*간단하게 설명하면 이렇게 분류된다.
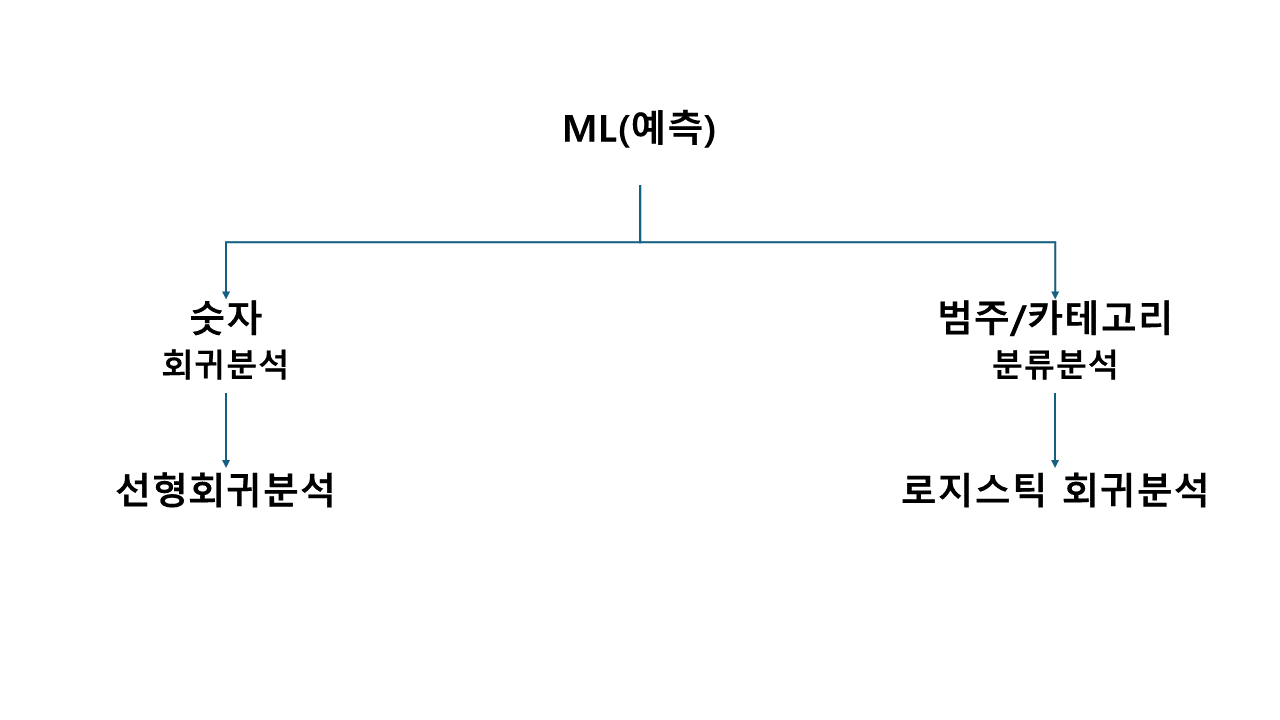
로지스틱회귀란?
: 범주형 데이터를 맞추는 분류 분석
1. 타이타닉 생존 분류 문제
- 머신이는 승객의 정보로 생존을 예측하는 문제를 보니 매우 재밌는 사실을 발견했다. 여성은 생존 확률이 높고 남성은 생존 확률이 낮다는 것이다. 이 부분만 적용해도 기본적인 예측은 할 수 있다.
여성은 모두 생존, 남성은 모두 사망으로 판별한다면?
가설 : 비상상황 특성 상 여성을 배려해서 많이 생존했을 것이다.
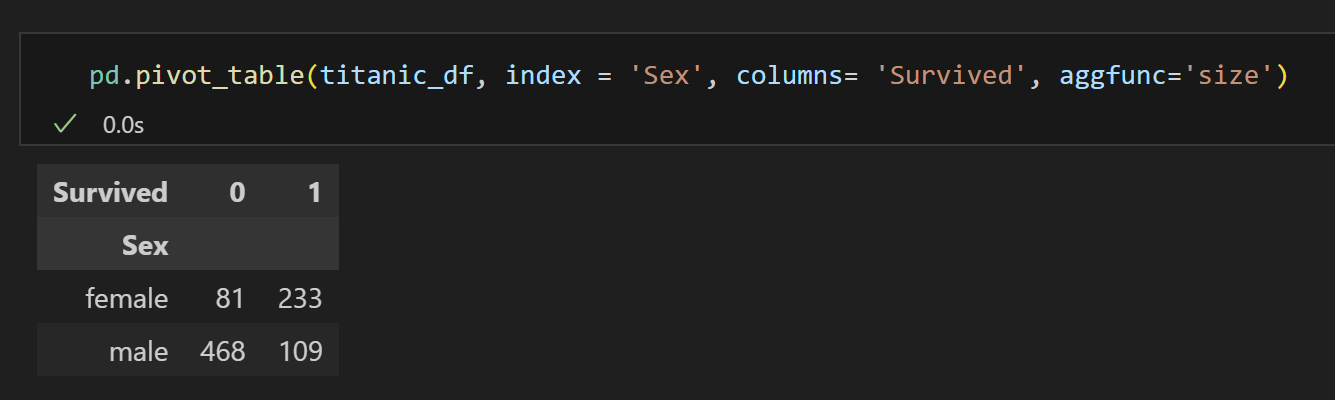
1) pivot table로 확인한다.
