
RoBERTa: A Robustly Optimized BERT Pretraining Approach
RoBERTa: A Robustly Optimized BERT Pretraining Approach는 2019년 발표된 논문으로 2018년에 발표된 BERT 모델을 모델 구조 변화 없이 학습 방법 변경과 더 큰 학습 데이터를 활용해 성능을 끌어올릴 수 있다는 것을 알린 모델로 학습 방법과 학습 데이터의 양이 모델 성능에 끼치는 영향이 크다는 것을 알린 논문입니다.
요약
언어 모델의 성능을 비교할 때는 고려할 점이 많습니다. 하이퍼 파라미터의 설정이나 학습하는 데이터에 따라 성능이 달라지기 때문으로 연구진들은 BERT 실험을 재현하는 과정을 통해 하이퍼 파라미터와 학습 데이터의 중요성을 보여줍니다.
또한 연구진들은 BERT의 성능이 상당히 저평가되었고 이후에 출시된 모델들의 성능조차 뛰어넘을 수 있다는 것을 발견했습니다. 그리고 이를 통해서 그동안 경시되었던 사항들과 최근 모델 성능 향상의 근원에 대해 보여주었습니다.
개요
그동안 self-training 방식이 많은 성능 향상을 가져왔지만, 정확히 어떤 요소가 성능에 얼마나 영향을 끼치는 것인지 알아내기는 쉽지 않습니다. 그래서 연구진들은 BERT 실험을 재현하면서 그 요소를 알아보려 했고 그 과정에서 BERT의 성능이 굉장히 저평가되었다는 사실을 발견했습니다.
연구진들이 BERT 모델에서 변경한 부분은 학습 방식(NSP 삭제, dynamic masking), 학습 데이터(텍스트 길이 증가, 학습량 증가)로 연구진들은 이렇게 변경된 모델을 RoBERTa(Robustly Optimized BERT Pretraining Approach)라고 명명했습니다.
BERT?
이 모델은 BERT를 기반으로 하고 있기 때문에 BERT에 대해 간단히 설명해 보면 Transformer의 Encoder를 기반으로 한 모델입니다. BERT의 큰 특징은 양방향 학습으로 현재 처리 중인 token보다 먼저 등장한 token들의 정보만 사용하는 Transformer와 달리 전체 token의 정보를 활용하는 방식으로 텍스트의 내용을 더 잘 예측할 수 있습니다.
그리고 BERT 또한 사전 학습 모델인데, 사전 학습 방식으로는 NSP(주어진 두 문장이 이어지는 문장인지 예측하는 훈련), MLM(문장의 일부 요소를 Masking한 뒤 예측하는 훈련)을 사용하였습니다.
이러한 요소들을 통해 BERT는 당시 최고 수준의 성능을 보였습니다. BERT에 대해 좀 더 자세히 알아보고 싶다면 BERT 논문 정리를 읽어보면 도움이 될 수 있을 것 같습니다.
RoBERTa의 개선점
RoBERTa는 BERT 모델의 학습 방식을 개선하여 모델의 성능을 향상한 것으로 아래는 각 개선 방식들을 간단하게 설명한 것입니다.
하이퍼 파라미터 변경
하이퍼 파라미터 설정을 변경하는 것으로도 모델의 성능을 좀 더 끌어올릴 수 있습니다. 연구진들은 Adam의 과 을 조정하는 것으로 학습의 안정성과 성능을 끌어올렸습니다. 또한 최대 token 수와 배치 크기를 변경하는 것으로도 성능을 향상했습니다.
학습 데이터 증강
사전 학습 모델에서 사전 학습 데이터의 크기는 매우 중요합니다. 사전 학습에 사용할 데이터를 증강하는 것으로 모델의 성능을 향상할 수 있을 정도입니다. 따라서 연구진들은 기존 BERT 연구진들보다 좀 더 다양하고 많은 양(160GB 이상)의 데이터셋을 확보하였습니다.
Dynamic Masking 적용
Dynamic Masking은 BERT의 MLM 학습을 개선한 것으로 기존의 MLM 학습에서는 각 데이터의 Masking 위치는 데이터 전처리 과정에서 정해진 뒤 변하지 않습니다. 하지만 RoBERTa에서는 각 epoch마다 Masking의 위치를 바꿔가며 학습을 진행합니다.
