Clustering(군집분석)
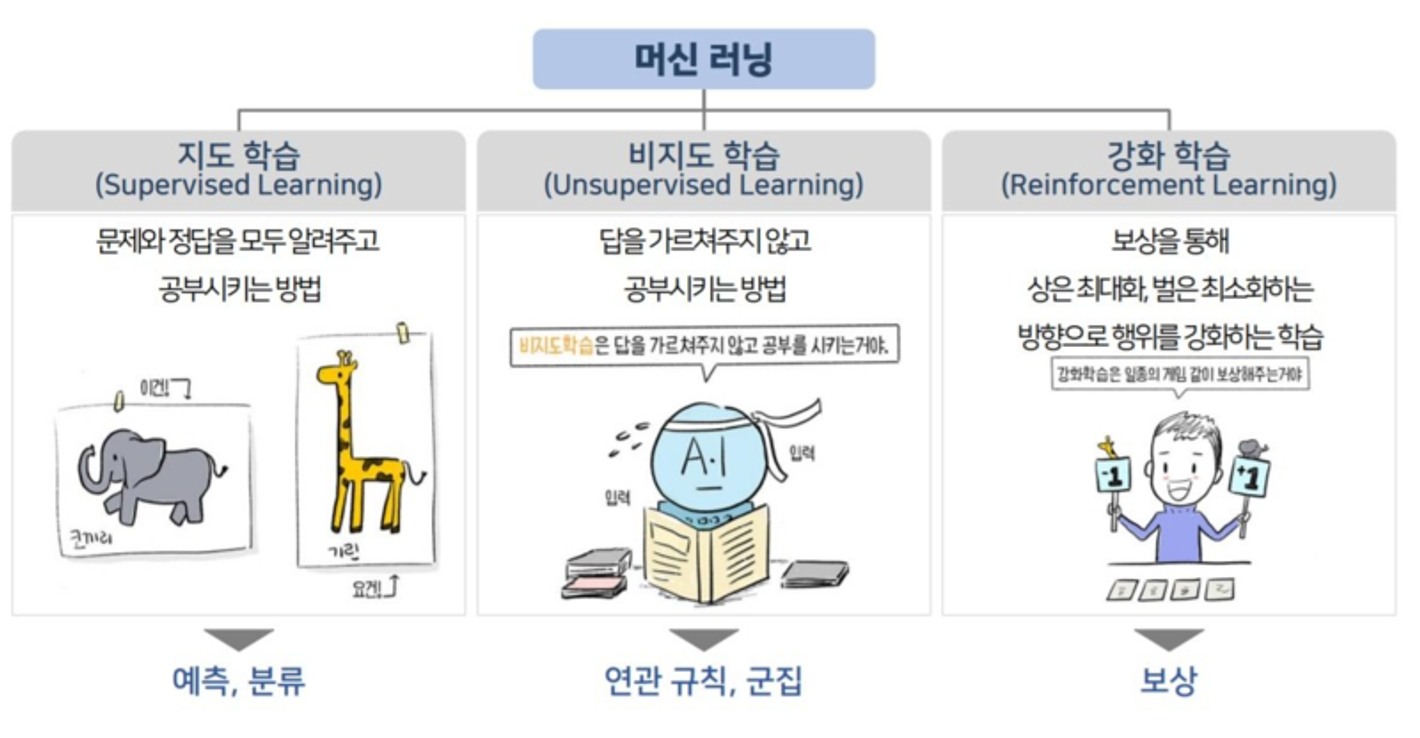
1. 클러스터링이란?
💡 정답이 없을 때, 정답을 찾아가는 과정!! = 비지도학습!
1) 정의
- 클러스터링은 데이터분석에서 피쳐(컬럼) 유사성의 개념을 기반으로 전체 데이터셋을 그룹로 나누는 그룹핑 기법이다. 여기서 각 그룹을 클러스터라고 한다!
즉, 의미있는 특징(컬럼), 우리가 놓치고 있는 부분등을 찾기위해 가설을 세우고, 최적의 그룹 갯수를 찾아 그룹별 인사이트를 도출해내야 한다!
2) 예시 - 마케팅데이터
클러스터링을 한 후, 기준을 어떻게 나눠야하는지 모를 때
▶ 결과 : '잠옷만 사는 고객', '골프채만 구매하는 고객' 등으로 분류. 그런데 나눠진 기준을 알 수 없다.
즉, 많은 컬럼들 속에서 어떻게 군집을 나누면 좋을 지 보고 싶을 때 클러스터링을 진행한다!
😄 : "우리 데이터 컬럼 이만큼 다 줄테니까, 니가 나눠봐!"
🤨 : "어 이상한데 몇개 빼고 다시해봐~"그 뒤에, 그룹이 잘 나뉘어 졌는지는 시각화를 통해 확인!
2. 클러스터링 프로세스
1) 프로세스(pre-processing)
① 기간 선정 : 클러스터링을 위한 데이터 기간 설정
- 의미 있는 패턴을 도출하기 위해서 ▶ 최소 3개월 이상의 데이터셋이 권장
- 클러스터링의 목적 : live한 데이터의 유입 시 유저의 행동을 통해 이를 알맞게 배치시키는 모델의 생성
- 해당 모델은 초기에 생성, 서비스 변동사항에 따라 일정 주기에 따라 재시행!
② 이상치 기준선정 및 제외 : IQR, Z-SCORE 등 다양한 이상치 기법을 통해 이상치 비중 기록
- 🌀 Z-SCORE
- 데이터의 분포가 정규 분포를 이룰 때, 데이터의 표준 편차를 이용해 이상치를 탐지하는 방법
- 각 데이터(행) 마다 Z-SCORE를 구한다.
- Z값은 X에서 평균을 뺀 데이터를 표준편차로 나눈 값. 표준 점수라고 부른다.
- 표준 점수는 평균으로부터 얼마나 멀리 떨어져 있는지를 보여주며, 일반적으로 -3에서 +3 사이의 값을 가진다. ❗±3 이상이면 이상치로 간주한다.❗
- ⚠️ 현업에서는, 정확한 ±3을 따지기 보단, 회사의 니즈에 따른 특정 조건에 따라 기준을 정립하고 이를 적용하여 데이터를 핸들링한다.
