선형회귀 심화
다중선형회귀
: 실제 데이터들은 비선형적 관계를 가지는 경우가 많다. 이를 위해서 X변수를 추가 할 수도, 변형할 수도 있다.
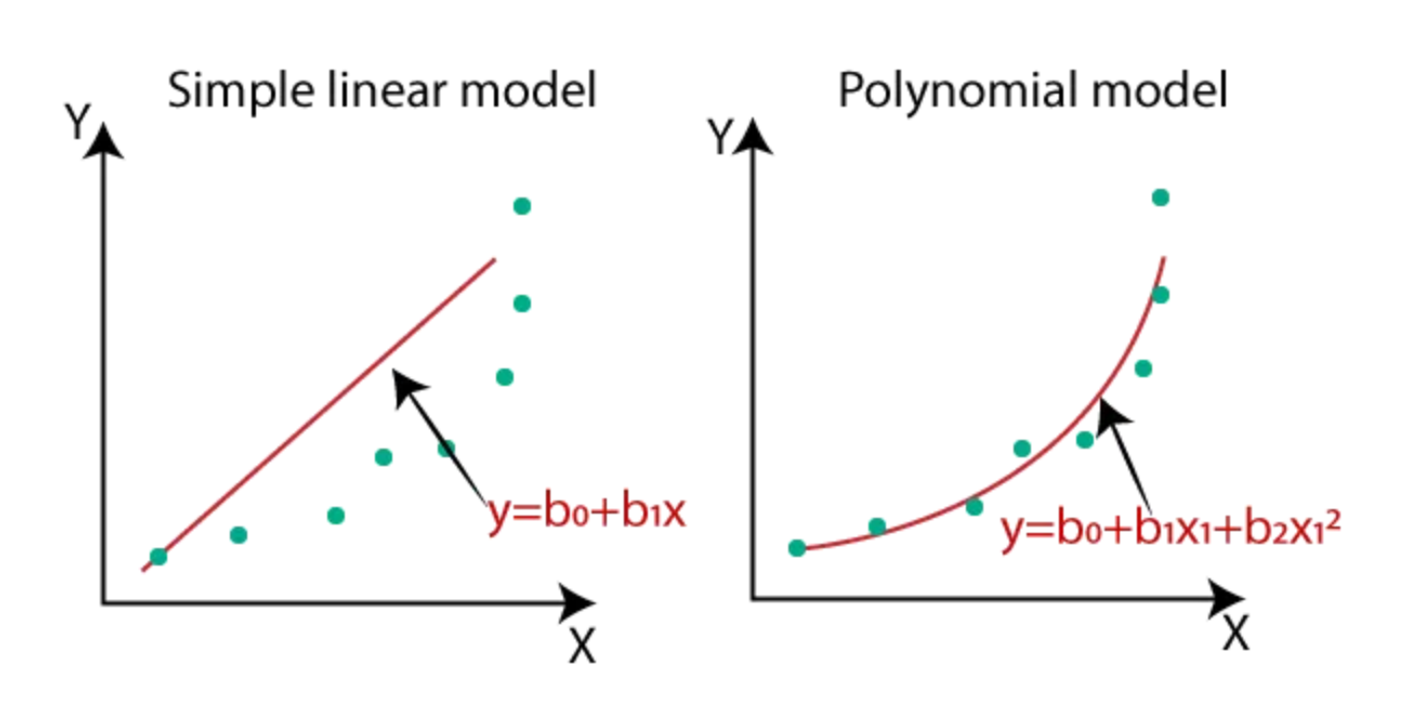
여기에서 제곱을 하거나, X변수가 추가되면 그게 바로 다중선형회귀이다.
ex) X = df[['']] ''안에다가 여러개 넣으면 된다.
