
LLaMA: Open and Efficient Foundation Language Models
LLaMA: Open and Efficient Foundation Language Models는 2023년 메타에서 발표한 논문입니다. LLaMA는 LLM 열풍 속에서 오픈소스 LLM 모델로 대중들에게 공개되었고 LLM의 발전에 많은 기여를 하였습니다.
요약
LLaMA는 약 1조 개의 토큰을 사용하여 학습한 LLM 모델로 대중에게 공개된 퍼블릭 데이터셋들만을 활용하여 이전의 모델들을 뛰어넘는 성능을 보여줬습니다. 또한 적은 파라미터로도 더 큰 사이즈의 모델들보다 더 좋은 성능을 보여주면서 모델 사이즈가 다가 아니라는 것을 보여주었습니다.
개요
최근 LLM 모델들은 엄청난 수의 파라미터를 가진 초거대 모델들이 주류가 되어가고 있습니다. 하지만 파라미터가 많아질수록 모델의 연산에는 더 많은 시간과 자원이 필요해지게 됩니다. 그동안 파라미터의 수와 성능이 비례한다는 믿음이 이러한 상황을 가속화시키고 있었습니다.
그러던 중 어느 한 연구 결과에서 같은 자원양에서 최고의 성능을 내기 위해서는 단순히 큰 사이즈의 모델을 활용하는 것이 아니라 작은 모델에서라도 많은 양의 데이터를 학습하는 것이 더 좋을 수 있다는 것을 밝혀냈습니다.
이에 따라 연구진들은 정해진 자원양에서 최대한의 성능을 낼 수 있는 지점을 찾으려고 했고 그중에서도 특히 inference 과정에 집중하였습니다. (train보다는 inference를 훨씬 많이 수행하기 때문에 inference에 들어가는 자원을 줄이는 것이 효율성이 높을 것입니다)
그리고 이러한 과정을 통해 연구진들은 기존의 모델들보다 더 적은 파라미터를 가지고도 성능에서 뒤지지 않는 모델 구조를 완성했습니다.
학습 데이터
LLaMA의 학습에는 수많은 데이터셋들을 사용했고 모두 공개 데이터셋들이었습니다. 데이터셋의 분류에 대해 살펴보면 English CommonCrawl 데이터가 67%를 차지하며 가장 많이 활용되었으며 중복 데이터 제거하고 영어가 아니거나 퀄리티가 낮은 데이터는 필터링을 한 후 사용하였습니다.
그다음으로 많이 쓰인 데이터셋은 C4 데이터 셋으로 총 15%를 차지하였고 역시 중복 데이터 제거와 필터링을 한 후 학습에 사용하였습니다.
이 외에도 Github(4.5%), Wikipedia(4.5%), Gutenberg and Books3(4.5%), ArXiv(2.5%), Stack Exchange(2%)의 데이터셋을 활용하였습니다.
학습 데이터의 토크나이징에는 BPE 알고리즘을 활용하였고, 데이터셋을 약 1.4 조개의 토큰으로 토크나이징하였습니다.
모델 구조
LLaMA는 트랜스포머 기반의 모델로 기존의 모델에 여러 변경점들을 적용하여 성능을 향상시켰습니다. 연구진들이 제시한 주요한 변경점들은 아래와 같습니다.
Pre-normalization: GPT3에서 영감을 얻은 방법론으로 결과 출력 과정 대신 각 sub-layer 단계에서 normalization을 수행하는 것입니다. 이 방법을 통해 학습의 안정성을 증대시킬 수 있다고 합니다.
SwiGLU activation function: PaLM에서 영감을 얻은 방법론으로 활성화 함수를 ReLU대신 SwiGLU라는 함수를 사용하는 것입니다. 이 방법을 통하면 성능을 향상할 수 있다고 합니다.
Rotary Embeddings: GPTNeo에서 영감을 얻은 방법론으로 absolute positional embeddings 대신 rotary positional embeddings(RoPE)를 활용하는 것입니다.
또한 학습 속도를 높이기 위해 여러 가지 최적화 방법들을 사용했습니다.
xformers 라이브러리 사용: 메모리 사용량과 학습 시간을 줄이기 위해 효율적인 구조의 multi-head attention를 제공하는 xformers 라이브러리를 사용하였습니다. 간단하게 설명하자면 마스킹 처리가 된 부분에 대해서는 attention 가중치를 저장하지 않고, key/query 점수 계산도 수행하지 않는 것이라고 합니다.
activation 계산량 감소: backward 과정에서 재계산되는 activation의 양을 줄였습니다. 자세한 설명에 따르면 linear layer의 output처럼 계산량이 많은 activation의 결과를 저장하여 사용하는 방식으로 총계산량을 줄였다고 합니다. 연구진들은 이 방법을 위해 PyTorch의 Autograd를 사용하지 않고 직접 구현한 backward 함수를 사용하였습니다.
위의 방법들을 최대한 활용하기 위해서는 메모리 사용량을 줄여야 했기 때문에 병렬화를 사용하였고 GPU 간의 communication과 activation function 연산 결과를 최대한 겹치도록 설계하였습니다.
