Efficient Estimation of Word Representations in Vector Space
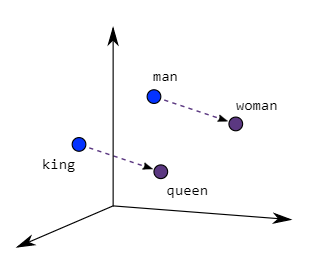
Efficient Estimation of Word Representations in Vector Space는 2013년에 발표된 논문으로 단어들을 벡터로 표현해 의미적 거리를 나타낼 수 있도록 한 word2vec이라는 representaion 방법을 다룬 논문입니다.
요약
wave2vec은 많은 양의 단어들을 vector 공간을 통해 representation하는 방법으로 단어들 간의 의미적 거리를 나타낼 수 있도록 하였습니다. 또한 이를 통해 더 적은 양의 자원을 통해 더 좋은 성능을 얻을 수 있었습니다.
개요
해당 논문 이전에 NLP 모델들에서는 단어를 atomic unit 단위로 다루었었습니다. 이 방법은 간단하고 강건한 특성이 있었지만 단어들 간의 유사도를 나타내는 개념이 존재하지 않았었습니다. 기존에는 간단한 구조에서 많은 양의 학습을 수행하는 것으로도 좋은 성능을 낼 수 있었지만 결국에는 한계를 맞이했습니다.
그에 따라 연구진들은 대량의 단어들을 여러 차원에 걸쳐 유사도를 표현하는 방법을 발표했습니다. 이 새로운 기술에서는 단어들을 단순히 비슷한 의미끼리 뭉쳐놓은 수준을 넘어 여러 관점에서 유사성을 표현할 수 있습니다.
모델 구조
벡터 공간을 통해 단어를 표현한 모델에는 대표적으로 LSA, LDA가 있습니다. 해당 논문에서는 LSA 모델보다 단어들의 linear regularity를 잘 보존하며, LDA보다 더 효율적으로 학습을 하는 것을 목표로 했습니다.
Feedforward Neural Net Language Model(NNLM)
probabilistic feedforwar neural network는 input layer, projection layer, hidden layer, output layer로 이루어진 모델이다. Input layer에서는 현재 위치부터 N개 이전의 단어까지가 1-of-V(원핫 인코딩) 방식으로 인코딩되고 이것을 projection layer에 projection합니다. 이후에는 projection-hidden-output으로 연산이 이어집니다.
NNLM 모델에서는 projection layer와 hidden layer 사이의 구간에서 많은 연산이 필요한데 연구진들은 vocabulary를 Huffman binary tree로 representation하는 방법을 통해 해당 구간의 연산량을 줄였습니다.
Recurrent Neural Net Language Model(RNNLM)
RNNLM은 context length를 명시해야 하는 등의 NNLM 모델의 한계를 넘기 위해 제안된 모델 형태입니다. RNNLM에는 projection layer가 없이 input layer, hidden layer, output layer로만 이루어져 있습니다. RNNLM은 RNN의 특성을 가지고 있기때문에 short temr memory를 사용 가능하고 이를 통해 이전 단계의 정보들을 현재 단계에서 사용할 수 있습니다.
Parallel Training of Neural Networks
대량의 데이터셋에서 모델을 학습하기 위해 연구진들은 DistBelief라 불리는 프레임워크를 구현했습니다.
DistBelief는 NNLM과 해당 논문에서 새롭게 제안된 모델을 포함하고 있고 병렬 학습 과정에서는 여러 개의 동일한 모델이 중앙 서버를 통해 파라미터들을 동기화하며 학습을 진행합니다.
New Log-linear Models
위의 모델 구조 항목에서 보았듯이 연산량에 많은 영향을 주는 부분은 모델의 비선형 hidden layer 부분입니다. 이 부분이 neural network의 핵심이긴 하지만 연구진들은 좀 더 간단한 구조의 모델을 이용하면 연산량을 훨씬 줄일 수 있을 것이라고 생각했습니다. 그리고 이에 따라 연구진들은 연산량을 줄이기 위한 두 개의 새로운 모델 구조를 제시했습니다.