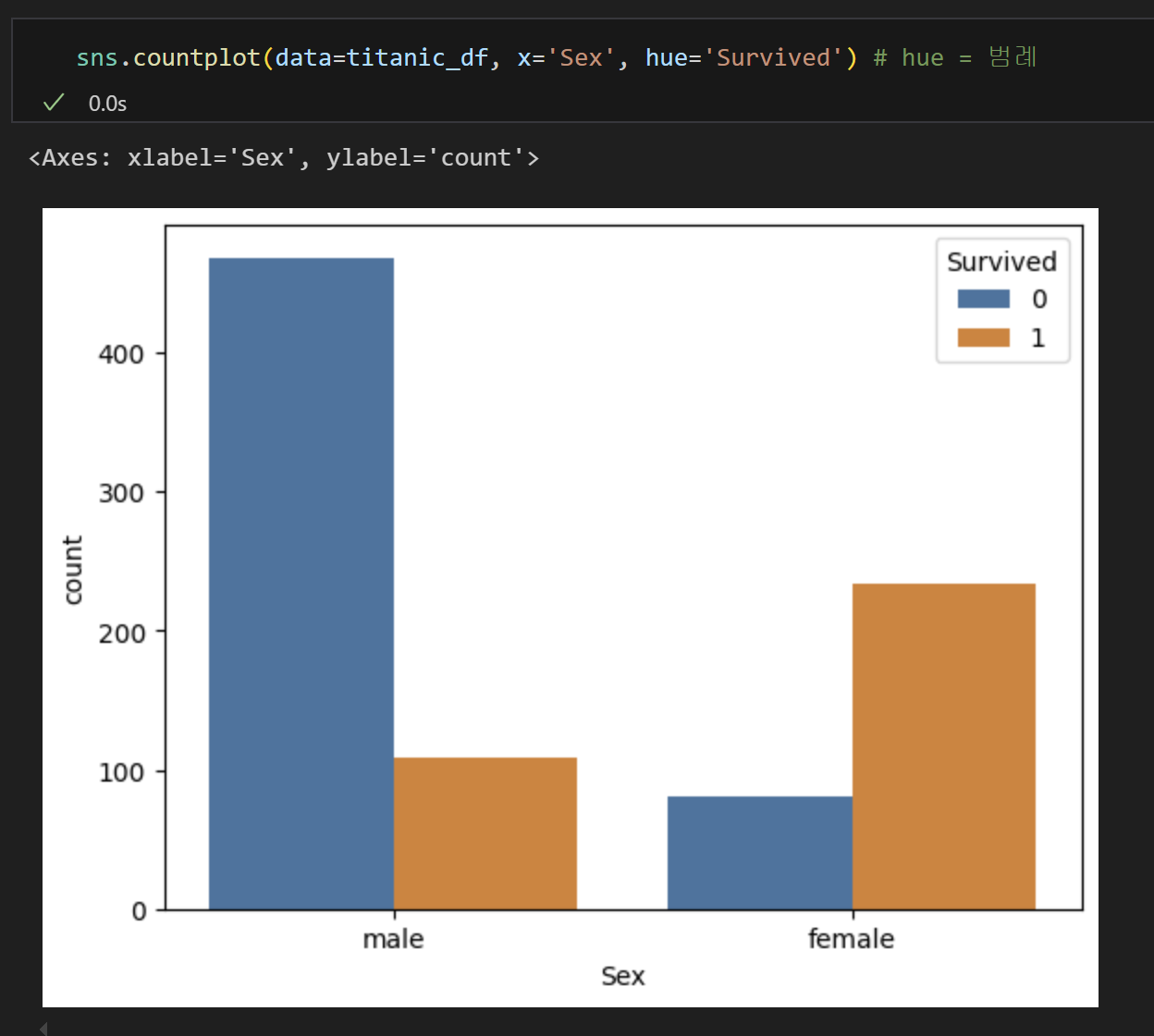
2) 그래프를 통해 확인한다.1) pivot table로 확인한다.
