[논문리뷰 | CV] AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE (2021) Summary
[논문리뷰]
Title
- AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE (2021)
- ViT

0. 이 논문을 읽기 전에 알면 좋을 것들
Downstream task란?
- 최종적으로 해결하고자 하는 작업을 의미
- 어떠한 분야에 상관 없이 모두 '자신이 최종적으로 해결하고 싶은 문제'를 의미
Pre-Training이란?
- 사전 학습된 모델을 의미하며, Xavier 등 임의의 값으로 초기화하던 모델의 가중치들을 다른 문제(task)에 학습시킨 가중치들로 초기화하는 방법
-> 즉, weight와 bias를 잘 초기화 시키는 방법을 의미한다.
- 이때 사전 학습한 가중치를 활용해 학습하고자 하는 본 문제를 Downstream task라고 부른다.
Fine-Tuning이란?
- 사전 학습한 모든 가중치와 더불어 Downstream task를 위한 최소한의 가중치를 추가해서 모델을 추가로 학습(미세 조정)하는 방법
- 기존에 학습되어져 있는 모델을 기반으로 아키텍처를 새로운 목적에 맞게 변형하고 이미 학습된 모델 weights로부터 학습을 업데이트하는 방법
Transfer Learning(전이학습)이란?
- Pre-training & Fine-tuning을 하는 학습 과정을 의미
- 전이학습은 이미 잘 훈련된 모델이 있고, 해당 모델과 유사한 문제를 해결하는 데 효율적으로 사용됨
- 즉, 사전 학습 모델을 기반으로 새로운 목적(질의응답, 번역 등)을 위해 이미 학습된 weight or bias를 미세하게 조정하는 과정을 의미
- 대표적인 모델:
BERT
대량의 Corpus를 사용해서 Pre-training 시키고 언어의 기본적인 패턴을 이해한 word embedding을 추출한다. Pre-training을 통해 생성된 embedding으로 새로운 문제에 적용하는 전이학습을 수행해 적은 데이터로 기존 ML/DL 모델에 적용하여 빠르게 학습이 가능하다.
Inductive Bias란?
- training에서 보지 못한 데이터에 대해서도 적절한 귀납적 추론이 가능하도록 하기 위해 모델이 가지고 있는 가정들의 집합을 의미한다.
즉, 주어지지 않은 입력의 출력을 예측하는 능력을 의미한다.
- inductive bias가 적다는 것은 그만큼 contraint 없이 이미지 전체에서 정보를 얻을 수 있다는 장점이 있지만, optimal parameter를 찾기 위한 space 또한 커져버리기 때문에 데이터가 충분하게 많지 않으면 학습이 잘 안되는 문제가 발생한다.
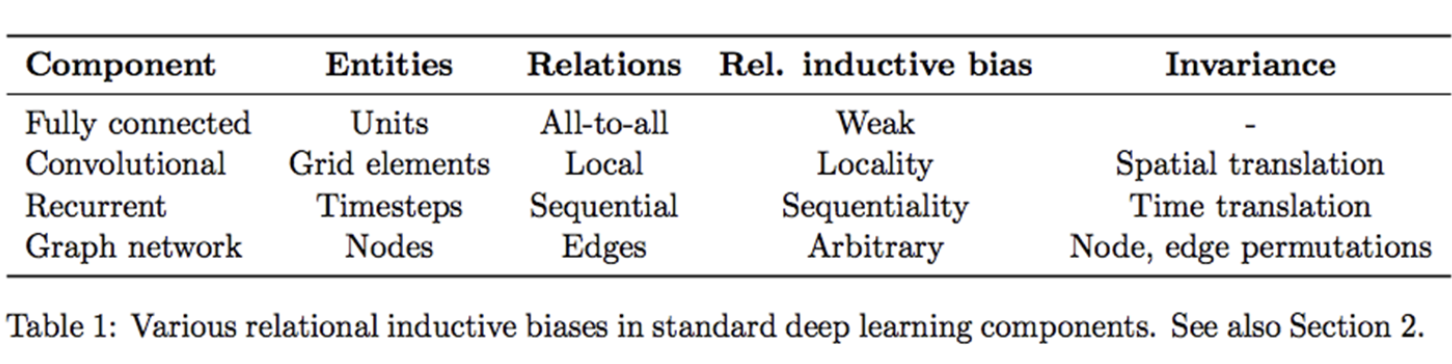
DNN 기본적인 요소들의 Inductive Bias는?
- Fully Connected: 입력 및 출력 요소는 상호 연결되어 있어, 특별한 relational inductive bias를 가정하지 않는다.
- Convolutional: CNN은 locality와 transitional invariance 특성을 갖고 있다. 작은 크기의 커널로 이미지를 지역적으로 볼 수 있으며, 동일한 커널로 전체 이미지를 볼 수 있다.
- Recurrent: RNN은 시계열 데이터가 있는 입력에 대해 가정을 하기 때문에 sequentiality와 temporal invariance 특성을 가지고 있다.
- Transformer는 Self-Attention 기반이고, CNN 및 RNN 구조에 전혀 의존되지 않기 때문에 보다 상대적으로 inductive bias가 낮다.
- Attention은 Query, Key, Value로 나누어서 Attention Score를 계산하고 이를 통해 Sequence가 다른 Sequence의 요소들과 어느 정도의 연관이 있는지를 나타낸다. 그래서 Fully Connected처럼 모든 입력 및 출력 요소가 상호 영향을 미칠 수 있으므로 Inductive Bias가 낮다고 말할 수 있다.
Abstract
-
NLP분야에서 Transformer 구조는 높은 성능을 보였지만, CV 분야에서의 적용은 제한적
-
본 연구에서는 NLP에서 사용되는 standard Transformer를 이미지에 그대로 적용하여 이미지 분류에 좋은 성능을 도출한 Vision Transformer를 제안함
- ViT는 CNN에 대한 의존을 끊고 image를 patch로 분할한 후, 이를 NLP의 단어로 취급하여 각 patch의 linear embedding을 순서대로 Transformer의 input으로 넣어 이미지를 분류를 수행함
image patch를 단어의 배열처럼 sequence로 생각하면 된다.
