Title
- A ConvNet for the 2020s
- ConvNeXts

Abstract
- 2020년대의 시각 인식 분야는 Vision Transformers(ViT)의 도입으로 시작되었고, 그 당시 이미지 분류 모델에서 SoTA였던 ConvNets를 뛰어넘음. 그 이후 Vision Task에서 Transformer 연구에 집중!
- 이 논문은 CNN에 Transformer 구조 & 최신 기법들을 적용한 ConvNeXt 모델을 제안하고, ViT와 Swin Transformer보다 높은 성능을 통해 CNN이 여전히 강하다는 것을 주장함.
- 결과적으로 Transformer가 발전했지만, CNN의 특징을 갖추지 못해 inductive bias 문제를 극복하기 위해 초기 방식으로 돌아감
- Swin Transformers에서도 CNN의 역할이 매우 중요하였고, 'CNN만 가지고 어디까지 성능을 도출할 수 있을까?'는 물음으로 이 논문이 시작됨.
0. Background
1. Introduction
- 2010년대 기존 CNN모델은 AlexNet, VGG, Inception, ResNet 등 Computer Vision의 새로운 시대를 시작함.
- 하지만 Transformers 도입과 ViT의 출현으로 인해 network architecture가 변하기 시작함.
- 본 연구는 ViT 이전과 이후의 모델들 간의 차이를 최소화하고 순수한 ConvNet의 최대 성능을 탐색하는 것을 목표로 함.
- ResNet50을 기반으로 계층적인 Transformer 구조를 CNN 방식으로 현대화하여 성능을 점진적으로 향상시킨 ConvNeXt라는 새로운 모델을 도입
2.Modernizing a ConvNet: a Roadmap
- ResNet에서 Transformer와 유사한 ConvNet으로의 변화 경로를 제공
- 두 가지 모델 크기를 고려하였고, 간단하게 ResNet-50 / Swin-T 복잡도 모델의 결과를 제시함.
- 어떠한 attention-based 모듈을 도입하지 않고, 표준 ConvNet(ResNet)을 계층적인 vision Transformer로 최신화함.
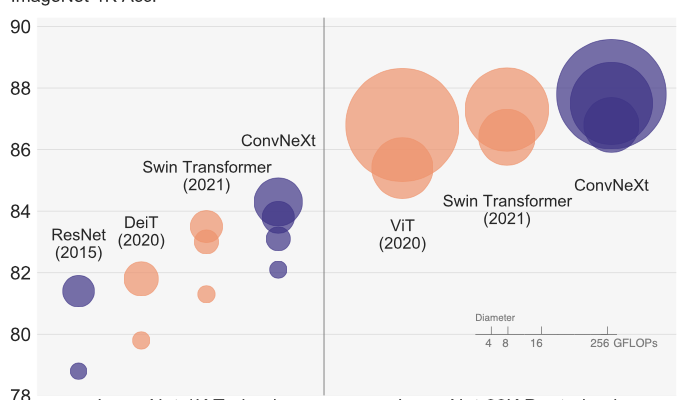
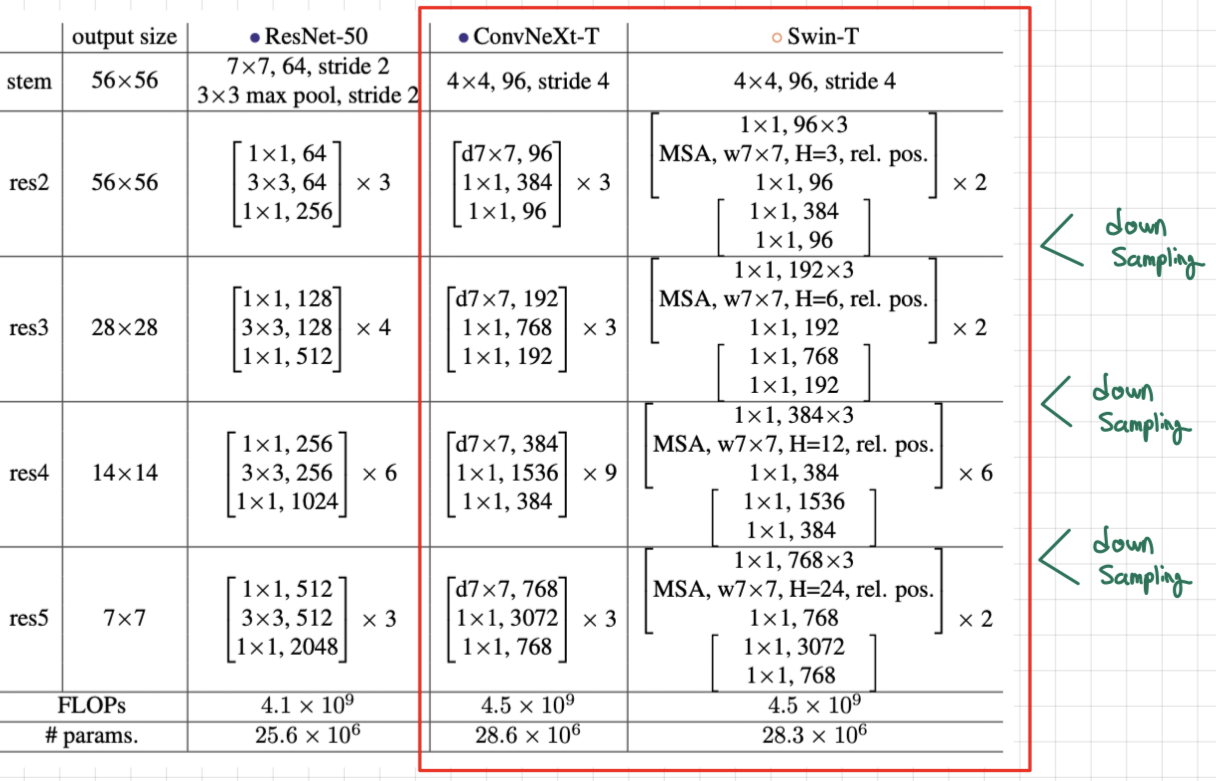
최신화된 기법으로 튜닝한 ResNet-50 vs Swin Transformer 비교
2.1. Training Techniques
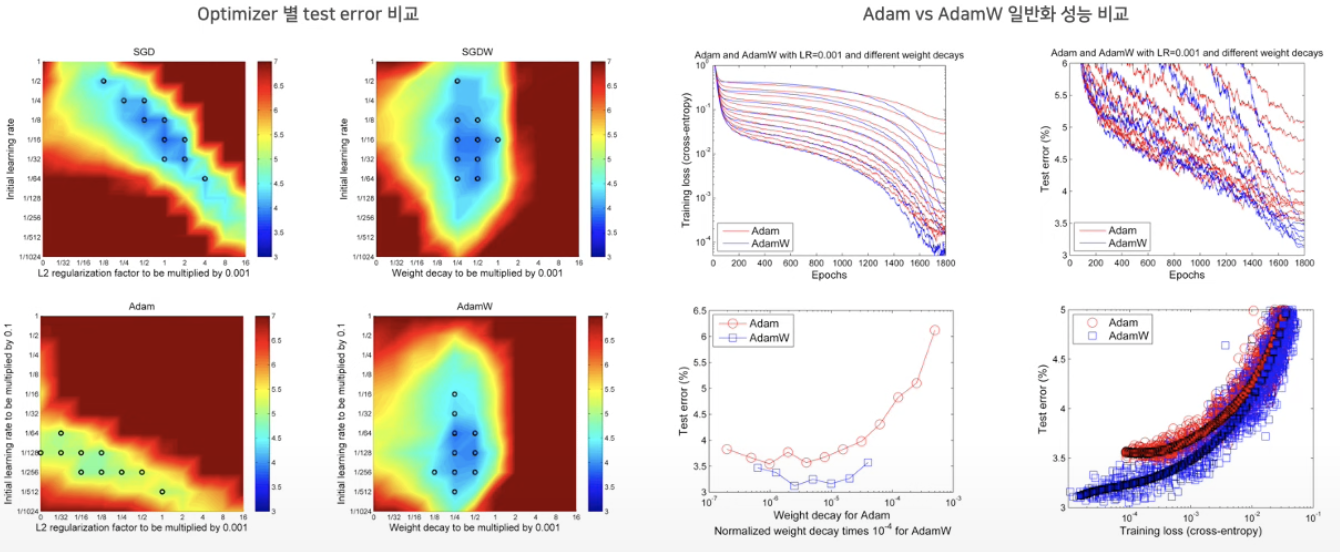
- 이 연구에서는 대부분의 최신 연구에서 선호하는 AdamW 최적화 기법을 사용하여 학습을 수행함.
- AdamW는 가중치 감소와 학습률 사이에서 독립성을 보이며 다른 방식에 비해 일반화 능력이 뛰어남.