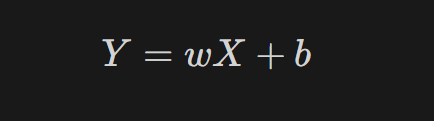
범주형 데이터 사용하기
범주형 데이터 vs 수치형 데이터
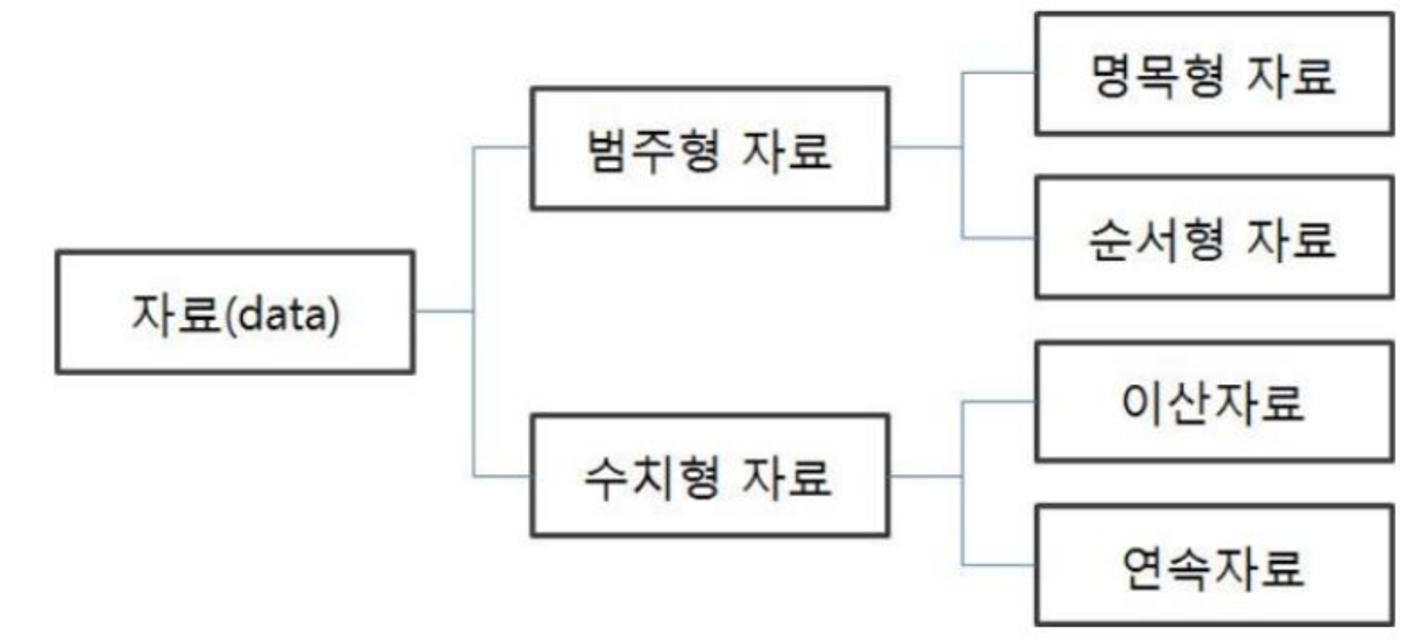
1) 범주형 데이터
- 순서형 자료 : 자료의 순서가 의미 있음!
ex) 학점(A,B,C,D,F > 0, 1, 2, 3, 4 등으로 변경), 등급
- 명목형 자료 : 자료의 순서가 의미 없음!
ex) 혈액형, 성별
2) 수치형 데이터
- 연속형 데이터 : 두 개의 값이 무한한 개수로 나누어진 데이터
ex) 키, 몸무게
- 이산형 데이터 : 두 개의 값이 유한한 개수로 나누어진 데이터
ex) 주사위 눈, 나이
범주형 데이터 실습
- 머신이는 데이터 선형회귀를 훈련 시켰지만 성능이 별로 좋지 않다는 것을 알게 되었다. 그래서 성별과 같은 다른 데이터를 사용하고 싶어졌다. 그런데 문제는 성별데이터는 문자형이어서 숫자로 표현할 방법이 필요해졌다.
- 머신러닝 모델에 데이터를 훈련시키려면 해당 데이터를 숫자로 바꿔야한다.
- 성별, 날짜와 같은 데이터를 범주형 데이터라고 부르며 이를 임의로 0, 1 등의 숫자로 변경할 수 있다. 이것을 Encoding 과정이라고 한다.
범주형 데이터 실습
- 함수를 쓸 수도 있고, sklearn에서 제공하는 함수를 쓸 수도 있다.