- 충분한 양의 데이터로 사전학습 한 경우, CNN 기반의 기존 SoTA 모델들을 뛰어넘는 결과를 보여줌
1. Introduction
- Transformers의 핵심은 Self-Attention을 사용하여 대량의 Corpus로부터 Pre-Training한 후 작은 task의 데이터셋에 대해서 Fine-Tuning하는 방식이다.
-> 기존 Sequence model (RNN, LSTM)은 순차적으로 token들을 넣어줘야하기 때문에 GPU처리가 매우 비효율적
- 연산이 매우 효율적이고, 확장성이 좋다. 특히 input sequence의 길이에 구애받지 않는다.
- Vit 논문이 발표되기 전까지는 여전히 CNN 기반 모델들이 지배적이었음.
-> Resnet 기반의 아키텍처들이 이미지 분야에서의 SOTA 모델이었던 상황
- 하지만, 구글팀은 NLP 분야에서 Transformer의 scaling successes에 영감을 받았고, 거의 수정을 거치지 않은 Standard Transformer를 이미지에 적용하였다.
핵심 아이디어는 다음과 같다.
- Image를 일정한 크기의 patch로 분할한 후, 이를 NLP의 단어의 배열처럼 Sequence로 취급하자!
즉, Image patch는 NLP의 Token(Words)처럼 처리하면 된다. (하나의 image patch = 하나의 Token)
- 각 patch들을 linear하게 embedding하여 sequence를 생성한다.
- 이 sequence를 Transformer의 Input으로 넣어 이미지를 분류한다.
- ViT를 ImageNet-1k에 학습했을 때, 비슷한 크기의 ResNet보다 낮은 정확도를 도출하는 것을 통해 ViT가 CNN
- ImageNet-21k와 JFT-300M에 pre-training한 ViT를 다른 image recognition task에 Transfer learning 했을 때, ViT가 SOTA 성능을 도출하였다.
- 이를 통해 Large scale 학습이 낮은 Inductive Bias로 인한 성능 저하를 해소시키는 것을 알 수 있다.
2. Related Work
Transformer 구조를 기반으로 대량의 Corpora로 학습하고 원하는 Task에 대해서 fine-tuning하는 대표적인 모델은
- BERT: a denoising self-supervised pre-training task
- GPT: language modeling as its pre-training task
-> 이때 사전학습 방법을Self-Supervised Learning이라고 한다.
- Self-Attention을 image에 다이렉트하게 적용한다고 하면, 이미지의 각 픽셀과 모든 픽셀의 Attention을 계산할 수 있다.
- 하지만 이런 방식은 pixel의 수에 따라 많은 비용이 소요될 수 있기 때문에 실질적인 input size에는 적용할 수 없는 한계가 있다.
- Transformer를 적용하기 위한 많은 노력들이 이 파트에 자세하게 설명되어 있다.
- Jean-Baptiste Cordonnier, Andreas Loukas, and Martin Jaggi. On the relationship between self attention and convolutional layers. In ICLR, 2020
- 핵심 아이디어: Fully image에 Attention을 적용하기 힘든 문제를 2 x 2 image patches를 추출해 Attention을 적용함으로써 연산량을 낮춤.
2. ImageGPT(IGPT)
: 가장 유사한 최근 모델이며, 이미지의 해상도와 색상 차원을 낮춘 뒤 Transformer를 pixel에 적용한 모델이다.
3. Method
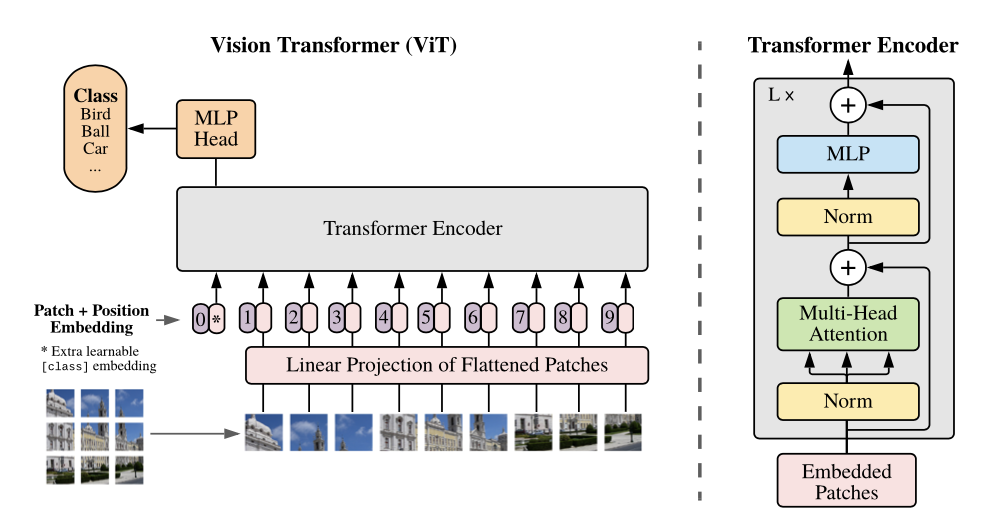
- 모델 설계에서 Standard Transformer를 그대로 이미지에 사용하고자 하였고, ViT 모델 구조는 아래 그림과 같다.
