EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
논문? 리뷰?
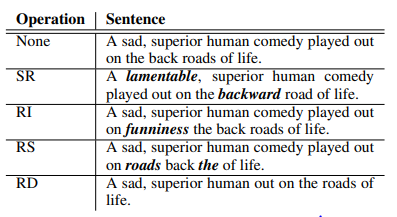
EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
EDA는 2019년 발표된 논문으로 모델이나 학습 기법에 관한 논문이 아니라 텍스트 데이터의 쉽고 간단한 증강 방식을 소개한 논문입니다. 당시 CV나 음성 인식 쪽에는 다양한 데이터 증강 기법이 있었지만, 텍스트 데이터에는 그 방법이 한정적이었는데 이 논문은 텍스트 데이터의 새로운 증강 방식을 선보였습니다.
요약
EDA는 Easy Data Augmentation의 약자로 쉬운 데이터 증강이라는 뜻입니다. 해당 논문에서는 EDA라는 단어의 뜻대로 굉장히 쉽고 간단하게 텍스트 데이터를 증강하는 방법들을 소개합니다.
논문에 소개된 증강 방식들을 간단히 설명하면 문장 내의 일부 단어를 동의어로 교체하는 기법(SR), 문장에 새로운 단어를 추가하는 기법(RI), 문장 내 일부 단어의 위치를 바꾸는 기법(RS), 문장 내 일부 단어를 삭제하는 기법(RD)가 있습니다.
개요
NLP 분야가 많은 발전을 거듭하며 좋은 성능을 보여주는 모델이 많이 생겼지만, 좋은 성능을 위해서는 질 좋은 학습 데이터가 많이 필요하다는 점은 변하지 않았습니다. 좋은 학습 데이터를 모으는 것은 쉽지 않은 일이고 많이 모으기까지 한다는 것은 어려운 일입니다.
당시 CV나 음성 인식 계열에는 데이터 증강이 널리 사용되었지만, NLP는 그렇지 않았습니다. NLP에도 데이터 증강이 존재하지 않지는 않았습니다. 유명한 기법으로는 텍스트를 다른 언어로 번역한 후 다시 원래의 언어로 번역하는 Back-Translation 기법 등이 있었죠.
또한 언어 모델을 활용해 새로운 문장을 생성하는 방법도 있었습니다. 하지만 이런 방법은 새로운 모델을 학습시키고 해야 하는 등의 번거로운 작업이 많아서 쉽게 사용하기는 힘들었습니다.
연구진들은 이런 상황에서 굉장히 쉽고 간단한 방식으로 텍스트 데이터를 증강하는 방식을 선보였습니다.
EDA의 증강 기법
EDA의 증강 방법은 4가지로 각각 SR, RI, RS, RD 기법이 있습니다. 문장의 일부 요소를 변경, 추가 또는 삭제하는 방식으로 각 기법의 자세한 내용은 아래에 설명하겠습니다.
SR(Synonym Replacement)
Synonym Replacement는 동의어 치환이라는 뜻으로 문장의 일부 단어를 동의어로 교체하여 새로운 문장을 생성하는 방식입니다. 증강 시에는 문장마다 개의 단어를 동의어로 교체합니다.
e.g. 맨체스터 유나이티드는 잉글랜드 최고의 팀이다 -> 맨체스터 유나이티드는 잉글랜드 최고의 클럽이다
RI(Random Insertion)
Random Insertion은 무작위 삽입이라는 뜻으로 문장에 있는 임의 단어의 동의어를 문장 내 임의의 위치에 삽입하여 새로운 문장을 생성하는 방식입니다. 증강 시에는 문장마다 개의 단어를 추가합니다.
SR 방식과의 차이점은 동의어를 삽입하고 기존 단어를 삭제하는 것이 아니라 기존 단어는 그대로 둔 채 동의어만 임의의 위치에 삽입한다는 것입니다. 또한 무작위 단어가 아닌 기존 단어의 동의어를 추가하는 이유는 무작위로 추가된 단어가 문장의 의미를 해치는 것을 방지하기 위한 것이라고 합니다.
e.g. 울산 HD FC는 대한민국 최고의 팀이다 -> 울산 HD 클럽 FC는 대한민국 최고의 팀이다
RS(Random Swap)
Random Swap은 무작위 교체라는 뜻으로 문장에 있는 두 단어의 위치를 서로 바꾸는 것을 통해 새로운 문장을 생성하는 방식입니다. 증강 시에는 문장마다 번의 Swap을 수행합니다.
e.g. T1은 월드 챔피언십 5회 우승을 달성한 유일무이한 팀이다 -> T1은 월드 챔피언십 5회 달성을 우승한 유일무이한 팀이다
RD(Random Delete)
Random Delete는 무작위 삭제라는 뜻으로 문장에 있는 임의의 단어를 삭제함으로써 새로운 문장을 생성하는 방식입니다. 각 단어가 삭제될 확률은 로 사용자가 지정 가능한 수치입니다.
e.g. 스테판 커리는 NBA 역사상 최고의 3점 슈터이다 -> 스테판 커리는 NBA 최고의 3점 슈터이다
문장의 길이에 따른 보정
위에서 설명한 증강 기법에서 RD를 제외한 나머지 3가지 기법은 모두 한 문장당 번의 변화를 준다고 합니다. 하지만 문장마다 길이가 다른데 긴 문장과 짧은 문장 모두 같은 횟수의 변화를 주면 긴 문장은 원래 문장과 별 차이가 없을 것이고 짧은 문장은 원래 문장의 의미를 잃어버릴 것입니다.