- Z-SCORE=0 : 평균과 같음을 의미한다. (= 평균에서 떨어진 거리가 0)
- Z-SCORE>0 : 평균보다 큼. (ex. Z-SCORE가 1이면, 평균보다 1 표준편차만큼 더 큰값을 의미)
- Z-SCORE<0 : 평균보다 작음. (ex. Z-SCORE가 -1이면, 평균보다 1 표준편차만큼 더 작은값을 의미)
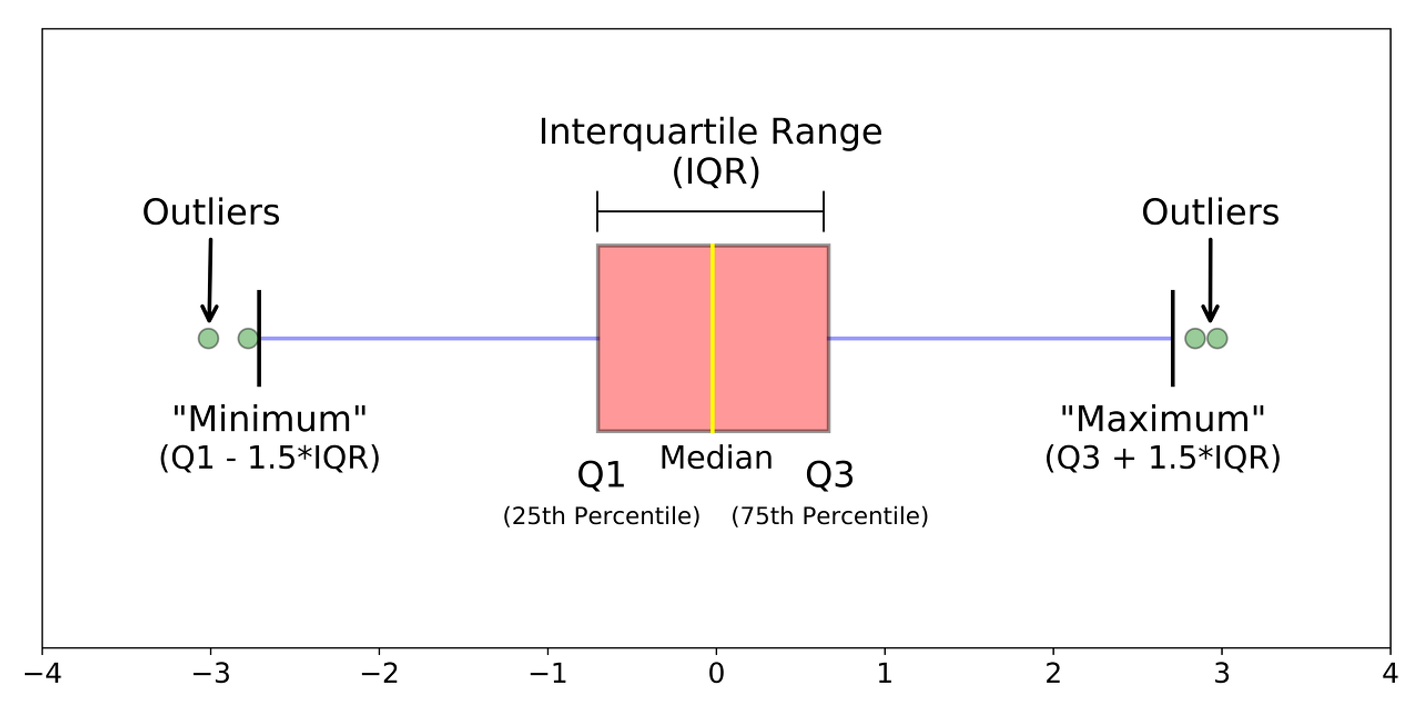
- 🌀 IQR(Interquartile Range)
- 데이터의 분포가 정규 분포를 이루지 않을 떄 사용한다.
- 데이터의 25% 지점()과 75% 지점() 사이의 범위()를 사용한다. ❗이를 벗어나는 값들은 모두 이상치로 간주❗
- 이걸 시각화 한 것 = Box Plot, IQR 밖의 데이터 포인트는 이상치로 표시
- IQR : (제 3사분위 값) - (제 1사분위 값)
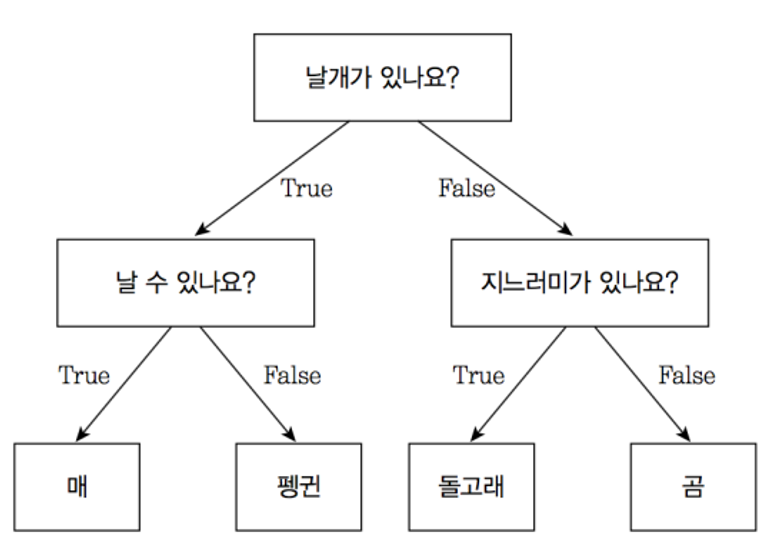
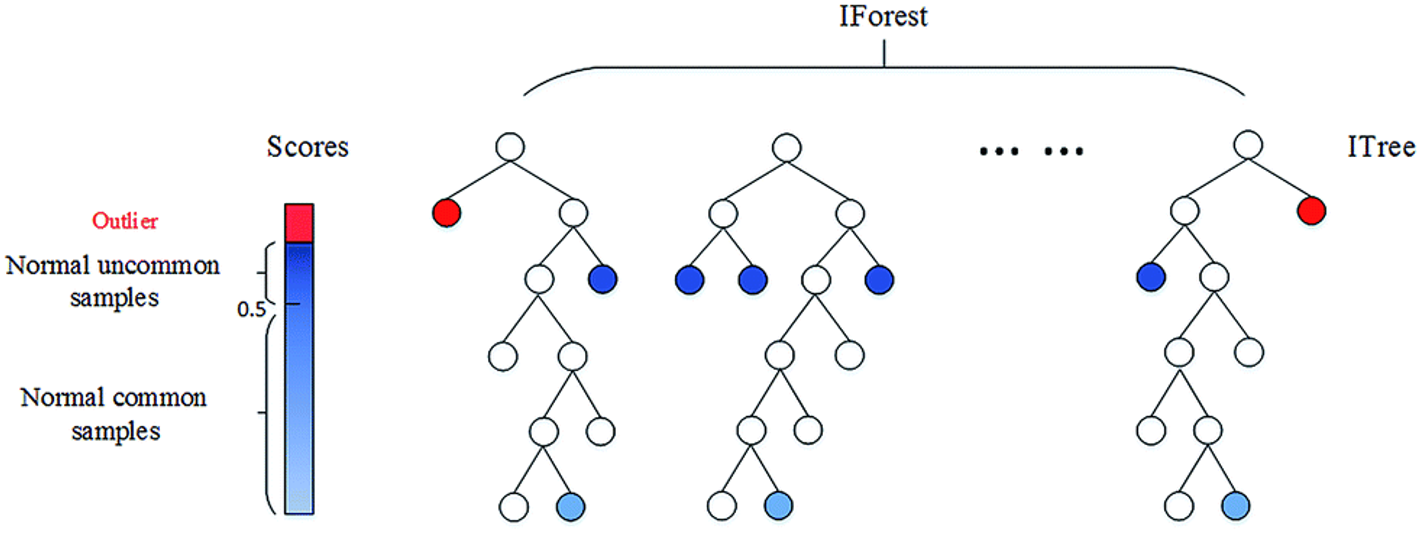
- 🌀 Isolation Forest
- 머신러닝 기법 중 하나다. ❗컬럼 갯수가 많을 때 이상치를 판별하기 용이하다.❗
- 데이터셋을 의사결정나무 형태로 표현한다.
- 질문에 질문들이 꼬리를 물고 이어져, 각 값은 매, 펭귄, 돌고래, 곰 중 하나에 배치된다.
- 하지만 이상치의 경우, 어디에도 속하지 않는다.
