[논문리뷰 | CV] MobileNet: Efficient Convolutional Neural Networks for Mobile Vision Applications (2017) Summary
[논문리뷰]
목록 보기
15/42
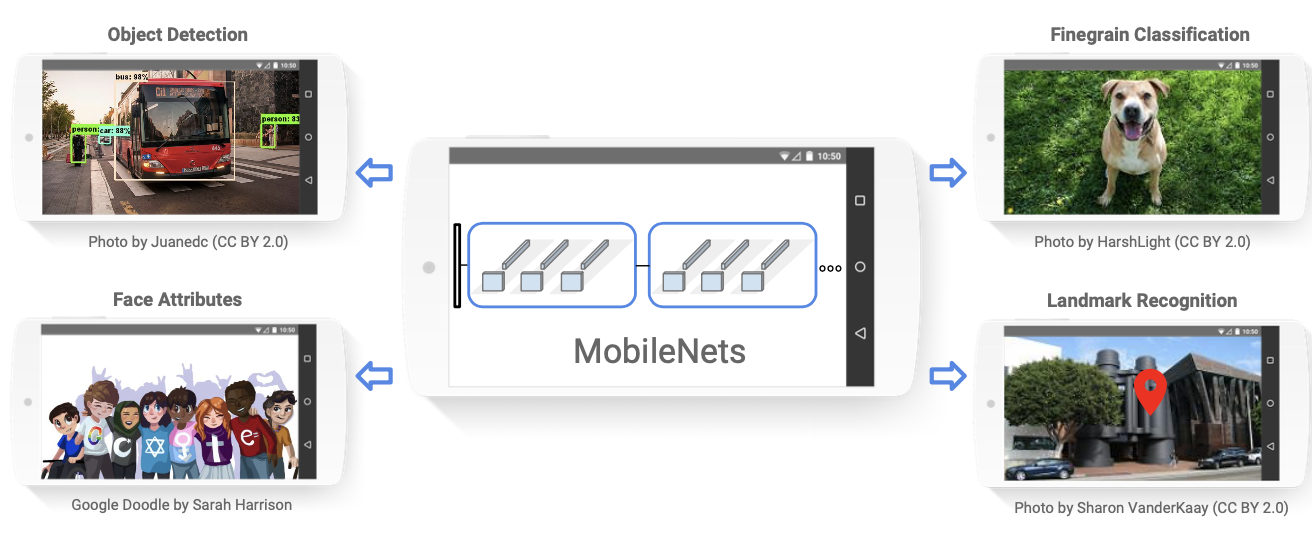
Title
- MobileNet: Efficient Convolutional Neural Networks for Mobile Vision Applications
- MobileNet

Abstract
- Google의 MobileNet은 성능 저하를 최소화하고 딥러닝 모델 파일의 크기를 줄이는 것을 목적으로 발표함
- 핸드폰 or 임베디드 시스템과 같이 저용량 메모리 환경에 딥러닝 모델을 적용하기 위해서는 경량화가 필수였음.
🏆 MobileNet의 핵심 🏆
- Depthwise separable convolution [핵심]
- Width multiplier
- Resolution multiplier
1. Introduction
- 기존의 합성곱 신경망은 Layer의 깊이를 깊고 복잡한 네트워크를 만들었음.
ex) VGG, GoogleNet, ResNet 등
- 본 논문의 이름과 같이 모바일과 임베디드 시스템을 위해 효율적인 네트워크 구조를 사용하여 속도가 빠르고 경량화된 모델을 소개함.
- 최대한 성능을 보장하면서 컴퓨팅 속도를 빠르게 하는 모델로 정확성보다는 효율성 관점에서 만들어짐.
