BEIT v3, v1을 읽고 읽었지만, 3개 중 가장 어려운 논문인거 같다.
v1 리뷰 / v3 리뷰
Knowledge Distillation이라는 처음보는 개념도 등장하는데,
일단 이 논문부터 하나씩 봐보자
Abstract
앞선 BEIT v1 논문에서 vision transformer를 학습시킬 때 사용했던 Masked Image Modeling(MIM) 을 이번에도 사용할 건데, v1보다 좀더 high-level semantic을 잘 학습하도록 업그레이드 한 visual tokenizer를 제시한다.
Vector-quantized knowledge distillation 을 활용할 것이다.
patch aggregation strategy 로 discrete한 image patch들로부터 global semantic representation을 잘 보도록 곁들인다.
1. Introduction
기본은 BEIT v1과 같이 MIM 방식으로 학습 시키고, image patch 와 visual token 두가지를 학습 재료로 쓸 것이다.
복습: 원본 이미지를 자르고, 토큰화 하여 visual tokens를 만들고 토큰들 중 일부를 mask로 가려 image patches로부터 가린 visual token을 맞추는 방식으로 학습한다.
MIM 학습 방식은 크게 복원 대상을 기준으로 3가지로 나눌 수 있는데, 1. 픽셀값 자체(low-level image elements), 2. hand-crafted features, 3. visual tokens(-BEIT).
하지만 이 세가지 모두 직/간접적으로 픽셀값을 맞추는 거랑 크게 다르지 않다. 하지만 NLP 학습을 보면 high-level semantic으로 학습을 하고 있기 때문에, 거기에서 발전 가능성을 보고 출발 했다.
이 논문에서 Semantic-aware visual tokenizer를 학습 시킬 것이다.
Vector-quantized Knowledge Distillation(VQ-KD) 알고리즘으로 semantic space를 표현한다.
1. VQ-KD encoder가 이미지를 learnable codebook에 따라 discrete token으로 변환 한다.
2. Decoder는 이 discrete token을 가지고 teacher model이 encode한 semantic feature를 복원하는걸 학습한다.
3. VQ-KD가 학습이 끝나면, encoder는 BEIT v1 구조에서 semantic visual tokenizer로 쓴다.
token들이 discrete한 상태이기 때문에 [CLS] token이 global한 image representation을 학습하도록 patch aggregation strategy를 적용한다.
2. Methodology
리마인드 차원에서
BEIT v1의 image patch - visual token 구조
v2에서는 visual token을 만드는데 vector-quantized knowledge distillation 알고리즘을 활용할 예정
patch aggregation strategy 곁들인다.
2.1 Image Representation
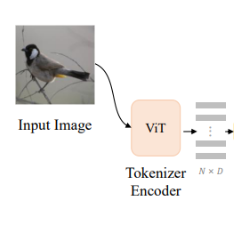
원본 이미지의 representation을 얻기 위해 Backbone network로 ViT를 쓴다.
원본 이미지를 쪼개 얻은 image patch를 ,
ViT의 output; encoding vector를 로 쓴다.
N은 patch 총 갯수에 해당한다.
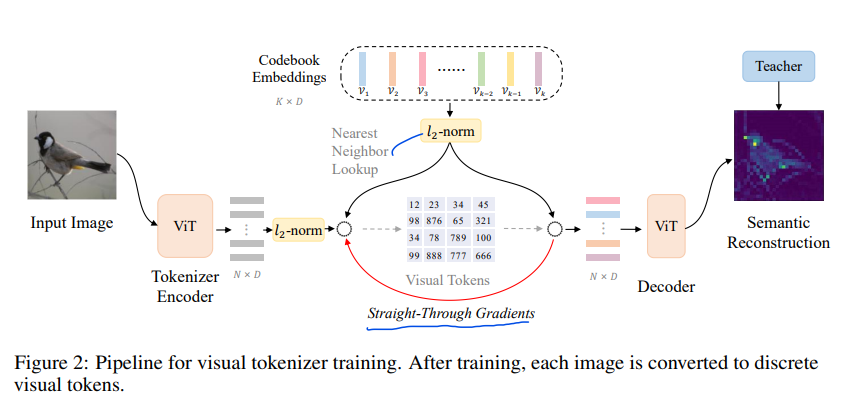
2.2 Training Visual Tokenizer
VQ-KD를 활용할 예정이고, visual tokenizer, decoder로 이루어진 구조이다.
Visual tokenizer 가 이미지를 visual tokens; discrete codes 으로 매핑한다.
즉, 이미지 를 토큰 으로 토큰화 한다.
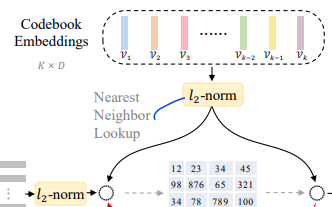
이때, 가 codebook의 code 하나에 해당해서 ;
K discrete codebook embedding을 가진다.
이 Tokenizer는 vision transformer encoder와 quantizer로 이루어져 있다. Tokenizer가 먼저 이미지를 vector(로 만들고,
quantizer가 codebook에서 nearest neighbor을 찾아 codebook embedding()을 매칭해 준다.
Nearest neighbor를 norm으로 찾는 과정을 수식으로 보면
- Cosine similarity를 찾는 과정과 동일하다.
Visual Tokens를 만들면, decoder에 -normalized codebook embedding 을 넣어 준다.
decoder도 multi-layer transformer구조로 이루어져 있다. decoder의 output vectors 로 teacher model(DINO, CLIP)의 semantic feature를 학습한다.
즉, teacher model의 feature vector 와 decoder의 output 사이의 cosine similarity가 커지도록 학습한다.
