선형회귀 정리
선형회귀의 가정
- 머신러닝모델 중에 선형회귀는 이해하기 쉽고 방법도 쉬운 장점이 있지만, 말 그대로 X-Y변수간의 선형적 관계가 좋아야만 좋은 성능을 낸다. 선형회귀의 가정에 대해 알아보자.
1. 선형성(Linearity)
: 종속 변수(Y)와 독립 변수(X)간에 선형 관계가 존재해야 한다.
= Weight vs Height는 선형성이 있다.
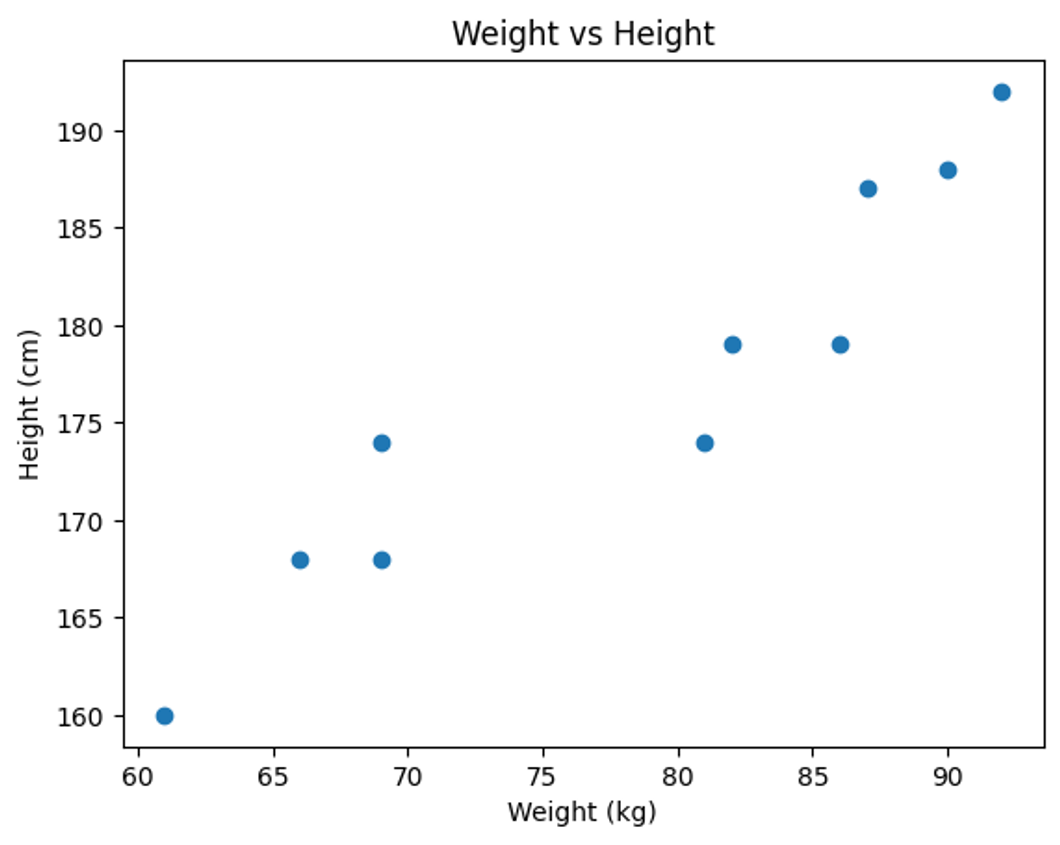
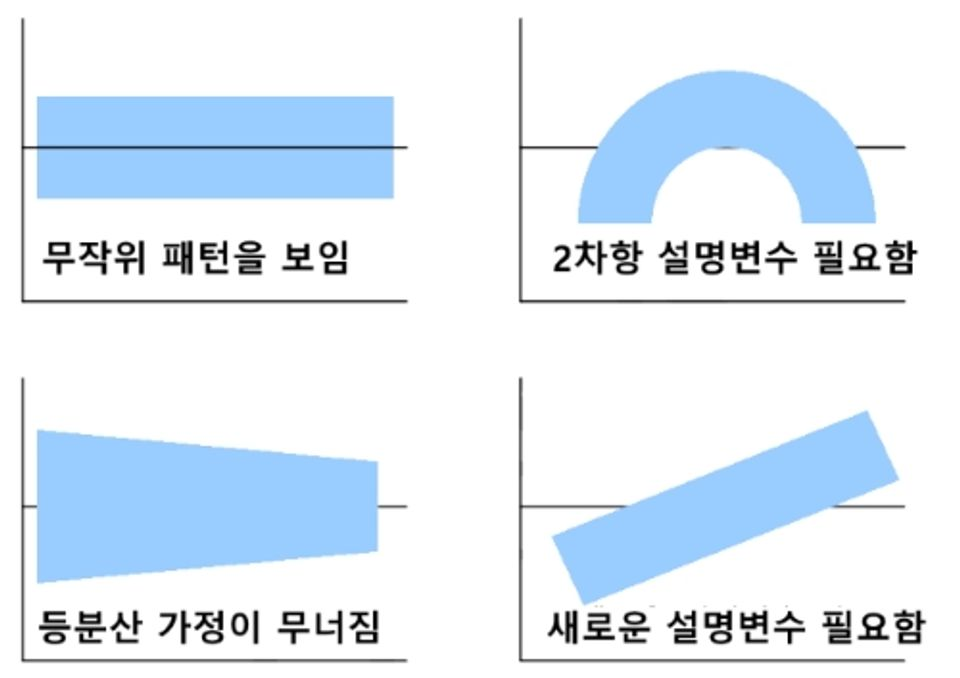
2. 등분산성(Homoscedasticity)
