
Seq2Seq
Seq2Seq 등장 이전 RNN, GRU, LSTM 등의 모델들은 입력값과 출력값의 길이가 같을 때는 좋은 성능을 보이지만 그렇지 않을 때는 성능이 떨어졌습니다. 하지만 Seq2Seq은 Encoder에서 입력값을 고정 길이 벡터로 변환해 Decoder의 입력값으로 사용하는 방식으로 해당 문제점을 보완하였습니다.
참고로 이 글은 Sequence to Sequence Learning with Neural Networks 논문을 바탕으로 작성한 글입니다.
Seq2Seq 모델 구조
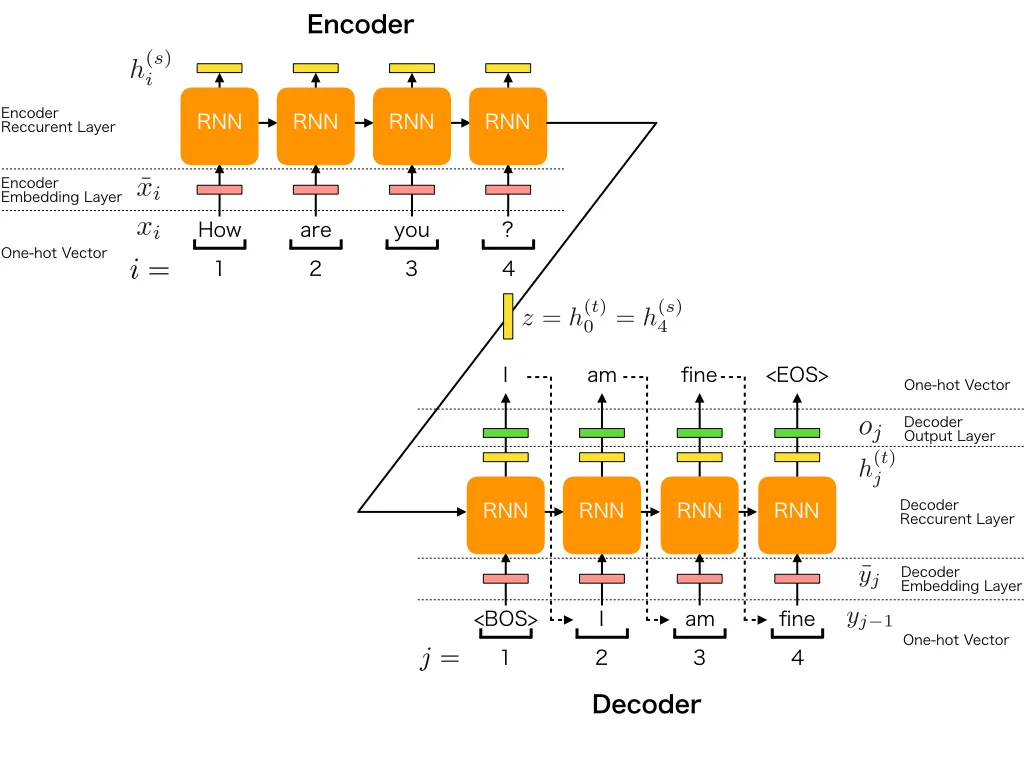
Seq2Seq 모델은 Encoder와 Decoder 구조로 이루어져 있고 각각의 Encoder와 Decoder의 여러 레이어의 RNN(해당 논문에서는 4 layer의 LSTM)으로 이루어져 있습니다.
Encoder와 Decoder
Encoder와 Decoder 구조는 Seq2Seq 모델의 가장 큰 특징으로 이전에는 하나의 모델에서 모든 과정을 처리했다면 Seq2Seq에서는 두 개의 모델이 역할을 분리하여 각각의 역할을 더 잘 수행할 수 있도록 하였고 Encoder에서는 입력값을 고정 길이 벡터로 변환하고 Decoder에서는 해당 벡터의 정보를 해석합니다.
Encoder와 Decoder를 분리하면서 얻을 수 있는 장점 중 하나는 입력값과 출력값의 길이에 제약을 덜 받는다는 점입니다. 기존의 모델에서는 입력값과 출력값의 길이가 다를 경우 둘을 mapping하는 데 어려움이 있었습니다. 하지만 Seq2Seq에서는 Encoder에서 입력값을 vector로, Decoder에서 vecotr를 출력값으로 각각 mapping하는 방법을 통해서 이러한 제약을 극복했습니다.