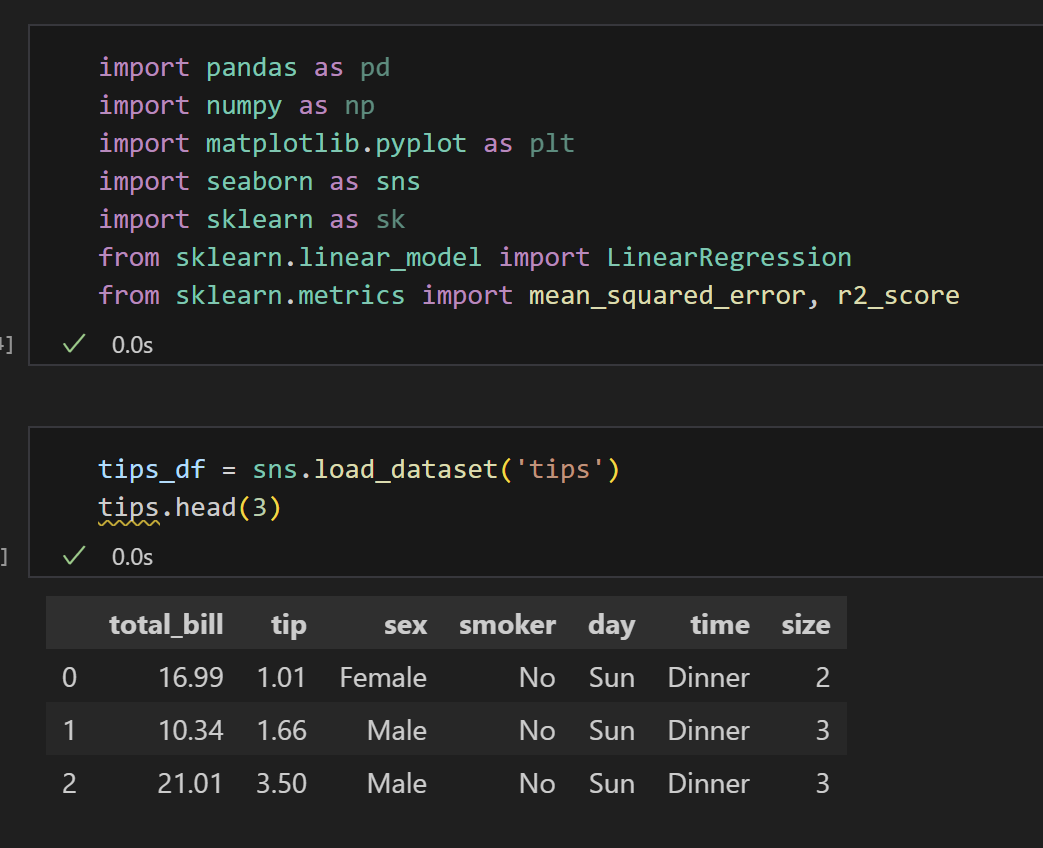
1) 데이터 생성 및 라이브러리 설치
2) 선형회귀모델을 불러오고 데이터 훈련하기
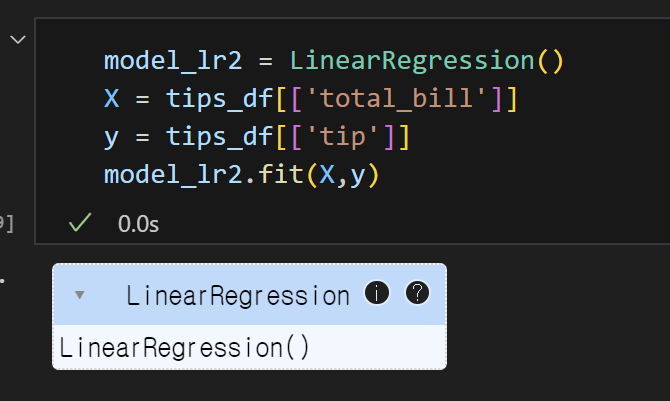
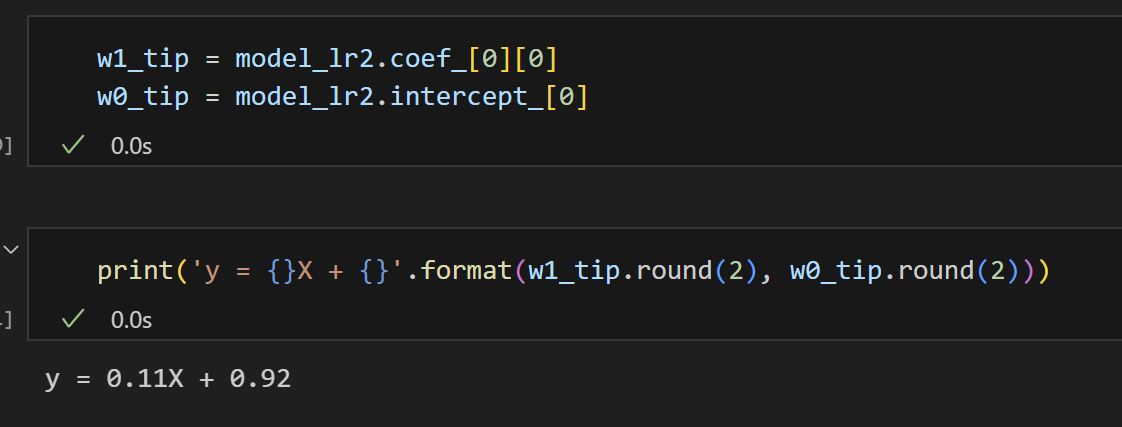