NSP 학습 제거
원래 NSP 학습은 BERT 모델의 학습에 중요하게 여겨지는 학습 방법이었습니다. 하지만 일부 연구 결과에서 NSP 학습의 필요성에 의문을 가지자, 연구진들은 NSP에 관한 연구를 진행하였습니다.
총 4가지 방법으로 학습을 진행하여 성능을 비교하였고 각각의 방법은 아래와 같습니다.
SEGMENT-PAIR+NSP: 기존 BERT에서 사용한 방식으로 몇 개의 문장으로 이루어진 SEGMENT 두 개가 서로 이어지는 SEGMENT인지 예측하는 방식입니다.
SENTENCE-PAIR+NSP: 위의 방법과 비슷하지만 SEGMENT 대신 한 개의 문장씩을 이용하여 학습하는 방법입니다. (즉 한 문장+한 문장이 한 쌍의 데이터입니다)
FULL-SENTENCES: 각 문서의 문장들을 통으로 학습에 사용하는 방식으로 NSP 학습을 수행하지 않습니다. 하지만 특별한 점이 있다면 학습 데이터 하나당 총 token 개수가 512개에 최대한 가까워지도록 하기 위해 한 문서에 포함된 token의 개수가 512개보다 적을 경우 다음 문서의 내용 중 전체 혹은 일부를 가져와서 token의 개수를 채웁니다. ([SEP] token을 통해서 문서의 경계를 구분합니다)
DOC-SENTENCES: FULL-SENTENCES와 비슷하지만, 해당 방법에서는 한 문서에 포함된 token의 개수가 512개보다 적더라도 다음 문서의 내용을 가져오지 않습니다.
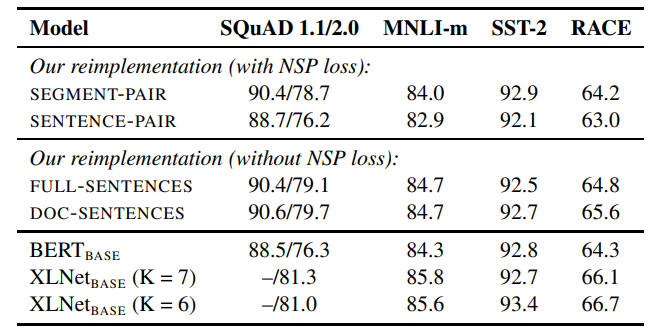 위의 표는 각 방법을 통해 학습한 모델의 성능을 표로 나타낸 것으로 NSP 학습을 수행하지 않은 경우가 전체적으로 더 좋은 성능을 보여주는 것을 볼 수 있습니다.
참고로 연구진들은 이후 실험의 편의성을 위해 성능이 더 좋은 DOC-SENTENCES 방식 대신 FULL-SENTENCES 방식을 활용했습니다.
위의 표는 각 방법을 통해 학습한 모델의 성능을 표로 나타낸 것으로 NSP 학습을 수행하지 않은 경우가 전체적으로 더 좋은 성능을 보여주는 것을 볼 수 있습니다.
참고로 연구진들은 이후 실험의 편의성을 위해 성능이 더 좋은 DOC-SENTENCES 방식 대신 FULL-SENTENCES 방식을 활용했습니다.
텍스트 인코딩 방식 변경
BPE(Byte-Pair Encoding) 인코딩 방식은 글자 단위와 단어 단위를 모두 표현 가능한 인코딩 방식입니다. BPE 인코딩을 간단히 예시를 들어보면
words: BERT, ROBERTA, ALBERT
B E R T, R O B E R T A, A L B E R T
vocab: B E R T R O A L
BE R T, R O BE R T A, A L BE R T
vocab: B E R T R O A L BE
BER T, R O BER T A, A L BER T
vocab: B E R T R O A L BE BER
BERT, R O BERT A, A L BERT
vocab: B E R T R O A L BE BER BERT위의 방식 처럼 일단 각 단어들을 글자 단위로 분리한 후 현재 단계에서 가장 자주 등장하는 연속 문자열(위에서부터 BE(B+E), BER(BE+R), BERT(BER+T)가 가장 많이 등장하였기 때문에 vocab에 추가)을 vocab에 추가하는 행위를 반복하면서 vocabulary를 만들어 나가는 식입니다.
기존의 BERT 모델은 heuristic tokenization rule를 이용해 전처리를 수행한 30K 크기의 글자 단위 vocabulary를 사용하였지만 RoBERTa에서는 전처리를 수행하지 않은 50K 크기의 byte 단위 vocabulary를 사용하였습니다.