- ✅ 한번 분리될 때 마다 경로 길이가 부여되며, 트리에서 몇 번 분리해야 하는지(데이터까지의 경로 길이)를 기준으로 데이터가 이상치인지 아닌지를 판단
- ✅ 즉, 이상치는 다른 관측치에 비해 짧은 경로 길이를 가진다.
- 경로 길이로 점수는 0에서 1사이로 산출되며, 결과가 1에 가까울수록 이상치로 간주한다.
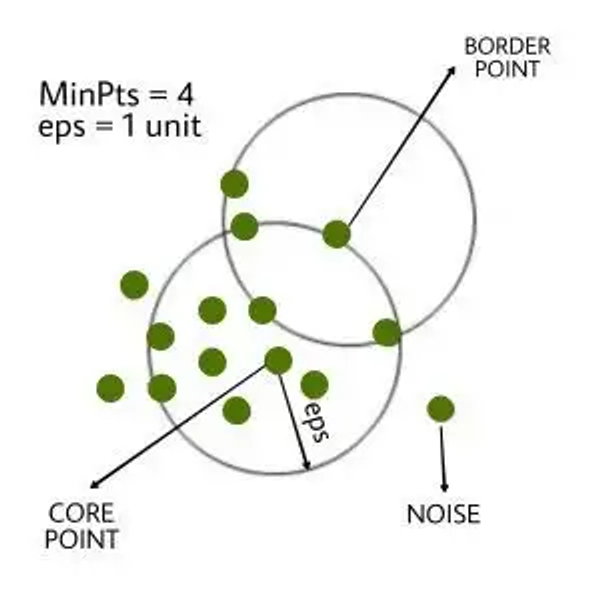
- 🌀 DBScan
- 밀도 기반의 클러스터링 알고리즘으로, 어떠한 클러스터에도 포함되지 않는 데이터를 이상치로 탐지하는 방법! ❗복잡한 구조의 데이터에서 이상치를 판별하는데 유용하다.❗
- ex. 지리 데이터 분석, 이미지 데이터 분석의 이상치 기법으로 사용.
- 각 데이터 밀도를 기반으로 군집 형성 ▶ 설정된 거리 내에서 설정된 최소 개수의 다른 포인트가 있을 경우 ▶ 해당 포인트는 핵심포인트로 간주!
- ✅ 핵심 포인트들이 서로 연결되어 군집을 형성하며, 이와 연결되지 않은 포인트 = 이상치로 분류.
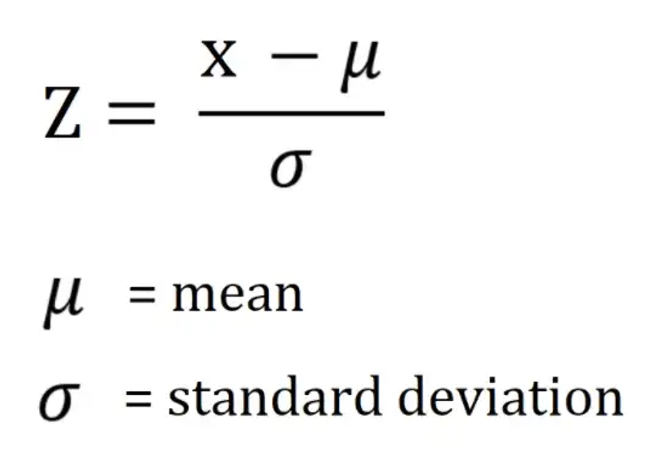
③ 표준화 : 데이터의 크기가 너무 크거나, 컬럼 간 데이터 range에 차이가 많을 때 일부 컬럼에 대해 진행! (ex. 데이터의 변동이 큰 경우 = 잔잔하게 있다가 갑자기 데이터가 팍! 튀었는데, 그 팍! 튄 자리에서 잔잔하게 있는 경우 표준화 진행)
- 🌀 MinMax Scale
- 모든 데이터 값을 0과 1 사이에 배치
- ❗이상치에 취약하다.❗
- ex.
df['pay_amt'] = 0,0,0,0,1,2,3,10000에서 100이 1에 배치되면서 나머지 값들은 0에 수렴하는 값을 가지게 되므로, 전체 데이터 분포가 뭉해지기 때문이다!- 🌀 Standard Scale
- 평균을 0, 표준편차를 1로 변환.
- ❗MinMax Scale이 가지는 한계점을 보완한다.❗
- 각각의 Data point가 '평균으로부터 얼마나 떨어져 있는지'에 대한 수치로 변환
- ✅ 군집 분석시 가장 많이 쓰는 표준화 기법
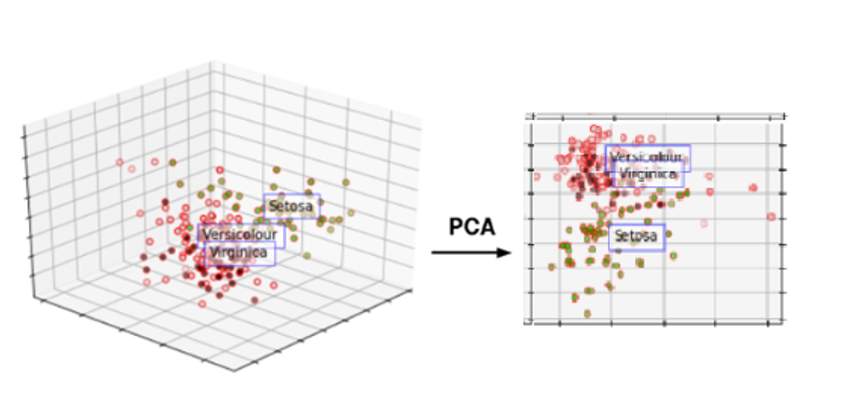
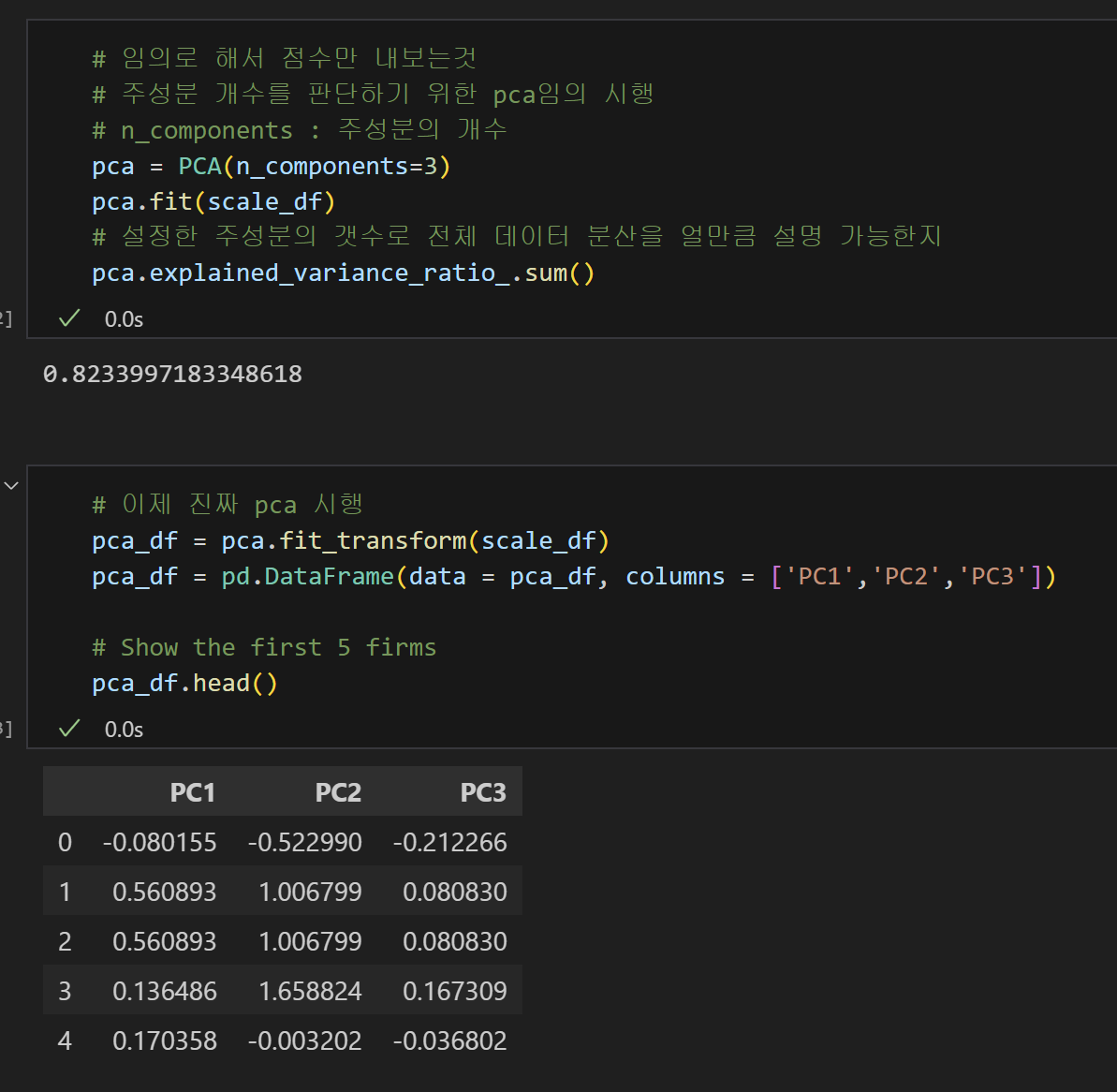
④ 🌟🌟차원 축소(PCA)🌟🌟 : 가장 대표적인 차원 축소 기법
