딥러닝을 이용한 자연어처리 입문 7시간 완성 - 메타코드M
https://www.youtube.com/watch?v=Rf7wvs8ZbP4&ab_channel=%EB%A9%94%ED%83%80%EC%BD%94%EB%93%9CM
6회차는 GPT, BERT 입니다. 드디어 마지막이네요.
BERT나 GPT나 전에 배웠던 Glove, Fast text, SGN, CBOW 같은 word2vec 모델의 일종이다.
미리 대용량 corpus로 학습된 모델을 받아
원하는 task에 해당하는 부분을 transfer learning으로 fine tune 해줘서 사용하면 된다.
1. BERT
먼저 BERT를 알아보자.
Bidirectional Encoding Representation from Transformer (BERT)
여기서 Bidirectional: 양방향성을 띄고, Encoding: Transformer의 Encoder부분을 활용할 것이다. 이정도 기억하고 가봅시다.
먼저 Bidirectional
4회차때 Bi-LSTM 구조를 공부했었다.
LSTM 모델을 쌓는데, 앞으로도 데이터를 참고하고, 뒤로도 참고하는 그런 구조를 띄었다. BERT도 비슷하다.
예를 들어
I love ___ so much. 라는 문장이 있다. 가운데 빈칸에 들어갈 단어를 예측하기 위해 앞의 I love, 뒤의 so much 둘다 참고하여 'you'를 예측한다.
구체적인 구조를 살펴보자
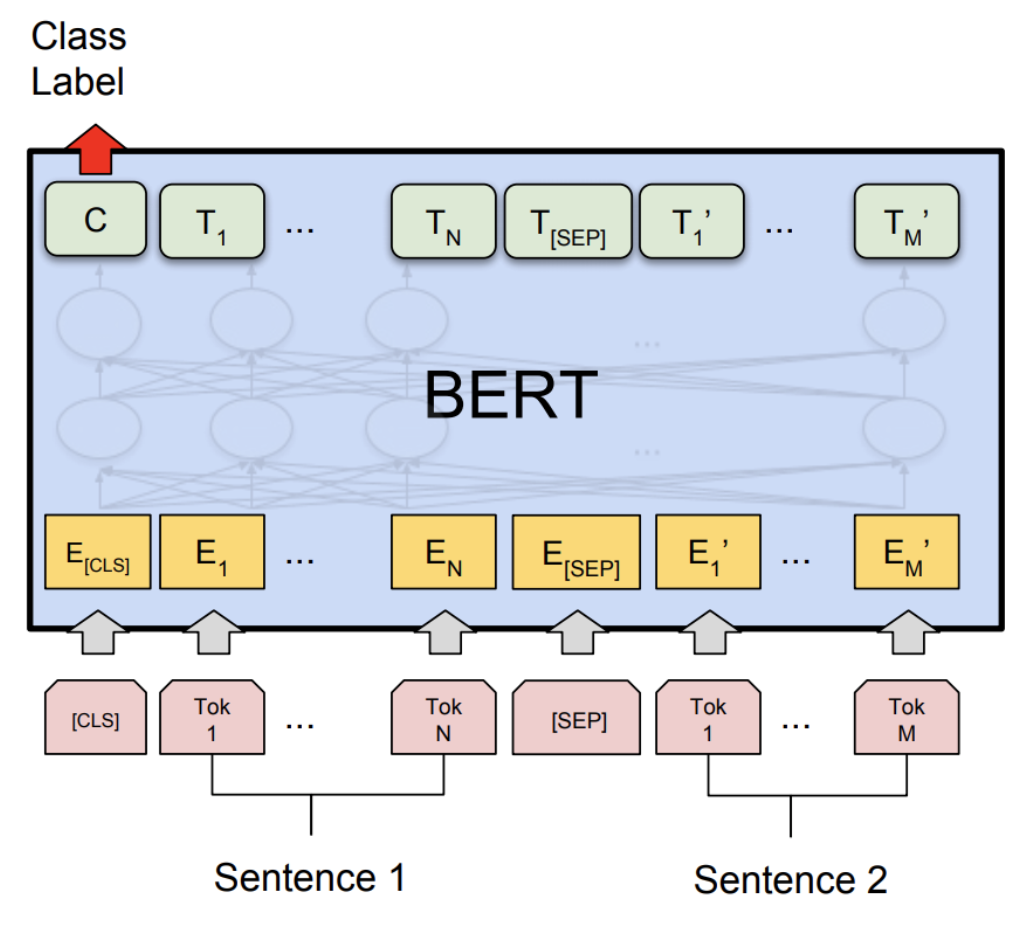
출처: https://tutorials.pytorch.kr/intermediate/dynamic_quantization_bert_tutorial.html
-
(분홍색) 문장 2개를 input으로 받아 두개 사이는 [SEP] 토큰으로 구분한다.
