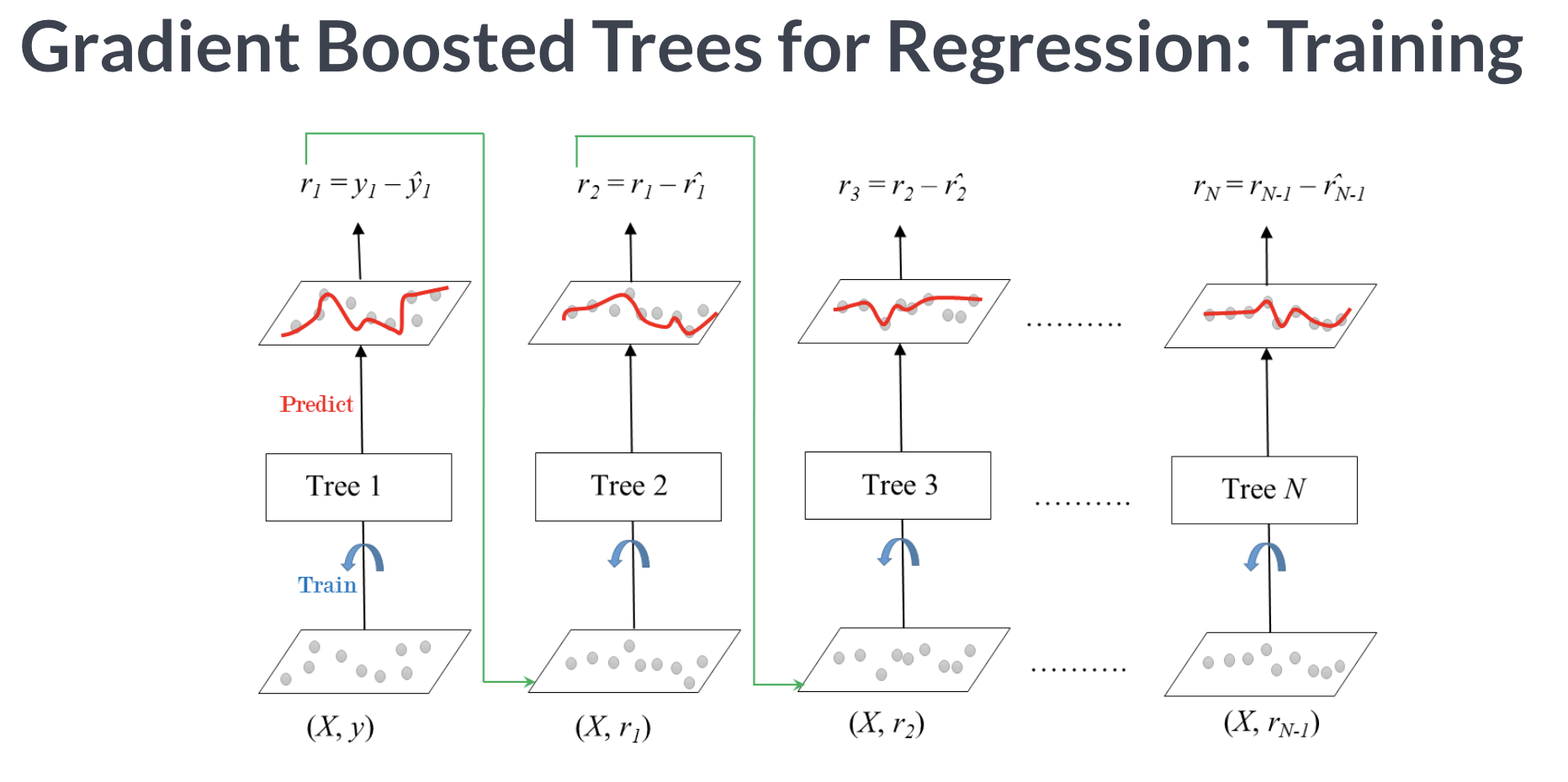
✍️ Gradien Boost
AdaBoost는 잘못 예측된 값에 가중치를 더하는 것이라면
Gradient Boost는 잔차를 학습시키는 방법으로 모델을 발전시킨다.
잔차가 더 큰 데이터를 더 학습하도록 해서 성능이 좋은 모델을 만드는 방법이다.
자세한 gradien boost의 프로세스는 여기서 확인해 보면 된다.
참고로 확인하면 좋은 Gradient Boosting python libraries
scikit-learn Gradient Tree Boosting — 상대적으로 속도가 느릴 수 있습니다.
xgboost — 결측값을 수용하며, monotonic constraints를 강제할 수 있습니다.
Anaconda, Mac/Linux: conda install -c conda-forge xgboost
Windows: conda install -c anaconda py-xgboost
LightGBM — 결측값을 수용하며, monotonic constraints를 강제할 수 있습니다.
Anaconda: conda install -c conda-forge lightgbm
CatBoost — 결측값을 수용하며, categorical features를 전처리 없이 사용할 수 있습니다.
Anaconda: conda install -c conda-forge catboost
😶 XGBoosting
XG Boosting는 Gradient boosting 알고리즘이 가진 이슈(느림, 과적합)을 보완하기 위해 나온 앙상블 모델이다.
- 랜덤포레스트보다 하이퍼파라미터 셋팅에 민감하다
- CART(Classification And Regression Tree) 기반으로 분류와 회귀 모두 가능하다.
- 조기 종료(early stopping) 사용하여 과적합 피할 수 있다.
📖 Python
from xgboost import XGBClassifier
# 파이프라인 구축
pipe = make_pipeline(
OrdinalEncoder(),
SimpleImputer(strategy='median'),
XGBClassifier(n_estimators = 1000 #1000 트리로 설정했지만, early stopping 에 따라 조절됨.
, max_depth = 7
, learning_rate = 0.2 # 높을수록 과적합되기 쉬움
, random_state = 2
, n_jobs = -1
# scale_pos_weight=ratio, # imbalance 데이터 일 경우 비율 적용)
)
pipe.fit(X_train, y_train)
# Early Stopping을 사용하여 과적합을 방지
encode = OrdinalEncoder()
X_train_encoded = encode.fit_transform(X_train)
X_val_encoded = encode.transform(X_val)
xgbc = XGBClassifier(
n_estimators = 1000,
max_depth = 7,
learning_rate = 0.2,
n_jobs = -1
)
eval_set = [(X_train_encoded, y_train),
(X_val_encoded, y_val)]
xgbc.fit(X_train_encoded, y_train,
eval_set = eval_set,
eval_metric = 'error',
early_stopping_rounds = 50)
# 50번 동안 돌렸을 때에도 스코어가 개선이 되지 않는다면 학습을 중단
[out]을 보면 35번째 iteration 이후 성능이 개선되지 않았기 때문에 학습이 중단되며,
35번째 학습 결과가 최적이라고 판단 할 수 있다.