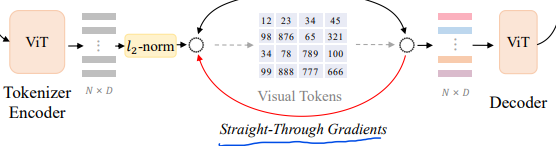
Quantization process는 미분이 불가능하기 때문에 encoder output을 학습시키기 애매해서, decoder input단의 gradient를 그대로 encoder의 output에 복붙한다.
전체적인 학습 식은 다음과 같다.
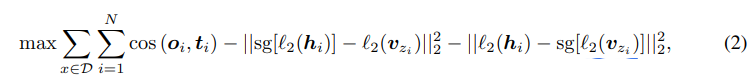
D: tokenizer 학습에 쓴 이미지 Data pool
sg[ ] : forward pass 일땐 identity, backward pass일땐 0으로
하나씩 보자.
- -> 모든 이미지의 각 패치에 대해 계산한 값을 최대로 하겠다.
- -> decoder에서 decoder output과 teacher model의 feature vector 사이의 cosine similarity를 최대화 (비슷하게)
-> forward pass: 학습할 때는 encoder output과 매핑된 codebook embedding vector 사이의 거리 최소화
-> backward pass: -> gradient를 업데이트 할 때는 각 vector 크기를 줄인다? (이부분은 잘 모르겠다.)
문제가 있다. Codebook을 쓸 때 'codebook collapse'가 발생한다. ; code들 중 일부만 사용하는 현상.
Empirical strategy 로 해결 가능하다.
Encoder output 과 codebook 매핑 할 때 norm을 계산한다 했었다. 이때 codebook space embedding 을 32-d로 줄여서 계산하고, 실제 decoder로 넘어가기 전에 dimension을 키워서 전달하는 방식이다.
Exponential moving average 를 계산해 codebook embedding을 업데이트 한다.
2.3 Pretraining BEIT v2
BEIT v1 논문에 등장했던 masking 규칙을 따른다.
요약하자면
- MIM을 할 때 image patches 앞에 학습 가능한 CLS 토큰을 붙인다.
- 특정 규칙에 따라 40% 정도에 해당하는 패치를 masking 한다.
- masking 한다는 건 원래 image patch 대신 학습가능한 패치 로 대체한다.
- 마스킹된 부분을 포함한 image patch들로 2.2에서 만든 visual token을 softmax classifier로 예측하도록 학습한다.
- Cross Entropy로 loss 연산
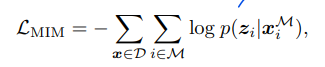
Pretraining Global Representation
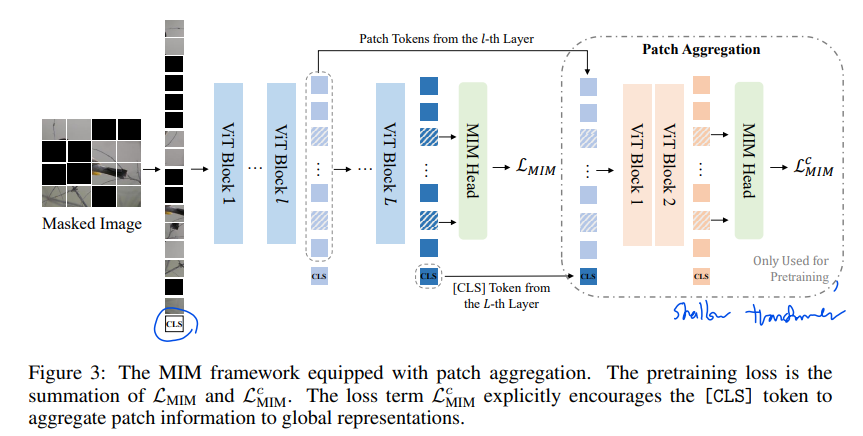
[CLS] 토큰이 global representation 담당이다.
[CLS] 토큰을 학습시키기 위해
번째 layer의 output vectors()와 마지막 layer(L번째)의 output에서 CLS 토큰을 concat한다. ->
이제 이걸 Shallow Transformer decoder에 집어넣는다. figure 3의 오른쪽 두 ViT block이다.
Shallow Transformer decoder 부분은 [CLS] 토큰 학습할 때만 사용해서, 학습 이후엔 안쓴다.
이 shallow transformer output으로 MIM loss 계산을 한다.
최종 Loss는 마지막 layer에서 계산한 MIM loss + shallow~에서 계산한 MIM loss 가 된다.
이유 부분 설명을 직관으로 해 두었는데 잘 이해가 안된다.
3. Experiments
각종 hyperparameter setting
patch size, ViT 크기, layer 수, epoch 수 등
3.4 Analysis
-
Decoder로 Deeper ViT를 사용하는게 성능이 MIM에 있어 좋지만, codebook usage와 downstream task 성능은 낮아지는 경향을 보인다.
-
Codebook의 dimension 수를 줄이는게 codebook utilization을 올린다.
-
Patch aggregation strategy (CLS 토큰 학습용 부분)
l th layer는 9, head depth를 2로 하는게 좋은 성능을 보였다. -
VQ-KD target model로 (teacher model) CLIP, DINO 실험 결과 CLIP 성능이 좋았다.
-
Visualization of codebook

4. Related Work
Visual Tokenizer
VQ-VAE 연계 연구들에서 이미지를 토큰화하는 방식들이 제안되었다.
Masked image Modeling
MIM method가 여러 연구서 등장한 바 있다.
총정리
논문 볼때마다 공부해야할게 늘어난다.
Knowledge Distillation 알아보자
얼른 Transformer 자세히 파보자. CLS token, ViT 대충 아는걸 채워야겠다.
날잡아서 코드도 한번 파자.