: 오차의 분산이 모든 수준의 독립 변수에 대해 일정해야 한다. 즉, 오차가 특정 패턴을 보여서는 안되며, 독립 변수의 값에 상관없이 일정해야한다.
* X축 : 독립변수, Y축 : 에러(오차)
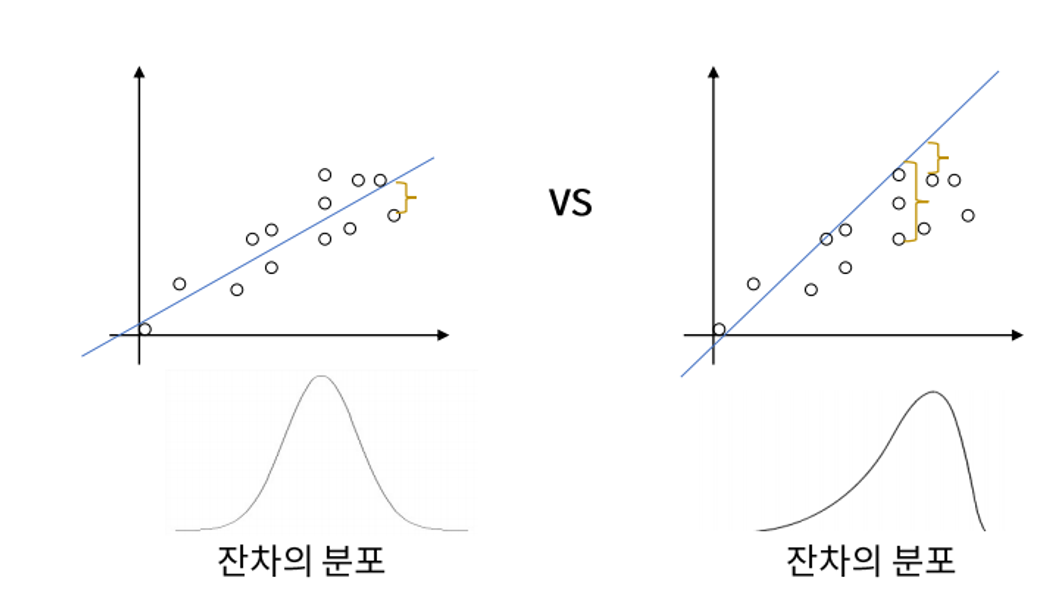
3. 정규성(Normality)
: 오차 항은 정규 분포를 따라야 한다.
= 선형 회귀를 기준으로 데이터들이 균일하게 좌우 대칭으로 분포해야한다.
4. 독립성(Independence)
: X변수는 서로 독립적이어야 한다.(=X변수가 여러 개일 때 서로 연관이 없어야 한다.)
1) 다중공선성 문제
① 변수가 많아지면 서로 연관이 있는 경우가 많다.