3) 가중치와 편향 구하기
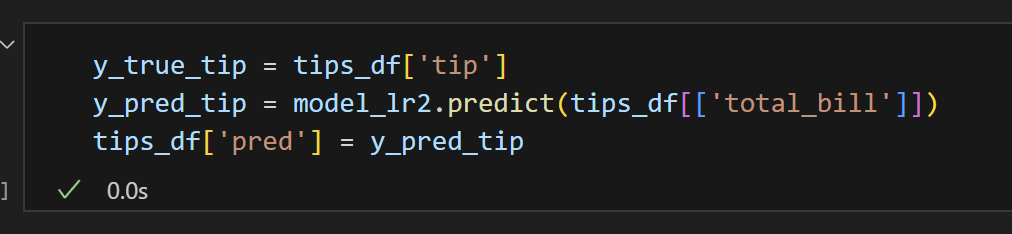
4) 예측 컬럼 만들기
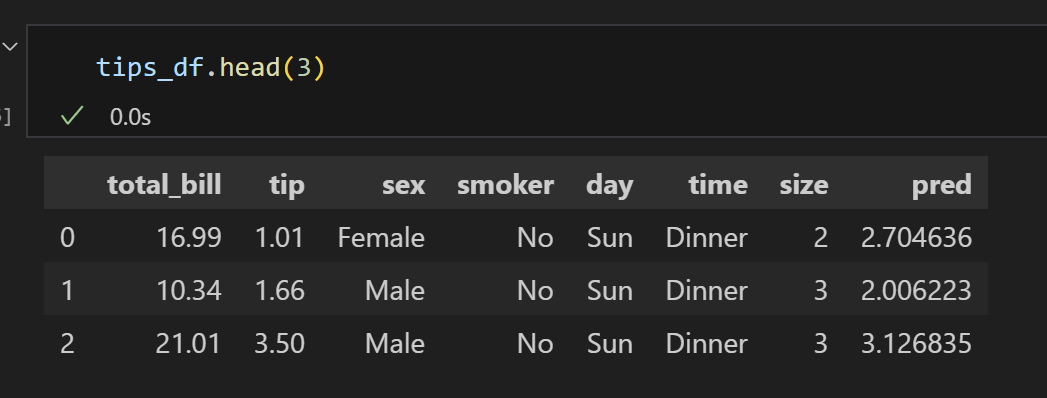
5) 데이터프레임 확인하기
6) 명목형 데이터인 'sex'를 수치형 데이터로 변환하기
