어.....전 포스트에서 Mini-Batch Stochastic Gradient Descent에 대해 이야기를 했었는데 이것에 대해 응용된 것들만 우선적으로 다루려고 한다.
먼저 Gradient Descent Algorithm의 주요 요소들에는 Gradient(기울기), Step size(차수), Hyper-parametre(초변수), Learnable Parameter(학습척도), J which is an error function(에러함수 J)들이 있다. 차수가 작을수록 기울기 강하율은 느려지게 되고, 클수록 강하율이 최솟값을 상회할 수 있어 수렴하지 않는다거나, 발산하는 경우도 생기게 된다.
이를 위해 MBSGD 또는 SGD를 사용하게 되는데, 문제는 극소값(고등학교 2학년때 다 배우는 것들이다)에서 이 알고리즘이 이를 최소값으로 이해하게 되어 생기는 Local Optimum이라는 문제가 생기게 된다.
이러한 Local Minimum을 피하기 위한 방법으로는 이차함수에다가 공을 얹어서 속도를 구현하는 Momentum구조(결국 엄청 낮은 Minima가 아닌 이상 공은 계속 굴러감. 결국 최소에서 속도가 0이 됨), Momentum의 loss 계산으로 인해 x가 안착하지 못하고 계속 발산하는 점을 고려하여 관성치를 더한 Nesterov Accelerated Gradient라던가, 업데이트 횟수에 따라 학습률을 조정하는 옵션이 추가된 최적화 방식인 AdaGrad를 사용하는 방식이 있다.
RMSProp은 AdaGrad의 최신화된 버전으로, 학습동안에 업데이트되는 파라미터에 대해 분모가 계속 커지게 되고 무한대로 갈때 학습률이 0으로 수렴하게 된다는 점을 착안한 버전이다. 물론 여기에 모멘텀을 추가로 하여 Adam이 만들어졌고 g를 delta_theta J(theta)로 두어 관성 초기의 초기 순간을 계산하고 RMSProp을 사용하여 차후 위치 및 순간 데이터를 확인한 후, 편향치를 측정하여 파라미터를 업데이트하는 방법을 의미한다.
Learning Rate Scheduling
학습률: Gradient-based algorithm의 초변수 역할을 하며, 점차적으로 시간이 지날수록 줄여나가야 한다. 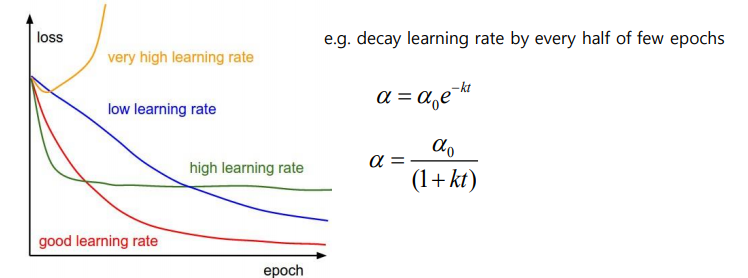
Regression 내의 Optimization
주어진 조건내에서 너무많은 기능들을 추가할 때, 가설은 Training Set의 데이터 셋에 알맞게 조정되지만 Outlier와 같은 새로운 데이터가 들어가게 될 경우 일반화가 어렵다는 단점이 존재한다.
이러한 Optimization 문제에 대한 해결책은 1. 원하는 분야에 필요한 기술들만 사용하는 방법이 있고 2. 기능은 유지하되 파라미터의 값이나 크기를 줄이고 간단한 가설에 대해 오버피팅을 하지 않도록 방지하는 Regularization 방식이 있게 된다.
