openAI에서 만든 vision-nlp multi-modal이다. multi-modal쪽은 처음이라 정확하지 않고 명확하지 않을 수 있음.
잘 모르는건 bold처리 해 두자. (언젠가는 사라지기를)
Abstract
기존에 알던 predetemined 된 object category들로 예측하는 모델들은 다른 task를 수행하기 위해서는 추가적인 라벨링된 데이터가 필요하다.
이미지를 text로부터 학습하는 것이 vision task에 있어 broad하게 학습시킬 수 있다.
따라서 1. 어떤 caption이 어떤 이미지에게 붙느냐를 학습시키는 간단한 pre-training 단계를 거친다. 2. 이후 자연어를 이용하여 앞서 학습한 visual concept으로 zero-shot transfer를 할 수 있게끔 한다.
1. Introduction
'text-to-text'를 input-output의 구조로 삼는 발전이 기존의 task-agnostic 구조에서 zero-shot transfer로 더 generalized된 모델을 만들 수 있게 되었다.
실제로 결과도 좋아서 nlp말고 CV에서도 ImageNet같은 대규모 데이터셋으로 pre-train시킨 모델말고, text로 학습시켜서 해봐도 좋을것 같다라는 출발점을 제시한다.
예전에 있던 비슷한 연구로는, CNN으로 image caption에 들어갈 단어를 예측하도록 학습시켜 봤더니 쓸만한 image representation을 얻었었다는 연구. AlexNet을 학습시켰더니 결과가 좋았고, 더 나아가 단어 하나보고 다음 단어를 예측하는 phrase n-gram에 대입해 보고, 이걸 zero-shot transfer로 다른 데이터셋의 이미지를 분류하는 task에 적용하는 연구도 있다. 이후 최신 구조인 transformer구조, masked language modeling, contrastive objectives를 활용한 시도도 있었다.
2. Approach
2.1 Natural language supervision
자연어를 쓰는게 왜 좋냐
이전에 있었던 text로부터 visual representation을 학습하는데, unsupervised, self-supervised, weakly supervised, supervised 방식으로 한 연구들에서 공통적으로 자연어를 학습 signal로 받아들였다는 점이다. 즉, natuaral language supervision을 배웠다는 점이다.
자연어 사용의 장점
1. 기존 방식같은 라벨링이 필요 없다.
2. 언어의 형식으로 학습하기 때문에, flexible zero-shot transfer가 가능하다.
2.2 Creating a sufficiently Large Dataset
natural language supervision을 사용하는 가장 큰 이유는 인터넷에 오픈된 방대한 데이터를 갖다가 쓸 수 있다는 점이다.
하지만, 기존에 사용하던 데이터셋의 몇몇 단점들 때문에, 400 million text-image pair의 새로운 데이터셋을 만들었다.
-> 500,000 queries에 한 query당 평균 20,000개 pair를 가지도록 구성했다. (이는 gpt-2를 학습할때 썼던 양과 비슷하다고 한다.)
2.3 Selecting an Efficient Pre-Training Method
기존 모델들은 무겁고, 간편하게 scaling하기 어려웠다. 이는 모델이 정확히 정답 단어를 맞추려고 해서 였는데, 여기서 contrastive representation learning을 활용한다. 실제로도 직접적으로 답을 예측하는 방식보다 잘 학습했다. 다른 접근으로는 생성모델을 활용하는 건데, 학습하는 image representation quality는 매우 좋지만, 연산량이 너무너무 많다는 단점이 있다.
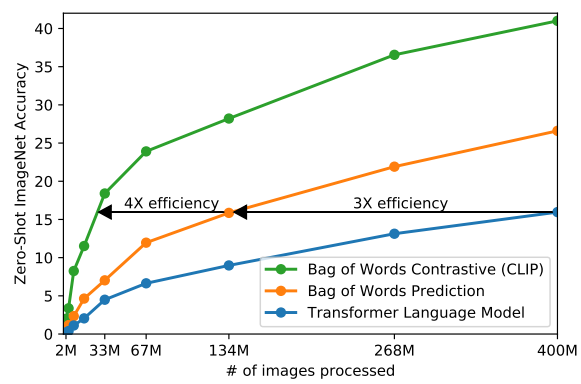
종합해서 이미지와 단어 하나를 pair하는게 아니라 텍스트 전체를 예측하게끔 해서, bag-of-words encoding baseline으로 출발하여 3배의 효율, 예측(predictive)이었던 목표를 비교하는(contrastive) 목표로 하여 4배의 추가 효율을 달성했다. (위 그래프 참조)
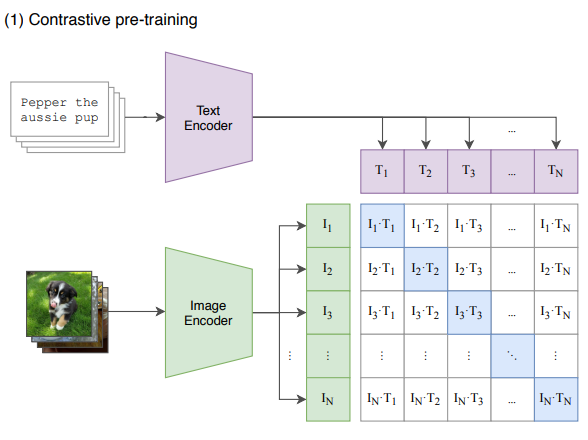
학습 방식은 N개의 (image,text) pair로 이루어진 batch가 있다고 하자. CLIP은 batch내에서 조합할 수 있는 NxN 개의 가능한 pair에 대해 점수를 매긴다.