- 많은 컬럼으로 구성된 다차원 데이터 세트의 차원을 축소하여 새로운 차원의 데이터 세트를 생성하는 것.
- (= 컬럼이 너무 많기 때문에 학습이 어렵고 더 좋은 특징만 가지고 사용하겠어!!)
"컬럼이 너무 많아서 뭘로 나눠야할 지 모르겠어!!" ▶ "오! 차원축소로 중요한 성분을 가지고 그걸 기준으로 데이터를 나눠 보겠어!! ▶ "성분을 2개~3개 골라볼까?" 의 시작점이 차원 축소
- 여러 변수 간에 존재하는 상관관계를 이용하여 이를 대표하는 주성분을 추출해 차원을 축소하는 기법.
- (데이터의 분포를 가장 잘 표현하는 성분을 찾아주는 것.)
- ✅ 핵심 : 가장 높은 분산을 가지는 데이터의 축을 찾아 그 축으로 차원을 축소하는 것.
- 축 = 주성분 = 피쳐 = 컬럼 = 차원
- 100%는 없다. 그래서 로 유의미한지 따져야 한다.
2) 프로세스(Experiment) : 비지도학습이라서 직접 k값을 넣어야한다. 이때 K값을 참고할때 다음의 3가지를 사용!!
⑤ K값(군집갯수), 초기 컬럼(피쳐) 선정 :
Sillhouette Coefficient,elbow-point,Distance Map을 통해 초기 군집 갯수 지정
- 초기 컬럼의 설정은 모든 컬럼을 기준으로 진행
- 클러스터링을 반복진행하며, K값과 피쳐의 컨디션을 기록하고, 최적으로 구분된 컨디션을 찾는다.
- 경우에 따라, 파생변수(ex. 게임시간, 획득한 경험치, 시간당 평균 획득 경험치(얘가 파생변수)를 확인)를 만들어 클러스터링을 진행하기도 함!!
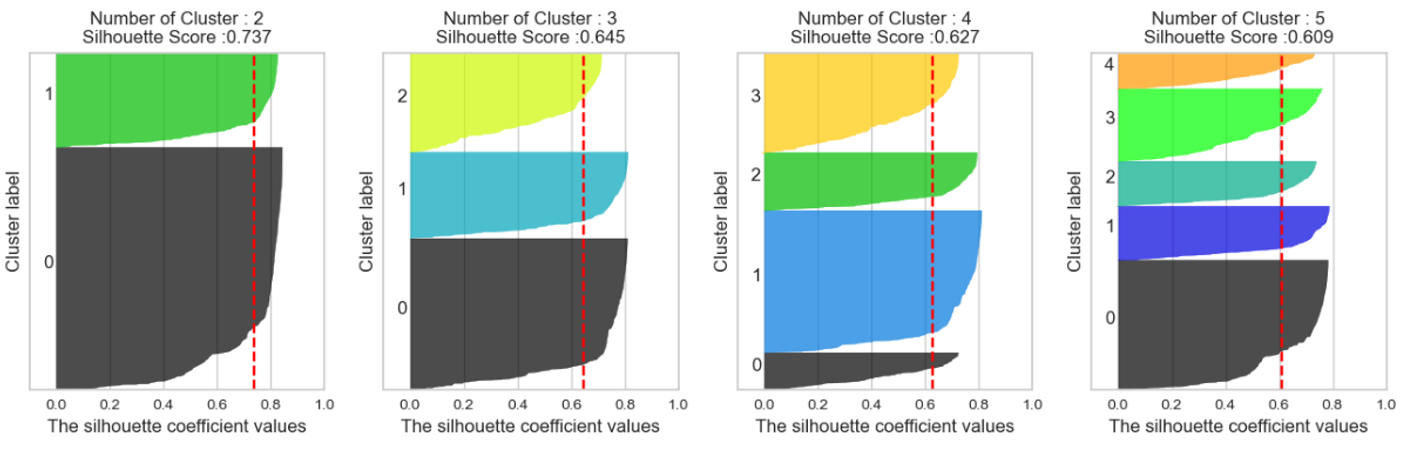
- 🌀 Sillhouette Coefficient
- "아 K값 몇개로 나눠야할 지 모르겠는데, 실루엣계수 함 볼까?"
- 각 군집간의 거리가 얼마나 효율적으로 분리되어 있는지를 나타낸다.
- 효율적으로 잘 분리되어 있다 = 다른 군집과의 거리는 떨어져 있고, 동일 군집끼리 데이터는 서로 가깝게 뭉쳐있다.
- 실루엣 계수는 -1에서 1사이의 값을 가지며, -1이나 1에 가까울수록 근처의 군집과 멀리 떨어져 있는 것이며 0에 가까울수록 근처 군집과 가깝다는 뜻이다!
- ✅ 즉, -1이나 1에 가까울수록 군집 간 거리가 유의미하게 구분된다는 것을 의미한다.