- 기존 Transformer 구조와 비슷하게 하려고 한 이유는
1) 확장성 (scalability)
2) efficient implementations
- 기존 Transformer 구조와 비슷하게 하려고 한 이유는
3.1 Vision Transformer (ViT) 모델 구조
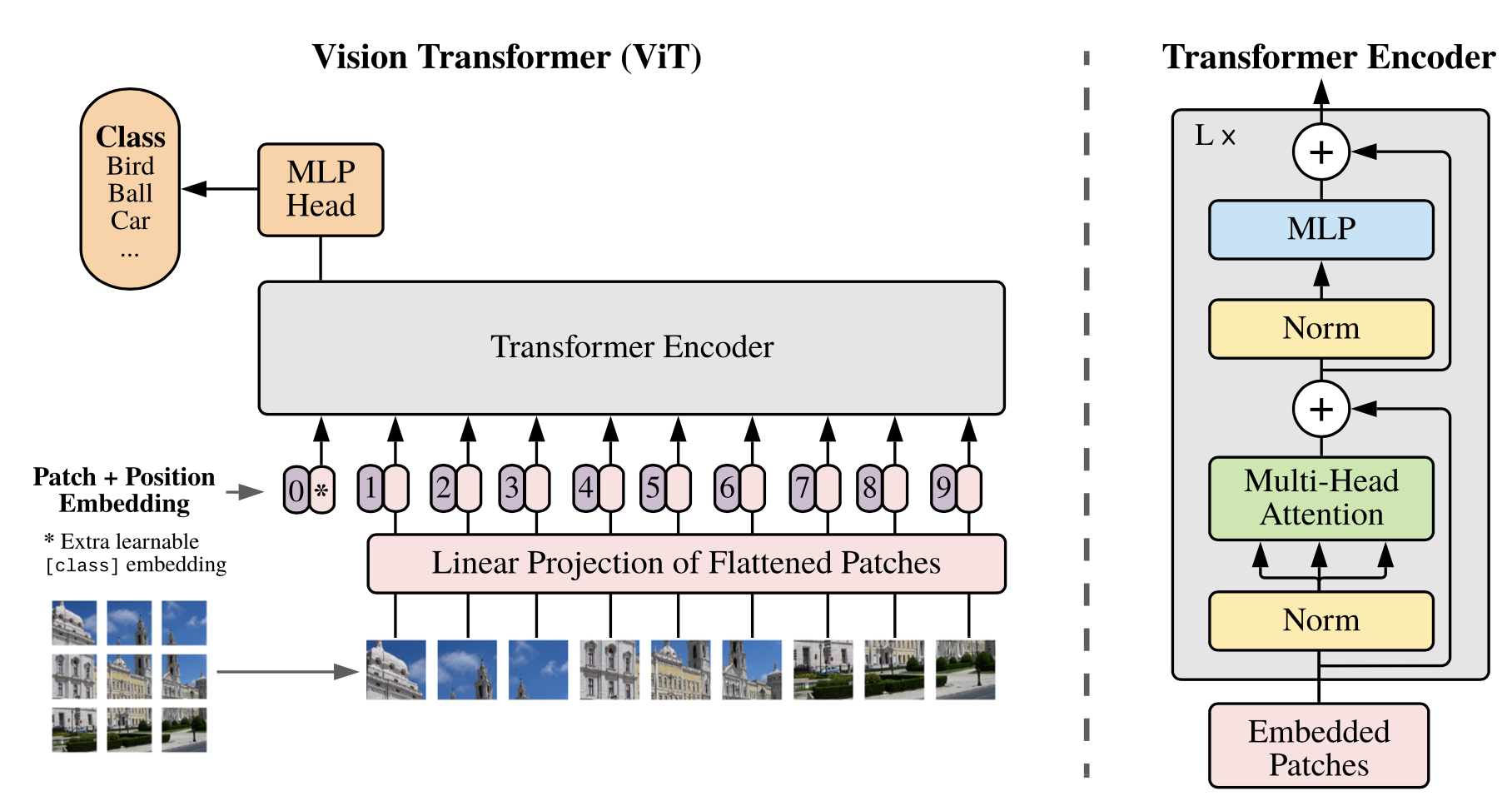
ViT의 작동과정은 다음과 같다. 참고자료
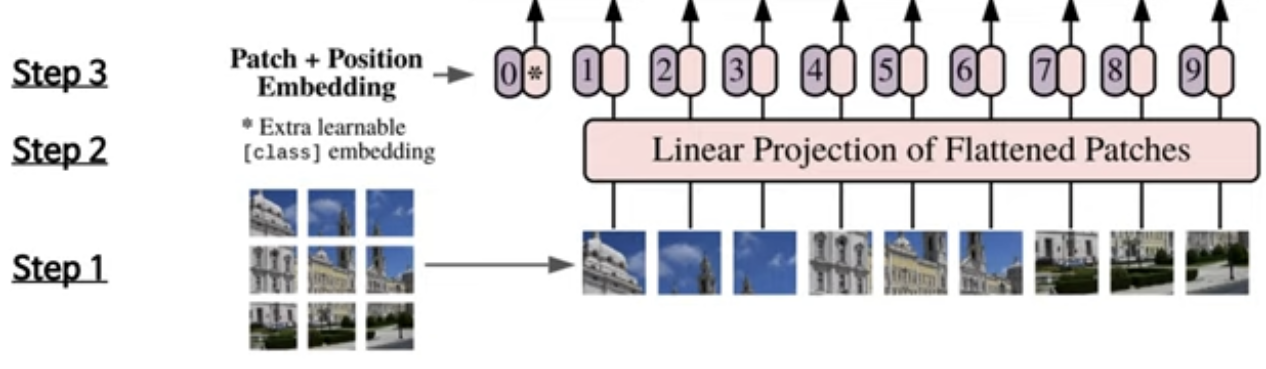
- 이미지 x ∈ 가 있을 때, 이미지를 (PxP) 크기의 N(= / )개로 분할하여 flatten한 패치 sequence ∈ 로 reshape 해준다.
- (): 원본 이미지의 해상도
- : 채널 개수
- (): 각 image patch의 해상도
- : reshape 결과, 나오게 되는 image patch의 개수
- ViT는 2d image를 다뤄야 하기 때문에 input에 해당하는 위치에서 위의 작업을 추가적으로 수행해줘야 한다.