2.2 Method
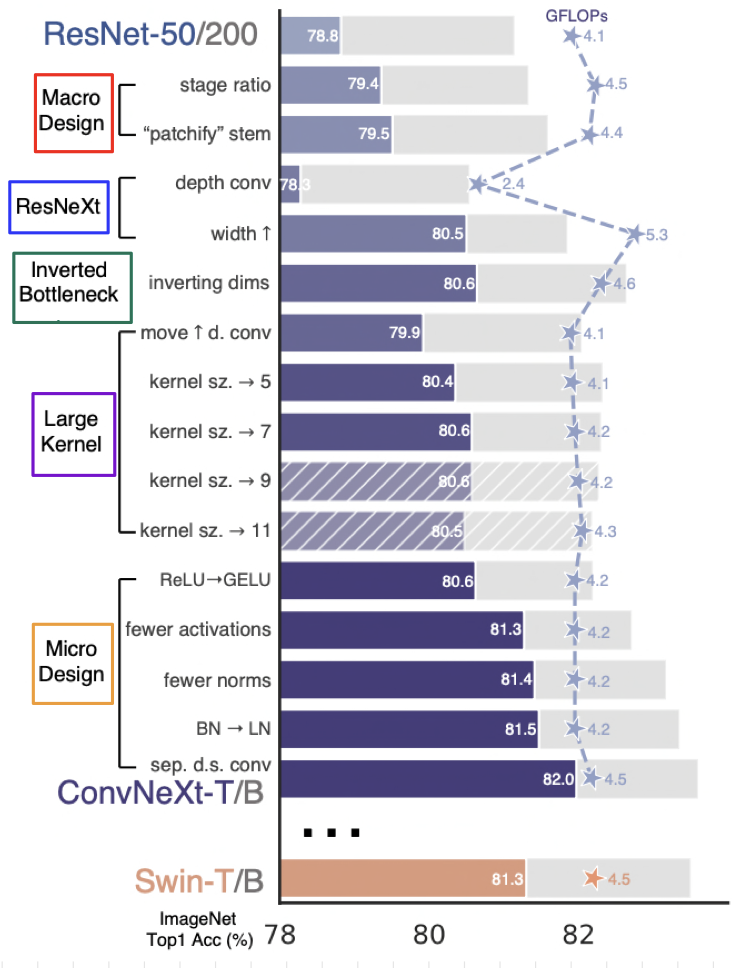
- ConvNet을 최신화하기 위해 (Swin Transformer 구조화하기 위해) 어떠한 변화를 주었는지 크게 5가지로 구분하여 모델 구조 변화를 정리함.
2.2.1. Macro Design
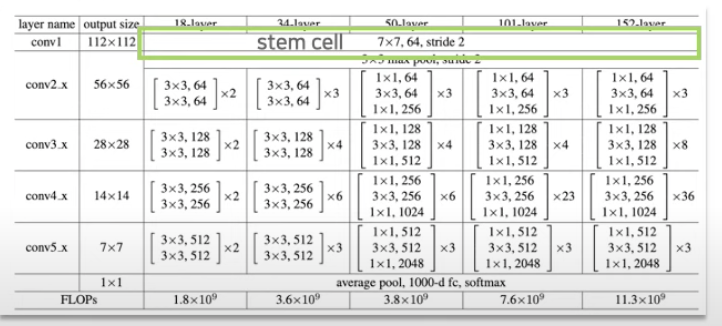
a. stage ratio (78.8% -> 79.4%)
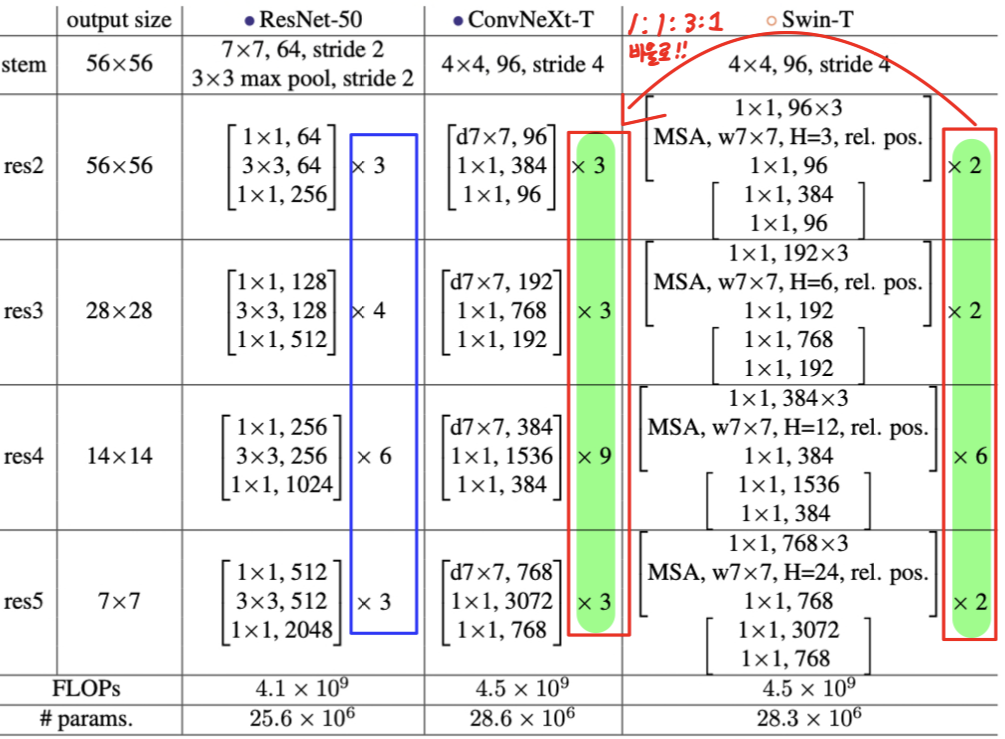
- Swin Transforemr 구성은 여러 stage로 구분되며, 각각의 stage에서 block의 수는 1:1:3:1의 비율로 맞게 설정됨.