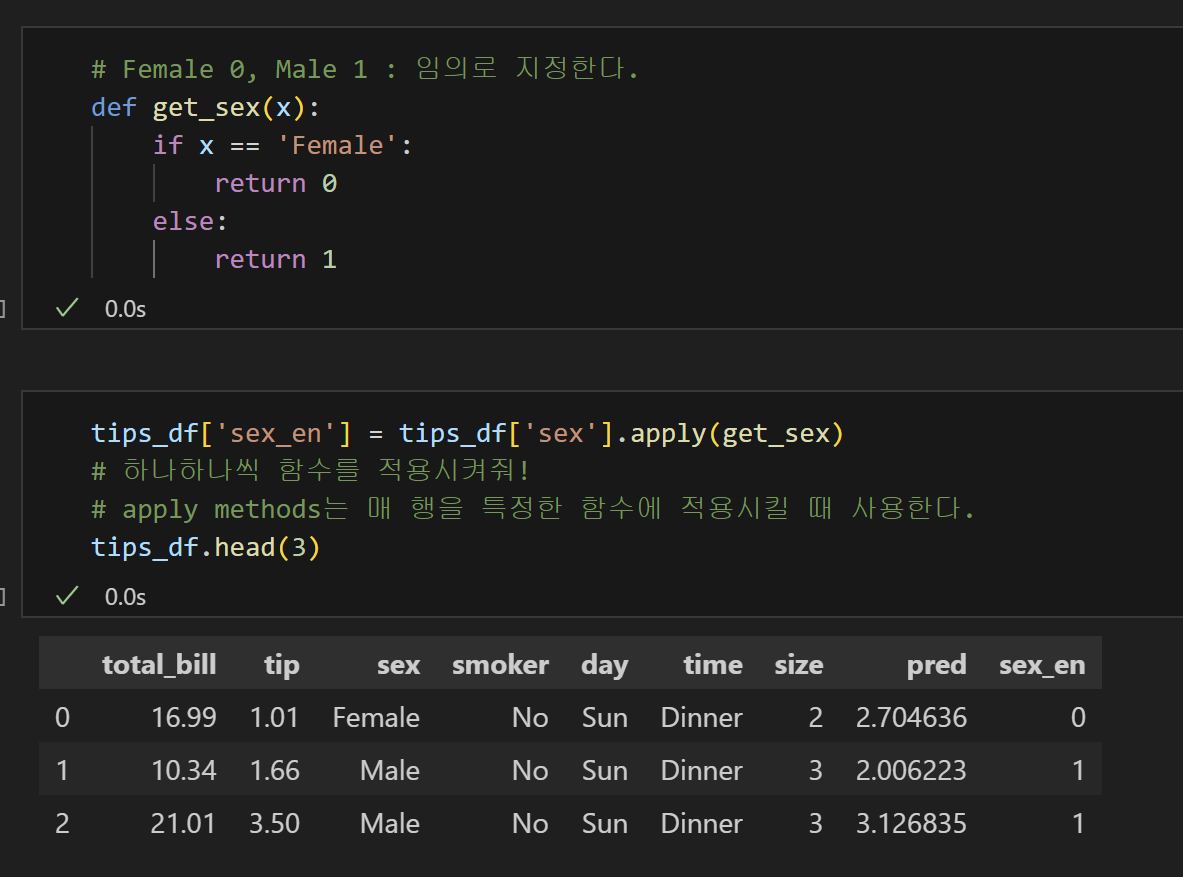
7) 모델 설계도 가져오기
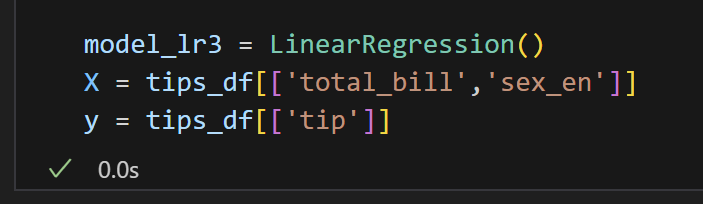
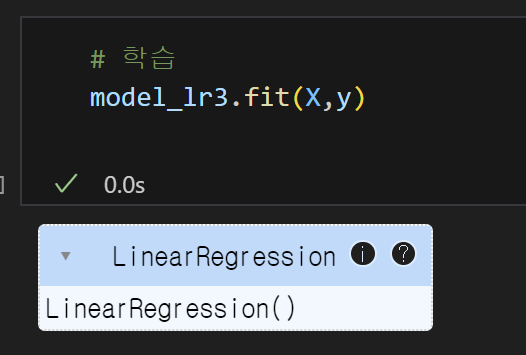
8) 데이터 집어넣고 학습시키기
