[논문리뷰 | CV] A Body Part Embedding Model With Datasets for Measuring 2D Human Motion Similarity (2021) Summary
[논문리뷰]
목록 보기
27/42
Title
- A Body Part Embedding Model With Datasets for Measuring 2D Human Motion Similarity

Abstract
- 인간의 동작 유사성은 액션 인식, 이상 탐지, 인간 성능 평가 등 여러 분야에서 활용되고 있음.
- 동작 유사성 측정은 큰 dataset이 부족하기 때문에 큰 관심을 받지 못했음.
- 이 문제를 해결하기 위해 이 논문에서는 모델 훈련을 위한 합성 동작 데이터셋과 동작 유사성 평가를 위한 실세계 비디오 클립 쌍의 인간 주석을 포함하는 dataset을 소개함.
또한, 이러한 데이터셋에서 동작 유사성을 계산하기 위해, 각 인체 부분의 다른 동작 간의 유사성을 측정하기에 적합한 동작 임베딩을 생성하는 딥러닝 모델을 제안함.
- 네트워크는 제안된 동작 변화 손실로 훈련되어 미묘하게 다른 동작까지 견고하게 구별함.
- 제안된 접근법은 동작 유사성 예측과 인간 주석 간의 상관관계 면에서 다른 기준선을 고려하여 성능을 향상시키면서 실시간 액션 분석에 적합함.
1. Introduction
- 인간의 동작은 각 신체 관절의 이동과 회전의 결합이며, 이는 인간에게 고유한 많은 정보를 포함하고 있음.
- 특히, 인간의 동작을 분석함으로써 얻을 수 있는 동작 유사성은 다양한 응용 분야에서 활용됨.
-> 동작 유사성은 액션 인식을 위해 사용될 수 있으며, 임무 수행의 품질을 판단하거나 비정상적인 행동을 식별하는 데에도 사용됨.
-> 다양한 카메라에서 목표 대상을 일치시키기 위한 동작 비교 시스템은 유용함.
하지만 동작 분석은 지금까지 큰 관심을 받지 못했음.
첫째, 동작 유사성을 측정하는 것은 어려운 문제임.
-> 다른 카메라 뷰 or 인간의 신체 구조로 인해 비슷한 동작에도 2D 관절 좌표가 다양하게 나타나므로, 관절 좌표만을 사용하여 유사성을 직접 측정하는 것은 불가능함.
둘째, 동작 유사성을 학습하기 위한 대규모 데이터셋의 가용성이 제한적임.
- 제안된 모델은 Adobe Mixamo에서 얻은 데이터셋을 기반으로 학습
- 이 연구의 목표는 기존의 동작 유사성 학습 방법과 대조적으로 skeletons와 camera views로부터 동작 임베딩을 학습하는 것임.
- 실제 데이터에서 제안된 모델의 성능을 평가하기 위해 NTU RGB+D 120 데이터셋을 사용함.
- 제안된 방법은 다른 기준 모델과 비교하여 평가된 유사성 점수와 인간의 인식 사이의 상관 관계가 가장 높았음.
요약하면, 이 연구의 주요 기여는 다음과 같음.
(1) 동작 유사성을 측정하고 신체 부분의 움직임 차이를 식별할 수 있는 Body part embedding (BPE) 모델
(2) 유사한 동작에서 미묘한 변화를 구별하는 동작 변화 손실
(3) 모델 훈련과 검증을 위한 데이터셋 소개

- 이 모델은 인간 관절 좌표의 연속을 입력으로 받아 몸 부위의 임베딩을 생성하며, 이
임베딩은 다른 동작 간의 유사성을 분석하는 데 사용됨.
2. Related Work
2.1. Motion Similarity
- 사람의 동작 유사성을 파악하는 것은 비디오 검색 시스템을 위해 중요하며, 다양한 연구들이 이를 위한 방법을 제안해옴.
- Ferrari 등은 이미지의 인간 자세를 분석하여 비디오와의 유사성을 평가함.
- 한편, Kim과 Kim은 두 춤의 자세를 비교함.
- 우리의 연구는 두 이미지 대신 동작 시퀀스 간의 유사성을 직접 평가함.
- Shen 등의 연구는 객체와의 상호 작용에 중점을 둔 동작 유사성을 제안했으나, 실시간으로 적용하기는 어려웠음.
Human motion analysis with deep metric learning의 연구에서는 LSTM을 사용하여 동작의 임베딩을 생성하였고, 이 architecture를 기준으로 우리의 모델 성능을 평가함.
2.2 Human Body Embedding
- 인간 행동 이해를 위해 몸을 여러 부분으로 분해하고 각 부분의 표현을 만드는 방법이 연구되어왔음.
- Choutas 등은 각 관절의 움직임을 분석하였고, Guo와 Choi는 팔다리와 토르소의 동작을 예측하기 위해 지역 표현 학습의 중요성을 강조함.
- Liu 등은 신체의 다양한 부분에 중점을 둔 표현 방법을 제안했으며, 기타 연구들도 몸의 다양한 부분과 그들의 상호작용을 분석하여 행동의 이해를 깊게 하려고 하였음.