-
(노란색) 3개의 embedding:
Token Embedding- 문장 토큰화 결과
Segment Embedding- 문장 단위 임베딩 (앞 문장인지 뒤 문장인지)
Position Embedding- 몇번째 임베딩인지. (Transformer encoder의 position embedding과 같다.)
을 합친다. -
(가운데) Transformer Layer를 거친다.
Trasnformer의 encoder부분:Multi-head self-attention->Add&Norm->Feed forward->Add&Norm
을 여러개 쌓아 학습시킨다.
논문 저자의 실험결과,
12 transformer block / 768 hidden size / 12 self-attention head 로 이루어진 구조가 최적이라고 한다.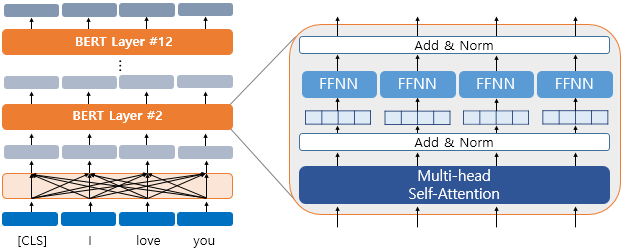 출처: https://wikidocs.net/115055
출처: https://wikidocs.net/115055
-
(초록색) 마지막 layer의 output으로 두가지(
MLM,NSP)를 확인한다.
Masked Language Model (MLM): 처음 문장을 input으로 넣어 줄 때 일부 단어를 mask 씌워 입력하고, 이후 출력단에서 맞게 예측했는지 loss를 계산한다.
-
전체 문장의 15%를 Masking 한다.
- 그 중 80%는 그대로 masking
- 10%는 random word로 치환
- 10%는 원래 단어 그대로 두고
성능을 계산한다.
Next Sentence Prediction (NSP): 앞 뒤 문장이 서로 이어지는가
예를 들어
A: I studied hard today
B: It is hard to predict stock market
라면 두 문장이 서로 이어지지 않는다. -> label=0
이어지는가/안 이어지는가 판단하는 Binary Classification과 같다.
Output 중에서 Class Label 값으로 label 값과 비교한다.
이후 원하는 task에 맞춰
문장 유형을 판단하는 task라면 class label값만 활용하면 되고,
각 단어의 품사를 tagging하는 task라면 각 토큰들의 output 모두를 이용하는 식으로 활용하면 된다.
2. GPT
BERT와 다르게 앞으로만 예측한다.
즉,
I love ___ very much. 라는 문장이 있으면
[ ] -> [I]
[ I ] -> [I love]
[I love] -> [I love you]
이런식으로 빈칸에 들어갈 단어를 앞의 단어들로만 예측한다.