- 기존 stage 구성(ResNet-50)은 위의 도표의 파란색 네모칸과 같이 3,4,6,3이었음.
- Swin Transformer-T 구성인 2,2,6,2와 같이 비율을 1:1:3:1로 수정함.
-> ResNet-50의 stage 구성: 3,3,9,3으로 구성
b. "patchify" stem (79.4% -> 79.5%)
stem이란?
- network를 처음 진입하는 부분을 의미
- ViT와 ConvNet 둘다 처음 이미지를 down sampling하여 학습함.
- stem 부분을 ViT의 patchify 방식을 활용
- ViT는 14x14 or 16x16 patch size로 이미지를 분할하고 이를 벡터화하여 선형 계층에 입력함. (14 or 16 크기의 Convolution 연산과 동일함)
- Swin Transformer의 'Patch Merging' 같이 kernel size를 4로 설정하여 더 작은 차원에서 작업을 진행함.
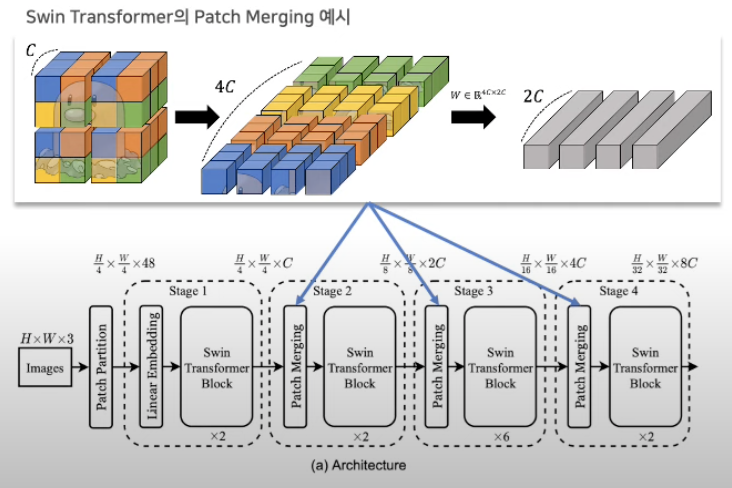
출처: 고려대학교 DSBA, 허재혁
위의 그림은 Swin Transformer의 Patch Merging의 예시임.
- Patch Merging은 계층적 구조를 구축하기 위한 핵심 요소 중 하나로 이미지의 해상도를 점진적으로 줄이는 방식임.
기본 아이디어는 다음 3가지임!
(1) 주어진 이미지를 초기에 작은 patch로 분할
(2) 인접한 patch들을 함께 병합되어 더 큰 patch로 형성
(3) 병합된 patch는 다음 계층에 input으로 사용
정리하면!!
- 이런 방식이 효과적이기 때문에 ResNet도 4x4 크기의 conovlution 적용함.
- 패치 분할과 유사한 효과를 위해 겹치지 않는 방식인 stride 4를 사용함.