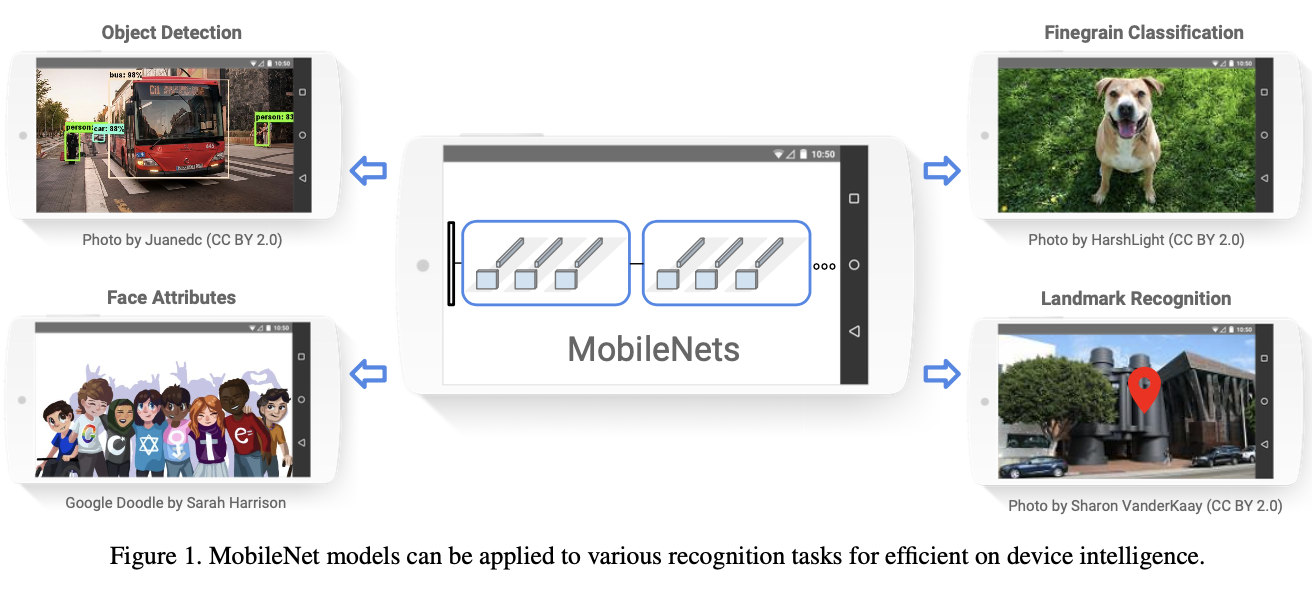
2. MobileNet Architecture
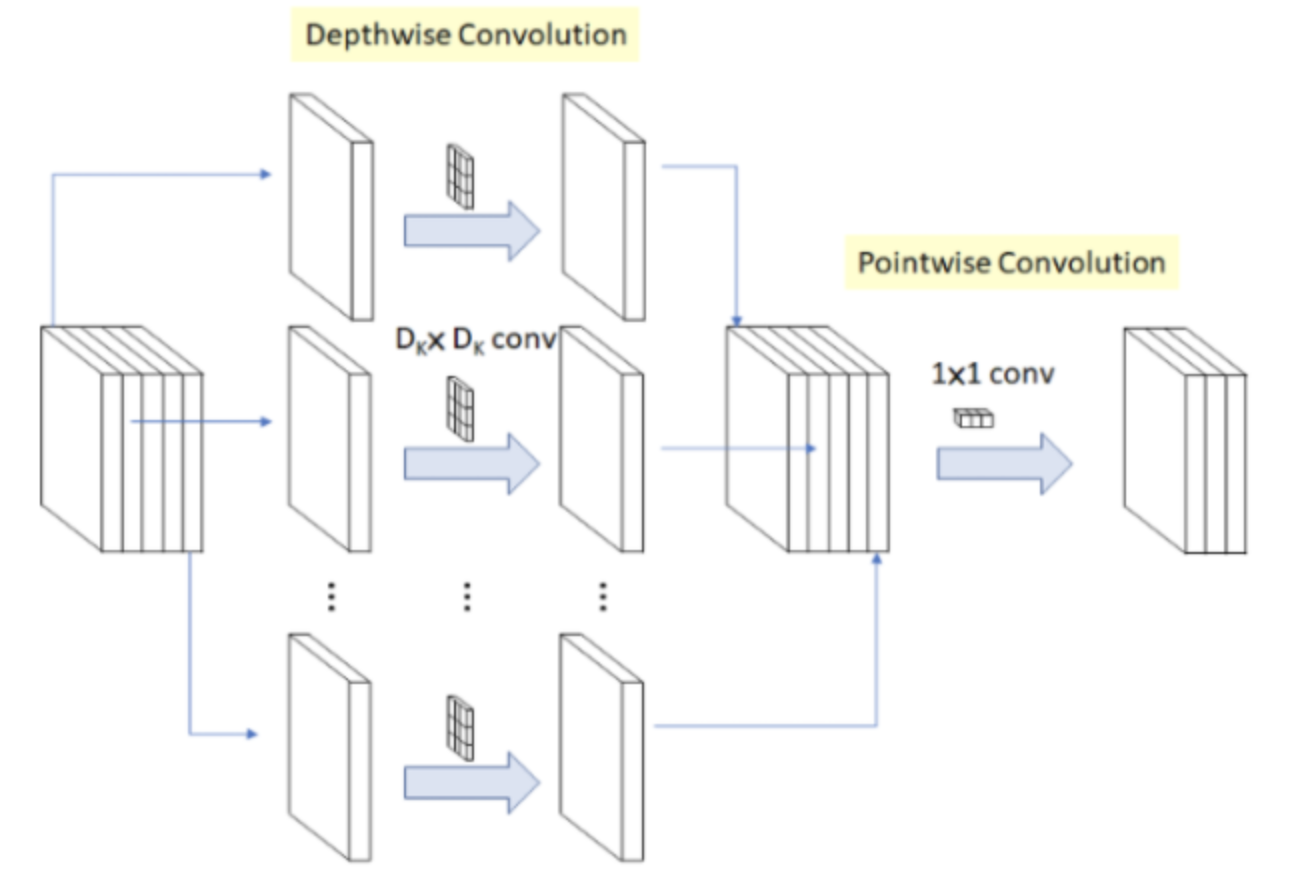
- Depthwise Separable Convolution + Pointwise Convolution
2.1. Depthwise Separable Convolution
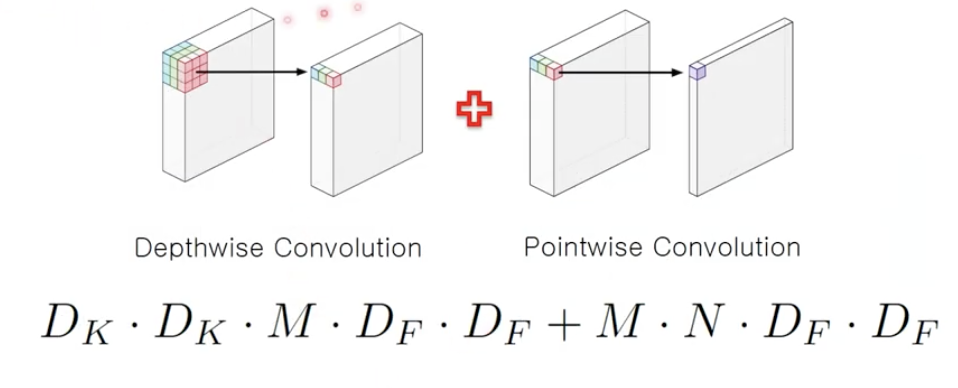
- Depthwise convolution과 Pointwise convolution을 결합하여 연산량을 줄이는 것이 목표
- 총 계산량:
xxxx$ $ + xxx
-> 기존의 Convolution에서는 채널 방향과 공간적 방향을 모두 함께 고려함.
-> Depthwise Separable Convolution 방식은 채널 방향과 공간적 방향을 아예 따로 분리함.
- 분리한다고 해도 채널과 공간적 방향을 모두 고려하기 때문에 기존 Convolutional 연산과 동일하게 작동함.
- 하지만 파라미터 수와 연산량을 훨씬 적음.
(a) Standard Convolution 연산
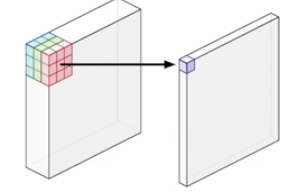
- 기존의 Convolution(이하 Conv) 구조는 각 채널에 대하여 한번 Conv를 거침.