② 이처럼 회귀분석에서 독립변수(X)간의 강한 상관관계가 나타나는 것을 다중공선성(Multicolinearity)문제 라고 한다.
③ IF 위에서 예시를 들었던 Weight, Height 가지고 다른 Y(ex. 발 사이즈)를 예측한다면 Weight, Height가 서로 연관있는 변수이기 때문에 다중공선성 문제가 나타난다.
2) 다중공선성 해결방법
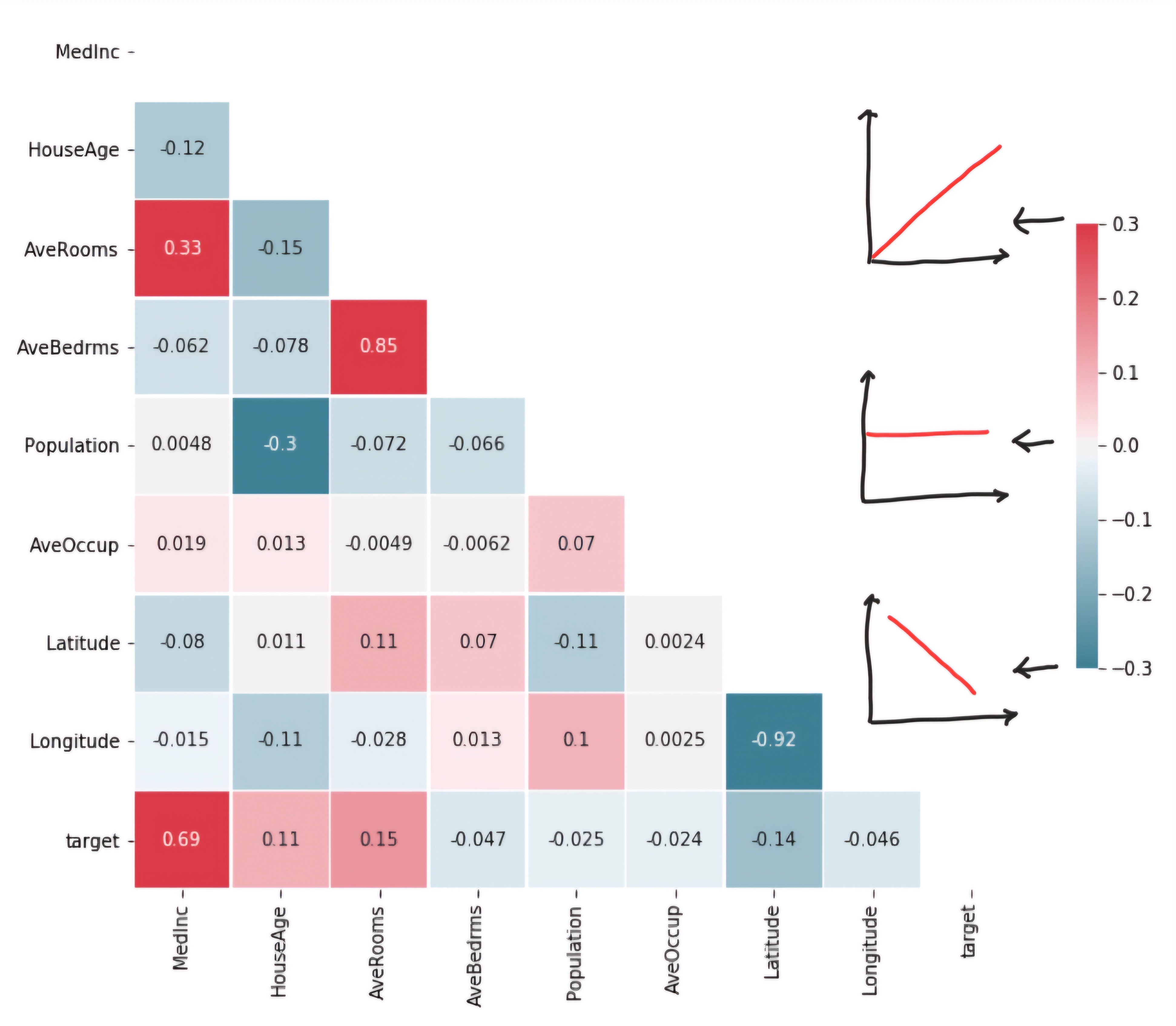