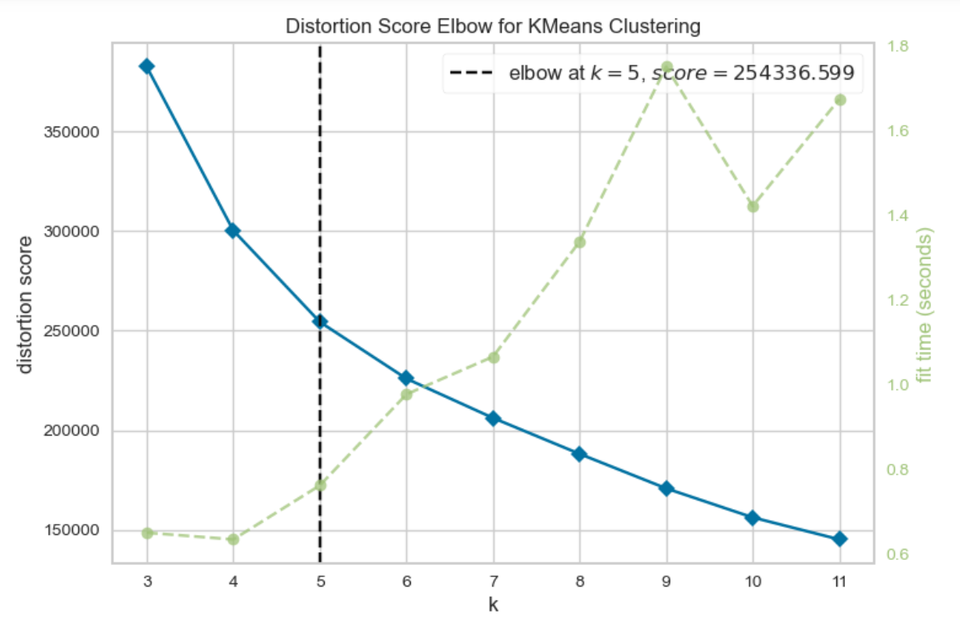
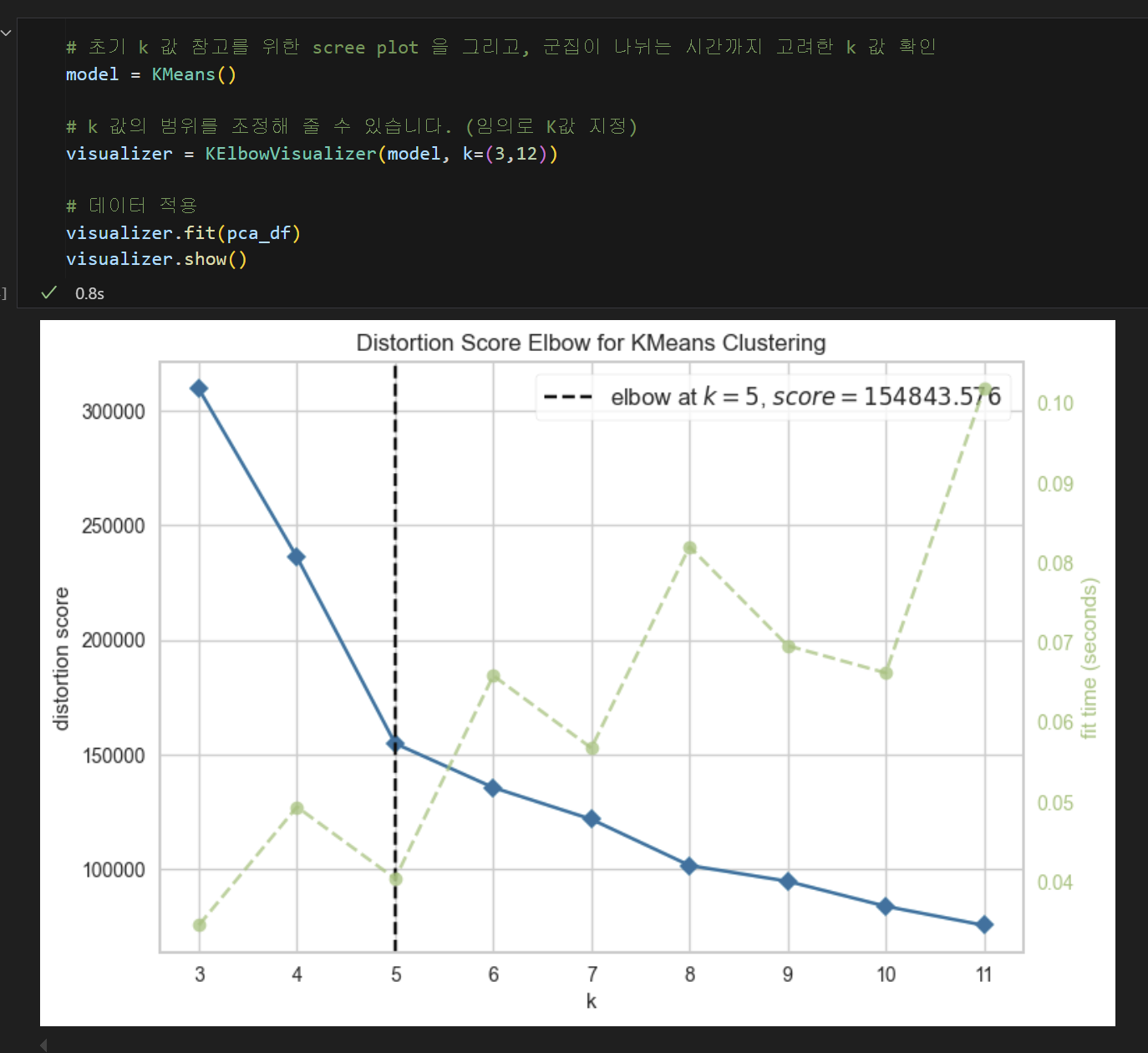
- 🌀 Scree plot의 elbow-point
- ⚠️ K값이 뭔지 모르겠을 때 가장 중요하게 봐야하는 지표!
- yellow brick library - elbow method를 사용하여, 알고리즘이 군집이 나뉘는 시간까지 고려한 K값을 도출한다.
- X축 = K값 = 군집 갯수
- elbow-point = 가장 많이 꺾이는 구간 = 까만색 점선
- 초록색 점선 : 군집을 나누는데 까지 알고리즘이 수행한 시간
- (ex. 9개로 나누는건 힘들었는데, 10개로 나누는건 쉬웠다!)
- elbow-point와, 각 군집이 갯수로 나누는데 까지 걸린 알고리즘의 시간을 포함하여 최적의 K값을 보여준다.