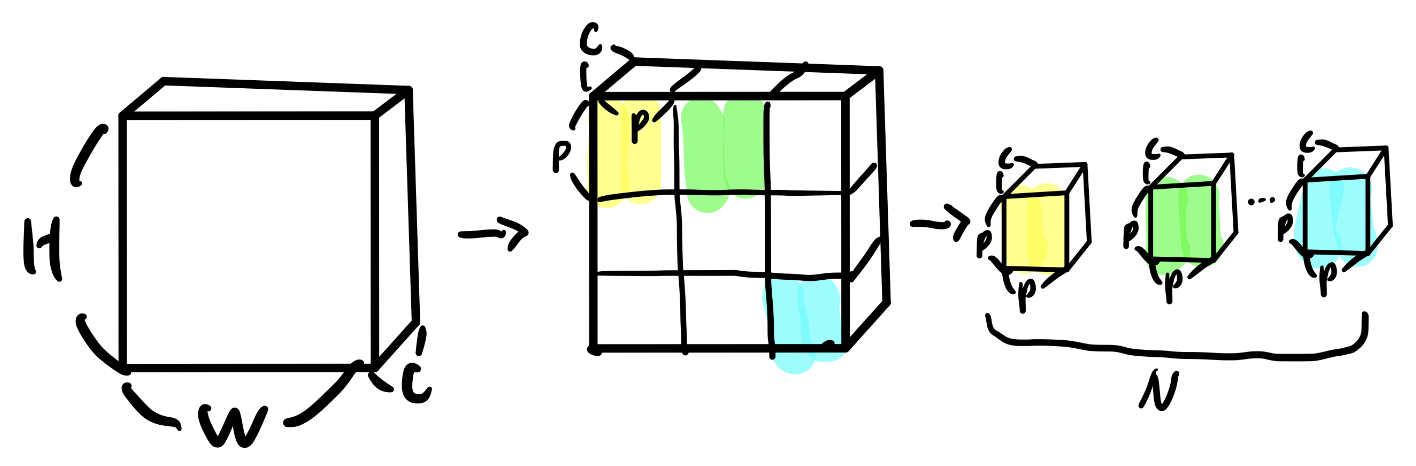
- Step 1을 그림으로 표현하면 위와 같다.
출처: https://baekyeongmin.github.io/paper-review/vision-transformer-review/
- Trainable linear projection을 통해 의 각 패치를 flatten한 벡터를 D차원으로 변환한 후, 이를 패치 Embedding으로 사용한다.
- Trainalbe linear projection의 역할은 각각의 패치인 를 flatten한 벡터 D차원으로 변환시켜준다.
- 2번째 단계를 거치면, 하나의 patch가 분홍색에 해당하는 vector로 나오게 된다.
이때 나온 output을 patch 임베딩이라고 한다.
- Learnable class 임베딩과 patch 임베딩에 learnable position 임베딩을 더한다.
-
Learnable class 임베딩은 Step3에서의 분홍색 맨 앞쪽의 * 해당하는 vector이다.
-
여기서 Learnable class는 BERT 모델과 같이 class token을 만들고, 이를 다른 token들에 concat해준다. (10xD)
-> BERT의 Class token과 유사하게, pre-traing, fine-tuning에서 이미지의 representation으로 이용될 학습 가능한 임베딩 을 시퀀스의 첫번째 위치에 추가한다.
- Transformer Encoder의 최종 output에서 class token에 해당하는 classification header의 input으로 사용한다.
- Step2에서 나왔던 총 9개의 patch 임베딩과 class token까지 concat 후 vectors(10xD)에 추가로 position information을 주기 위해 positional Embedding을 더해준다.
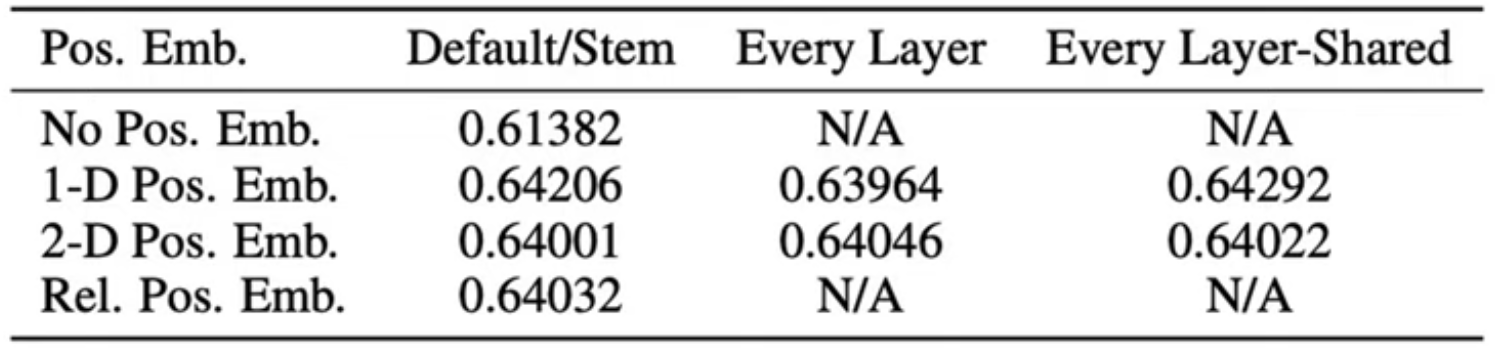
** ViT에서는 위의 4가지 position Embedding을 시도한 후, 최종적으로 가장 성능이 좋은 1D position Embedding을 사용하였다.
** 원래 이미지에 맞게 positional embedding도 2D-aware position embedding을 사용했으나 성능 향상이 없었다.
- 임베딩을 vanilla Transformer encoder에 input으로 넣어 마지막 Layer에서 class embedding에 대한 output인 image representation을 도출한다.
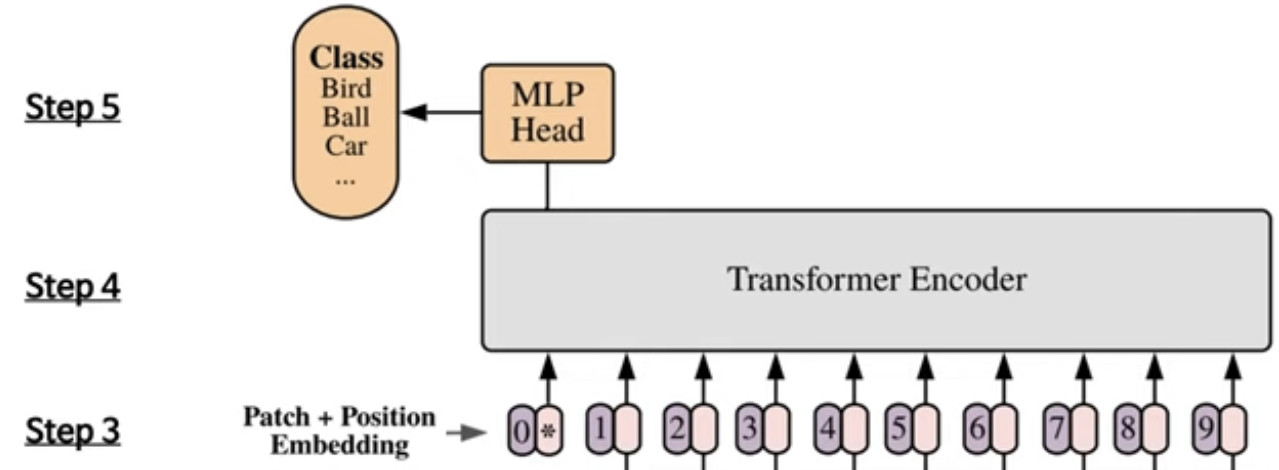
- MLP에 image representation을 input으로 넣어 이미지의 class를 분류한다.