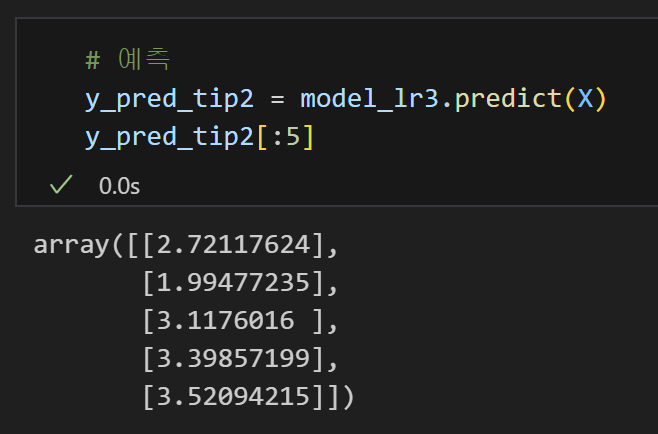
9) 예측 데이터 만들기
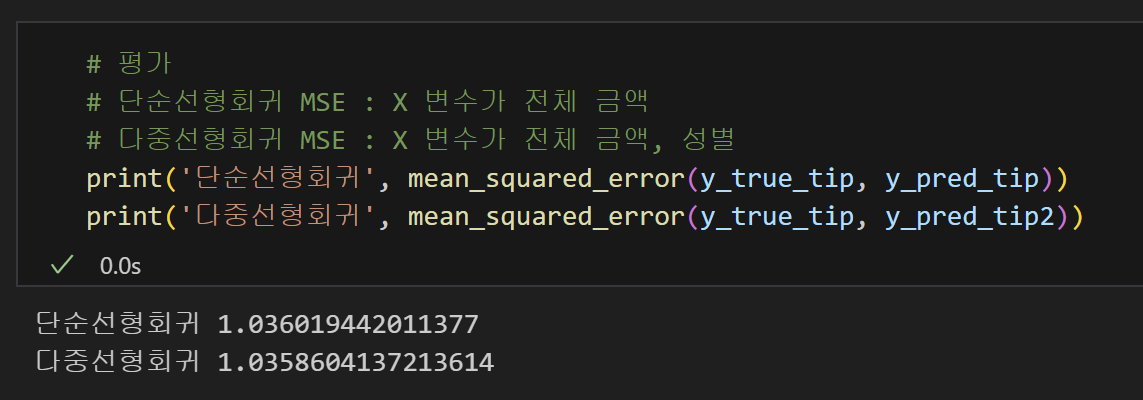
10) MSE 계산완료! 평가하기!
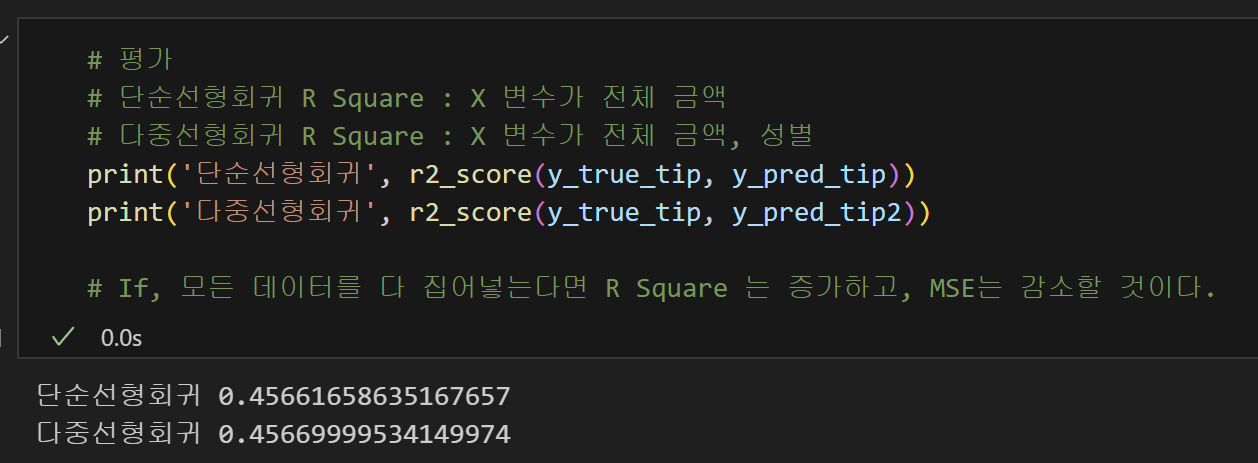
11) R Square 계산완료! 평가하기!