① 서로 상관관계가 높은 변수 중 하나만 선택(산점도 혹은 상관관계 행렬)
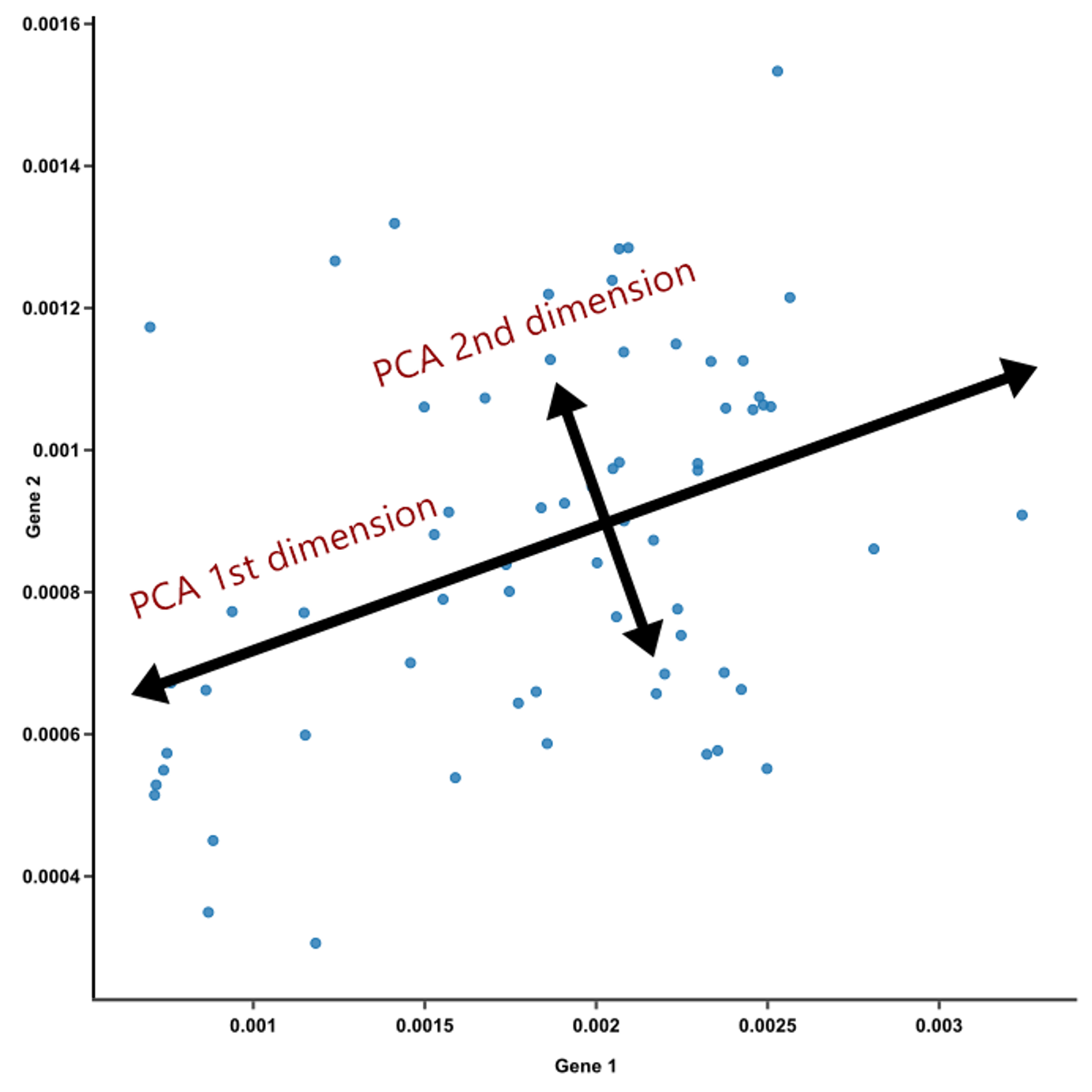
② 두 변수를 동시에 설명하는 차원축소(Principle Component Analysis, PCA) 실행하여 변수 1개로 축소
- pairplot 기능을 이용한 산점도 (= 같은 항목은 히스토그램, 다른 항목은 산점도/산점도가 선형회귀를 띄는 데이터로 모델을 만들면 된다.)