3.2. Transformer Encoder
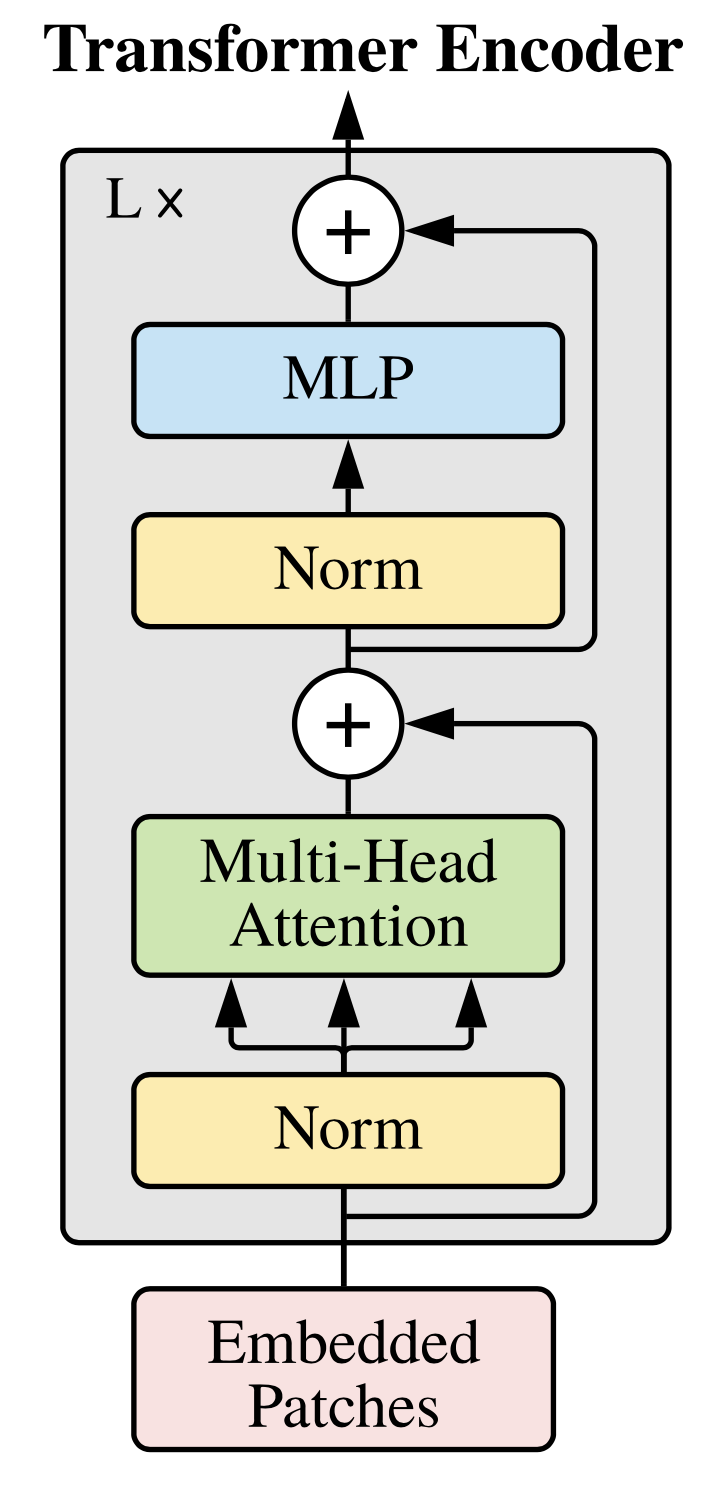
- Multi-head Self Attention (MSA)와 MLP Block으로 구성된다.
- MLP는 2개의 Layer를 가지고 있고, GELU activation function을 사용한다.
- 기존 Transformer와는 달리, 각 block의 앞에는 Layer Normalization을 적용하고, 각 block의 뒤에는 residual connection을 적용한다.
