신용카드 이상 거래 탐지와 같은 task는 데이터의 불균형 정도가 매우 심하다
(정상 거래 : 이상 거래의 비율이 9 : 1인 경우가 대다수다).
Classification task에서 label의 불균형이 존재할 경우 보통 Oversampling과 Undersampling기법을 사용한다.
- Oversampling : 낮은 비율 클래스의 데이터 수를 늘림으로써 데이터 불균형을 해소
- Undersampling : 불균형한 데이터 셋에서 높은 비율을 차지하던 클래스의 데이터 수를 줄임으로써 데이터 불균형을 해소
하지만 Oversampling은 소수 클래스의 데이터를 억지로 늘리기에 모델이 해당 클래스에 대해 과도하게 최적화될 수 있으며, 데이터의 품질 또한 보장할 수 없다.(물론 GAN을 활용하는 등 생성 데이터의 정교화를 보장하기 위한 연구가 진행되지만 근본적으로 인공 데이터로서의 문제는 불가피할 것이다) Undersampling 또한 정보가 과도하게 손실될 수 있다.
그래도 label의 불균형을 해결하는 방법이 이 두 가지 말고는 없으려나? 하는 생각에 kaggle을 둘러보았다.
AutoEncoder
첨에 본 2개의 kaggle notebook은 모두 SMOTE를 활용한 Oversampling이었다. 정작 이것말고는 없나 싶을 때 해당 notebook을 발견했다.
https://www.kaggle.com/code/shivamb/semi-supervised-classification-using-autoencoders/notebook
AutoEncoder의 정의
AutoEncoder의 개념을 보다 정확히 살펴보자
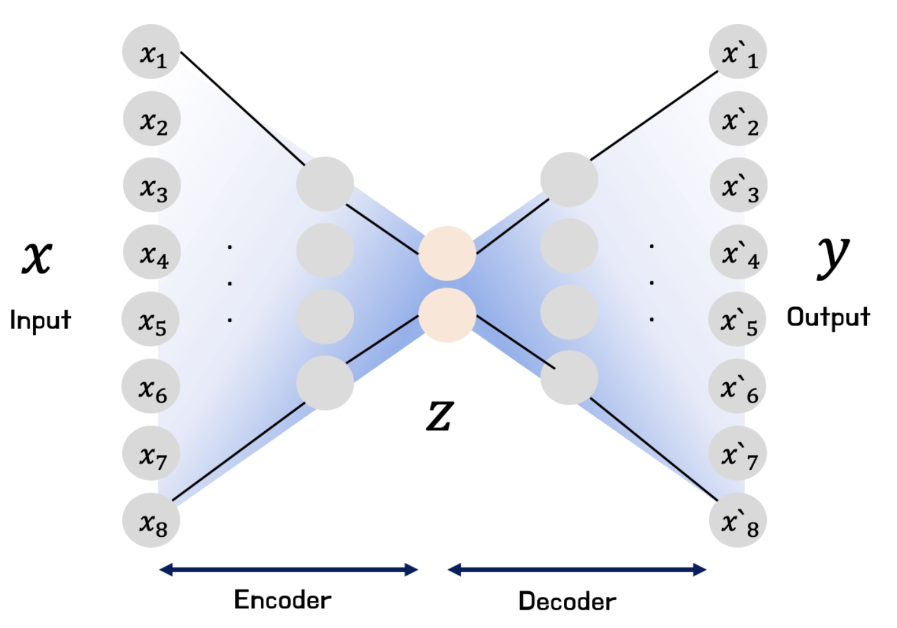
- AutoEncoder : 입력이 들어왔을 때 해당 입력 데이터를 압축시킨 다음, 데이터의 특징을 추출하여 다시 본래의 입력 형태로 복원시키는 신경망
정의부터 얘기하면 Representation learning 작업에 신경망을 활용하도록 하는 Unsupervised learning이라고 한다. 때문에 Unlabeled data에 효과적이다. Unlabeled data를 의미있게 압축시켜 Representation으로 Encoding하는 Encoder와, 이를 다시 입력 데이터로 복원하는 Decoder로 이루어져 있다.
AutoEncoder의 목적
조금 더 자세히 들어가보자.
AutoEncoder를 사용하는 데는 두 가지 목적이 있을 수 있다.
1) Manifold Learning
이는 Encoder를 학습시키는 것에 초점을 둔 것이다. Manifold Learning이라는 것은 결국 고차원 공간의 데이터를 저차원 Manifold space로 mapping시키는 함수를 찾는다는 것인데, 이는 입력 데이터만의 특성을 활용하여 어떠한 task를 수행한다는 느낌으로 받아들일 수 있다.
(Encoder 기반인 BERT는 분류와 같이 전체 문장의 이해를 요구하는 task에 적합한 것과 같은 맥락)
2) Generative model
윗 내용과 달리 Decoder를 학습시키는 것에 초점을 둔다. 실제 데이터의 분포를 학습하여 데이터를 생성한다. Latent variable을 실제 데이터의 분포로 mapping시키는 함수를 찾는다고 생각하면 된다.