새로운 모델 구조들은 두 단계의 학습 과정을 거칩니다. 첫번째 단계는 간단한 모델에서 word vector들을 학습하고 두번째 단계는 NNLM에서 이를 활용해 학습을 진행하는 것입니다.
Continuous Bag-of-Words Model(CBOW)
CBOW는 윗 문단에서 언급된 NNLM과 비슷한 구조의 모델이지만 비선형 hidden layer가 존재하지 않습니다. 또한 projection layer가 모든 단어들 사이에서 공유되기 때문에 항상 같은 position에 projection 됩니다. 연구진들은 이러한 구조를 bag-of-words 모델이라고 명명하였고 이 구조에서는 단어들의 순서가 projection에 영향을 미치지 않습니다.
또한 해당 구조에서는 현재 단어 전후에 등장한 단어들을(연구진들은 전후로 4개씩의 단어가 가장 좋은 성능을 보였다고 합니다.) 이용해서 현재 단어를 예측하는 방식으로 훈련을 진행합니다.
Continuous Skip-gram Model
Skip-gram 모델도 역시 CBOW와 비슷한 구조의 모델입니다. 하지만, 이 방식에서는 현재 단어를 input으로 사용하여 근처에 등장해야 할 단어들을 예측하는 방식으로 훈련을 진행합니다. 그리고 현재 단어에서 멀리 떨어진 단어는 가까운 단어에 비해 연관이 적은 경우가 대부분이기 때문에 가중치를 통해 이를 반영했습니다.
또한 연구진들은 예측 범위를 늘리는 것이 성능을 향상에 도움이 된다는 것을 발견했지만 이 방법을 사용할 경우 연산량도 함께 늘어난다고 합니다.
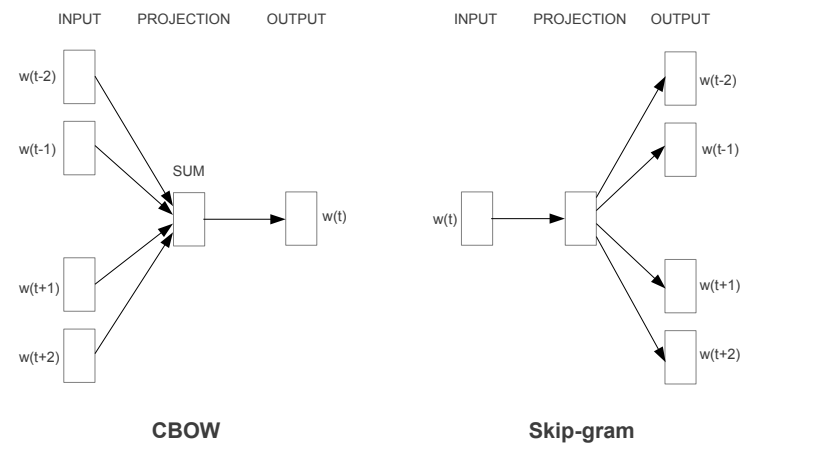
위 그림은 CBOW와 Skip-gram 방식을 시각적으로 표시한 것으로 CBOW에서는 현재 시간(t) 근처의 단어들을 input으로 사용하여 output(현재 단어)을 출력하고 Skip-gram에서는 현재 단어를 input으로 사용하여 output(현재 단어 근처의 단어)을 출력하는 것을 볼 수 있습니다.
단어들간의 관계 표현 실험 결과
연구진들이 제시한 word vecotr representation에는 단어들의 다양한 관계를 표현할 수 있다고 하였고 이를 측정하기 위해 테스트 데이터셋을 제작하였습니다. 아래의 표는 데이터셋의 일부로 두 단어와 그 두 단어의 관계가 데이터로 주어지는 것을 볼 수 있습니다.