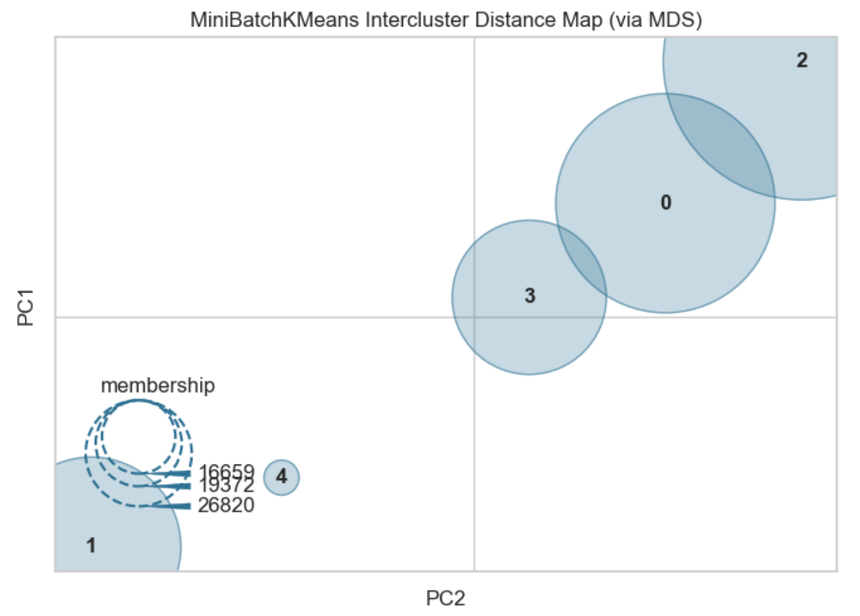
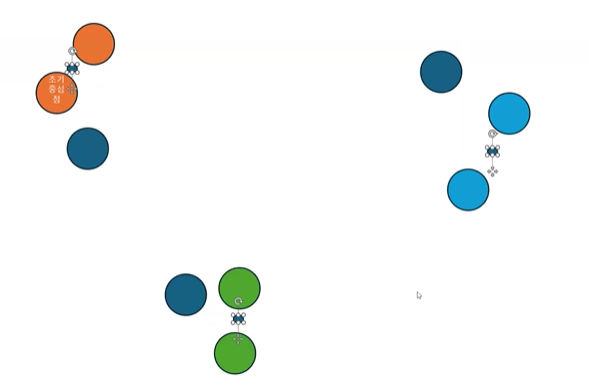
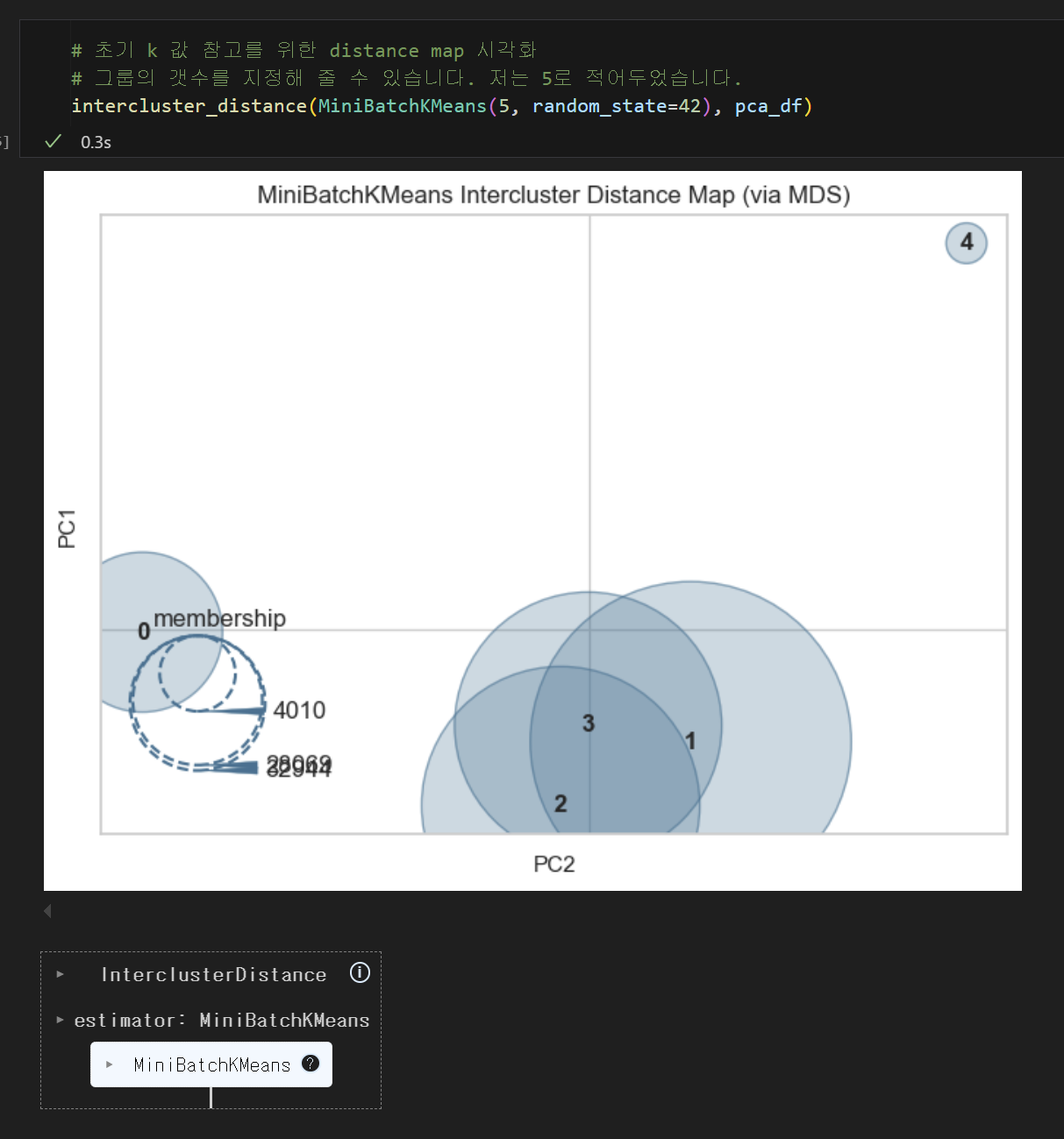
- 🌀 Distance Map
- 군집간 거리를 시각화 해주는 기법
- 실행마다 다르게 보여질 수 있다.
- 군집이 떨어져 있는 거리를 가시적으로 확인하기 위한 참고치일 뿐이다.