- 위의 그림과 같이 필터의 크기가 x , 높이와 너비가 , 입력 채널수는 , 출력 채널 수(=Filter 수)는
- 총 계산량은 xxx
(b) Depthwise Convolution 연산
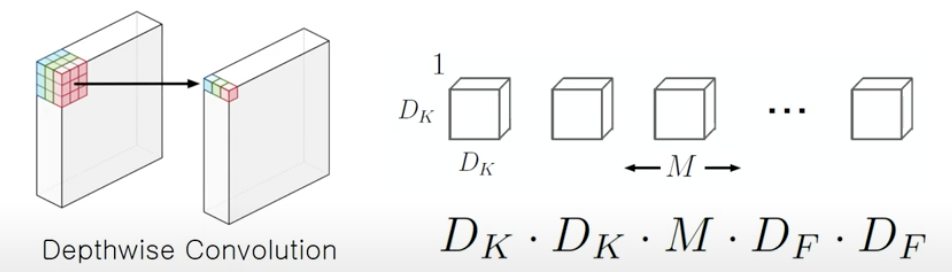
- 채널마다 따로 필터를 학습을 시키는 방법
- 각각의 채널에 대해서 각각의 필터를 연산해주기 때문에 Depthwise convolution에서는 차원 감소가 일어나지 않음
- 보통 3x3 Conv를 활용하여 하나의 Feature Map를 생성
- 채널마다 다른 필터가 적용되기 때문에
출력 채널 수=입력 채널 수
-
채널 axis로 연산이 이루어지지 않았기 때문에 연산량이 적어짐.
-
총 계산량: xxxx
-: 필터 크기
-: 채널 수
-: 이미지 사이즈 수
(c) Pointwise Convolution 연산

- 필터의 크기가 1x1 convolution으로 고정된 Layer
- 필터가 1x1이기 때문에 Input에 대한 공간적인 Feature를 추출하지 않은 상태로 각 채널에 대한 연산만 수행함.
- Output의 크기는 변하지 않고, 채널의 수는 자유롭게 조정 가능
- Pointwise convolution 연산은 보통 차원축소를 위해 많이 사용됨
-> 채널의 수를 줄여주기 때문에 연산량 감소에 있어서 매우 중요함!
- 연산량을 줄이는데 효과적이며, 필터 수를 줄여서 차원 축소 가능
- 채널 방향으로 연산을 수행하고 공간 방향으로 연산 수행 X
- 총 계산량: xxx
-: 채널수
-: 필터수
-: 이미지 사이즈
(d) Standard + Depthwise Separable Convolution
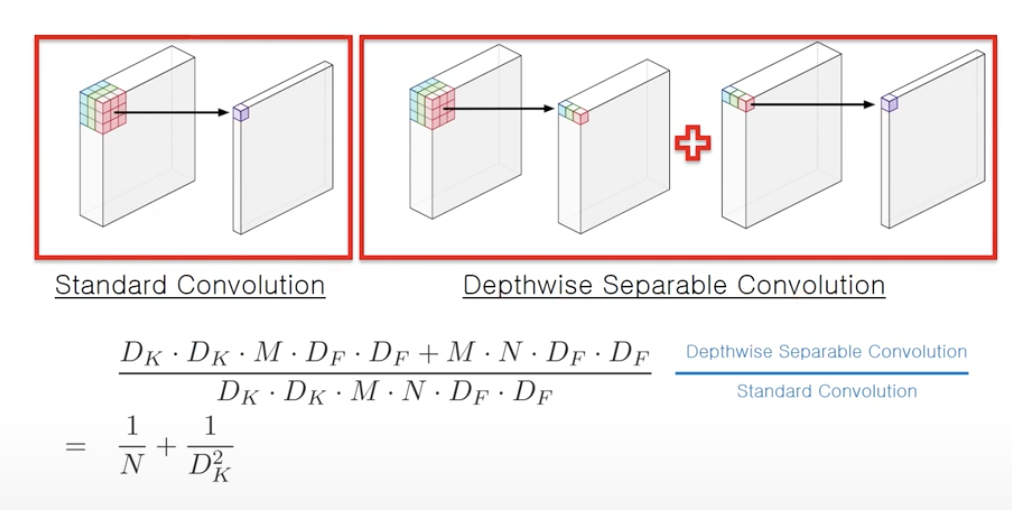
- 은 채널을 의미하는데 보통 64, 128, 512 등으로 구성
- 는 필터 사이즈를 의미하는데 보통 3x3를 많이 사용하므로 로 구성
2.2. Width Multiplier: Thinner Models
- 입력, 채널의 수를 배만큼 축소해준다.