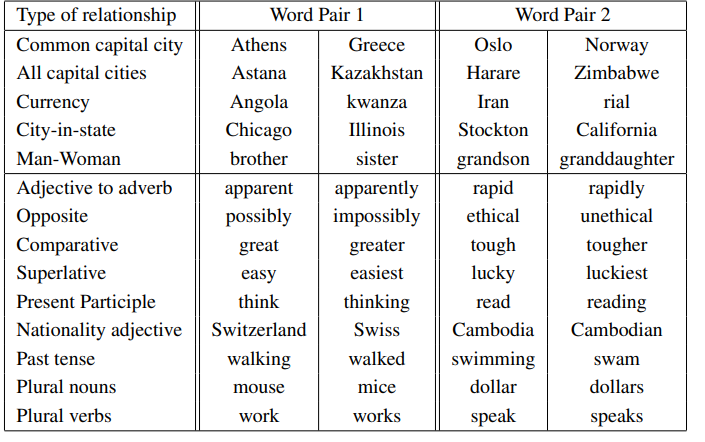
제작진들은 이 데이터셋을 통해서 모델의 성능(해당 논문에서는 accuracy를 성능 측정의 지표로 사용)을 실험해 보았고 그 과정에서 여러 다른 조건들에 따른 성능 변화도 실험해 보았습니다.
차원의 수와 학습에 사용한 단어 수에 따른 성능 차이
차원의 수와 학습에 사용한 단어 수에 따라 성능이 어떻게 변하는지 알아보기 위해 차원의 수와 단어 수를 바꿔가며 실험을 진행하였습니다. 실험 결과는 아래의 표를 통해 볼 수 있습니다.
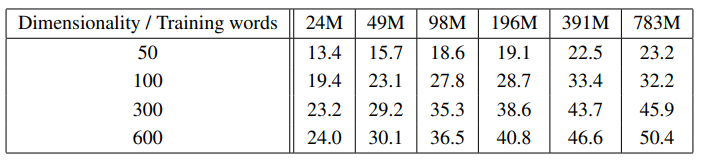
위의 표를 보면 차원의 수가 높을수록, 그리고 학습에 사용한 단어가 많을수록 더 좋은 성능을 보이는 것을 알 수 있습니다. 차원이 많을수록 단어들의 관계를 더 다양한 측면에서 표현할 수 있고 학습에 사용한 단어가 많을수록 더 많은 관계를 학습할 수 있기 때문에 당연한 결과인 것처럼 보입니다.
모델 구조에 따른 성능 차이
모델 구조에 따른 성능 차이를 알아보기 위해 논문에 제시된 구조의 모델들을 모두 같은 조건으로 학습한 뒤 성능을 비교해 보았습니다.
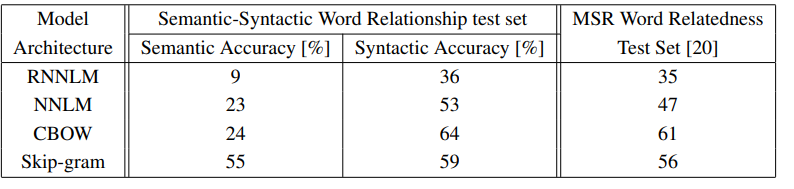
위의 실험 결과표를 보면 RNNLM과 NNLM보다 CBOW, Skip-gram 모델이 더 좋은 성능을 내는 것을 볼 수 있습니다.
결론
해당 논문에서는 간단한 모델 구조로도 매우 높은 수준의 word vector를 학습할 수 있다는 사실을 발견했습니다. 간단한 모델은 연산량이 적기 때문에 많은 양의 데이터에서도 높은 차원의 word vector를 사용할 수 있으므로 좋은 성능을 보이는 것이 가능합니다.
후기
예전에 배운 요소들을 좀 더 자세히 알아보기 위해 논문을 읽어보고 있는데, 쉽지 않다. 확실히 누군가가 정리를 해놓은 내용을 보는 것과 논문을 직접 읽는 것에는 많은 차이가 있는 것 같다. 내가 아직 논문을 제대로 이해하는 능력이 부족한 것과, 예전에 배우는 과정에서 제대로 학습이 되지 않은 것이 문제인 것 같고 이를 해결하기 위해서는 결국 기본기를 제대로 다져야 할 것 같다.