2.3. Datasets for measuring the Similarity
- 기존 dataset은 동작의 유사성을 잘 반영하지 못하였음.
- Mori 등의 연구에서는 특정 임계값을 기준으로 자세의 유사성을 자동 주석으로 달았지만, 이 방법은 실제 인간의 인식과 일치하지 않았음.
- 또한, 같은 액션 라벨 내에서도 실제로는 유사하지 않은 동작들이 있어서, 이러한 내부 차이를 반영하기 어려웠음.
- 이러한 문제점을 해결하기 위해, 약 2만 쌍의 비디오에 대한 동작 유사성 주석을 포함하는 새로운 데이터셋을 제안함.
2.4. Triplet and Quadruplet Losses
- Triplet Losss는 세 이미지 (anchor, positive sample, negative sample)를 사용하여 특정 간의 거리를 학습하는 방식임.
- 이 방식은 다양한 연구에서 활용되었고, 특히 객체 인식 or 3D 포즈 예측에서 효과적이였음.
- 일부 연구들은 네 개의 이미지를 활용하여 더 정교한 특정 거리 학습을 시도함.
- 이 연구의 목표는 실제 동작의 변화를 반영하여 잠재 공간에서의 거리를 정확히 학습하는 것임.
2.5. Dynamic Time Warping
- Dynamic Time Warping (
DTW)은 두 시계열 데이터 간의 최적 정렬을 결정하는 알고리즘임.
-서로 다른 길이의 두 시계열 데이터를 정렬하기 위해 DTW는 동적 프로그래밍을 사용하여 비용 행렬을 구성함.
-각 행렬 원소는 두 데이터 포인트 사이의 비용을 나타냄.
-최적의 정렬은 비용의 합이 가장 작은 경로를 통해 얻어짐.
-이렇게 얻어진 경로는 동일한 시간 포인트가 아닌 유사한 패턴의 포인트와 일치함.
-이 DTW를 사용하여 두 움직임을 정렬하고 그들 사이의 유사성을 계산함.
다시 정리하면,
DTW
- 두 시계열 데이터 간의 유사성을 측정하기 위한 기법임.
- 이는 두 시계열 데이터 간의 시간적인 차이를 고려하여 유사성을 비교하는 데 매우 유용한 기법임.