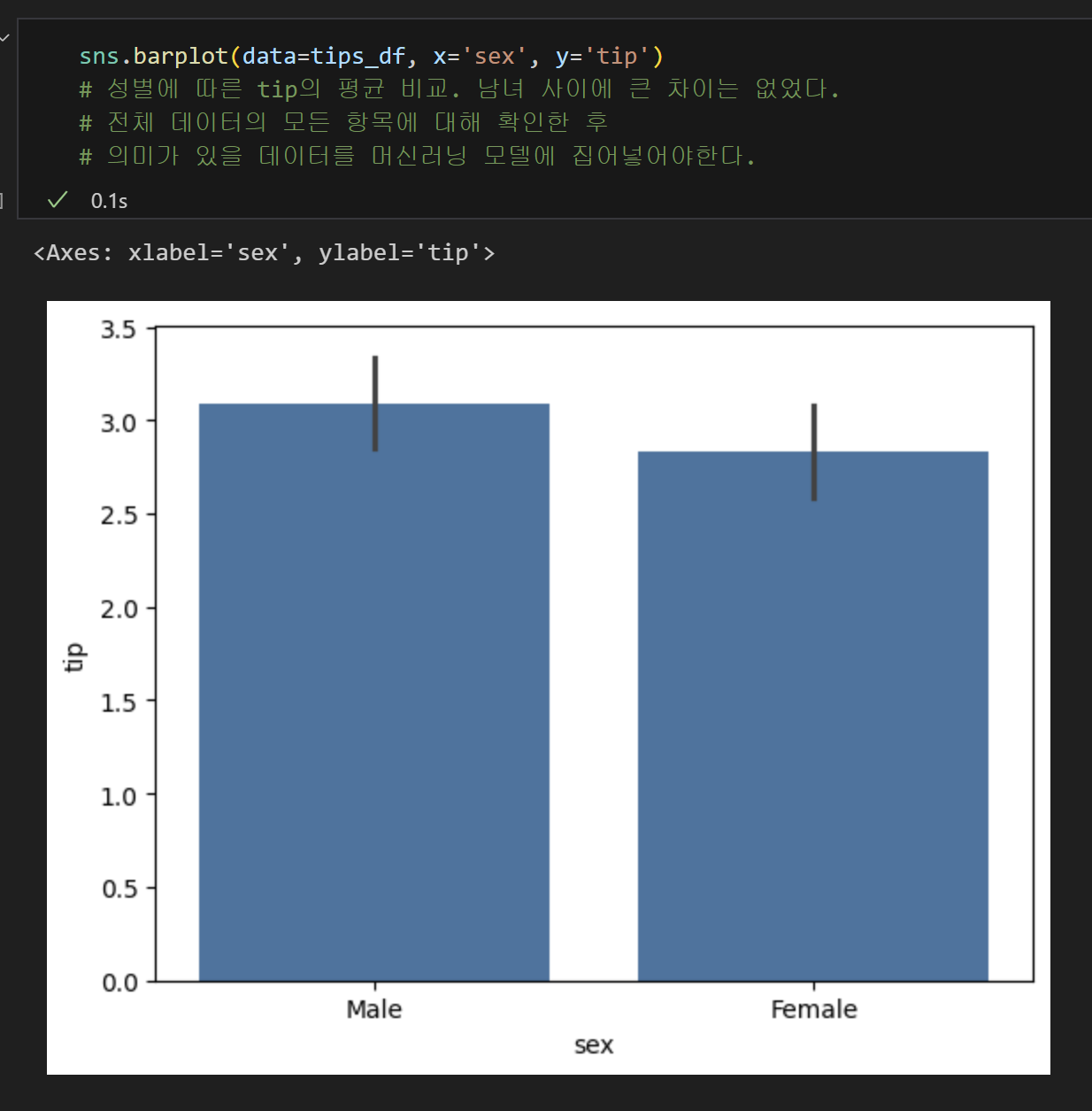
12) 분석하기
MSE와 R Square를 비교하였을 때, 큰 차이가 없었다.
즉, 성별은 tip에 영향을 크게 주지 않는다는 것이다.
전체 데이터의 모든 항목에 대해 비교한 후, 의미가 있을 데이터를 머신러닝 모델에 집어넣어야한다.

First time, Last time, Every time.