-> 만일 출력 채널이 원래 512배이고 =0.5라고 하면 축소된 출력 채널수는 256개가 된다.
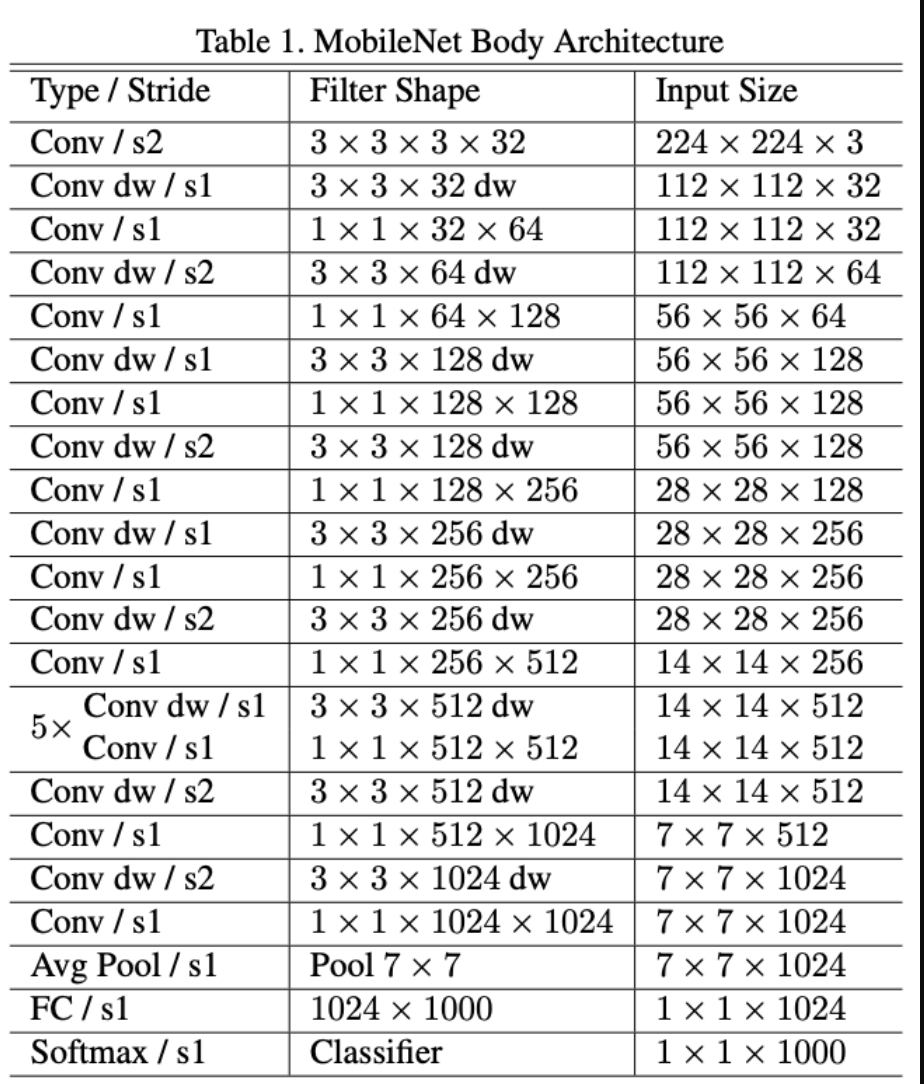
- 처음부터 Depthwise Convolution을 하는 것이 아닌, 일반적인 Conv연산을 진행한다. (s2:stride 2)
-> 정보 손실을 피하고자 일반적인 Conv 연산을 수행함
- 그 다음 Conv dw / s1 (dw:depthwise Conv) 와 Filter shape가 1x1x32x을 통해서 연산량을 줄여준다.