기존(7x7 kernel size, stride 2) -> 현재(4x4 kernel size, stride 4 )
2.2.2. ResNeXt-ify (79.5% -> 80.5%)
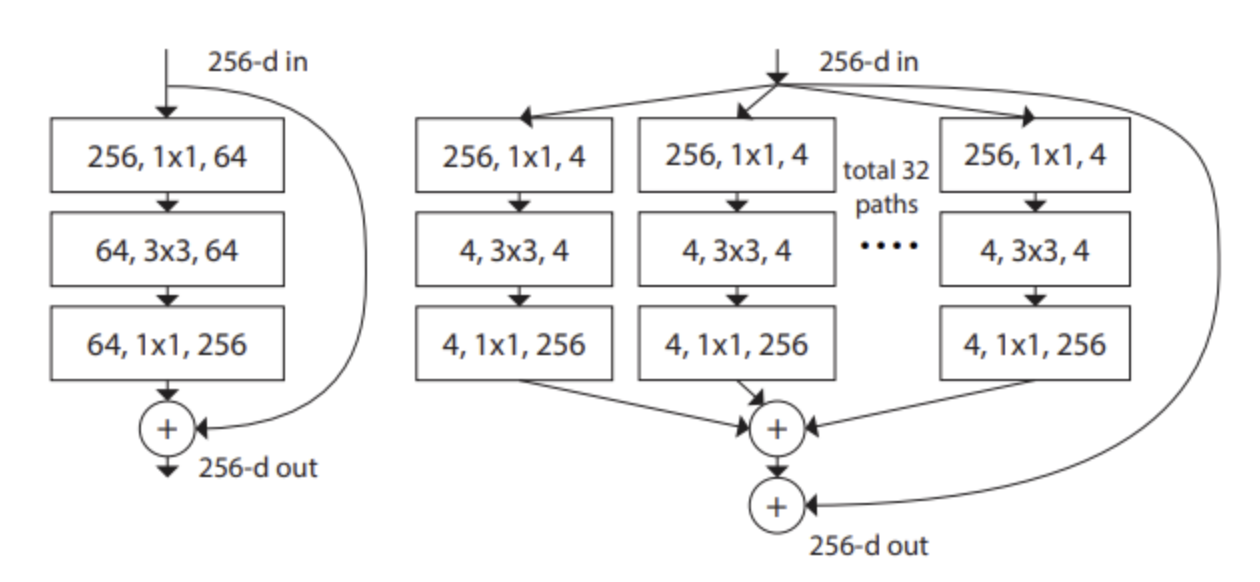
- 전통적인 접근법(ResNet)에서는 256차원 입력을 bottle neck을 통해 64차원으로 축소한 뒤, 3x3 conv를 통과시켜 원래 256차원으로 복귀함.
- 반면, ResNeXt는 입력 경로를 여러 경로로 분할 한 뒤, 각 경로에서 bottle neck 구조를 통해 4차원까지 줄이고 다시 256차원으로 확장하여 모든 경로를 통합함. (depthwise separable convolution 도입)
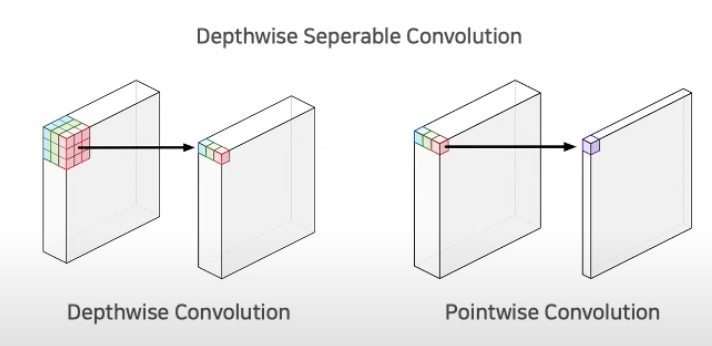
- ResNeXt에서 도입한 depthwise separable convolution 기법을 통해 연산 효율성을 향상시키고 유지함.
- 채널마다의 가중치 합산 방식을 고려하면, self-attention 기법과 비슷함.
2.2.3. Inverted Bottleneck

(a): ResNet
- 1x1 conv로 채널을 줄인 뒤 3x3 conv를 진행하고 1x1로 채널을 키우는 Bottleneck 구조임.
- '넓게', '좁게', '넓게'로 구성됨.
(b): MobileNet-v2
- FLOPs를 줄이기 위해 Inverted Bottleneck구조
- '좁게', '넓게', '좁게'로 구성하여 메모리 효율 증가
(c): ConvNeXt
- Swin Transformer 구조를 띄고, Large Kernel Size를 위해 위쪽으로 Layer를 이동함 (b -> c)
- Inverted Bottleneck을 적용하여 FLOPs 감소를 보였으며 정확도 또한 증가됨.
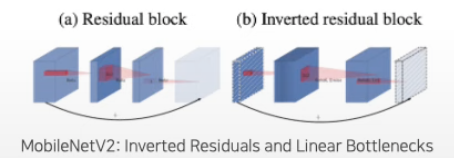
- 메모리가 효율적인 MobileNet v2 활용
-> Inverted Residual block을 사용
- 기존 ResNet의 구성은 '넓게', '좁게', '넓게'로 구성됨.
- 반면, MobileNet v2의 구성은 '좁게', '넓게', '좁게'로 구성하여 메모리 효율을 높이고자 함.