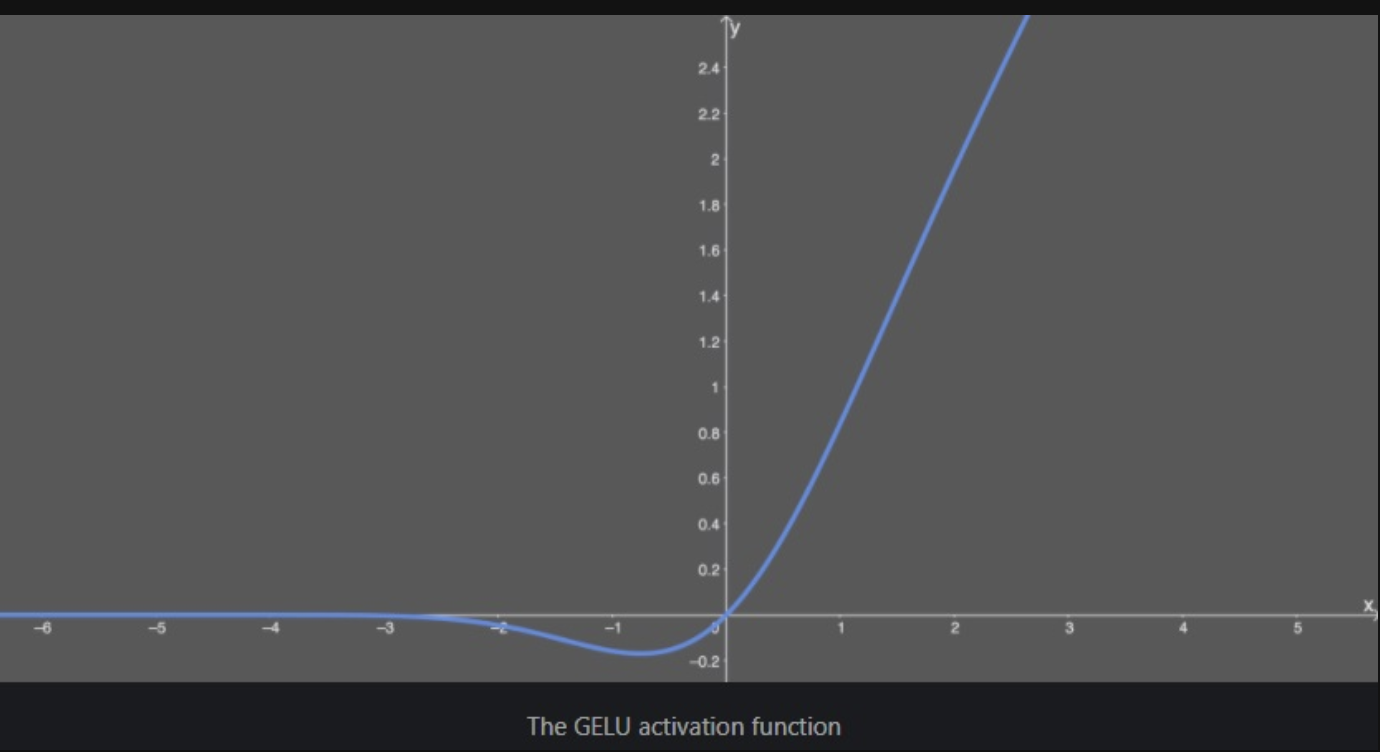
GELU activation function 참고자료
- GELU 함수는 dropout, zoneout, ReLU 함수의 특성을 조합한 함수로, NLP, Vision 등 다양한 Task에 대해 ReLU, ELU보다 일관적으로 성능이 좋다.
- Gaussian Error Linear Unit의 줄임말로, 원본입력에 원본입력을 Gaussian Distribution의 CDF를 통과한 값과 곱해주는 함수이다.
- 이를 통해 x가 다른 입력과 비교했을 때 얼마나 큰지로 gating이 되는 효과를 얻는다.
- bounded below가 되어 있어 gradient vanishing에서 자유롭다.
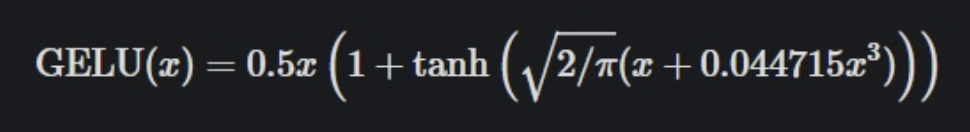
3.3. Inductive Bias
- MLP에서는 locality와 translation equivariance가 있지만, MSA는 global한 특징을 가지고 있기 때문에 CNN 아키텍처에 비해서 더 작은 image-specific inductive bias를 가진다.
- locality
: 가까이 있는 neighborhood pixel들에 영향을 많이 받고 거리가 멀어질수록 그 영향도가 떨어지는 것
- translation equivariance
: xy축으로 이동하거나 회전을 주더라도 같은 object로 인식하는 것
- locality
-
ViT에서는 모델에 2가지 방법을 사용하여 Inductive Bias의 주입을 시도하였다.
- Patch Extraction
: Step 1에서 봤었던 image를 여러 개의 patch로 분할하여 Sequence 형태로 넣는 것.
- Resolution adjustment
: 이미지의 Resolution에 따라서 patch의 크기는 동일하지만 patch의 개수는 달라지게 된다. 이 달라지는 개수에 대해 fine-tuning을 할 때, 미세 조정하는 것
- Patch Extraction
-
inductive bias가 적다는 것은 contraint 없이 이미지 전체에서 정보를 얻을 수 있지만, 적합한 파라미터를 찾기 위한 space가 커져버리기 때문에 데이터가 충분치 않으면 학습이 안된다.
3.4. Hybrid Architecture
- ViT는 raw image가 아닌 CNN으로 추출한 raw image의 feature map을 활용할 수 있다.
- feature map은 이미 raw image의 공간적 정보를 포함하고 있기 때문에 patch를 자를 때 1x1로 설정해도 된다.
- 1x1 크기의 patch를 사용할 경우, feature map이 공간차원을 flatten하여 각 벡터에 linear projection을 적용하면 된다.
- CNN의 feature map을 Transformer Encoder의 입력 sequence로 넣는 방법이다.
- 즉, CNN 위에 Transformer encoder를 쌓은 구조를 이용한다.
3.5. Fine-Tuning and Higher Resolution
- ViT를 Large Scale로 pre-training 후, 모델을 Downstream Task에 fine-tuning을 진행한다.
- Downstream Task에 적용하기 위해서 pre-training할 때 prediction head를 zero-initialized feed forward layer로 대체한다.
- 고해상도 이미지를 사용할 때 pre-training 단계에서 사용했던 patch size와 동일한 size를 사용하기 때문에 sequence 길이가 더 길어진다.
- ViT는 가변적 길이의 patch들을 처리할 수 있지만, pre-train 단계에서 학습시켰던 positional embedding은 효과가 없어지기 때문에 원본 이미지의 위치에 따라 2D interpolation을 사용한다.
이 과정이 Resolution adjustment을 의미한다. 이 과정에서 해상도(resolution)을 조정하고 patch를 추출하며 inductive bias가 수동으로 주입된다.
4. Experiments
이 파트에서는 여러 데이터셋과 모델을 비교하면서 실험을 진행하였다. 결과만 간략하게만 보고 넘어가겠다.
