💡군집화(Clustering)
- cluster(클러스터) : 비슷한 feature를 가진 데이터들의 집단
- 군집화란 비지도학습 중 하나로 cluster를 무리지어 나가는 처리 과정 즉, 군집화 과정을 말한다.
(Clustering은 상대적 거리를 통해 유사한 feature들 끼리 cluster를 형성한다.)
클러스터링은 데이터들이 얼마나. 어떻게 유사한지 요약, 정리하는데 아주 효율적이다.
그러나 label이 없어서 정답을 확신할 수 없기 때문에 예측보단 EDA를 위한 방법으로 많이 쓰인다.
🔍 Clustering 방법
✍️ Hierarchical Clustering (계층적 클러스터링)
- Agglomerative (Bottom-up방식)
: 각각의 점을 원소로 가지는 클러스터들로부터 전체를 포함하는 클러스터 하나를 만들 때 까지 반복적으로 두 개의 '가까운' 클러스터를 합치면서 진행하는 방법 - Divisive (Top-down방식)
: 큰 하나의 클러스터로부터 시작해서 모든 클러스터가 정확히 하나의 원소를 가질 때가지 계속 쪼개는 방법
Hierarchical Clustering은 덴드로그램을 생성한다.
덴드로그램이란 계층적 군집에서 클러스터의 개수를 지정해주지 않아도 학습을 수행을 돕도록 개체들이 결합되는 순서를 나타내는 트리 형태의 구조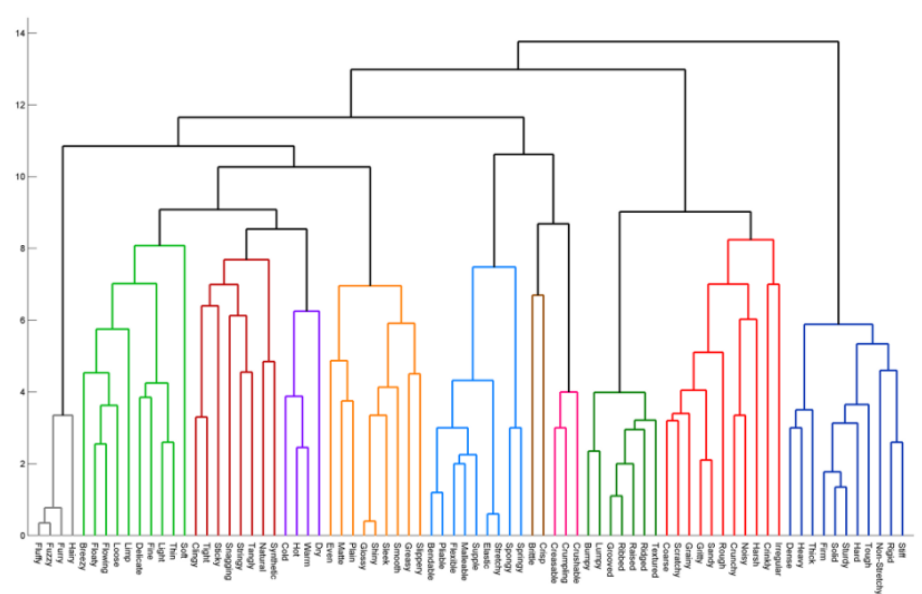
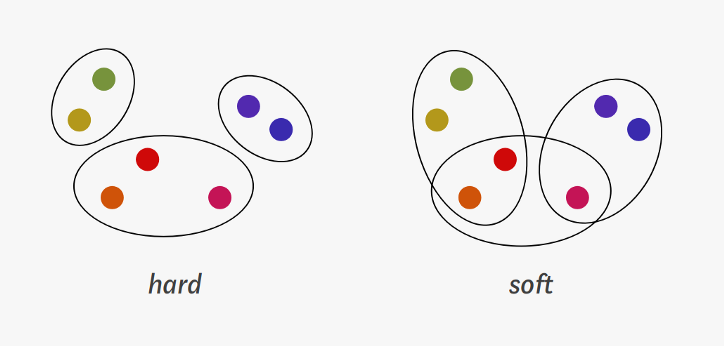
✍️ Hard & soft Clustering
- Hard Clustering - 한 개체가 여러 군집에 속할수 없는 군집화 방법
- Soft Clustering - 한 개체가 여러 군집에 속할수 있는 군집화 방법
✍️ Point Assignment (계층적 클러스터링)
: 시작시에 cluster 수를 정한 후, 데이터들을 하나씩 cluster에 배정시키는 방식이다.
즉, 이미 형성된 cluster들 중 새로운 점을 가장 가까운 cluster에 할당한다.
대표적인 방법 중 하나는 K-means clustering 가 있다.
✍️ Similarity
: Euclidean, Cosine, Jaccard, Edit Distance 등을 통해 데이터 간의 거리(distance)를 측정하여 유사한 정도를 파악하여 clustering 하는 방법.
일반적으로 많이 쓰이는 방식은 Euclidean 이지만, 각 목적에 따라 다른 방식들도 자주 사용되기 때문에 clustering 알고리즘이나 distance 방식을 공부하는 게 좋다.
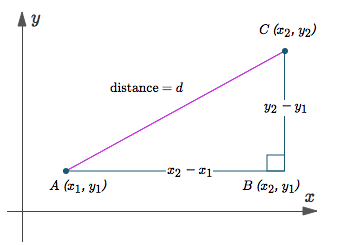
- Euclidean
: 유클리드 클러스터링은 두 점사이의 거리를 계산하는 방법이다.
(주로 최단거리를 구하는 방식으로 많이 쓰인다.)
# 라이브러리를 통해 구현 가능
# centroids = 클러스터 내 점들의 평균 (포함된 점이 아닐 수 있음, 즉 좌표)
from scipy.spatial import distance
distances = distance.cdist(x1, x2, 'euclidean')
# 혹은 norm을 통해 가능
import numpy as np
x = np.array([1, 2, 3])
y = np.array([1, 3, 5])
dist = np.linalg.norm(x-y)