- 이 과정을 반복하고, 28번 Layer를 수행해준다.
- 마지막으로 Avg Pooling과 FC Layer를 거친 다음 Softmax를 통해서 Image Classification을 수행해준다.
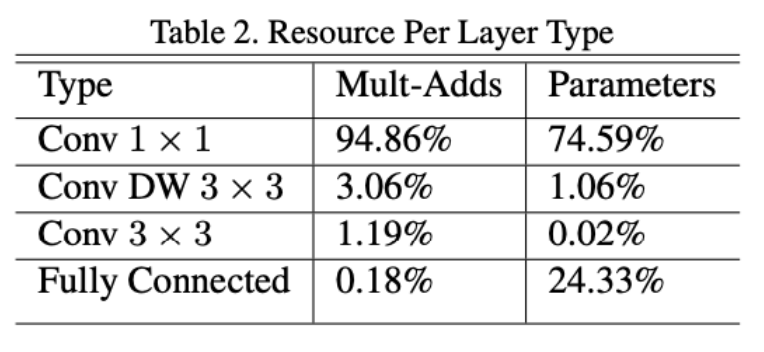
- 성능을 분석해보면, Conv 1x1이 94.86% 차지함
-> Feature map을 1x1 연산을 수행해주기 때문에 연산량이 많음
- Conv DW 3x3는 3.06% 차지함
- Conv 3x3는 1.19% 차지함
- FC는 0.18% 차지함
2.3. Resolution Multiplier: Reduced Representation
- 입력 영상 및 중간 레이어들의 해상도를 배 만큼 축소함
-> 만일 입력 영상의 해상도가 224x224이고, =0.571이라고 하면 축소된 해상도는 128x128임

Conv(462) ->Depthwise SeparableConv(52.3) 으로 9배가 줄어듦
- 입력 채널 수를 Width multiplier을 적용하기 위해서 를 0.75로 둘 때, 29.6으로 감소함
- resolution multiplier을 를 0.714로 둘 때, 파라미터의 수는 15.1로 감소함
2.4. Network Structure and Training
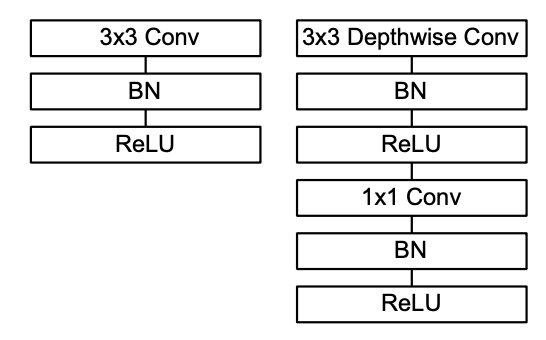
- 좌측은 Standard Convolution Layer
- 3x3 Conv -> Batch Normalization -> ReLu
- 우측은 Depthwise Separable Convoluton Layer
- 3x3 Depthwise Conv -> Batch Normalization -> ReLu -> 1x1 Conv -> Batch Normalization -> ReLu
3. Experiments
3.1 Model Choices

- ImageNet Accuracy에서 보면, 성능은 1.1% 감소했지만, 파라미터의 수는 (
4866) -> (569)로 9배가 감소한 것을 알 수 있음.
-> MobileNet이 연산 속도면에서 매우 효율적임

- 위의 표는 Layer가 깊을수록 좋은지 얕을수록 좋은지를 나타낸 표임.
- Layer가 깊었을 때가 얕았을 때보다 성능이 3.1% 더 좋았음.

- Width Multiplier의 수를 줄일수록 성능은 다소 떨어지지만 파라미터의 수도 감소하기 때문에 효율적인 연산이 가능해짐.