그러면 그림에서 파란색으로 칠해진 N개가 정답이니까 image embedding과 text embedding이 max cosine similarity를 가지도록, 나머지 N^2-N개에 대해서는 min cosine similarity를 가지도록 image encoder과 text encoder를 동시에 학습시킨다.
아래 코드로 symmetric cross entropy를 이용해 similarity score loss를 계산했다. 코드를 보면 가로, 세로 따로 계산해서 평균내는 식이다.
 이런식으로 batch를 구성하여 contrastive representation learning을 하는 방식은 **ConVIRT** 논문(자주 등장하는 Zhang et al.(2020))에서 등장한 바 있다.
이런식으로 batch를 구성하여 contrastive representation learning을 하는 방식은 **ConVIRT** 논문(자주 등장하는 Zhang et al.(2020))에서 등장한 바 있다.
학습 특이사항으로는
- 두 encoder를 학습시킬때 ImageNet같은 데이터로 학습시킨 pre-trained weight을 가져다 쓰지 않고 scratch 상태에서 부터 학습시켰다.
- 두 encoder에서 multi-modal embedding space로 갈때 non-linear projection을 사용하지 않고 오직 linear projection만 사용하였다.
- ConVIRT에서 제시한 방식에서 text transform function t_u를 제거하였다. (사용하는 dataset의 text가 대부분 한 문장이기 때문)
- ConVIRT의 image transform function t_v를 단순화 하였다; image augmentation으로 resize, random square crop만 적용했다.
- temperature parameter T를 학습중에 최적화 되도록 해서softmax의 logit을 조절하는 변수가 하이퍼파라미터처럼 튜닝되지 않도록 했다.
2.4 Choosing and Scaling a Model
먼저 Image Encoder: 2 종류를 활용 했다.
1. ResNet-50
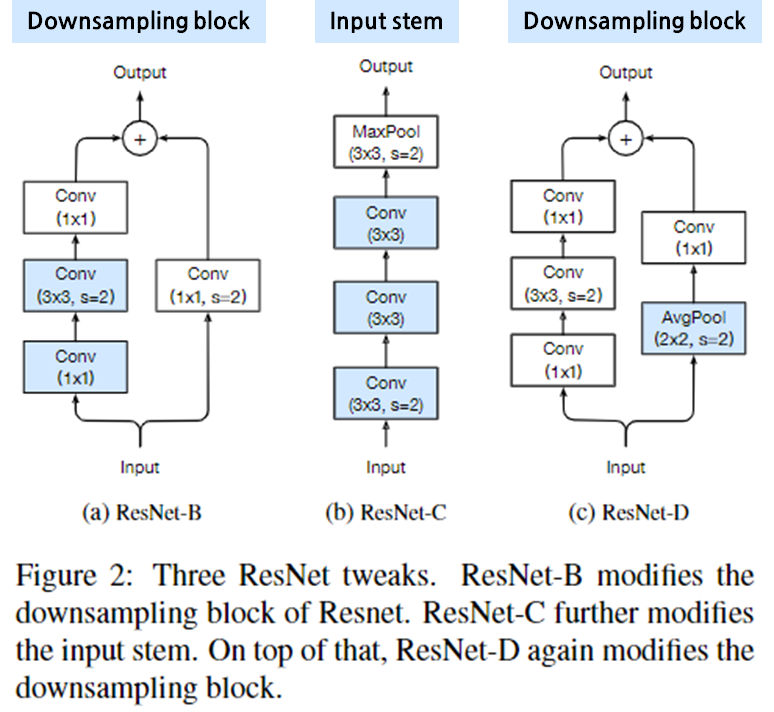
그냥 Resnet-50에서 변형을 준 ResNet-D 구조에서, antialiased rect-2 blur pooling 적용, global average pooling layer를 attention pooling 방식으로 바꿨다.
여기서 attention pooling은 transformer처럼 multi-head QKV를 계산하고, query가 global average-pooled representation에 따라 조절되는걸 말한다.
- ViT
대부분 원래 형태를 따랐고, combined patch에 추가적인 layer normalization을 붙이고 transformer에 넣기전 position embedding을 추가했다. 약간 다른 initialization scheme를 사용했다고 한다.
다음은 Text Encoder: 역시 Transformer를 사용했다.
1. Transformer
기본 모델 사이즈로 63M parameter, 12-layer, 512-wide model with 8 attention heads를 사용했다.
Text는 lower-cased byte pair encoding (BPE)를 적용했다.
연산 효율을 위해 최대 sequence 길이를 76으로 제한하고, [SOS]토큰과 [EOS]토큰으로 감쌌다. 이때 transformer의 제일 끝 layer에서 [EOS]토큰은 layer normalized된 feature representation으로 취급되고, multi-modal embedding space로 넘길 때 linearly projected 되었다.
Masked self-attention을 적용했다.
pre-trained model을 적용하거나 언어에 따른 모델링은 future work으로 남겨두었다.
Image Encoder는 width, depth, resolution을 늘리는 방식으로 모델을 scaling 했는데, 세가지를 모두 비율로 조절하는 EfficientNet 연구 결과에 따라 좀 더 간단하게 세가지 모두 동일한 양의 추가 연산을 넣어주었다.
Text Encoder는 ResNet을 scaling 한 만큼만 비율에 맞춰서 width만 조절해 주었다. - Text Encoder의 capacity에 덜 민감하다는걸 발견했기 때문이다.
2.5 Training
학습할때 사용한 모델구조나 epoch수 등을 써두었다. 일단 패스
3. Experiments
3.1 Zero-shot Transfer
-추후 추가 예정
논문 원본 링크: https://arxiv.org/abs/2103.00020