모델 성능 실험 결과
연구진들은 위의 변경점들을 통해 BERT 모델 학습 방법을 개선했고 그 성능을 직접 테스트해보았습니다. 각 실험은 사전 학습에 사용된 데이터의 양과 학습의 진행 횟수에 대해 집중하여 진행했습니다.
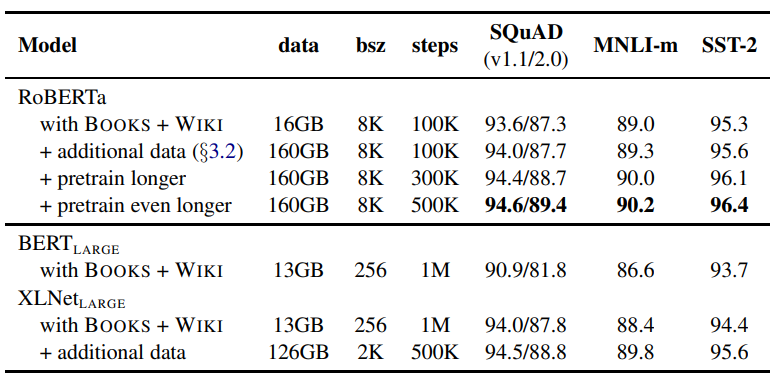
위의 표를 통해 모델과 학습 과정별 성능을 비교해 보면 더 큰 데이터에서 더 오래 학습할수록 성능이 좋아진다는 것을 알 수 있습니다.
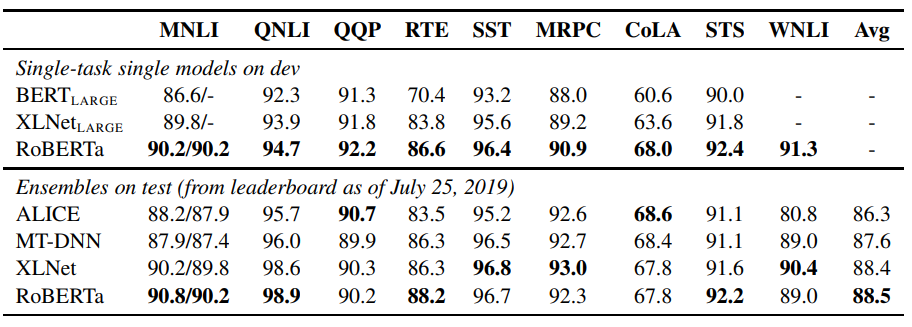 추가로 더 다양한 작업에서의 성능을 봐도 RoBERTa가 기존의 다른 모델들에 비해 더 좋은 성능을 낸다는 것을 알 수 있습니다.
추가로 더 다양한 작업에서의 성능을 봐도 RoBERTa가 기존의 다른 모델들에 비해 더 좋은 성능을 낸다는 것을 알 수 있습니다.
결론
연구진들은 BERT의 학습 방식을 변경하고 더 큰 데이터에서 더 오래 학습을 하는 것으로 성능을 끌어올리는 것을 통해 학습 과정의 중요성을 증명했습니다. 또한 RoBERTa는 여러 가지 작업에서 SOTA를 달성하며 BERT의 모델 구조가 여전히 경쟁력이 있으며 학습 과정 또한 모델 구조 만큼이나 중요하다는 것을 알렸습니다.
후기
예전에 부캠 시절 몇 번 사용했었던 RoBERTa 모델의 논문을 드디어 읽어보았습니다. 그 당시에는 단순히 BERT보다 성능이 좋다는 이유만으로 사용했었는데, 이 논문을 읽어보니 왜 성능이 더 좋은지 어렴풋이 알게 되었습니다. 그리고 그 당시에 모델 선정 과정에서 단순히 성능만을 보기보다는 논문을 제대로 읽어보며 어떤 점이 해당 태스크에 잘 어울리는지 고민해 보고 모델을 선정하였다면 어땠을까 하는 생각이 들었는데, 앞으로는 AI 관련 프로젝트를 진행하면서 모델에 대해 알아보는 시간이 꼭 필요하겠다는 생각이 듭니다.
또한 늘 그렇듯 어디까지나 저의 해석이기 때문에 해당 글에는 틀린 내용이 많이 존재할 것인데 이 글을 읽으시는 분은 꼭 감안해주시길 바랍니다.