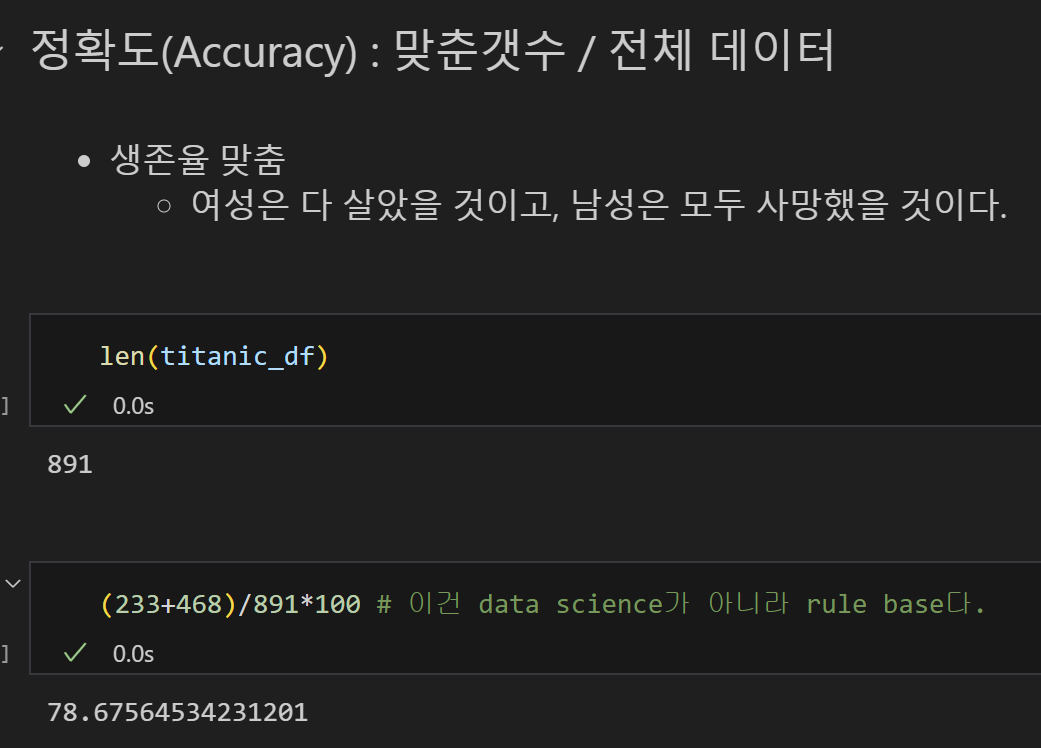
- 정확도 = 맞춘 갯수(여성 생존 수 + 남성 사망 수) / 전체 데이터
2) 그래프를 통해 확인한다.
✅ 모델을 만들지 않고도 78%의 정확도를 가진 인사이트를 도출했다. 하지만 이것은 Data Scientific하지 않다.

2. 로지스틱회귀 이론
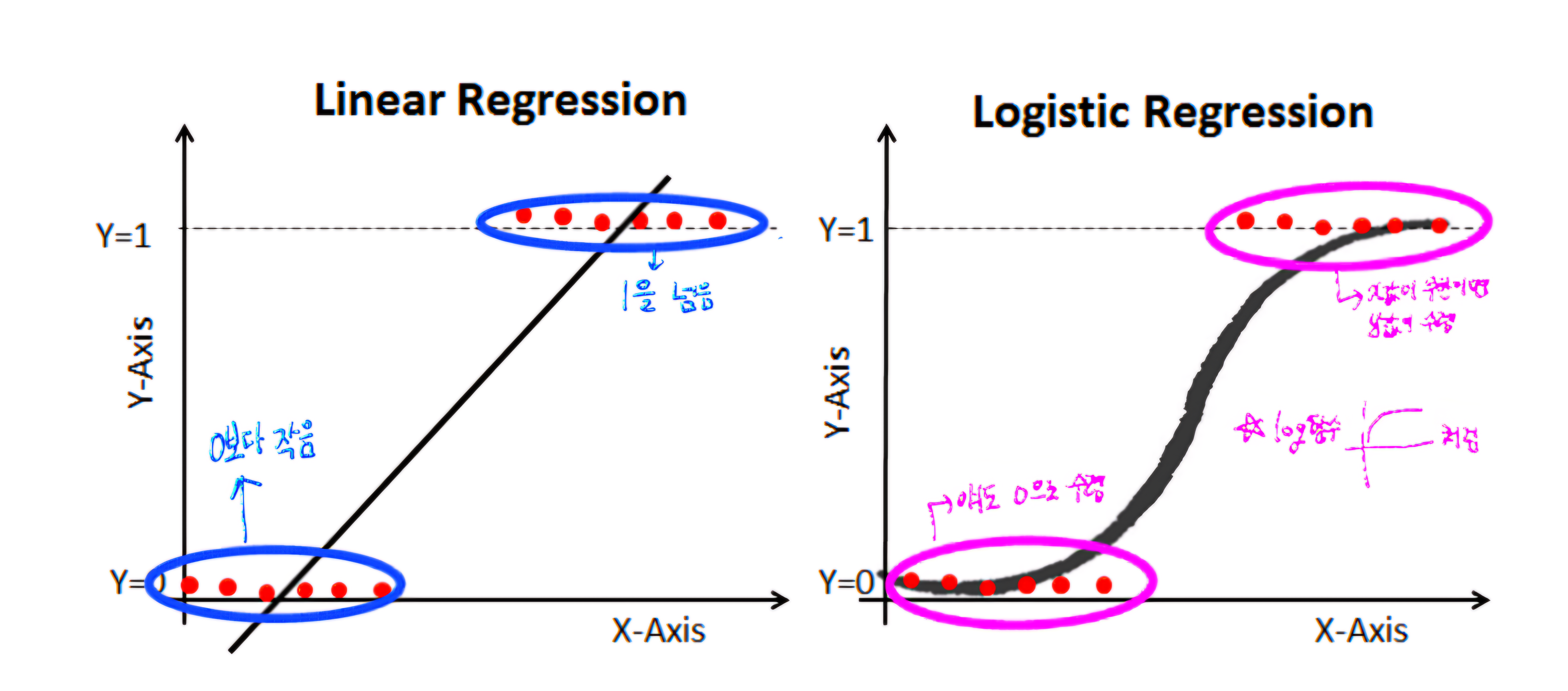
1) 범주형 Y에서 선형함수의 한계
- X가 연속형 변수이고, Y가 특정 값이 될 확률이라고 설정한다면, 왼쪽 그림과 같이 선형으로 설명하긴 쉽지 않아보인다. 확률은 0과 1사이 인데, 예측 값이 확률 범위를 넘어 갈 수 있는 문제가 있기 때문이다.
