💡머신러닝(Machine Learning, ML)
- 머신러닝은 데이터에서 규칙을 학습하고, 결과를 예측하는 알고리즘이다.
즉, 사람이 하나부터 열까지 알려주는 것이 아니라, 기계 스스로 데이터를 효율적으로 가공하고, 패턴이나 관계를 찾아 새로운 결과를 예측하는 것.
머신러닝의 정의를 분류하자면 다음과 같다.
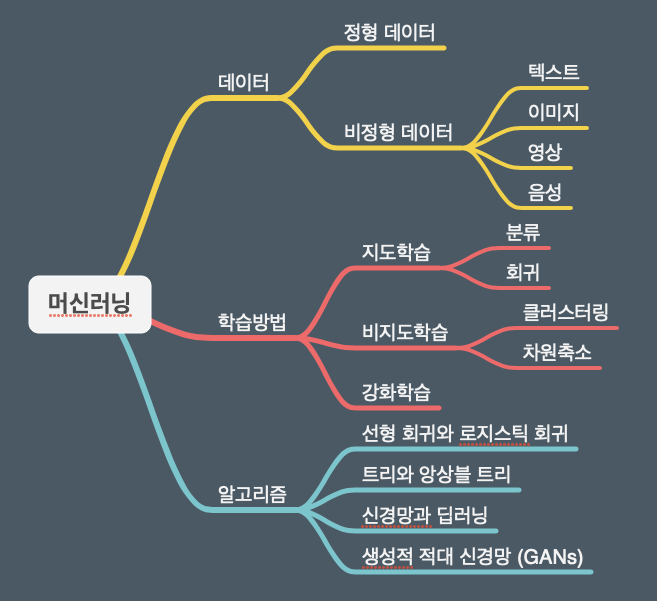
자료출처 : 브런치
🔍 Machine Learning의 분류
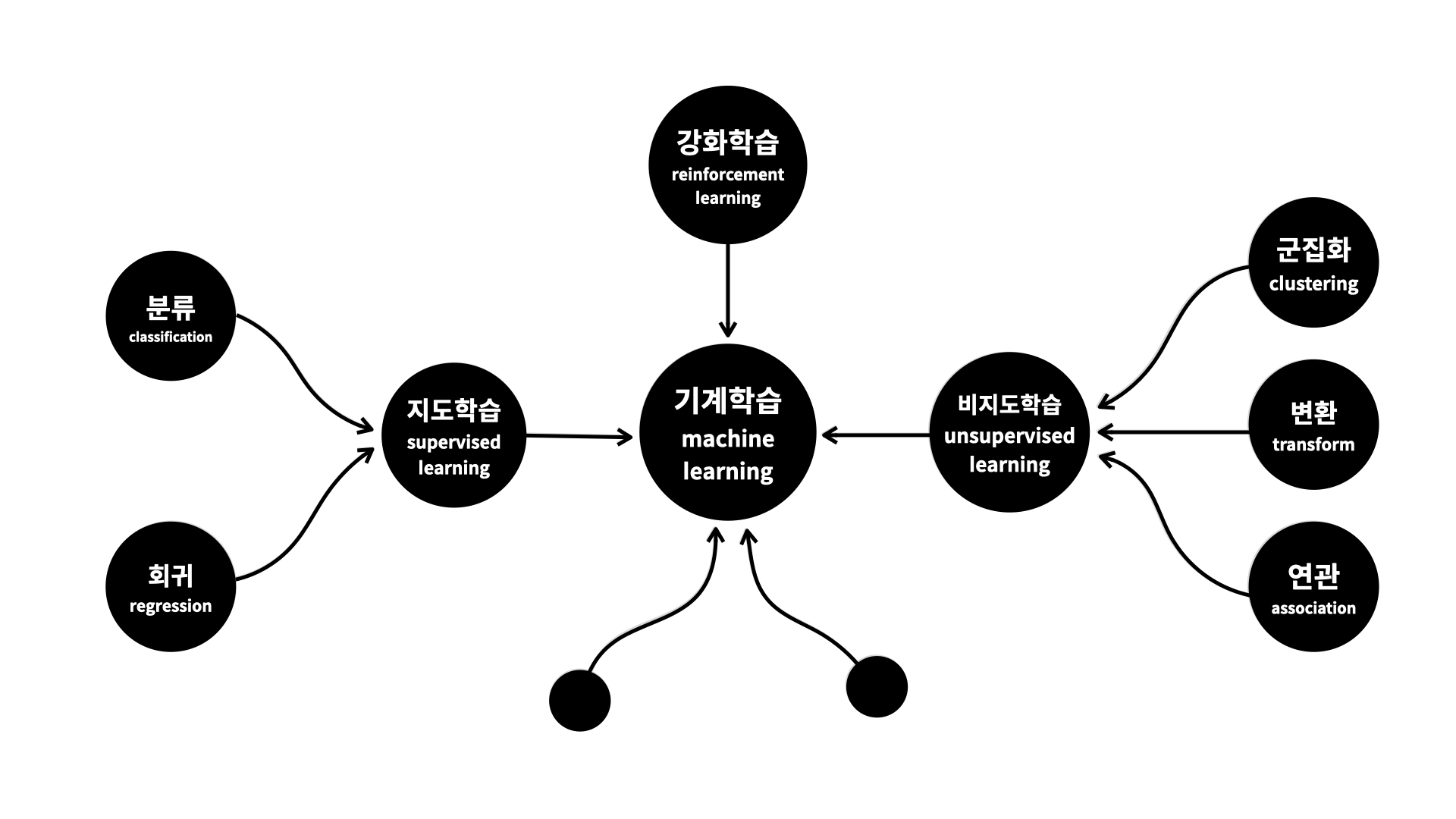
✍️지도학습(Supervised Learning)
정답(label)이 있는 데이터를 활용해 데이터를 학습시키는 것이다.
* 회귀(Regression) vs 분류(classification)
: 회귀와 분석은 우리가 예측하고자 하는 값의 종류 (즉, 데이터의 목적) 에 따라 나뉜다.
값이란 것은 연속형 데이터인 numerical data 와 categorical data 로 생각하면 쉽다.
- 회귀란 예측하고자 하는 종속변수가 연속형 데이터 일때 사용하게 방법
- 분류란 예측하고자 하는 종속변수가 categorical data 혹은 class 일때 사용하는 방법
| 분류 | 회귀 | |
|---|---|---|
| Data type | Categorical | Numerical |
| 찾고자 하는 것 | Decision Boundary | Best Fit Line |
| 평가지표 | Accuracy | SSE(Sum of Squared Error) |
✍️비지도학습(Unsupervised Learning)
정답(label)이 없는 데이터를 비슷한 특징끼리 군집화하여, 새로운 데이터에 대한 결과를 예측하는 학습법이다.
* 군집화(Clustering)
: 데이터들의 연관된 feature를 바탕으로 유사한 cluster를 만드는 방법. 대표적으로 K-means clustering.