그렇기 때문에 은 고정 수치가 아닌 가변 수치로 사용합니다. 문장의 길이가 일 때 사용자 지정 파라미터 (RD에서는 삭제 확률 로 사용됨)를 곱한 을 으로 사용하여 각 문장의 길이에 알맞은 양의 변화를 적용합니다.
데이터 증강 성능 실험 결과
연구진들은 EDA의 성능을 알아보기 위해 다양한 데이터셋에서 성능 실험을 진행해 보았습니다.
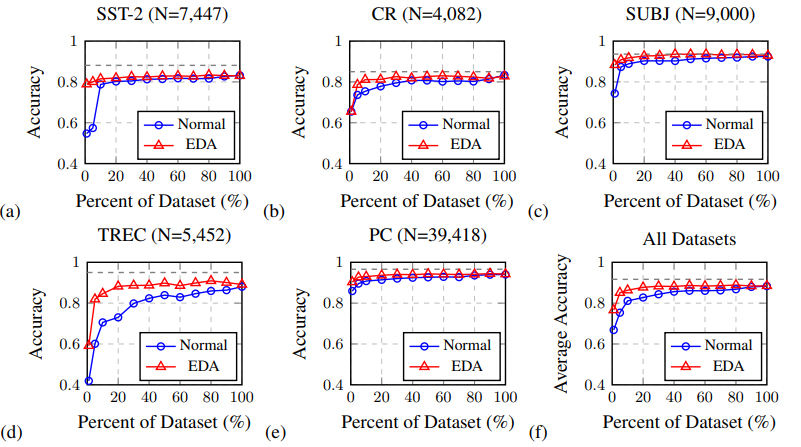
각 데이터셋 별로 EDA를 적용했을 때와 적용하지 않았을 때의 성능 차이를 나타낸 그래프로 아래의 Percent of Dataset은 전체 데이터 중 학습에 사용한 데이터의 비율입니다. 학습 데이터가 적을수록 EDA의 효과가 더 크게 드러나는 것을 볼 수 있습니다.
데이터셋 크기 별 증강 횟수
연구진들은 단순히 성능 실험에서 그치지 않고 데이터셋의 크기 별로 최적의 증강 횟수도 실험해보았습니다.
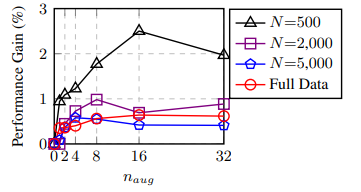
위의 그래프를 보면 데이터셋의 크기가 500일 때는 증강의 횟수가 16회일 때 가장 좋은 성능을 보였지만 그 외에는 4회나 8회일 때 가장 좋은 성능을 보였습니다. 데이터셋의 크기가 작을 때는 많은 증강을 통해 과적합을 방지하며 성능을 많이 끌어올릴 수 있지만 이미 데이터셋의 크기가 큰 경우는 그런 영향이 적어지기 때문에 4회나 8회가 적당하다고 합니다.
결론
연구진들은 매우 쉽고 간단한 방법으로 텍스트 데이터의 양을 늘릴 수 있는 기법을 제시하였습니다. EDA 방식은 대량의 데이터를 보유한 경우에는 그리 효과적이지 않을 수 있지만 데이터가 적은 경우에는 상당한 도움이 될 수 있다고 합니다.
후기
이번에는 예전에 부캠 시절에 프로젝트를 진행할 때 애용했던 EDA 기법에 대해 제대로 알아보기 위해 논문을 읽어보았다. 그 당시에 그렇게 자주 이용해 놓고 정작 논문은 읽어보지 않은 게 지금 생각하면 이해가 가지 않지만, 지금이라도 읽어보아서 다행이라고 생각이 든다.
또한 논문을 보니 EDA 기법이 BERT 모델에서는 그리 효과적이지 않을 것이라고 하는데(물론 그럼에도 조금은 성능의 향상이 있었던 것 같다) 그 당시에는 논문을 읽어보지 않았으니 BERT 계열 모델을 사용하면서도 EDA 방식에 집착을 했었던 것 같다.
지금 와서 돌아보면 논문을 읽어보지 않고 이런저런 실험을 진행한다는 것이 눈을 감고 길을 찾으려고 하는 것 같다. 하지만 이제라도 눈을 뜨고 길을 찾으려는 시도를 하고 있으니, 그때보다는 발전을 한 것 같다.