- ex. Y=1(생존)일 확률을 맞추는 것. P(Y=1), 0≤P≤1
2) 로짓의 개념 두두등장!
- 위 S형태의 함수를 만들기 위해 오즈비(Odds ratio)의 개념을 적용해보겠어!
여기서 잠깐❗
- 오즈비(Odds ratio)란? 실패확률 대비 성공확률로, 도박사들이 자주 쓰는 개념이다.
- ex) 도박이 성공할 확률이 80%라면, 오즈비는 80%/20% = 4다.
- 즉, 1번 실패하면 4번은 딴다는 것이다.

BUT❗오즈비는 바로 쓸 수 없다!!
- P는 확률 값으로, 0과 1사이 값인데, P가 증가할 수록 오즈비가 급격하게 증가하기 때문에 너무 확률이 급격하게 증가하고 선형성을 따르지 않게 된다. 따라서 로그를 씌워 이 부분을 좀 완화해야 한다!!
log(로그)의 역할 : Tranquila~ - ex 1) p=0, 0/1-0 = 0
- ex 2) p=0.9, 0.9/1-0.9 = 9
- ex 3) p=1, 1/1-1 = 1/0 = +∞(발산)
✅ 이렇게!
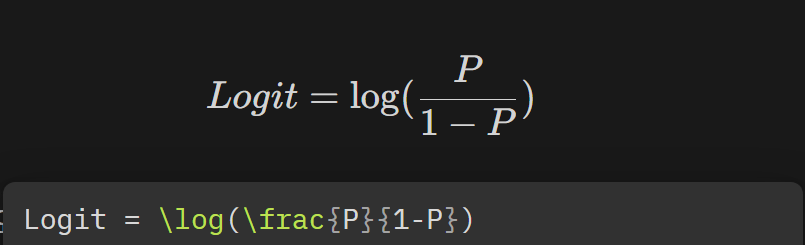
3) 오즈비와 확률의 관계 / 로짓과 확률의 관계
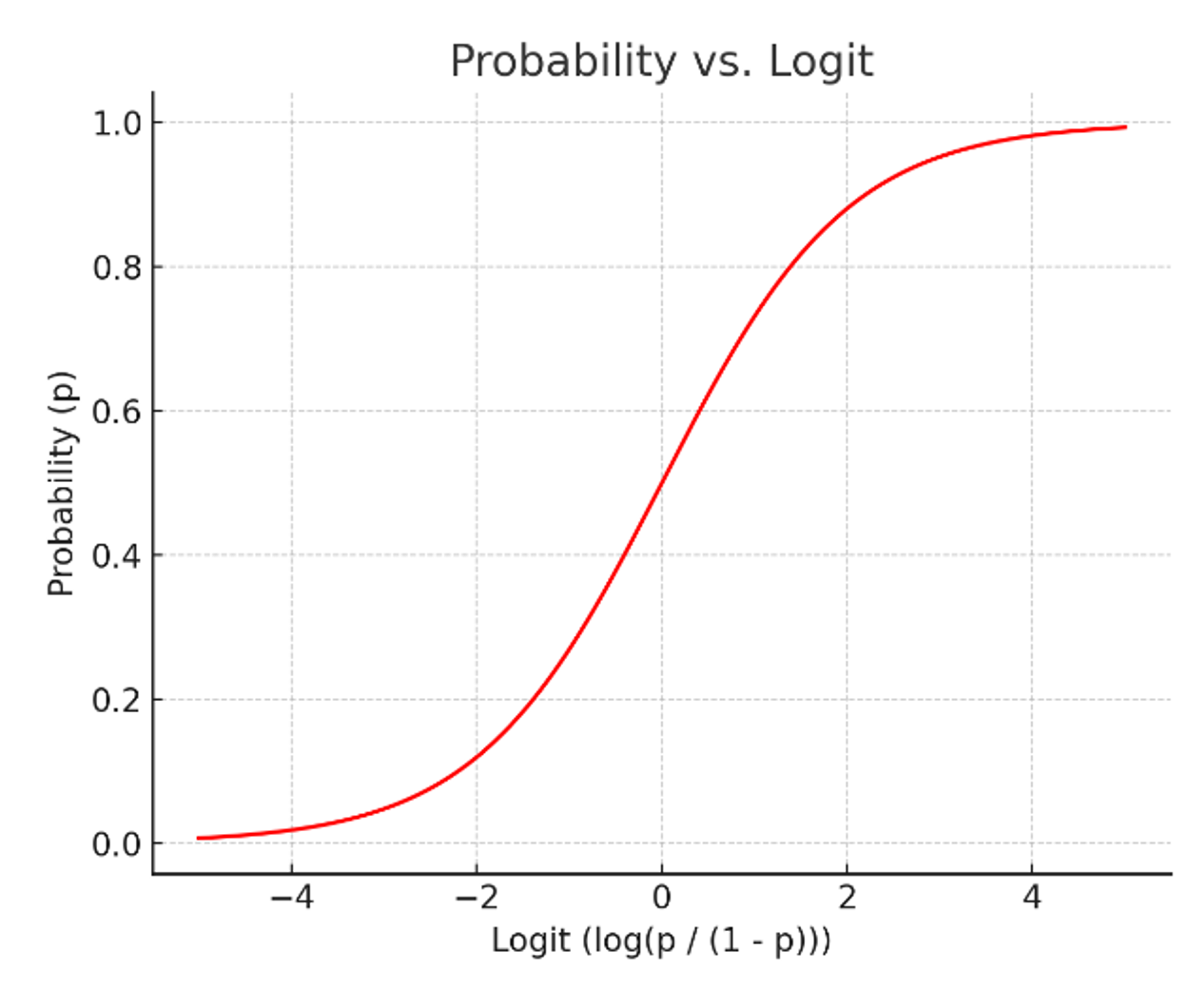
① 로짓의 그래프가 더 선형적인 그림을 나타내어 선형회귀의 기본식을 활용할 수 있게 됨
② 이게바로 로지스틱'회귀'라고 불리는 이유이다.