Instruction Finetuning
연구진들은 instruction finetuning을 활용하면 큰 성능 향상을 가져올 수 있다고 합니다. Instruction finetuning이란 사용자의 질문과 LLM을 답안으로 이루어진 데이터셋을 활용하여 finetuning을 진행하는 것으로 특정한 형태의 데이터셋을 활용한 finetuning으로 볼 수 있습니다.
예시를 들어보자면
질문: 모델을 학습하는 법에 대해 알려줘
답안: 모델을 학습하기 위해서는 다음과 같은 절차가 필요합니다. 1. 모델을 선정합니다. 2. 데이터셋을 수집합니다...같은 데이터들을 학습에 사용하는 것이지요.
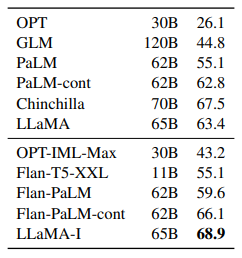
Instruction Finetuning을 수행한 결과는 아래 표와 같고 65B 모델에서 성능이 약 5점 정도 상승한 것을 알 수 있습니다.
생성형 AI의 해결 과제: 편향과 공격적인 언어 그리고 잘못된 정보
생성형 LLM 모델들의 문제점인 편향(인종, 성별, 직업 등), 공격적인 언어(욕설, 인종차별, 폭력적 발언 등) 그리고 잘못된 정보(할루시네이션)와 관련된 문제에서 LLaMA 역시도 자유로울 수는 없습니다.
연구진들 또한 본인들이 사용한 데이터셋 내에 이러한 문제를 일으킬 수 있는 데이터가 포함되어 있을 것이라고 생각하였고 이를 확인하기 위해 여러 실험을 진행해 보았습니다.
진행한 실험은 RealToxicityPrompts, CrowS-Pairs, WinoGender, TruthfulQA로 각각 공격적인 언어, 편향적 사고, 정보의 신뢰성을 테스트하는 실험입니다.
실험 결과를 종합하여 보면 공격적인 언어의 경우는 모델의 사이즈가 커질수록 증가하였으며, 편향적 사고 실험에서는 인종, 장애, 사회적 지위 부분에서 좋은 지표를 기록하였습니다. 마지막으로 정보의 신뢰성 같은 경우는 GPT-3를 완전히 뛰어넘는 성능을 보였으며 모델 사이즈가 커질수록 성능이 향상되었습니다.
모델 성능 실험 결과
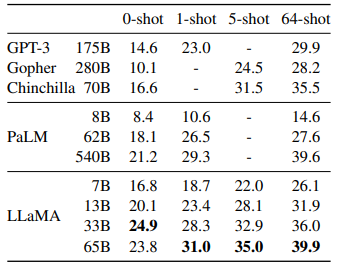
연구진들은 실험 과정에서 Zero-shot부터 1-shot, 5-shot, 64-shot을 입력했을 때 각각 어떻게 성능이 변하고 또 다른 모델과 비교했을때는 어떤 결과가 나오는지 실험을 진행하였습니다. 또한 모델 사이즈 별로 어떻게 성능이 변하는지도 보기 위해 다양한 사이즈의 모델로 실험을 진행하였습니다.
성능 실험을 위해서 QA, 내용 요약, 언어 이해 부분에서 실험을 진행하였고 QA 분야에서는 모델 사이즈가 크고 많은 shot을 사용할 수록 좋은 성능을 보였습니다. 내용 요약에서도 모델 사이즈가 클수록 좋은 성능을 보였고 언어 이해 부분에서도 마찬가지였습니다.
아래는 QA 분야 실험 결과로 모델 사이즈가 커질수록, 사용한 shot이 많을 수록 대체로 더 좋은 성능을 보이는 것을 알 수 있습니다.
결론
연구진들은 공개 데이터셋만을 활용하여 기존의 모델들(심지어 파라미터 개수가 10배 가까이 차이 나는 모델도)을 뛰어넘는 성능을 보이는데 성공하였습니다. 이런 점은 아직 LLM이 많은 발전을 이룰 수 있다는 것을 보여주는 것이라고 생각합니다.
또한 해당 연구진들은 LLaMA 모델을 오픈소스로 공개하였는데 본인들의 연구를 통해 LLM 분야가 발전하는 데 도움이 되기를 원한다고 하였는데 실제로 LLaMA는 이후의 LLM에 많은 영향을 미치고 발전 속도를 가속화시키는데 많은 도움이 되었습니다.
후기
한동안 옛날 논문을 위주로 보다가 오랜만에 최근(이라기엔 작년이긴 하다)에 나온 논문을 읽어보았다. 내가 그동안 읽었던 논문들에 나온 지식들이 쌓이며 이런 모델이 나왔다는 것이 신기하기도 하지만 중간중간 내가 모르는 내용들이 튀어나와서 아직 공부가 부족하다는 생각이 들기도 했다.
하지만 그런 빈 공간들을 메우다 보면 언젠가는 NLP와 LLM이라는 분야에 발가락이라도 담가볼 수 있는 때가 올 거라 믿고 꾸준히 공부를 해야겠다.