- Resolution에 따른 실험결과, 적을수록 성능은 줄어들지만, 파라미터의 수도 감소하기 때문에 효율적인 연산이 가능해짐.
3.2. Model Shrinking Hyperparameters

- 위의 그림은 연산량이 적어질수록 정확성이 Linear하게 떨어지는 것을 확인할 수 있음.
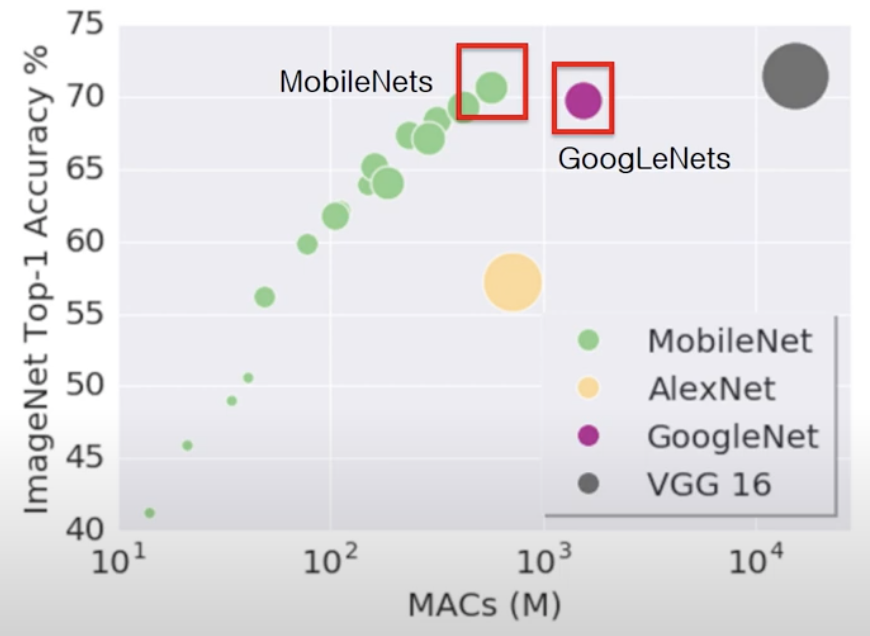
- MobileNet(2017)은 연산량을 줄였음에도 불구하고 GoogLeNet(2014)보다 성능이 좋았음.
- 그 뿐만 아니라 연산량도 더 적었기 때문에 효율적인 연산이 가능함.
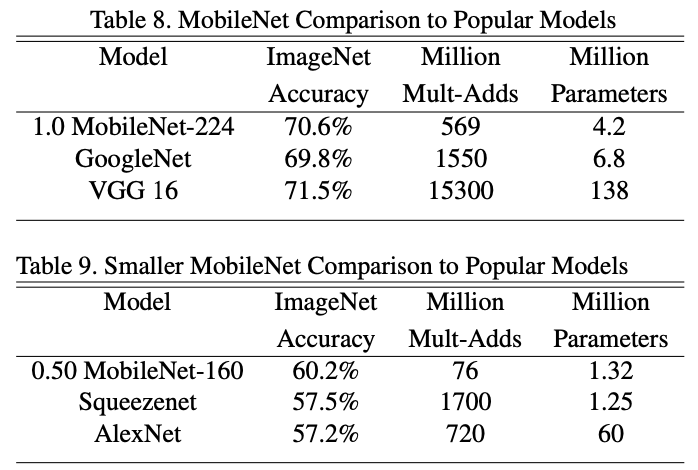
- 위의 정리와 같이 GoogLeNet보다 성능이 좋은 것을 확인 할 수 있음. 하지만 VGG보다는 성능은 다소 떨어지지만연산량이 많이 감소하여 효율적인 연산 가능함.
- Squeezenet과 AlexNet보다 성능이 더 좋으면서 연산량을 획기적으로 줄였다는 Insight 도출

- 위치 인식 Task에서 MobileNet을 사용했을 때 기존 PlaNet MobileNet보다 더 좋은 성능을 도달함.