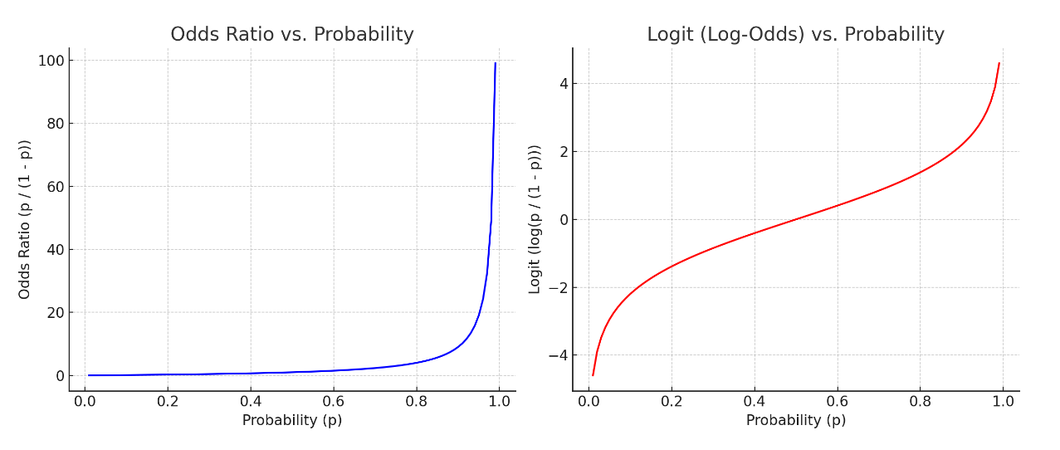
- 확률이 증가할수록 (좌)오즈비는 급격히 발산, (우)로짓은 완만하게 증가
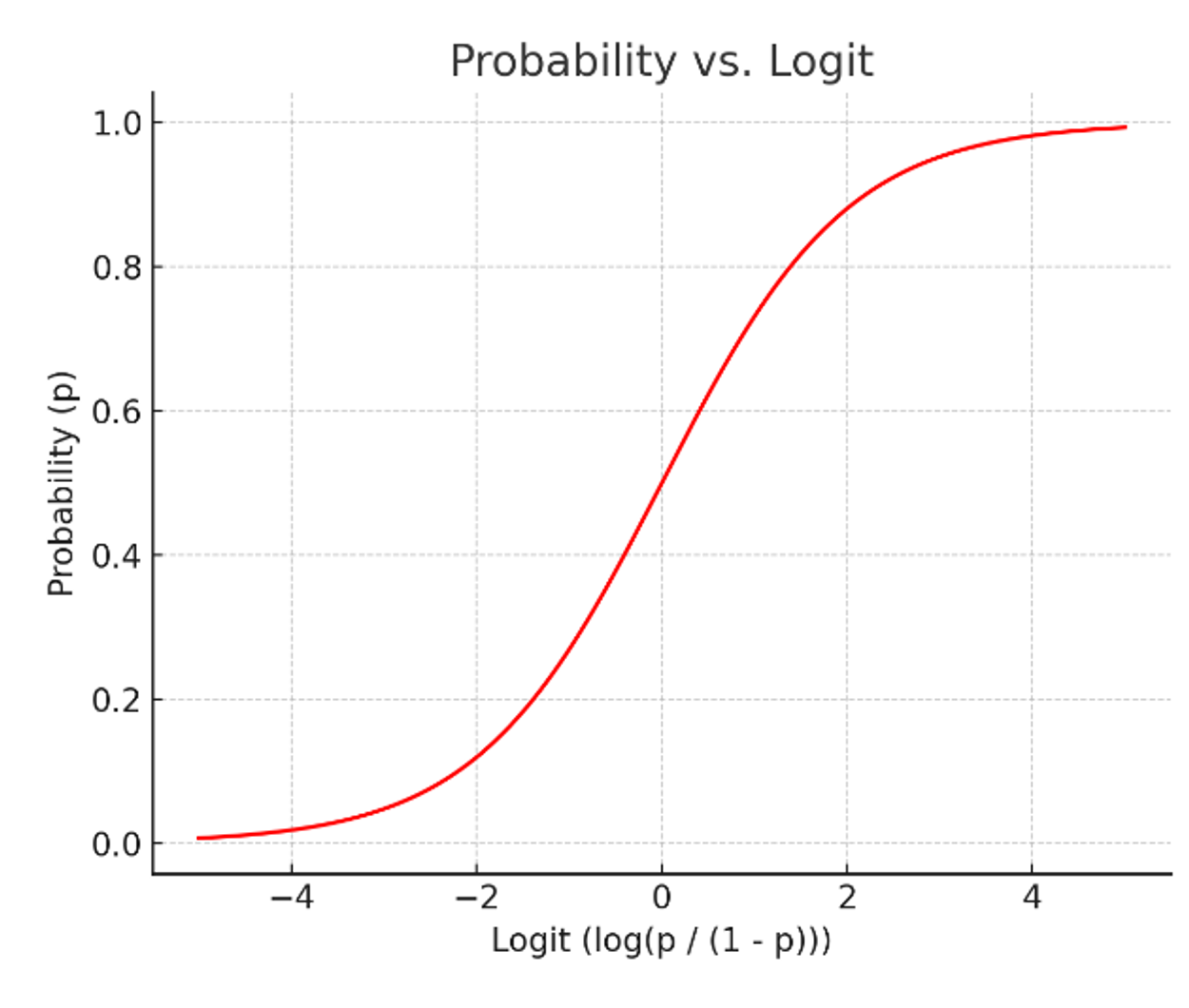
- 위 그래프의 확률-로짓 그래프 X-Y축을 교체!
✅ 이게 바로, 로지스틱 함수
✅ 로지스틱 함수는 시그모이드 함수 중 하나로 딥러닝에서도 활용된다.
✅ 값을 계산하면 확률이 도출된다!!