기본 아이디어는 다음과 같음.
(1) 두 시계열 데이터가 주어졌을 때, 한 데이터의 시점을 다른 데이터의 다른 시점과 매칭시켜 두 데이터 간의 유사성을 비교함.
(2) 이 때, 모든 가능한 매칭 조합을 고려하는 것이 아니라, 가장 비슷한 패턴을 가진 부분끼리 매칭될 수 있도록 동적 프로그래밍 기법을 사용
(3) 결과적으로, 두 시계열 데이터 간의 최소 거리(또는 비용)를 구할 수 있음.
- 간단한 예로, 두 사람이 각기 다른 속도와 리듬으로 같은 노래를 불렀다고 생각해보면,
- 한 사람은 노래를 빠르게 부르고, 다른 한 사람은 느리게 부른다. 이 때, DTW를 사용하면 두 노래의 유사성을 시간의 차이를 고려하여 비교할 수 있음.
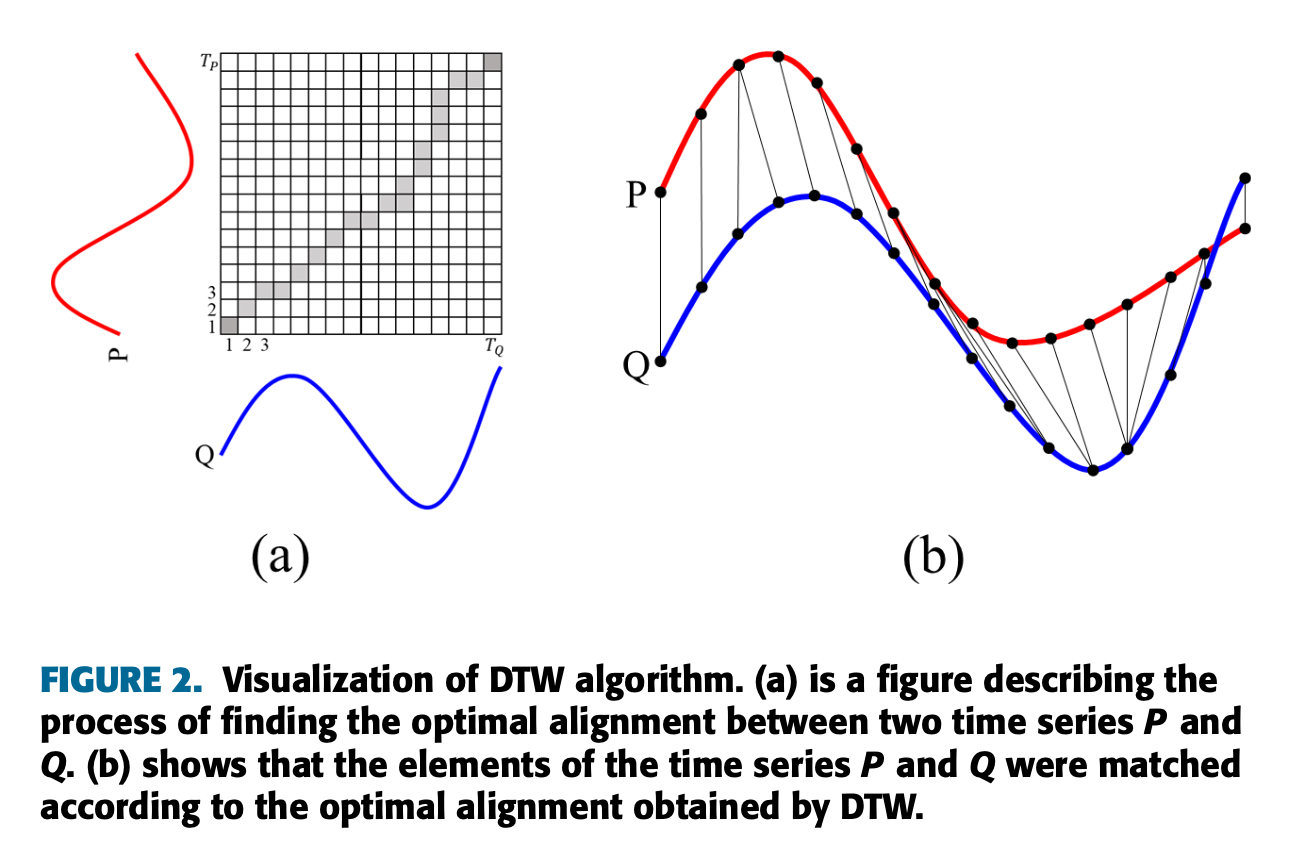
- 위의 그림은 DTW 알고리즘의 시각화임.
(a)는 두 시계열 P와 Q 사이의 최적의 정렬을 찾는 과정을 설명하는 그림임.
(b)는 DTW로 얻은 최적의 정렬에 따라 시계열 P와 Q의 요소가 어떻게 매칭되었는지 보여줌.
3. Method
- 동작 유사성 평가에 필요한 고유한 동작 임베딩을 인코딩하기 위한 학습 기반 방법을 제안
Learning character-agnostic motion for motion retargeting in 2D연구의 프레임워크에서 영감을 받아, 전체 몸 대신 각각의 신체 분위(Section III-A1)를 재구성하기 위한 모델을 훈련시켜 특정 손 or 발의 움직임을 파악함.
- 동작 유사성을 견고하게 계산하기 위해 motion variation loss(Section-III-A2)를 제안함 (Section III-B)
3.1. Body Part Embedding Model
3.1.1. Network Architecture
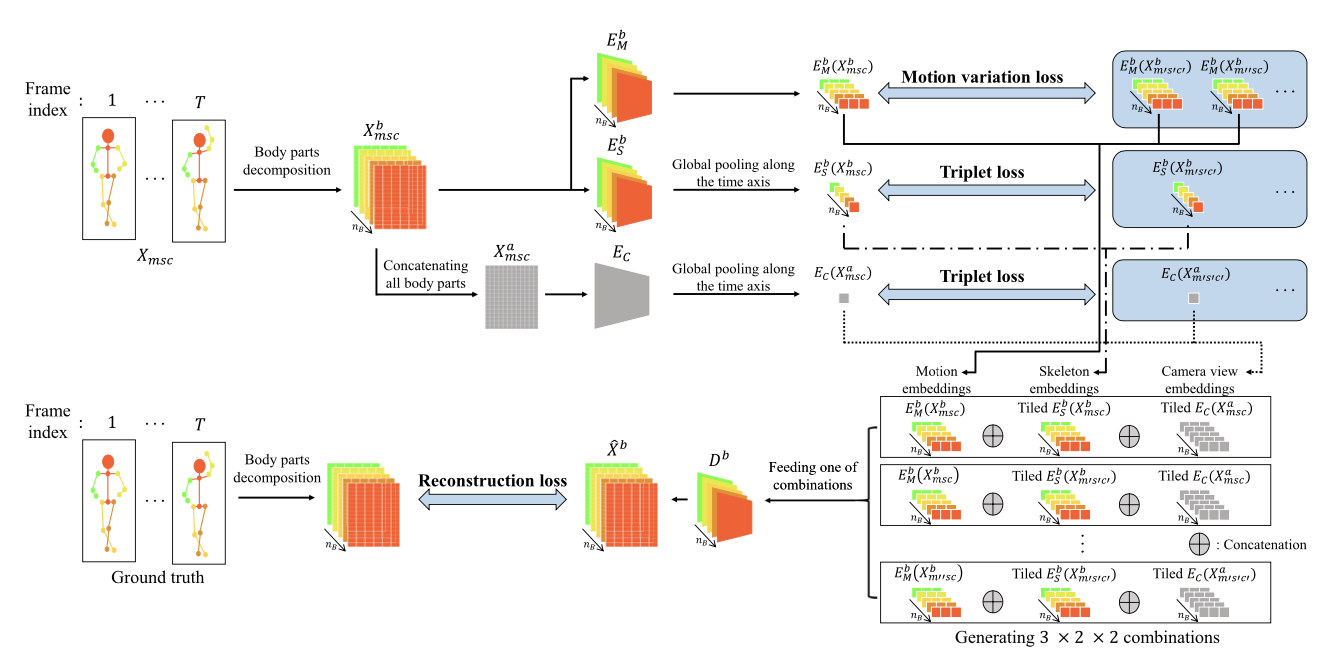
- 학습 세트의 motion, skeleton, camera view 속성을 각각 , , 로 표현함.