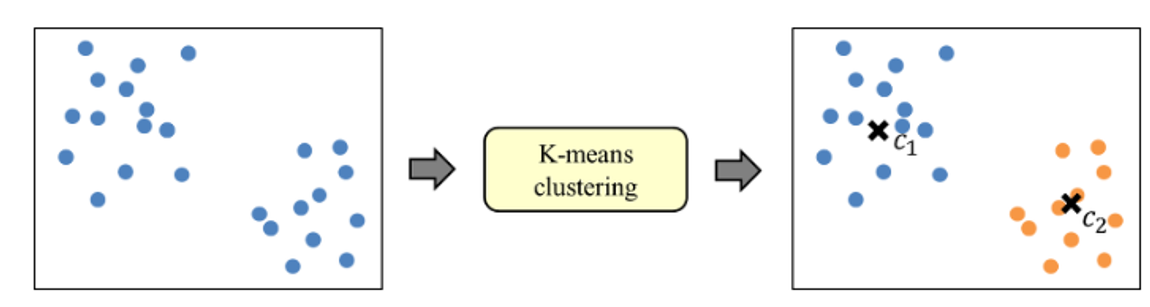
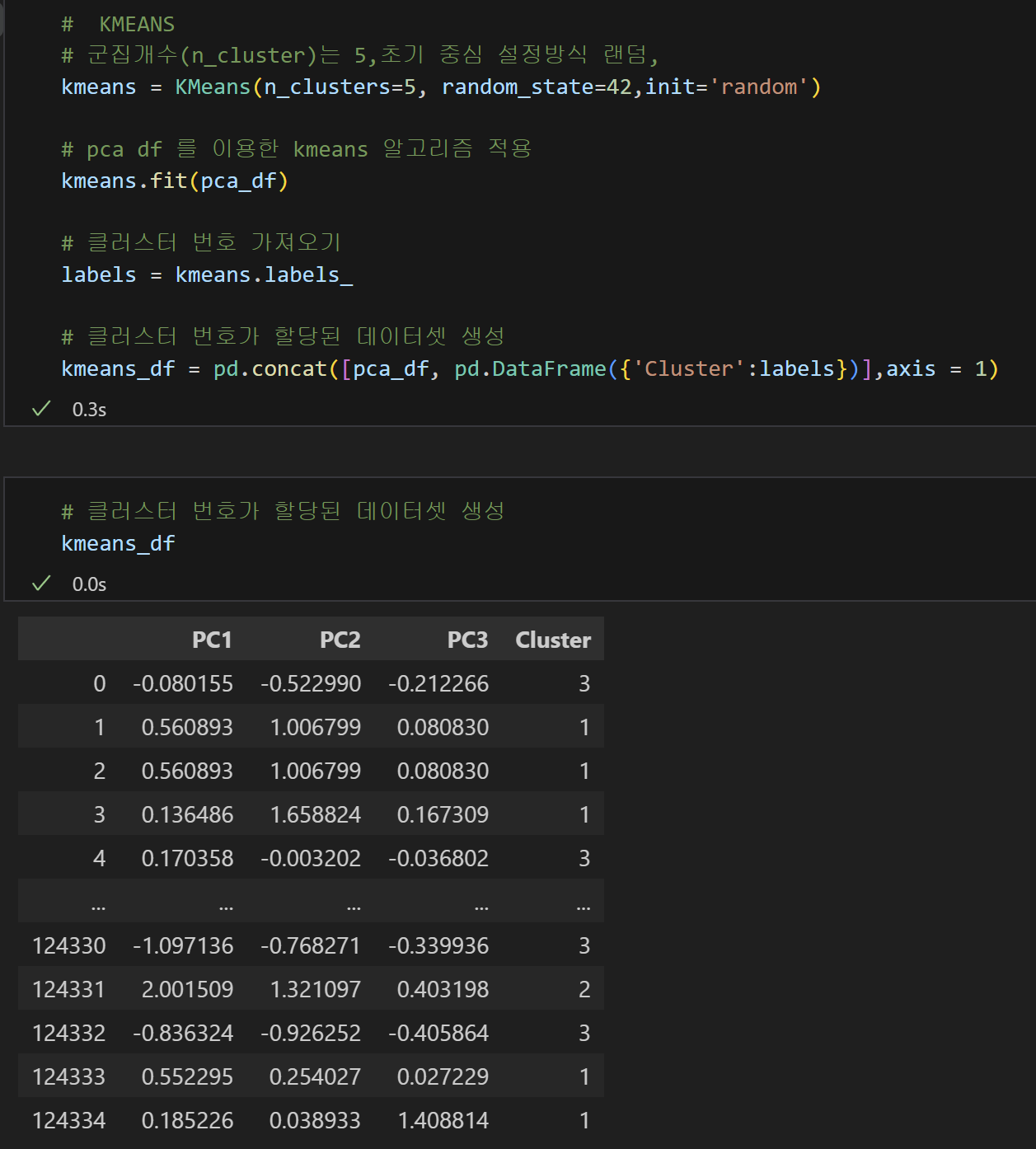
⑥ k-means clustering 시행 : 데이터를 거리기반 K개의 군집(Cluster)으로 묶는(Clustering) 알고리즘
- K : 묶을 군집(Cluster)의 개수
- means : 평균
- ✅ 즉, 각 군집의 평균(mean)을 활용하여 K개의 군집으로 묶는다!!
- 🌀 알고리즘
- 중심점을 랜덤하게 설정하고, 임의의 점에서 절대거리를 계산하고 가장 가까운 군집에 배치한 뒤, 중심점을 평균으로 업데이트하고, 다시 다음 점에 대해 알고리즘을 돌리는 것. 이 중심점이 더이상바뀌지 않을때(= 평균의 값이 더이상 변하지 않는다 = 더이상 나눌 데이터가 없다)까지 군집을 수행!
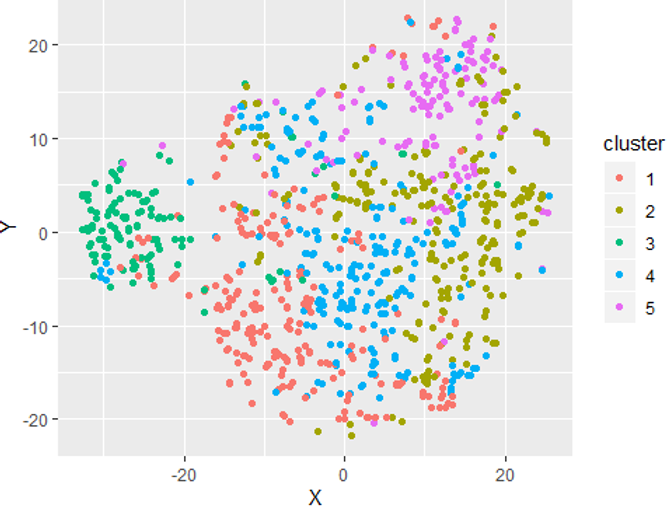
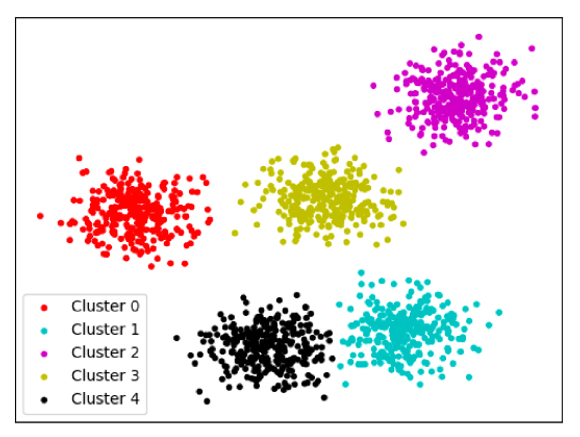
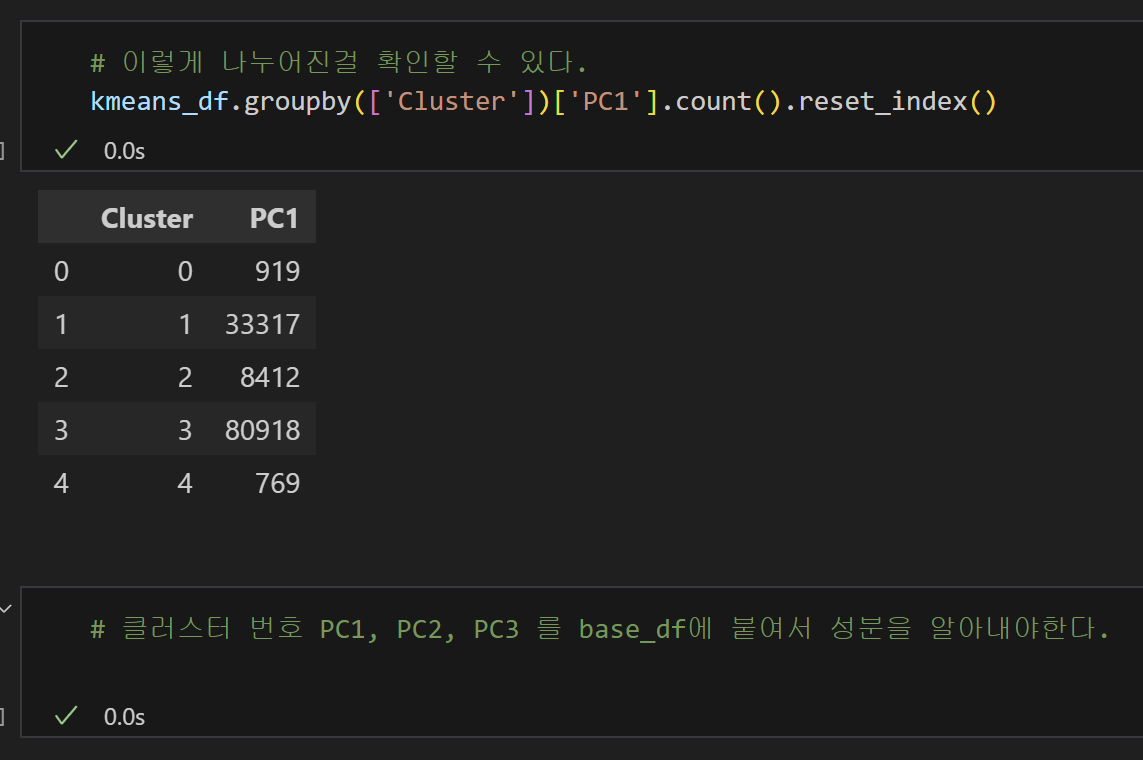
⑦ 군집 분포 확인
- 데이터셋을 기반으로 데이터가 잘(얼마나 밀도있게) 나뉘었는지 확인하는 과정을 거치게 된다.