2.2.4. Large Kernel Sizes
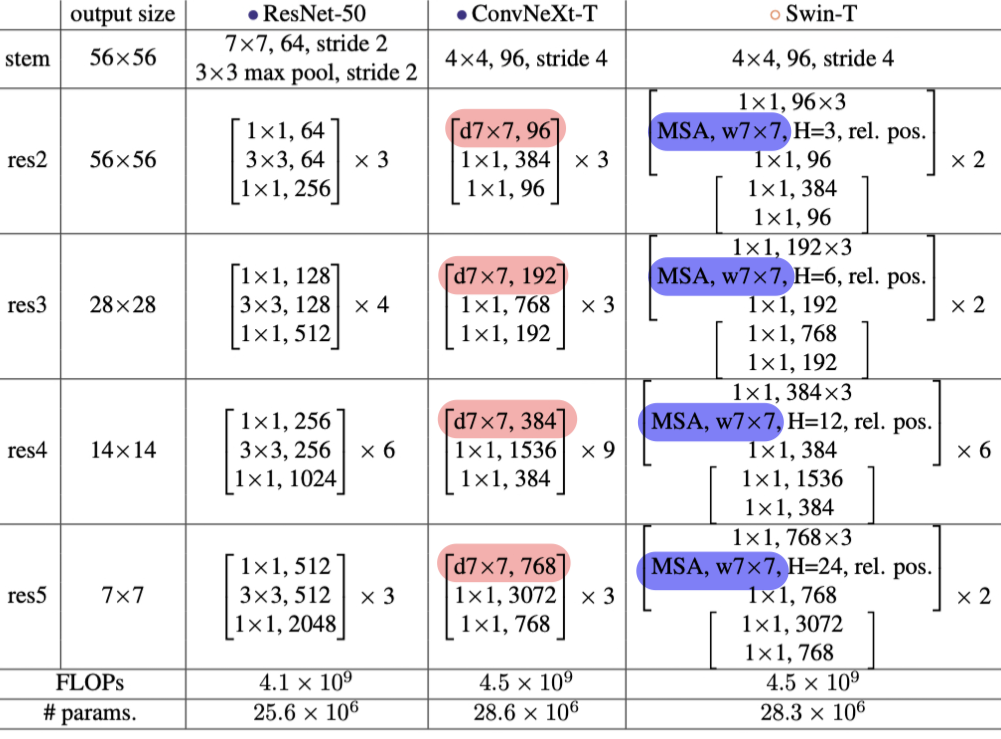
- 과거에는 large kernel을 선호했었지만, VGG에서 3x3 kernel size가 효율성이 좋기 때문에 계속 사용됨.
- 하지만 Swin Transformer에 맞게 ConvNeXt도 7x7 kernel size (49개의 patch)로 수정함.
- 다양한 kernel size 실험(3,5,7,9,11)을 통해 7x7 kernel size에서 결과가 안정화되었음.
- FLOPs 변화 없이 유지되었고, 정확도는 79.9% (3x3 kernel size) -> 80.6%로 상승함.
2.2.5. Micro Design
a. ReLU -> GELU

- 단순하고 효율적이기 때문에 ConvNet에서 ReLU를 사용하였음.
- 하지만 BERT, GPT-2, ViT 등 최근 연구에서 GELU를 사용하였기 때문에 이후에 GELU로 대체함.
b. Fewer activation functions / normalization Layers
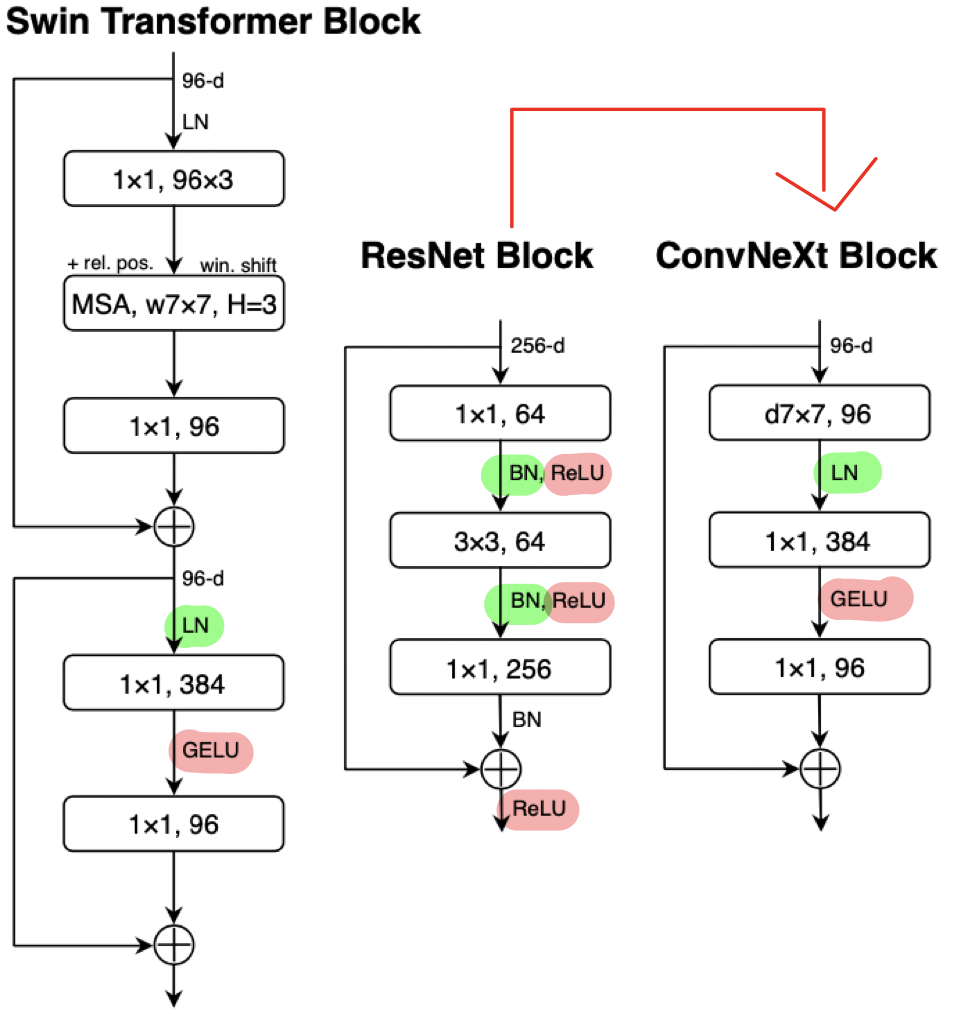
- ResNet
: ReLU와 BN을 매 Layer마다 적용시킴.