(Decoder 기반인 GPT는 생성 요약과 같이 새로운 문장을 생상하는 task에 적합한 것과 같은 맥락)
종류로는 Sparse AutoEncoder, Denoising AutoEncoder, Contractive AutoEncoder 등이 있다고 하는데,, 이름만 난잡하지 결국 Regularization term을 부여하거나 Noise, Dropout을 추가하는 등 과적합을 방지하는 내용이다.
AutoEncoder를 활용한 불균형 데이터 학습
그럼 AutoEncoder로 불균형 데이터를 어떻게 다룬다는 걸까?
아이디어가 되게 재밌다.
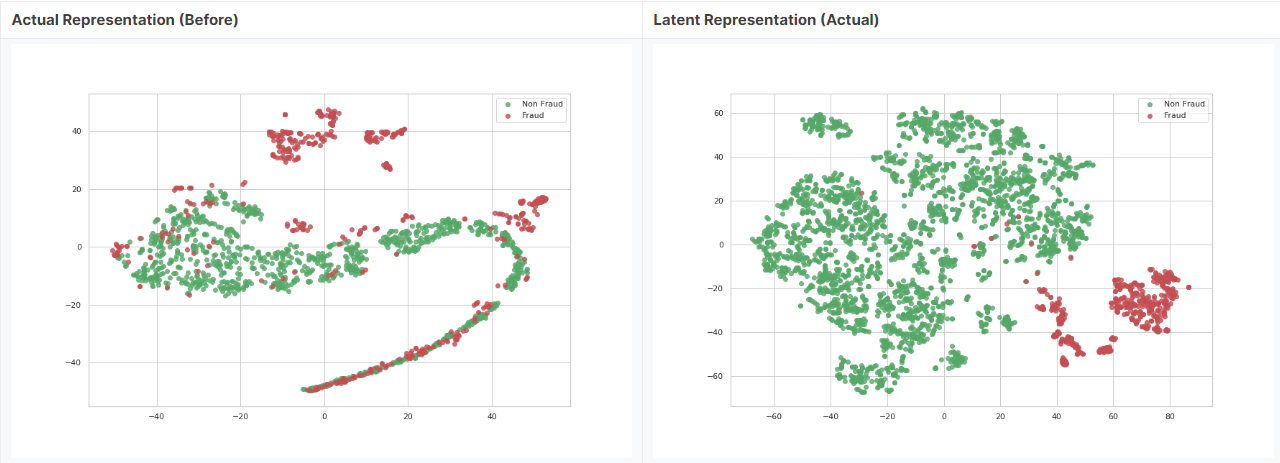
해당 내용을 다룬 Kaggle Notebook에서 분석가가 Non-Fraud를 일부만 선택해 AutoEncoder로 돌린 결과를 시각화한 그림이다. t-SNE으로 차원축소한 데이터이고 초록색이 Non-Fraud, 빨간색이 Fraud이다. AutoEncoder를 돌리기 전은 Non-Fraud와 Fraud가 공간상에 겹쳐지는 부분이 있어 예측에 어려움이 있다. 하지만 Non-Fraud만 AutoEncoder를 통해 Representation으로 인코딩함으로써 저차원 Manifold Space로 압축시켰더니 오른쪽과 같은 결과가 나온다. 즉, Non-Fraud에 맞춤형으로 Latent code가 구성된 것이다.
그럼 추론할 때 Fraud에 해당되는 데이터를 입력한다고 하자. 모델은 Encoder를 사용해 Non-Fraud에 맞춰진 Latent code로 해당 데이터를 인코딩할 것이다. 이제 Decoder에서 Latent code를 다시 복원한다면 결과값은 입력값과 동일하지 않게 된다. 이러한 원리로 Fraud를 탐지할 수 있는 것이다.
결론
한 가지 의문은,,, 참고한 Kaggle Notebook은 AutoEncoder을 통해 추출한 Non-Fraud Representation과 Fraud를 함께 분류기에 학습시킨다. Non-Fraud와 Fraud를 확실히 공간상에서 구분한 뒤 분류기로 학습한다는 방향인 것 같다. 결과가 잘 나오는 것 보니 이 또한 효과가 있어 보인다.
결론은 AutoEncoder 자체적으로 분류기로서 활용을 할 수도 있고, AutoEncoder로 Non-Fraud를 Representation한 값으로 분류기를 돌릴 수도 있는 것이다.
(과적합의 여지가 있어 보이지만 마땅한 근거가 떠오르지는 않는다. 나중에 생각나면 다시 와야지)
Reperence
AutoEncoder 설명
https://www.youtube.com/watch?v=X8SBsVqmVdY
https://velog.io/@jochedda/%EB%94%A5%EB%9F%AC%EB%8B%9D-Autoencoder-%EA%B0%9C%EB%85%90-%EB%B0%8F-%EC%A2%85%EB%A5%98
AutoEncoder를 활용한 신용카드 이상거래 탐지
https://github.com/KerasKorea/KEKOxTutorial/blob/master/20_Keras%EC%9D%98%20Autoencoder%EB%A5%BC%20%ED%99%9C%EC%9A%A9%ED%95%B4%20%EC%8B%A0%EC%9A%A9%EC%B9%B4%EB%93%9C%20%EC%9D%B4%EC%83%81%20%EA%B1%B0%EB%9E%98%20%ED%83%90%EC%A7%80%ED%95%98%EA%B8%B0.md