* 차원 축소 (Dimensionality Reduction)
: 고차원 데이터셋을 feature selection / extraction 등을 통해 차원을 줄이는 방법
* 연관 규칙 학습 (Association Rule Learning)
: 데이터셋의 feature들 간에 관계(연관성)을 발견하는 학습 방법
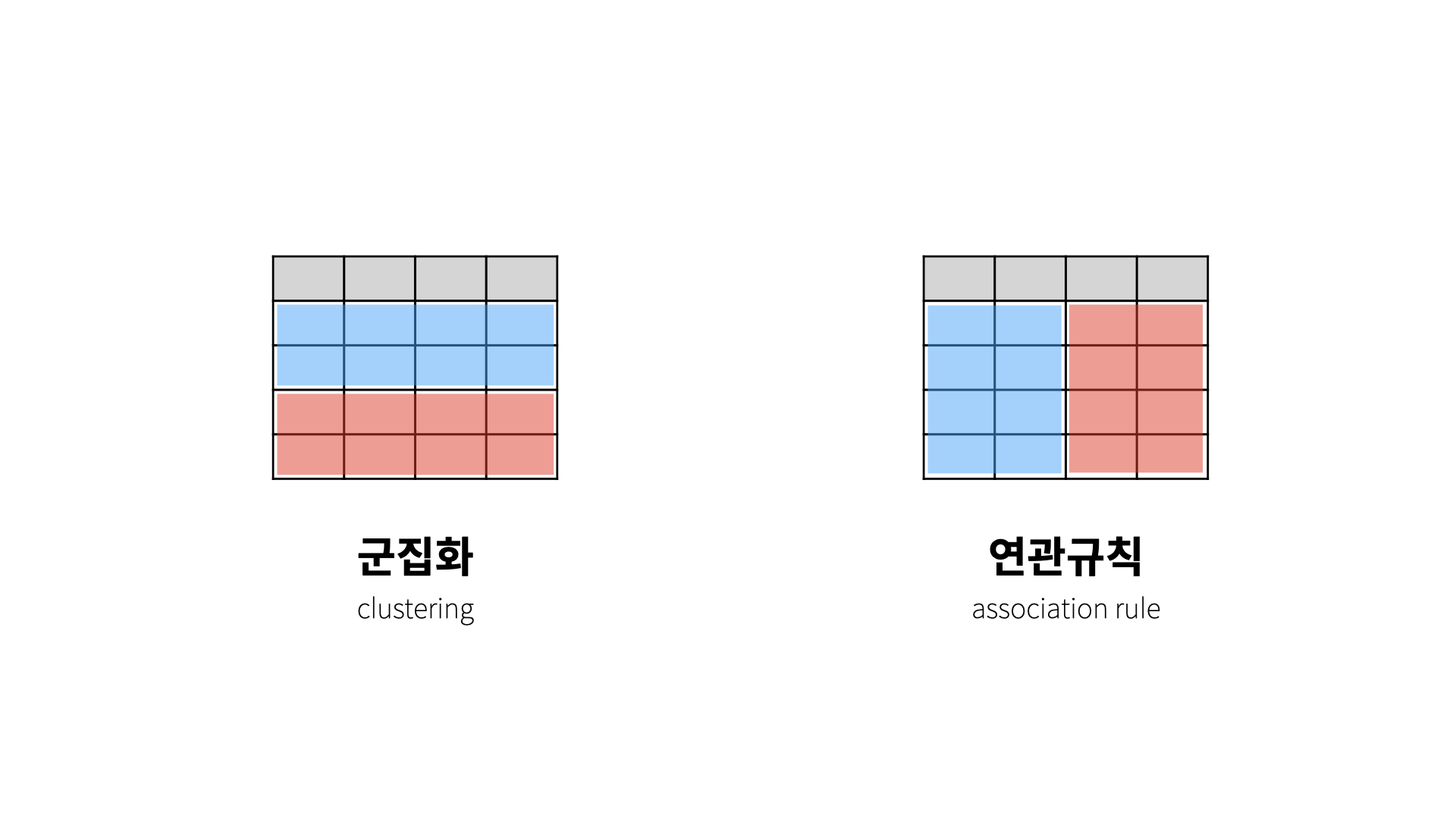
*군집화는 관측치(행)를 그룹핑, 연관 규칙은 특성(열)을 그룹핑
✍️강화학습(Unsupervised Learning)
머신러닝의 일종으로 기계의 좋은 행동에 대해 파라미터에 가중치를 두는 '보상'과 같은 피드백을 통해 학습 하여 목표를 찾아가는 알고리즘이다.
참고로 지도학습과 비지도학습의 대표적인 알고리즘은 다음과 같다.
| 지도학습 | 비지도학습 | ||
|---|---|---|---|
| Regression | Linear Regression | Clustering | |
| Locally Weighted Linear | K Means | ||
| Lasso | Density Estimation | ||
| Ridge | Exception Maximization | ||
| Classification | Machine Decision | DBSCAN | |
| Naive Bayes | Pazen Window | ||
| kNN | |||
| Support Vector |
출처 : 웬디의 기묘한 이야기
자료출처 : 생활코딩