- ConvNeXt
- 2개의 1x1 conv 사이에 하나의 GELU만을 사용한 결과, 정확도를 81.3%까지 향상함.
- Inverted bottleneck의 첫번째 1x1 Conv layer 앞쪽에 LN을 적용시킨 결과, 정확도를 81.4%까지 향상함.
- Actionvation function과 Normalization 부분을 매 Layer마다 한번만 적용하는 것이 Keypoint!!
c. BN -> LN
- Batch Normalization -> Layer Normalization으로 변경함
- Batch Normalziation은 overfitting을 방지한다는 장점이 있지만 batch size에 따른 성능 변화의 편차가 있어서 성능에 좋지 않을수도 있다는 단점이 있었음.
- 반면, Transformer는 Layer Normaliztion을 적용하여 높은 성능을 도출함.
- 그래서 ConvNeXt에 LN을 적용하여 정확도를 81.5%까지 올림. (0.1% 향상)
d. Separate downsampling Layers
매번 Conv Layer 이후 down-sampling 이후 stage마다 down-sampling 진행함.
- ResNet
: 각 블록 종료 후, 다음 블록의 시작 레이어에서 3x3 conv & stride 2를 활용함
-> 너비와 높이를 줄임으로써 feature를 추출함
- Swin Transformer
: 별도의 down-sampling Layer인 'Patch Merging'을 가지고 있기 때문에 ConvNeXt도 이를 도입함.
-> 2x2 conv와 stride2를 활용함.
-> Normalization Layer를 추가해 학습을 안정화시켰음.
-> 정확도를 82.0%까지 끌어올림.
2.2.6. Result
- 위의 변화 포인트 내용을 정리하면
(1) Residual Block -> Transformer Block
(2) Kernel Size: 7x7
(3) Down-Sampling -> 매 stage마다 적용
(4) Optimizer: AdamW
(5) Convolution: depthwise convolution (단, width 크게)
(6) Activation & Normalization Layer: block마다 적용
3. Experiments

- dimention & block 구성에 따라 model 버전을 5가지로 구성함.
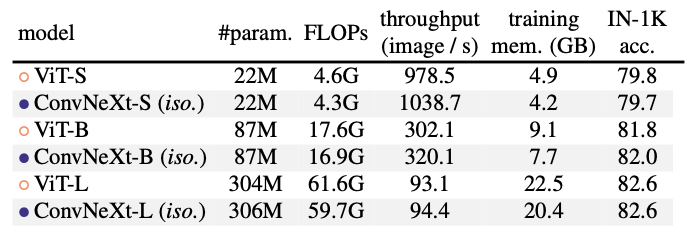
- 위의 연구는 ConvNeXt vs ViT임.
- ConvNeXt는 ViT와 비슷한 성능을 보여주며, 이는 ConvNeXt 블록 디자인이 비계층적 모델에서도 경쟁력 있음.
- down-samling 없이 비교했을 때 동일한 성능 but 적은 연산량(FLOPs)을 보임.