정리하면, MobileNet은 classification, object detection, localization 등의 분야에서 널리 사용 가능함.
모델이 가볍기 때문에 모바일 또는 임베디드 기계에 적용하기 최적의 모델임.
4. Conclusion
- 효율적인 모델 구축을 위해 Width Multiplier & Resolution Multiplier을 활용하여 모델의 크기와 연산량을 줄였음.
- Layer수를 줄이는 것보다 Width를 줄이는 게 성능 향상에 도움이 됨.
- Depthwise Separable Convolution의 Idea는 단순하면서 강력함.
-> 이는 모델 연산량과 크기의 감소에 비해 성능 하락은 별로 없기 때문에 효율적인 모델임.
🎯 Summary
- 저자가 뭘 해내고 싶어 했는가?
Depthwsie convolution에1x1 convolution을 순차적으로 적용시키기!
- 정확도가 살짝 내려가지만 모델 크기를 줄이고 빠르게 하자!
- 이 연구의 접근 방식에서 중요한 요소는 무엇인가?
- Depthwise separable convolution
- Width multiplier
- Resolution multiplier
- 어느 프로젝트에 적용할 수 있는가?
- Image Classification
- Object Detection
- Localization
- 참고하고 싶은 다른 레퍼런스에는 어떤 것이 있는가?
- MobileNet-v2
- MobileNet-v3
- Inception v3
- Inception v4
- Xception
- 느낀점은?
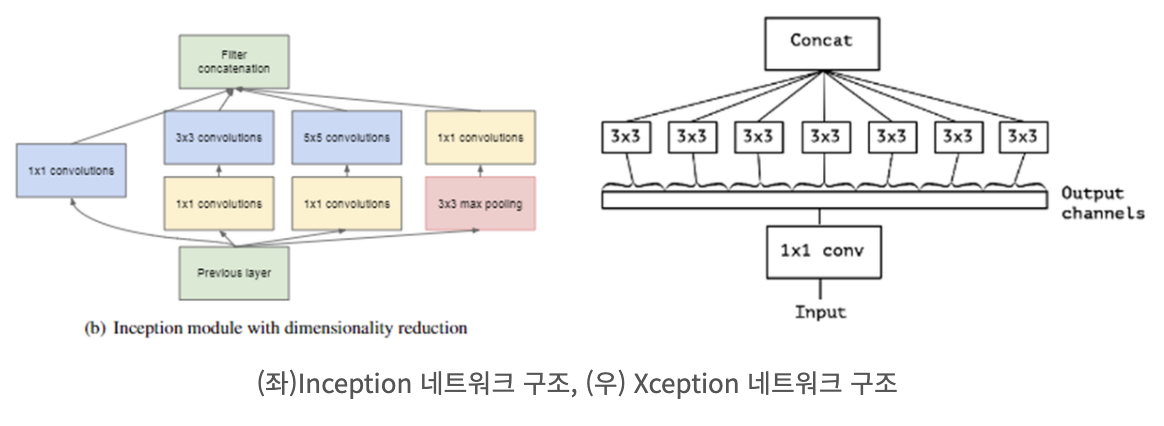
- Inception: 채널과 공간정보 각각에 대해
따로 학습을 함으로써 성능 향상을 증가시킴.
- MobileNet: Inception의
파라미터 감소에 Focus
- 기존에는 파라미터 감소로 인한 병렬적인 Conv를 활용하여 성능 향상을 도모함. 하지만 MobileNet에서는 Channel에 대하여 한번만 학습하여도
성능 저하가 없음+Parameter는 크게 감소하였기 때문에 너무 신기함.
- Transformer 등장 이전까지 Inception or Xception, ResNet 논문들과 같이 연산의 분리를 통해
파라미터 감소,병렬화,파편화중 하나를 집중적으로 타켓으로 잡아서 성능 향상을 위해 효율적인 모델을 구축한 느낌을 받았다.
- MobileNet v2와 v3 논문도 읽어봐야겠다!
📚 References
논문
유튜브
블로그

AI 전문가가 되기 위해 [a-zA-Z]까지 정리하는 거나입니다 😊