또한 모델의 성능을 향상시키기 위해 Encoder와 Decoder를 구성하는 RNN 모델의 레이어 수를 늘리는 방법을 사용하였습니다. 이에 따라 Seq2Seq 모델은 여러 개의 레이어를 사용하기 때문에 각 레이어에서 입력값이 달라질 수 있습니다. Encoder의 첫 번째 레이어에서는 입력값 가 사용되지만, 이후 레이어에서는 이전 레이어의 hidden state가 입력값으로 사용됩니다. 마찬가지로, Decoder의 첫 번째 레이어에서는 Encoder의 마지막 레이어에서 나온 hidden state가 입력값이 되며, 이후 레이어에서는 이전 레이어의 hidden state를 입력값으로 사용합니다.
Seq2Seq 구현 소스코드
class MyLSTMCell: // LSTM 모델과 동일
def __init__(self, input_size, hidden_size):
self.hidden_size = hidden_size
self.input_size = input_size
self.Wf = np.random.randn(hidden_size, input_size) * 0.01
self.Wi = np.random.randn(hidden_size, input_size) * 0.01
self.Wo = np.random.randn(hidden_size, input_size) * 0.01
self.Wc = np.random.randn(hidden_size, input_size) * 0.01
self.Uf = np.random.randn(hidden_size, hidden_size) * 0.01
self.Ui = np.random.randn(hidden_size, hidden_size) * 0.01
self.Uo = np.random.randn(hidden_size, hidden_size) * 0.01
self.Uc = np.random.randn(hidden_size, hidden_size) * 0.01
self.bf = np.zeros((hidden_size, 1))
self.bi = np.zeros((hidden_size, 1))
self.bo = np.zeros((hidden_size, 1))
self.bc = np.zeros((hidden_size, 1))
def forward(self, x_t, h_prev, c_prev):
f_t = sigmoid(np.dot(self.Wf, x_t) + np.dot(self.Uf, h_prev) + self.bf)
i_t = sigmoid(np.dot(self.Wi, x_t) + np.dot(self.Ui, h_prev) + self.bi)
o_t = sigmoid(np.dot(self.Wo, x_t) + np.dot(self.Uo, h_prev) + self.bo)
c_hat_t = tanh(np.dot(self.Wc, x_t) + np.dot(self.Uc, h_prev) + self.bc)
c_t = f_t * c_prev + i_t * c_hat_t
h_t = o_t * tanh(c_t)
self.cache = (x_t, h_prev, c_prev, f_t, i_t, o_t, c_hat_t, c_t, h_t)
return h_t, c_t
def backward(self, dh_t, dc_t, lr):
x_t, h_prev, c_prev, f_t, i_t, o_t, c_hat_t, c_t, h_t = self.cache
do_t = dh_t * tanh(c_t) * d_sigmoid(o_t)
dc_t += dh_t * o_t * d_tanh(tanh(c_t))
di_t = dc_t * c_hat_t * d_sigmoid(i_t)
df_t = dc_t * c_prev * d_sigmoid(f_t)
dc_hat_t = dc_t * i_t * d_tanh(c_hat_t)
dWf = np.dot(df_t, x_t.T)
dUf = np.dot(df_t, h_prev.T)
dbf = np.sum(df_t, axis=1, keepdims=True)
dWi = np.dot(di_t, x_t.T)
dUi = np.dot(di_t, h_prev.T)
dbi = np.sum(di_t, axis=1, keepdims=True)
dWo = np.dot(do_t, x_t.T)
dUo = np.dot(do_t, h_prev.T)
dbo = np.sum(do_t, axis=1, keepdims=True)
dWc = np.dot(dc_hat_t, x_t.T)
dUc = np.dot(dc_hat_t, h_prev.T)
dbc = np.sum(dc_hat_t, axis=1, keepdims=True)
dh_prev = np.dot(self.Wf.T, df_t) + np.dot(self.Wi.T, di_t) + np.dot(self.Wo.T, do_t) + np.dot(self.Wc.T,
dc_hat_t)
dc_prev = dc_t * f_t
self.Wf -= lr * dWf
self.Uf -= lr * dUf
self.bf -= lr * dbf
self.Wi -= lr * dWi
self.Ui -= lr * dUi
self.bi -= lr * dbi
self.Wo -= lr * dWo
self.Uo -= lr * dUo
self.bo -= lr * dbo
self.Wc -= lr * dWc
self.Uc -= lr * dUc
self.bc -= lr * dbc
return dh_prev, dc_prev
class Encoder: // Seq2Seq의 Encoder