- 총 손실을 계산하려면 각각 , , 의 부분 집합인 = {m, m′, m′′}, = {s, s′}, = {c, c′}가 필요함.
m과 m′′은 다른 특성(motion variation)을 가진 동일한 motion class에서 와야 하며,m′은 다른 class의 motion이어야 함.
s와 s′는 다른 몸체 구조를 가진 두 골격을 나타내고,c와 c′는 3D motion이 2D로 투영될 때의 시야 각도임.
- 는 골격의 관절 수이고, 는 motion 순서의 시간 길이임.
- 는 5개의 신체 부위로 구성된 세트로, 골격을 분해하여 신체 부위 임베딩을 구성함.
3.1.2 Losses
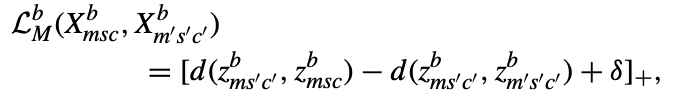
- motion triplet losss는 위와 같음.
- 하지만 이 손실은 sample이 얼마나 유사한지에 대한 정보를 포함하고 있지 않음.
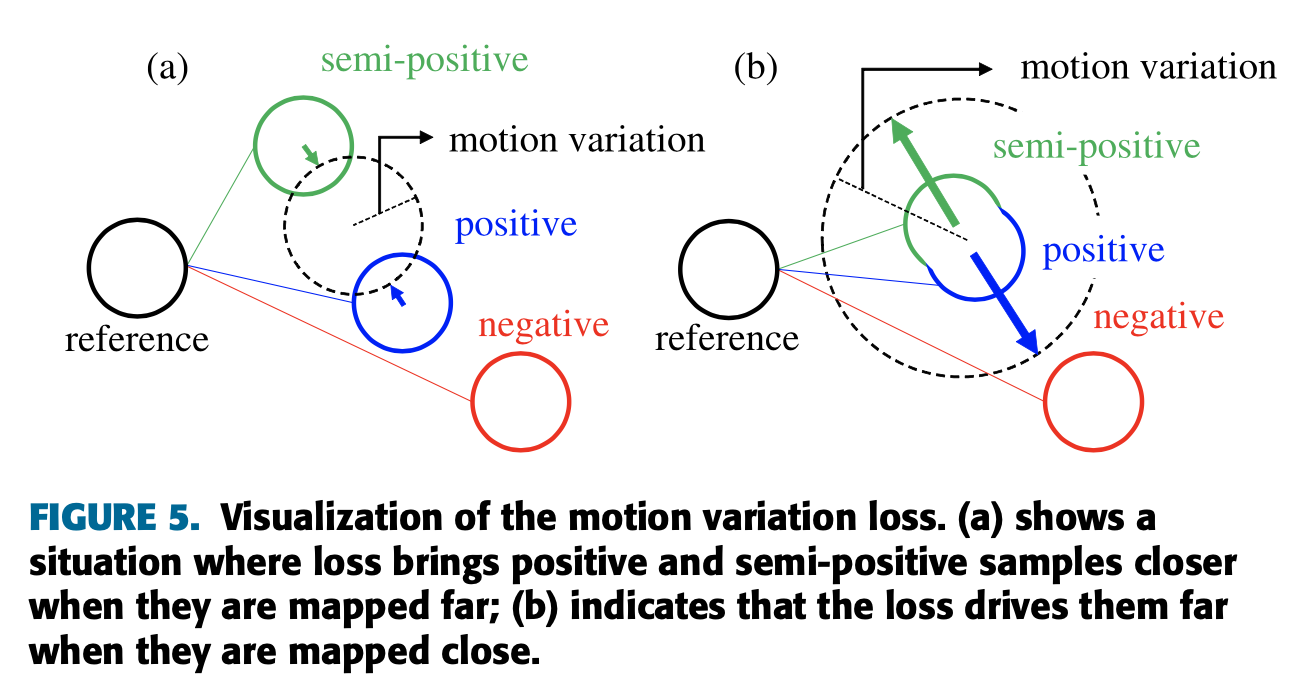
- 이러한 motion triplet losss의 제한을 극복하기 위해, 동일한 행동 범주 내의 sample 간의 motion variation score를 활용하여 loss을 제안함.
- 위의 그림에서처럼 제안된 motion variation losss는 motion variation에 의해 정의된 특정 거리에서 positive and semi-positive samples을 투영함.