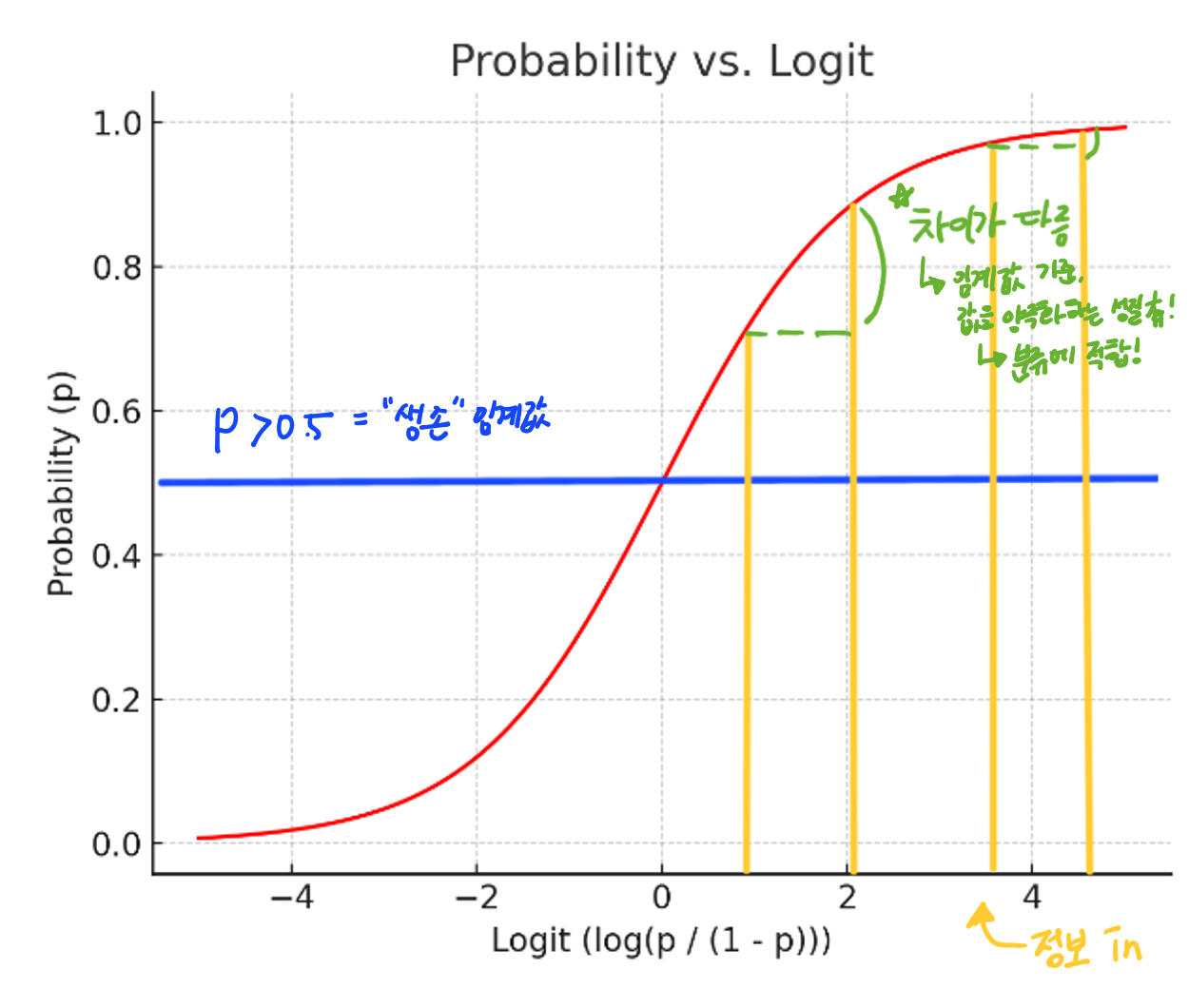
✅ 기준이 되는 임계값은 정해줘야 한다.- ex 1) 생존확률 P = 0.9 이 생존을 의미하려면, P>0.5, 생존 이라는 임계값을 정해줘야한다.
✅ 임계값을 기준으로, X값 대비 Y값의 차이가 크다. = 양극화
= 분류에 적합하다.
- 이 식을 P에 대해서 다시 정리하면, (이항하면,)
- 이렇게 된다!!
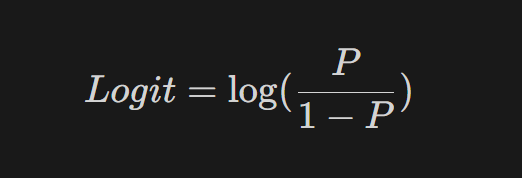
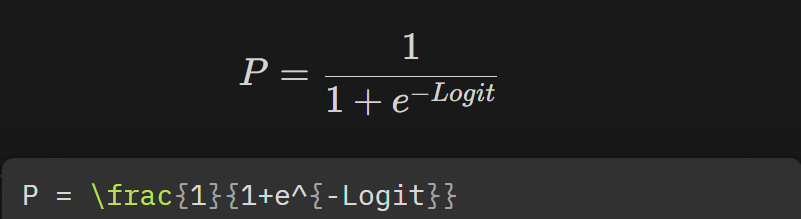
③ 로짓의 장점은 어떤 값을 가져오더라도 반드시 특정 사건이 일어날 확률(Y값이 특정 값일 확률, ex.Y=1(생존))이 0과 1안에 들어오게 하는 특징을 가진다.