def __init__(self, input_size, hidden_size, num_layers=4):
self.input_size = input_size
self.hidden_size = hidden_size
self.num_layers = num_layers // 사용할 layer의 개수
self.lstm_layers = [MyLSTMCell(input_size if i == 0 else hidden_size, hidden_size) for i in range(num_layers)] // 첫 layer는 입력값이 x_t이므로 (input_size, hidden_size), 이후의 layer는 입력값이 이전 layer의 hidden state이므로 (hidden_size, hidden_size)
def forward(self, inputs):
h = np.zeros((self.hidden_size, 1))
c = np.zeros((self.hidden_size, 1))
for index in inputs:
x_t = np.zeros((self.input_size, 1))
x_t[index] = 1
for layer in self.lstm_layers: // layer 순으로 연산 진행
h, c = layer.forward(x_t, h, c)
x_t = h // 현재 layer의 hidden state가 다음 layer의 입력값으로 사용
return h, c
def backward(self, dh, dc, lr):
for layer in reversed(self.lstm_layers): // 역전파는 layer의 역순으로 진행
dh, dc = layer.backward(dh, dc, lr)
return dh, dc
class Decoder: // Seq2Seq의 Decoder
def __init__(self, hidden_size, output_size, num_layers=4):
self.hidden_size = hidden_size
self.output_size = output_size
self.num_layers = num_layers // 사용할 layer의 개수
self.lstm_layers = [MyLSTMCell(hidden_size, hidden_size) for _ in range(num_layers)] // 첫번째 layer는 Encoder의 hidden state가 입력값, 이후의 layer는 이전 layer의 hidden state가 입력값이므로 (hidden_size, hidden_size) 고정
self.Wo = np.random.randn(output_size, hidden_size) * 0.01
self.bo = np.zeros((output_size, 1))
def forward(self, h, target_length):
outputs = []
x_t = h
h = np.zeros((self.hidden_size, 1))
c = np.zeros((self.hidden_size, 1))
for _ in range(target_length):
for layer in self.lstm_layers: // layer 순으로 연산 진행
h, c = layer.forward(x_t, h, c)
x_t = h // 현재 layer의 hidden state가 다음 layer의 입력값으로 사용
output = softmax(np.dot(self.Wo, h) + self.bo)
outputs.append(output)
return outputs
def backward(self, dh, dc, lr):
for layer in reversed(self.lstm_layers): // 역전파는 layer의 역순으로 진행
dh, dc = layer.backward(dh, dc, lr)
return dh, dc
class MySeq2Seq:
def __init__(self, input_size, hidden_size, output_size):
self.encoder = Encoder(input_size, hidden_size)
self.decoder = Decoder(hidden_size, output_size)
def train(self, inputs, targets, lr):
h, c = self.encoder.forward(inputs)
outputs = self.decoder.forward(h, len(targets))
loss = sum(-np.log(softmax(y)[targets[i]] + 1e-7) for i, y in enumerate(outputs))
self.backward(outputs, targets, lr)
return loss
def backward(self, outputs, targets, lr):
dh, dc = np.zeros((self.encoder.hidden_size, 1)), np.zeros((self.encoder.hidden_size, 1))
self.decoder.backward(dh, dc, lr)
self.encoder.backward(dh, dc, lr)후기
이전에 읽어본 논문을 이번에는 코드로 구현해 보았는데 확실히 논문을 읽기만 할 때와는 느낌이 많이 다른 것 같습니다. 논문을 읽기만 할 때는 대략적인 컨셉 정도만 확인하는 느낌이었다면 구현을 할 때는 연산의 과정에 대해 좀 더 많이 알게 된 것 같습니다. 앞으로도 꾸준히 논문 구현에 도전해 보며 논문을 좀 더 깊게 이해할 수 있도록 노력해야 할 것 같습니다.