- motion m에 대해 이러한 변수 중 하나에 해당하는 각 요소를 가진 특성 벡터를 vm이라고 가정하면, m과 m''는 동일한 motion class에 속하므로 vm과 vm''는 동일한 nvm 변수 수를 가짐.
- 그런 다음 m과 m'' 사이의 motion variation var(m, m'')는 위와 같이 정의함.
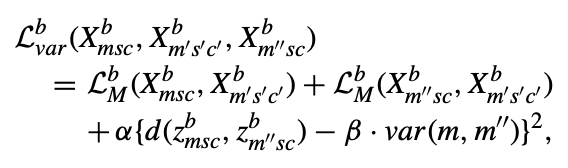
- 여기서 는 거리 척도를 나타내며, 하이퍼파라미터 α와 β는 각각 1과 0.1로 설정됨.
- 이를 사용하면, positive and semi-positive samples의 모션 임베딩 벡터가 특정 벡터에 의존하게 될 것으로 기대됨.
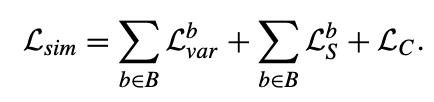
- skeleton & camera view Embeddings의 경우, 와 triplet loss는 맨위와 같은 방식으로 얻을 수 있음.
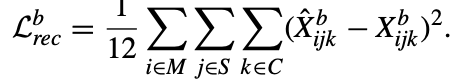
- 위의
reconstruction error term은 motion, skeleton, camera view Embedding vectors를 분리하는 데 도움을 줌.
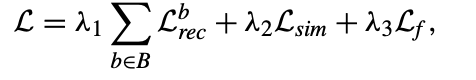
Learning character-agnostic motion for motion retargeting in 2D에서 사용된 foot velocity loss 는 손과 발에서 큰 오차를 일으키는 foot skating 현상을 방지하기 위해 적용됨.
- 최종 손실은 개별 손실 항의 가중치 합임.
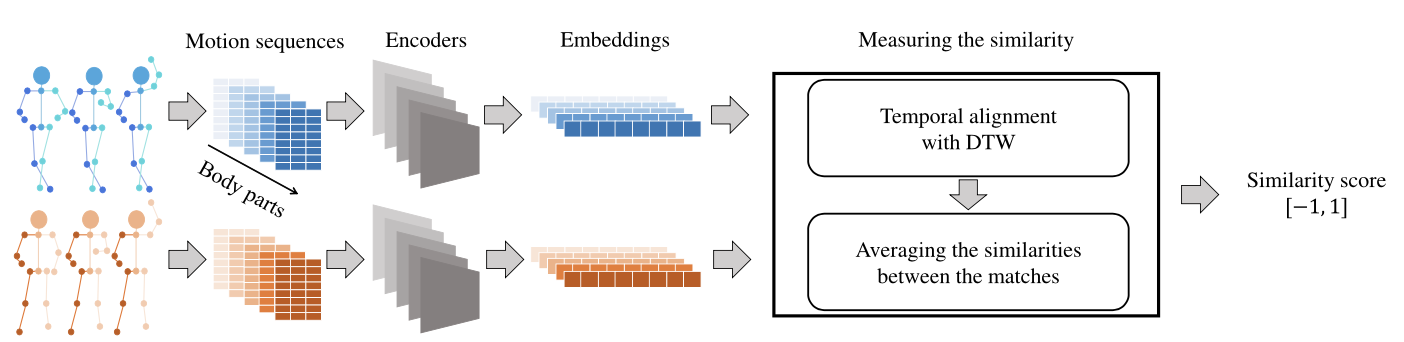
3.2. Measuring Motion Similarity
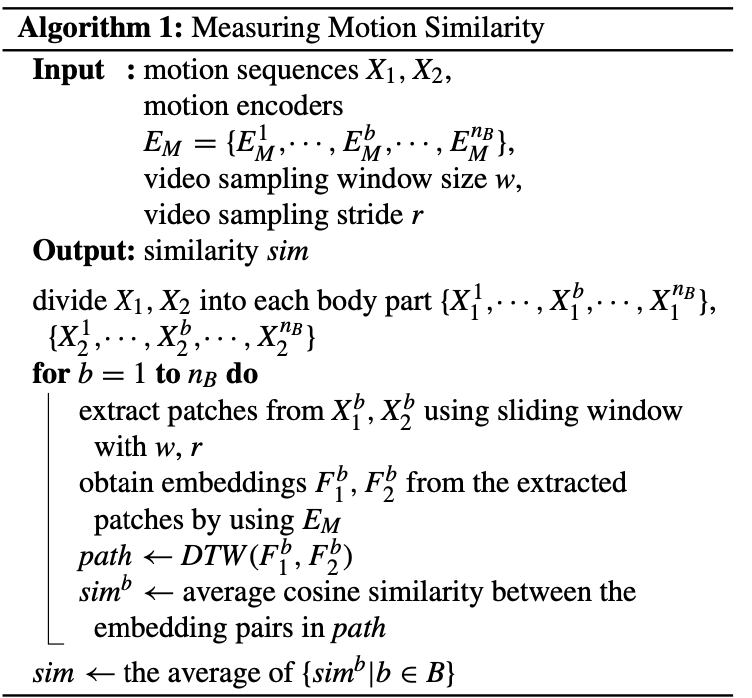
- Motion간의 유사성 측정은 위의 알고리즘에서 설명됨.
