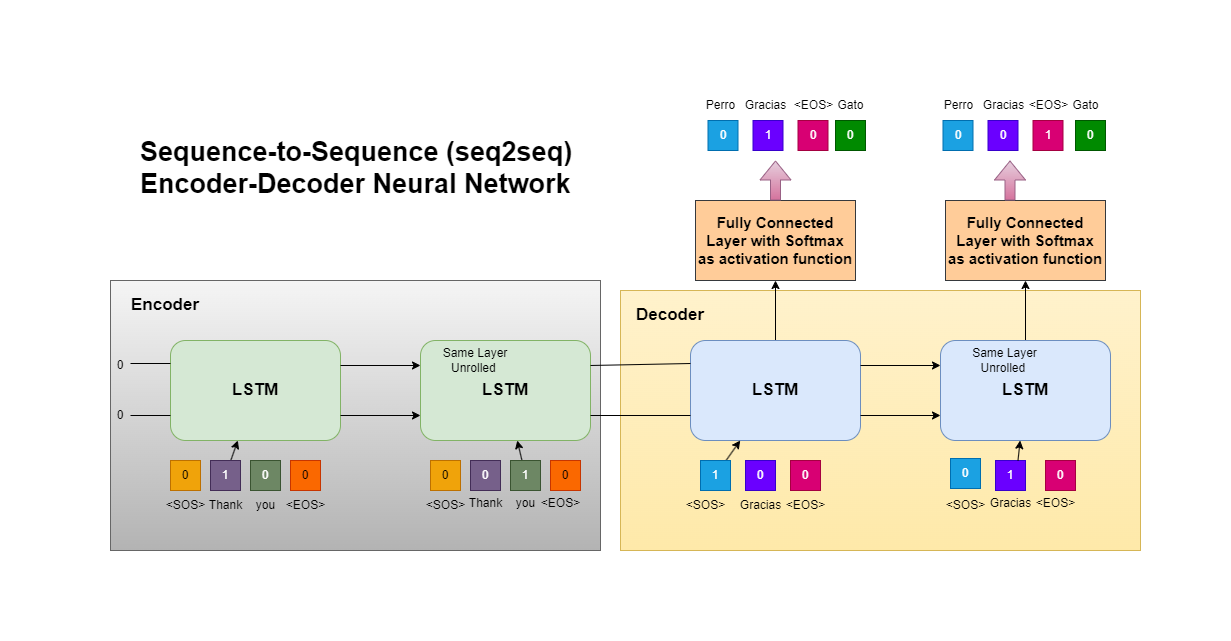
Sequence to Sequence Learning with Neural Networks
Sequence to Sequence Learning with Neural Networks은 2014년 발표된 논문으로 seq2seq 모델을 제안하였습니다. Seq2seq 모델은 이전의 모델들에 비해 긴 텍스트에서 좋은 성능을 보였었고 Transformer의 등장 이전에 자연어처리에서 널리 사용되었습니다.
요약
딥러닝 모델은 다양한 태스크에서 좋은 성능을 보이지만 sequence와 sequence를 mapping하는 데 사용하기는 힘들었습니다.
하지만 seq2seq에서는 여러 layer의 LSTM(Long Short-Term Memory)을 사용하여 input sequence를 vector로 mapping한 후, decoding을 통해 target sequence에 mapping하는 방법을 사용하였습니다.
이를 통해 영어-불어 번역 작업에서 seq2seq 모델은 좋은 성능을 보였습니다.
또한 LSTM은 길이가 긴 문장에서도 좋은 성능을 보였습니다. 그리고 seq2seq의 또 다른 특징 중 하나는 input sequence를 뒤집어서 사용한다는 것으로 이 방법은 모델의 성능을 눈에 띄게 향상시켰습니다.
개요
기존의 딥러닝 모델들이 다양한 작업에서 좋은 성능을 보였지만 input과 output의 길이가 동일할 때에만 제대로 동작할 수 있다는 문제점이 있었습니다. 딥러닝 모델이 수행하는 많은 문제들의(ex.기계 번역, 음성 인식 등) 경우에 답의 길이가 얼마가 될지 모르는 상황이 많기 때문에 이런 점은 큰 제약으로 작용하였습니다.
해당 논문에서는 LSTM 모델 두 개를 각각 인코더와 디코더로 활용한 새로운 모델 구조를 통해서 이러한 제약을 해결하려고 하였습니다.