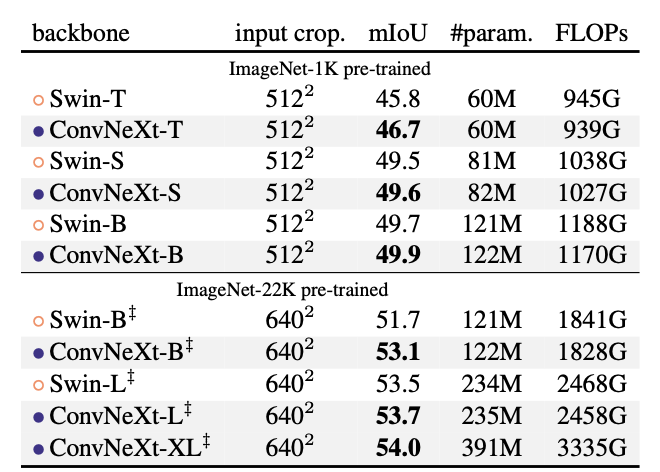
- UperNet을 사용한 ADE20k 검증 결과임.
- 위의 Swin과 ConvNeXt를 비교해봤을 때, 후자가 mIoU가 높고, FLOPs는 더 낮았음.
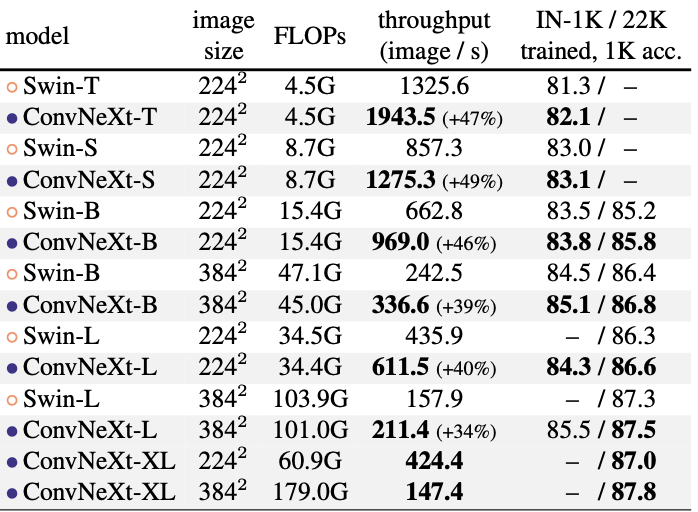
- 위의 연구는 Inference 부분임.
- ConvNeXt는 Swin Transformer에 비해 추론 속도가 상당히 빠른 속도를 보임.
4. Conclusions
- 2020년대에는 Vit와 Swin Transformers와 같이 Transformer 기반의 모델이 각광을 받음.
- 본 논문에서는 ConvNeXts라는 순수한 ConvNet 모델을 제안하며, 기존 Transformer 기반의 모델과 경쟁할 수 있는 성능을 보이는 ConvNets의 간결함과 효율성을 유지하도록 연구.
- 중요한 점은 새로운 technique들을 만든 것이 아닌, 지난 몇년동안 나온 것을 종합하여 이뤄낸 성과임.
🎯 Summary
- 저자가 뭘 해내고 싶어 했는가?
- ConvNets의 설계 공간을 다시 살펴보고, ViT와 유사한 설계를 통해 얼마나 높은 성능을 달성할 수 있는지 탐구하고자 하는 것이 목표
- 전통적인 ConvNets만을 사용하여도 Transformers와 경쟁력 있는 성능을 달성할 수 있는 모델인 ConvNeXt를 제안함.
- 이 연구의 접근 방식에서 중요한 요소는 무엇인가?
- Design Modernization
- Performance Enhancement
- ConvNeXt model
- 어느 프로젝트에 적용할 수 있는가?
- Image Classification
- Object Detection
- Semantic Segmentation
- Transfer Learning
- Customized Vision Solutions
- Benchmarking & Comparative Studies
- 참고하고 싶은 다른 레퍼런스에는 어떤 것이 있는가?
- 기존 ConvNet (AlexNet, VGG)
- ResNet
- ViT
- AdamW
- Swin Transformer
- 느낀점은?
- 상당한 충격을 받았다. Transformer는 센세이션한 모델이라고 생각했고, 이를 기반으로 SOTA를 도출했기 때문에.. ConvNet 기반의 모델이 더 성능이 좋다는 결과를 들었을 때 충격을 받았던 것같다.
- 그래서 꼭 Transformer구조가 어떤 상황에서든 정답은 아니라는 생각이 들었다. 상황에 따라서 CNN과 결합한 모델을 사용해보며 다양한 실험을 해보는 것이 중요하다.
- CNN의 역할에 대한 중요성...다시 알게 되었다. 기존의 방법론과 아이디어를 다시 연구하는 것이 매우 중요하다는 것을 알게 되었다. 역시 근본이 최고인가... 근본 is best...라는 생각을 하며 오늘의 리뷰는 끝!!
📚 References
- 논문
- Decoupled Weight Decay Regularization ICLR(Poster), 2019
- 유튜브
- https://www.youtube.com/watch?v=SG-nnGmtWno, 고려대학교 dsba (허재혁)
- 블로그

AI 전문가가 되기 위해 [a-zA-Z]까지 정리하는 거나입니다 😊