- 두 sequence 과 를 비교하여 이 두 sequence는 몸체 부분별로 분할되고, 슬라이딩 윈도우 방식을 사용하여 작은 패치로 나누어짐.
- 이 패치들은 동작 인코더를 통과하여 임베딩(특징 벡터)으로 변환됨.
- 이후 DTW 알고리즘을 사용하여 두 sequence의 최적 정렬을 찾기!
- 각 몸체 부분의 유사성은 이 정렬을 기반으로 average cosine similarity을 통해 계산되며, 전체 동작의 유사성은 몸체 부분별 유사성의 평균으로 얻어짐.
4. Datasets
- 모델 학습을 위해 합성된 3D 동작 데이터셋을 사용함.
- 제안된 모델의 실세계 데이터에 대한 동작 유사성 평가 능력을 보여주기 위해
NTU RGB+D 120 dataset에수동으로 주석을 달았음.
- 후자 dataset은 성능 평가에만 사용됨.
4.1. Synthetic Motion Dataset: SARA Dataset
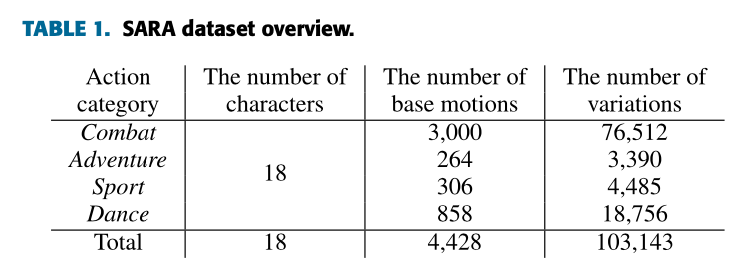
- 데이터셋의 통계는 위의 표1과 같음.
- 저자는 동작 유사성에 대한 추론에 적합한 동작 임베딩을 생성하기 위한 모델을 훈련시키기 위해
Synthetic Actors and Real Actions(SARA)'라는 3D 동작 데이터셋을 구축함.
- 8개의 다른 배우 (즉, 동작을 수행하는 캐릭터)의 조합으로 동작 연속 데이터를 생성함.
- 이 캐릭터들은 Adobe Fuse 소프트웨어로 뼈대 형태로 렌더링되었음.
- 32 frame 이상의 각 동작을 포함하는 네 가지 동작 카테고리 (전투, 모험, 스포츠, 댄스)를 선택함.
- SARA 데이터셋에는 4,428개의 기본 동작 (예: 댄싱, 점프)이 있음.
- Mixamo는 각 동작의 다양한 특성 (예: 에너지)을 조절하여 다른 동작 특성을 생성할 수 있게 사용자에게 허용함.
- 특성 변수의 값은 [-1,1] 범위 내에 있으며, SARA 데이터셋에서는 {-1, -0.5, 0, 0.5, 1} 중 하나로 설정되었음.
- 이 매개 변수는 동작에 따라 다르게 구성되었는데, 각 시퀀스 프레임은 모든 신체 부위의 17개 관절의 3D 좌표를 제공하며, 우리는 2D 투영을 통해 샘플을 생성하였음.
4.2. NTU RGB+D 120 Similarity Annotations
- 실세계에서의 동작 유사성을 평가하기 위해 NTU RGB+D 120 datset에 대한 동작 유사성 주석을 수집함.
NTU RGB+D 120 dataset은 106명의 사람들의 120개의 다양한 동작을 포함하는 114,480개의 동영상으로 구성된 동작 인식 dataset임.
- 이 dataset의 원래 동영상은 AMT에서 실제 동작 유사성을 얻기 위해 사용되었지만, 우리의 모델에서는 동작 유사성을 추정하기 위해 2D skeleton sequences만 사용되었음.
- 이 데이터셋 중 일부만 사용되었는데, 이 데이터셋에는 읽기, 쓰기, 전화 통화와 같은 작은 움직임을 가진 행동들도 있기 때문임.
- 이러한 동작들을 제외한 후, 시각적 검사를 기반으로 큰 움직임과 잘 정의된 움직임을 가진 21개의 동작이 선택되었고, 그런 다음 각 동작에 대해 39명의 사람들의 두 개의 동영상이 샘플링되었음.
총 샘플링된 비디오 클립의 수는 1,638개!
- 샘플링된 동영상을 사용하여 AMT의 사람들로부터 동작 유사성 점수를 얻었음.
- 각 동영상 쌍에 대한 동작 유사성은 1점(완전히 다른 동작)에서 4점(동일한 움직임)까지의 4점 척도로 평가됨.