구조
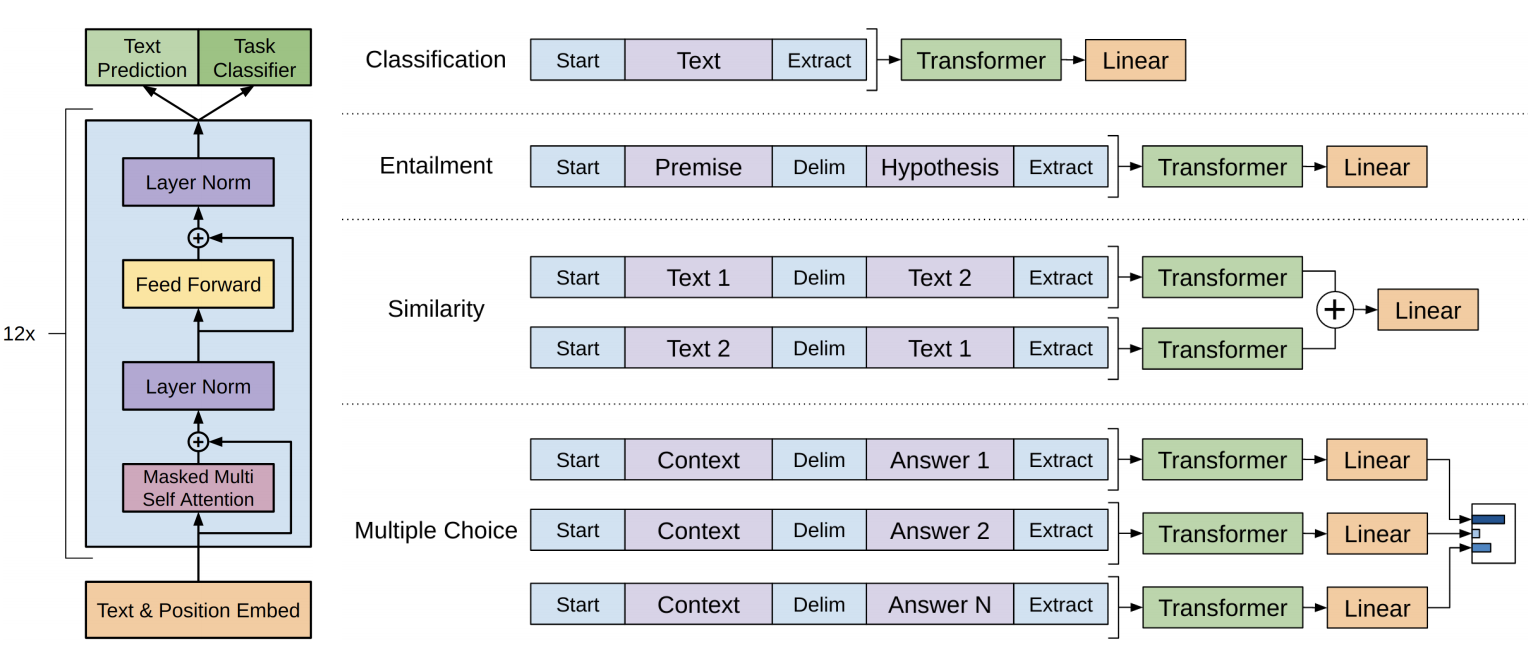
출처: https://paperswithcode.com/method/gpt
오른쪽 부분은 원하는 Task에 맞게 마지막 layer에 붙여주면 된다는 의미고
실제 모델 구조는 Transformer의 Decoder 구조인 왼쪽 모습이다.
Masked multi Self attention -> Layer norm -> Feed forward -> Layer norm
코드 구현
pytorch-transformer 라이브러리를 다운받으면 다양한 버전의 BERT를 쓸 수 있다.
총정리
BERT GPT 까지 알아봤다. 알기 전에는 뭔가 어마어마한 구조일 것 같았는데,
Vision으로 비유하면 CNN 공부하고, CNN 어떻게 쌓았느냐에 따라 모델이름 붙이는 것 처럼
Transformer를 어떻게 활용했느냐에 따라 BERT, GPT가 되는거라 아는만큼 보이는걸 다시 느꼈다.
이제 플젝 해보면서 NLP가 어떻게 돌아가는지 자세히 알아보자 + llm 관련해서도 알아보게 llama 논문 읽어보자