(이 부분은 추후 코드 실습 진행할 때 더 자세하게 볼 예정이다. )
a. Comparision to state-of-art
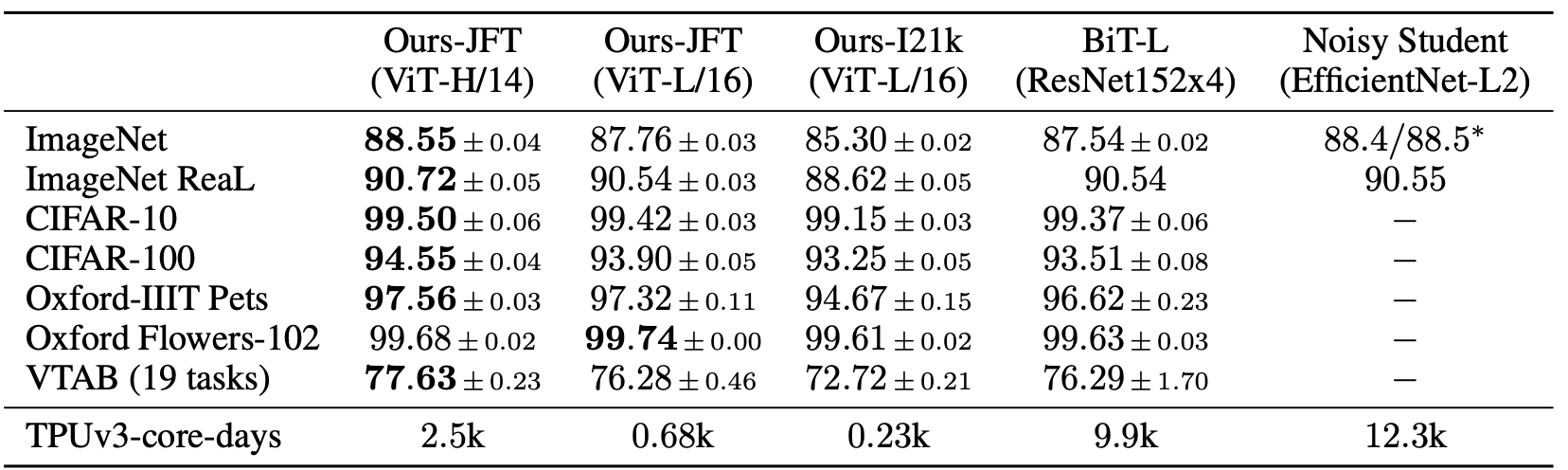
- 본 실험에서는 14x14 patch size를 사용한 ViT-Huge와 16x16 patch size를 사용한 ViT-Large의 성능을 baseline과 비교한 표이다.
- ViT-L/16 모델이 모든 downstream task에 대하여 BiT-L보다 높은 성능을 도출하였다.
- ViT-L/14모델은 ViT-L/16 모델보다 향상된 성능을 도출하였고, BiT-L모델보다 학습시간이 훨씬 짧다.
b. Pretraining data requirements
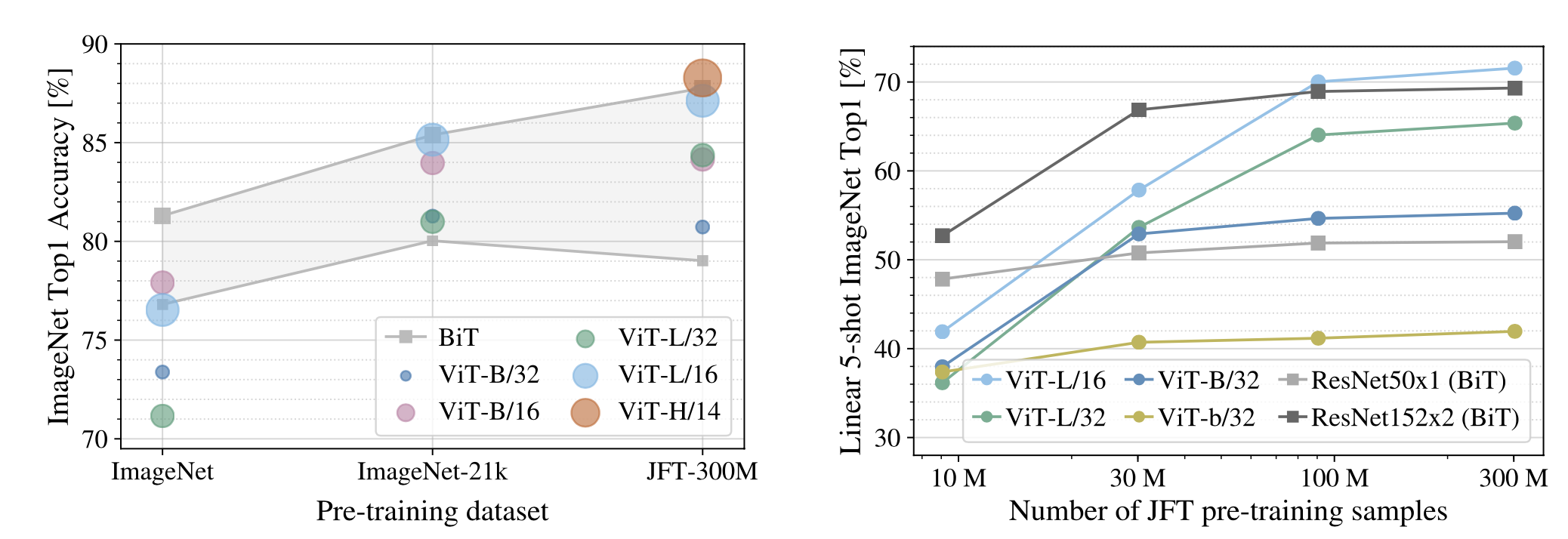
- 이 실험에서는 pre-training dataset의 크기에 따른 fine-tuning 성능을 확인한다.
- 데이터가 클수록 ViT가 BiT보다 성능이 좋고, 크기가 큰 ViT 모델이 효과가 있다.