✅ 즉, Y의 값을 예측하는 것이 아니라, Y=1일 확률을 예측하는 것이다.
✅ 그 다음에, 임계값을 기준으로 컷오프를 통해 Y가 n이면 생존, 사망을 예측하는 것이다.
- 로짓과 기존 선형회귀의 우변을 합쳐 다음과 같은 식을 도출한다.
- 양변에 자연지수 를 취하면 (이항 하면)
- 💡해석 : X값이 만큼 증가하면 오즈비는 만큼 증가한다.
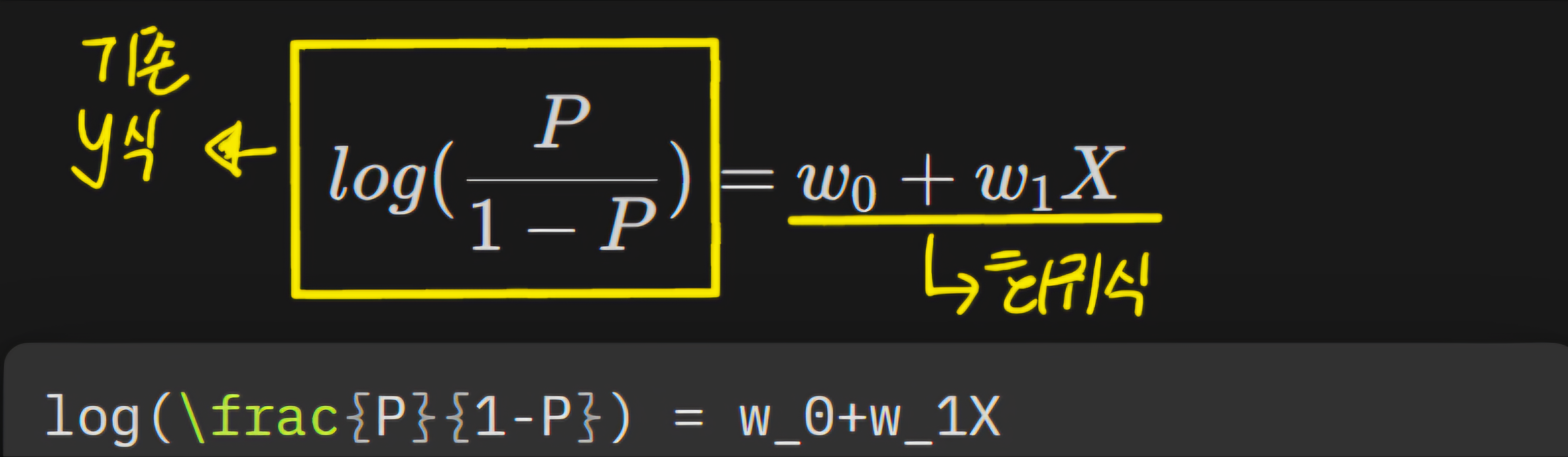
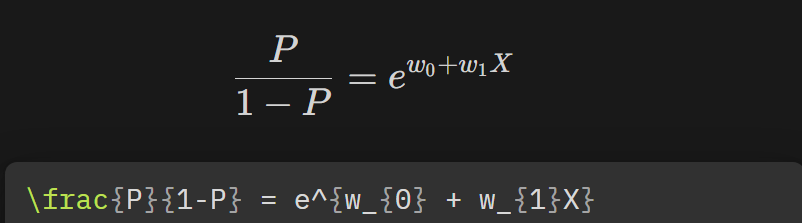
4) 정리
- 로지스틱 함수는 가중치 값을 안다면 X값이 주어졌을 때 해당 사건이 일어날 수 있는 P의 확률을 계산할 수 있게 된다.
- 이때, 확률 0.5를 기준으로 그보다 높으면 사건이 일어남(P(Y)=1), 그렇지 않으면 사건이 일어나지 않음(P(Y)=0)으로 판단하여 분류 예측에 사용한다.
- X가 연속형변수, 성별(0,1)
- y가 이진분류(0,1), 다중분류를 이용한 다른 함수(Softmax)(=A,B,C가 일어날 확률을 각각 클래스에 대해 분류하고 모든 클래스의 확률을 합이 1)

First time, Last time, Every time.