- 한 쌍의 유사성 점수는 AMT의 적어도 열 명의 작업자들로부터 수집된 점수의 평균임.
- 가능한 모든 후보 중에서 20,093개의 임의로 샘플링된 비디오 쌍에 대한 주석이 수집되었고, 이 주석들은 모델을 평가하기 위해 모두 사용되었고, 훈련을 위해 사용되지는 않았음.
- NTU RGB+D 120 dataset에는 부정확한 skeleton data가 있었는데,
- 이를 해결하고자 2D 관절 주석을 생성하기 위해 COCO 2017 valid 세트에서 큰 객체에 대한 평균 정밀도가 0.709인 Multi-PoseNet(MultiPoseNet:Fastmulti-person pose estimation using pose residual network)의 복제본을 사용하여 새로운 2D 관절 주석을 생성함.

- 위의 그림은 NTU RGB+D 120 데이터셋에서 AMT 주석 쌍의 예시 그림임.
- (a), (b), (c), (d)는 각각 점수 4,3,2,1의 예시이고, (e)는 수집된 총 점수의 히스토그램임.
5. Experiments
- 먼저 모델에 대한 구현 세부 사항을 제시한 다음
- 두번째, NTU RGB+D 120 쌍에 대한 수집된 주석과 여러 모델이 생성한 유사성 사이의 상관관계 측정 소개
- 그 다음 모델의 동적 잠재 공간 시각화 소개
- 우리의 프레임워크가 실세계 작업에 어떻게 적용될 수 있는지 설명
- 모든 실험에서는 훈련을 위해 SARA dataset만 사용되며, 평가를 위해 NTU RGB+D 유사성 주석이 사용됨.
5.1. Preprocessing
- motion sequences는 32 frames 단위로 나ㄴ어지고, SARA dataset은 훈련과 검증용으로 분할됨.
- 실세계에서는 카메라와의 거리에 따라 사람의 크기가 다르기 때문에 이를 조정하기 위해 스케일 인자를 사용하여 skeleton size를 조절함.
- 각 신체 부위마다 참조되는 관절을 기준으로 좌표를 상대적으로 변경하고, 이 좌표들은 z-정규화를 통해 최종 입력으로 정규화됨.
5.2. Network Structure

- 각 계층 사이에는 배치 정규화와 LeakyReLU 활성화 함수가 사용됨.
- 각 신체 부위에 대한 motion Encoder는 해당 부위의 2D sequence를 입력으로 받음.
- torso motion Encoder의 임베딩 차원은 128로, 다른 Encoder보다 크게 설정되어 있음.
- Skeleton Encoder도 Motion Encoder와 같은 입력을 사용하지만, global max pooling을 사용하여 시간 정보를 압축함.
- 카메라 뷰 Encoder는 신체 부위의 연결을 입력으로 사용하고, average pooling을 사용하여 64차원의 임베딩을 생성함.
- Decoder는 각 신체 부위에 대한 추정치를 출력함.
5.3. Comparisons with the other Baselines

- 모델의 예측과 주석된 유사도 점수 간의 상관관계를 계산하여 모델이 인간의 인식과 얼마나 비슷한지 평가함.

- 제안된 BPE 모델로 가장 높은 상관 결과를 얻음.
- 우리의 방법은 유사도 평가와 인간의 인식 간의 상관 결과를 크게 향상시킴.
- 모든 경우에서 제안된 BPE 모델을 기반으로 한 유사도 상관 결과는 Body flip을 사용하여 SoTA
-> 이는 사람들이 수평으로 뒤집힌 동작을 동일한 동작으로 간주한다는 것을 의미함.
- 마지막으로, 모든 방법에 대해
MultiPoseNet으로 수정된 motion sequence를 사용하면 상관 점수가 더 높아진다는 것을 확인했음.
-> 저자는 정확하지 않는 주석이 달린 자세를 정제하는 것이 이러한 영향을 미쳤다고 생각한다고 함.

(a)의 왼쪽 부분에서는 SARA 검증 세트의 동작 클래스가 색상으로 군집화되어 있음.
- 검은색 원 안에 있는 짙은 초록색 (
Adventure152)과 연한 노란색 (Dance132)은 팔꿈치를 구부리고 뒤로 기대어 서 있는 비슷한 동작을 나타냄.
(b)의 왼쪽 부분에서는 NTU RGB+D 120의 21개 샘플 동작의 시각화가 이루어져 있음.
- 오른쪽 상단에 위치한 파란색 (cheer up)과 빨간색 (stretch oneself)은 비슷한 동작을 나타냄.
5.4. Application
- 실제에서 제안된 동작 유사성을 어떻게 활용할 수 있는지에 대한 지침을 제공함.
목적
- 운동 (댄스, 요가, 피겨 스케이팅 등)의 성능을 평가하는 것은 제안된 모델의 자연스러운 응용 프로그램임.
시나리오
- 어떤 댄서가 기준 동작을 반복하는 것을 목표로 함.
- 우리의 목표는 댄스가 진행됨에 따라 주기적으로 성능을 평가하는 것임.