- CNN은 작은 데이터셋에서는 indutive bias 덕분에 좋은 결과를 도출하고 있지만, 큰 데이터셋에서는 ViT가 더 좋은 성능을 도출하였다.
c. Scaling study
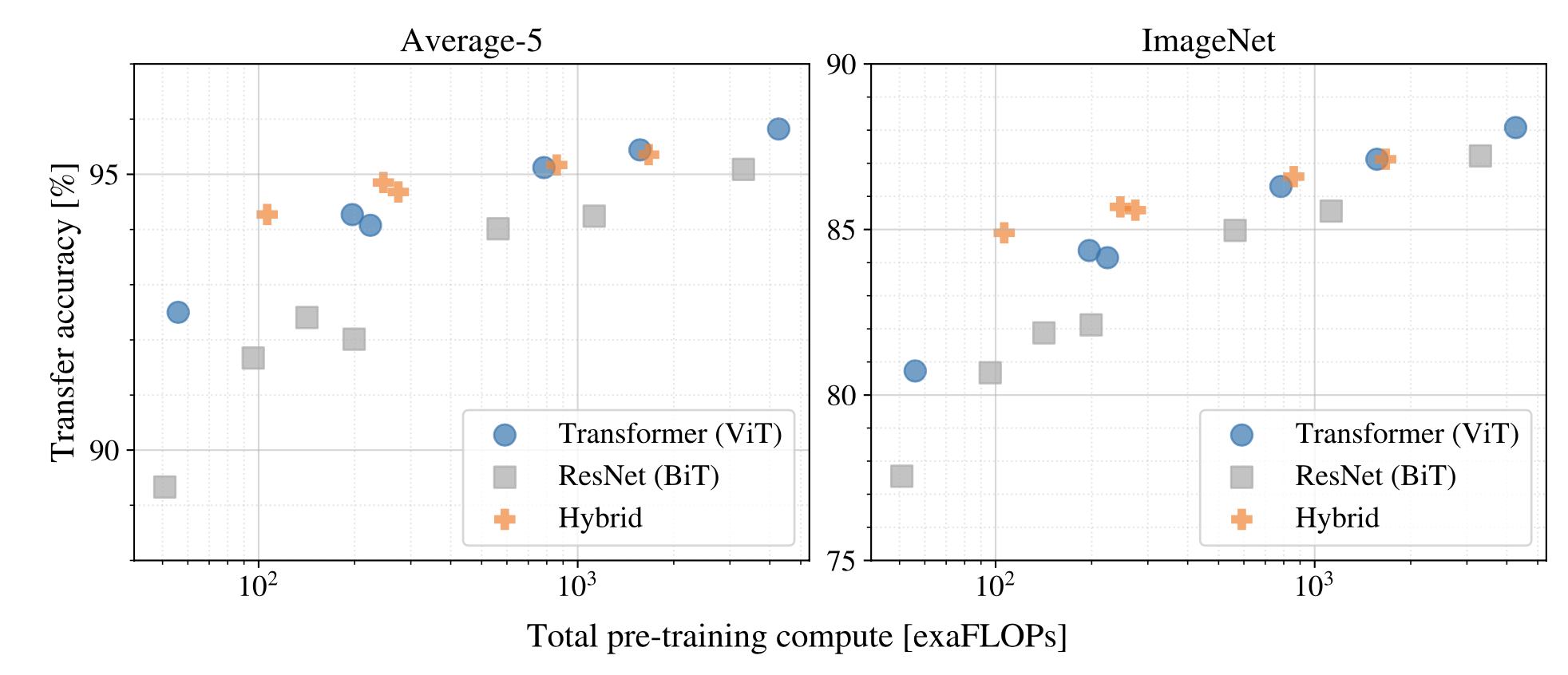
Pre-training cost란?
: TPUv3 accelerator에서 모델의 inference 속도 관련 지표
- 모델들의 scale를 맞춘 후 성능을 비교하는 실험이다. 이때 FLOP을 scale의 지표로 사용한다.
- ViT가 ResNet(BiT)와 비교했을 때, 성능과 cost의 trade-off가 우세하다.
- Cost가 증가할수록 Hybrid와 ViT의 성능과 trade-off 차이가 감소한다.
5. Conclusion
- image를 patch로 분할하여 sequence를 Transformer Encoder에 투입하여 Self-Attention을 사용한다.
- 대량의 datasets으로 pre-training시킬 때 기존의 SoTA 모델들을 능가하는 성능과 상대적으로 저렴한 비용이 발생된다.
- Detection and Segmentation와 같은 다른 CV분야에 ViT를 적용하는 것이 숙제이다. 또한, self- supervised pre-training methods를 계속 탐색하는 것이 숙제이다.
🎯 Summary
-
저자가 뭘 해내고 싶어 했는가?
NLP분야에서 좋은 성능을 보인 Transformer구조를 CV 분야에서도 적용하고자 하였고, 이미지 분류에 좋은 성능을 도출한 Vision Transformer를 제안하였다.
-
이 연구의 접근 방식에서 중요한 요소는 무엇인가?
image를 일정한 크기의 path로 분할한 후, 이를 단어의 배열처럼 sequence로 취급하자!
즉, image patch는 NLP의 Token처럼 처리하자! -
어느 프로젝트에 적용할 수 있는가?
이미지 분류 프로젝트!
-
참고하고 싶은 다른 레퍼런스에는 어떤 것이 있는가?
-Transformer
-BERT
-GPT
-ImageGPT(IGPT)
-On the relationship between self attention and convolutional layers -
느낀점은?
- NLP에서만 보던 Transformer를 CV분야에서 보니까 색다르고 신기했다. 그리고 Transformer 내용을 여러번 복습할 수 있어서 좋았고, 특히 복습을 하면서 Posional Embedding의 필요성을 구체적으로 알 수 있었다. 그리고 헷갈리던 개념들을 정리하고 나니까 시야가 넓어질 수 있었던거같다.
- CV 분야에 Transformer를 적용하기 위한 많은 노력들이 있었는데, Related Work에서 소개된 논문을 추후 시간되면 읽어봐야겠다.
- NLP에서만 보던 Transformer를 CV분야에서 보니까 색다르고 신기했다. 그리고 Transformer 내용을 여러번 복습할 수 있어서 좋았고, 특히 복습을 하면서 Posional Embedding의 필요성을 구체적으로 알 수 있었다. 그리고 헷갈리던 개념들을 정리하고 나니까 시야가 넓어질 수 있었던거같다.
📚 References
유튜브
블로그
그림 및 개념 참고
- GELU 그림 참고: https://velog.io/@tajan_boy/Computer-Vision-GELU
- Pre training & Fine tuning 개념 참고: https://velog.io/@soyoun9798/Pre-training-fine-tuning
- DownStream Task, Transfer Learning 개념 참고: https://chan-lab.tistory.com/31
- '텐서플로 2와 머신러닝으로 시작하는 자연어 처리 (개정판)' 7장 참고
- BERT 개념 참고: https://ebbnflow.tistory.com/162?category=895676
- GELU 개념 참고: https://sanghyu.tistory.com/182