모델 구조
Seq2Seq 모델의 구조는 두 개의 LSTM 모델이 결합되어 있는 형태로 이루어져 있습니다. 두 LSTM 모델은 각각 인코더, 디코더의 역할을 합니다. 이런 구조를 사용하는 이유 중 하나는 input sequnce와 output sequence의 길이에 제약을 덜 받기 때문입니다.
기존의 모델은 input sequence와 output sequence의 길이가 다를 경우 mapping에 어려움이 있었지만, Seq2Seq에서는 각각의 LSTM 모델이 input sequence를 vector로, vector를 output sequence로 mapping 하는 방법을 통해서 작업을 수월하게 진행할 수 있습니다.
또한 LSTM 모델의 layer 개수를 늘리는 방법을 통해서 추가적으로 성능을 좀 더 끌어올렸습니다.
Decoding and Rescoring
해당 모델의 학습 과정에서는 두 문장의 쌍(원문과 번역문)들을 활용하였습니다. 이 과정에서 학습 목표는 source sentence 가 들어왔을 때 제대로 된 번역문 가 나올 확률을 최대화하는 것으로 설정되었습니다.
번역은 매 time-step마다 beam-search를 활용하여 알맞은 단어를 선정하는 방식으로 진행되었고 beam의 size가 작을 때도 좋은 성능을 보였다고 합니다.
Reversing the Source Sentences
Seq2Seq의 중요한 특징 중 하나는 input sequence에서 word들의 순서를 뒤집어서 사용한다는 것입니다. 예를 들자면 I-like-apple이라는 input sequence를 apple-like-I의 순서로 사용하는 것입니다.
해당 방법론을 통해서 실험진들은 큰 성능 향상을 얻을 수 있었습니다.
또한 연구진들은 이 방법론을 통해 예측 성능 향상 정도만을 예상했지만, 긴 문장을 다루는 경우에서도 성능이 향상되었다고 합니다.
이 방법이 왜 효과적인지에 대해서는 실험진들도 정확히 알지 못한다고 하지만 input sequence를 뒤집음으로써 target 값을 예측할 때 대응하는 word와 가까워지기 때문인 것 같다고 짐작하였습니다.
모델 성능 실험 결과
연구진들은 Seq2Seq 모델의 성능을 알아보기 위해 BLEU score를 통해 다른 모델들과 성능을 비교해 보았습니다.
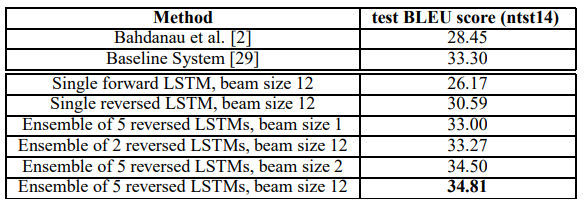
위의 표에서 보이듯이 Source Sentence를 뒤집어서 사용한 LSTM이 그렇지 않은 모델에 비해 더 좋은 성능을 보였고 앙상블을 통해서 기존 모델의 성능을 뛰어넘는 모습을 보여줬습니다.
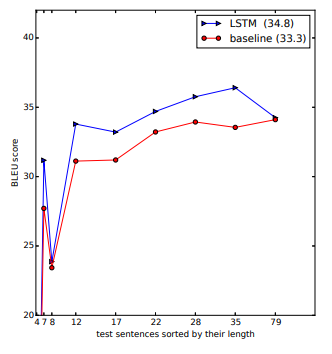
또한 긴 문장에서도 좋은 성능을 보여줬는데 아래의 표를 통해 그 성능을 볼 수 있습니다.
결론
연구진들은 larger deep LSTM이 제한된 vocabulary만을 가지고도 좋은 성능을 낼 수 있다는 것을 보여줬습니다. 또한 단순히 source sentence의 word 순서를 뒤집는 것만으로도 성능을 높일 수 있다는 놀라운 발견을 해냈습니다. 거기에 더해 LSTM이 긴 문장에서도 좋은 성능을 낸다는 것까지도 알아냈습니다.
후기
예전 부스트캠프 시절에 배웠던 모델인 Seq2Seq 모델에 대해 다시 공부해 보기 위해 논문을 읽어보았습니다. 분명히 이전에 들어본 적이 있는 모델이지만 논문을 읽어보니 몰랐던 내용도(배웠는데 잊은걸 수도...) 알 수 있었습니다. 이렇게 꾸준히 기존 논문들을 읽으며 지식을 쌓아가다 보면 언젠가는 최신 논문을 읽고 이해할 수 있게 되는 날이 올 것이라 생각하고 그날이 올 때까지 계속 노력해야 할 것 같습니다.