- 이를 위해 같은 댄스를 수행하려고 하는 두 사람의 시간적으로 정렬된 비디오를 비교
동작 유사성
- window size = 32, stride = 32를 사용하여 두 sequences 간의 동작 유사성을 얻음.
포즈 추출
- 관절의 위치를 추출하기 위해 (MultiPoseNet:Fastmulti-person pose estimation using pose residual network)의 방법을 사용했으나, 다른 인간 포즈 추정 알고리즘이 적합할 수 있음.
성능
- 두 비디오 클립을 비교하는 데 제안된 방법은 약 7.8초가 걸렸으며, 포즈 추정 추출을 제외하고는 관절 데이터 전처리, 네트워크 추론, 및 동작 유사성 계산을 포함함.
제한점
- 제안된 방법은 잘못된 인간 관절의 정확한 위치나 행동을 더 유사하게 만들기 위해 위치를 어떻게 수정해야 하는지에 대한 피드백을 제공하지 않음.
- 그러나 우리의 방법은 수동으로 정의된 규칙을 기반으로 동작 유사성을 평가할 필요 없이 sequence에 대한 유사성 점수를 제공함.
6. Conclusions
- 이 논문에서는 두 동작 sequence의 유사성을 측정하는 방법을 제안함.
- 유사성을 계산하기 위해 각 신체 부위에 대한
동작 임베딩 벡터를 생성하고, 비슷한 동작을 구별하기 위해동작 변동 손실 항을 도입함.
- 모델 학습을 위한 합성 데이터셋을 구성함.
- 평가를 위해 NTU RGB+D 120 데이터셋의 실제 주석을 수집했고, 평가 결과 이 방법론이 다른 기준 모델에 비해 SoTA 달성
- 이 접근 방식은 동작 sequence에 의존하기 때문에 정확한 자세 추정이 가능할 때 유사성 모델이 가장 잘 수행됨.
- 하지만 가려짐, 붐비는 장면과 같은 어려운 상황에서 자세 추정이 만족스럽지 않을 수 있고, 이러한 상황속에서 유사성을 측정하는 것은 앞으로의 연구 과제임.
- 확장된 모델이 정렬 & 비정렬된 액션 데이터셋과 데이터 기반 sequence 정렬을 사용하여 더 나은 유사성 예측을 생성할 것으로 기대함.
- 동작 유사성을 적용하여 액션 인식 or 사람 재식별과 같은 기존의 작업의 성능을 평가하는 것도 가능함.
🎯 Summary
- 저자가 뭘 해내고 싶어 했는가?
- 저자는 동작의 유사성을 평가하기 위한 새로운 방법을 제안하고자 함.
- 이 방법은 기존의 방법들보다 더 인간의 인식과 유사한 결과를 가져오기 위해 설계됨.
- 제안된 모델은 여러 동작 시퀀스 간의 유사성을 비교하고 평가하기 위해 사용됨.
- 이 연구의 접근 방식에서 중요한 요소는 무엇인가?
- 몸 부위 분해 (Body Part Embedding): 전체 몸 대신 개별 몸 부위의 동작을 분석하여 더 상세한 동작 정보를 캡처
- 손실 함수: 재구성 손실과 동작 변동 손실을 포함하여, 모델이 세밀한 동작의 변화도 포착할 수 있게 함.
- DTW (Dynamic Time Warping): 두 시퀀스 간의 최적의 정렬을 찾기 위해 사용됨.
- 어느 프로젝트에 적용할 수 있는가?
- 댄스, 요가, 피겨 스케이팅과 같은 운동의 성능을 평가하는 데 유용할 것임.
- 댄서의 움직임을 기준 움직임과 비교하여 성능을 평가하는데 사용할 수 있음.
- 참고하고 싶은 다른 레퍼런스에는 어떤 것이 있는가?
- MultiPoseNet:Fastmulti-person pose estimation using pose residual network
-> 여러 사람의 포즈를 빠르게 추정하기 위한 방법을 제안
- NTU RGB+D 120: A large-scale benchmark for 3D human activity understanding
-> 3D 인간 활동 이해를 위한 대규모 벤치마크로, 다양한 동작을 포함하는 큰 데이터셋
- 느낀점은?
- 'Learning Character-Agnostic Motion for Motion Retargeting in 2D' (2019) 논문을 먼저 읽고 이 논문을 읽었던지라 내용 이해하기 수월했음. (무조건 앞 논문을 읽고 봐야됨)
- Body Part Embedding하는 것이 핵심인듯함. motion을 sequence로 풀어내는 부분이 인상적이였음. 그리고 DTW 알고리즘을 사용하여 최적의 정렬을 사용하는 부분도 인상적이였음.
- 동작의 유사성을 연구하는 것은 매우 흥미로움. 특히 스포츠와 연관해서 연구하면 좋을 듯함. 운동선수들이 자신의 동작을 전문가나 기준 동작과 비교하여 훈련을 최적화하고 향상시키길 소망함.
📚 References
논문

AI 전문가가 되기 위해 [a-zA-Z]까지 정리하는 거나입니다 😊