- scatter plot은 군집이 잘 나뉘어진걸 확인한다.
- K값과 컬럼(피쳐)을 조정하며, 군집별 특성이 명확하고 각각의 data point가 충돌하지 않도록 실험을 반복해야한다.
- ⚠️ 반드시 기록하면서 비교해야한다!!
⑧ ②~⑦번 과정을 반복하며 최적의 결과 도출
- 실험을 수행할 때마다 다양한 기준을 고려해야 한다.
- 통계학적 지식을 필요로 하지만, 이것이 모든 부분을 설명할 수 없다. (추론통계니까!)
- 비지도학습인만큼, 주관이 개입되어야한다.
- 데이터 자체에 결측이 많지는 않은지? (ex. 50%이상 결측이면, 해당 컬럼 버린다.)
- 데이터가 결측은 아니나, value가 0인 경우가 많은지?
- 데이터의 전반적인 분포는 어떠한지?(컬럼별로) 컬럼 간 상관계수는 어떠한지?
- 데이터가 불규칙한지? (불규칙▶표준화)
- 컬럼이 가지는 개념적인 의미는 무엇인지? (주관▶ex. 고객 분류 시, 결제금액을 제외하냐? NO!)
- 컬럼 값이 이진형인지? (T/F는 지양하는게 좋음▶클러스터링 시 극단적인 결과를 불러옴)
- cluster 비중이 지나치게 편향되어 있는지?(ex. A-100명, B-100명, C-100만명 ▶ NO!)
⑨ 모델링
- 클러스터링 결과를 가지고 이를 모델에 학습시킨다.
- 모델은 우리가 실험한 로직을 매번 수행하지 않도록 해주는 개념이다!!
⑩ 데이터 적재 및 자동화 설정
- 이렇게 cluster 별로 나뉜 고객들을 별도 테이블에 저장해준다.
- Python으로 진행할 수 있다.
- 스케줄 기능을 통해, 주기별로 라이브한 데이터를 자동 테이블에 적재하는 것 까지가 클러스터링의 최종 작업이다.
⑪ 인사이트 도출
- 이렇게 적재된 테이블을 통해 클러스터별로 인사이트를 도출할 수 있다.
3. Python code 실습
1) 라이브러리 설치 및 데이터 로드
2) 데이터 확인 및 결측치 제거
3) 클러스터링 할 컬럼 지정 : 연속형 변수들만
4) 표준화
5) 차원축소(PCA)
6) k값, 초기 컬럼(피쳐) 설정
screen plot의 elbow-point로 k값 설정
distance map으로 군집간 거리 확인
7) kmeans clustering 시행
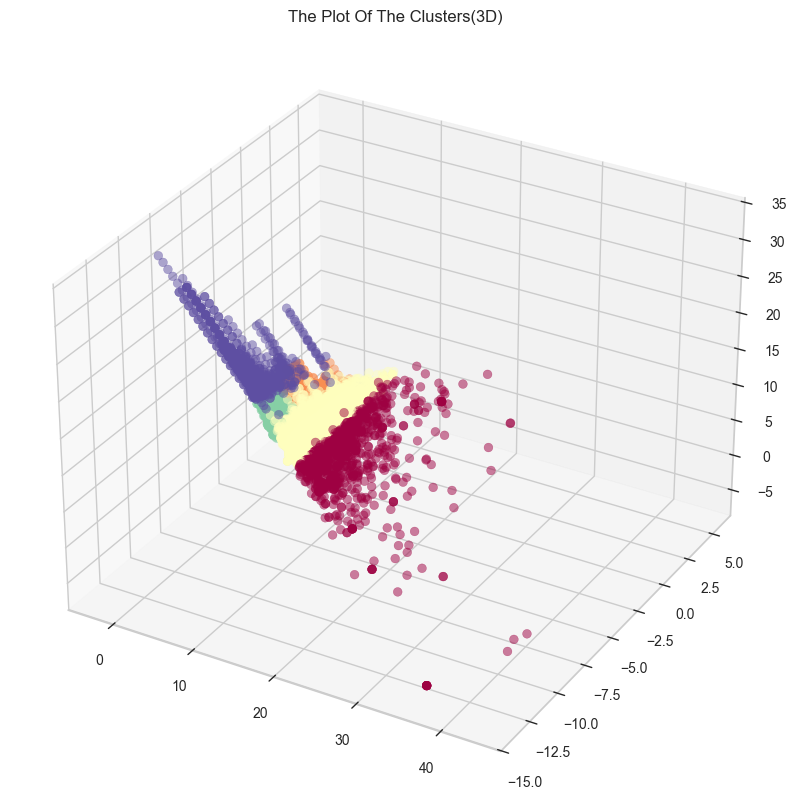
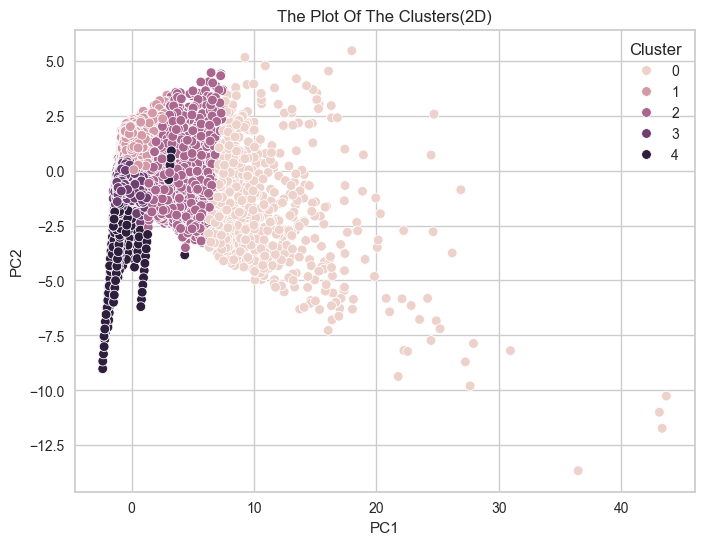
8) 군집 분포 확인 : 시각화
-3D
-2D
9) 결론
scatterpolt에 검은 점들이 섞여 있으므로, 피쳐를 조절해가며 다시 진행해야 한다.
*클러스터 번호에 base_df의 컬럼을 concat해서 어떤 컬럼이 기준인지 알아내야 한다.

First time, Last time, Every time.