- heatmap을 이용한 상관관계 행렬
- 사실 pairplot과 heatmap은 같은걸 말하고자 한다. 그냥 둘 중에 편한거 사용해서 상관관계를 비교하면 된다.
- PCA(Principle Component Analisys)를 이용한 차원축소
- 주 성분(데이터의 공통점을 파악한 뒤 그걸 설명하는 하나의 축-PCA 1st dimension. ex.몸무게와 키를 설명하는건 체격이 될 수 있다.)을 만들고, 원래는 두개인 데이터를 축 하나로 설명하는 것이다.
- 즉, 변수 두개 쓸거를 하나로 합칠 수 있다.(=공통점만 뽑아서 특성으로 쓸거야!)
- 주 성분은 데이터를 100% 설명하진 않는다.
선형 회귀 정리
장점!
- 직관적이며 이해하기 쉽다.
- X-Y관계를 정량화 할 수 있다.
- 모델이 빠르게 학습된다.(가중치 계산이 빠르다.) → 행렬 계산
단점!
- X-Y간의 선형성 가정이 필요하다.
(if 선형성이 없다면, 선형성을 가지도록 데이터를 가공하거나, 선형성 있는 데이터를 가져오거나, 다른 모델을 선택해야한다.) - 평가지표가 평균(mean)을 포함하기에 이상치에 민감하다.
(이상치가 크면, 평균이 커지므로 이상치 처리가 필수다.) - 범주형 변수를 인코딩시 정보 손실이 일어난다.
(ex. 서울, 경기 → 0, 1 => 정보 특색이 없어짐)
Python 패키지
- `sklearn.linear_model.LinearRegression`데이터 프로세스 과정
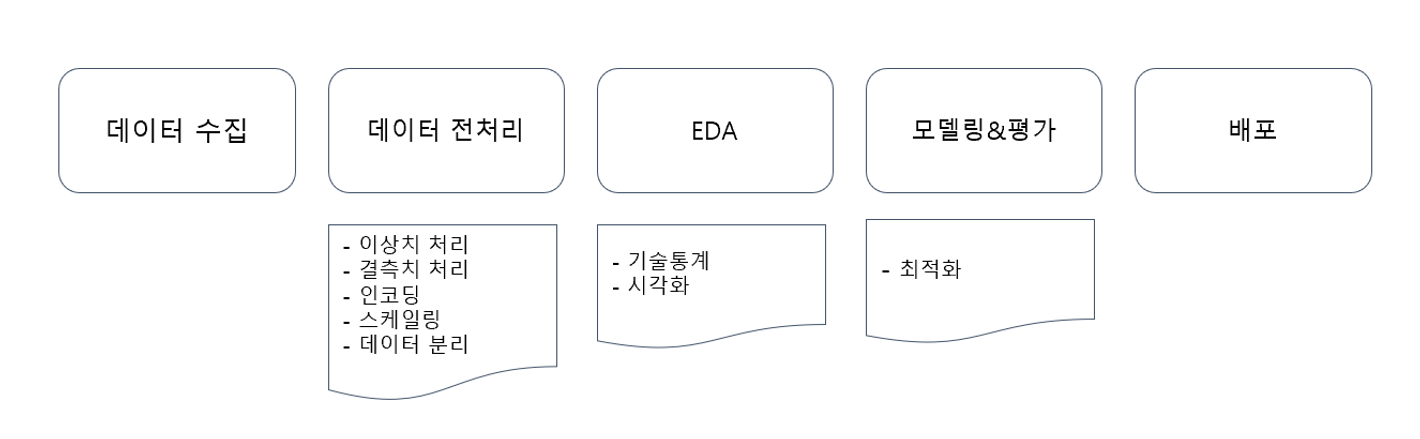
- 데이터 수집
- 데이터 전처리
1) 이상치 처리
2) 결측치 처리
3) 인코딩 (범주형 데이터 → 수치화)
4) 스케일링 (수치형 데이터의 단위를 맞춰주는 것)
5) 데이터 분리- EDA(탐색적 데이터 분석)
1) 기술통계
2) 시각화- 🌟모델링&평가🌟
: ex. 평가 - 회귀(MSE)
1) 최적화- 배포
여기까지가 선형회귀분석이었다!!!!!!

First time, Last time, Every time.