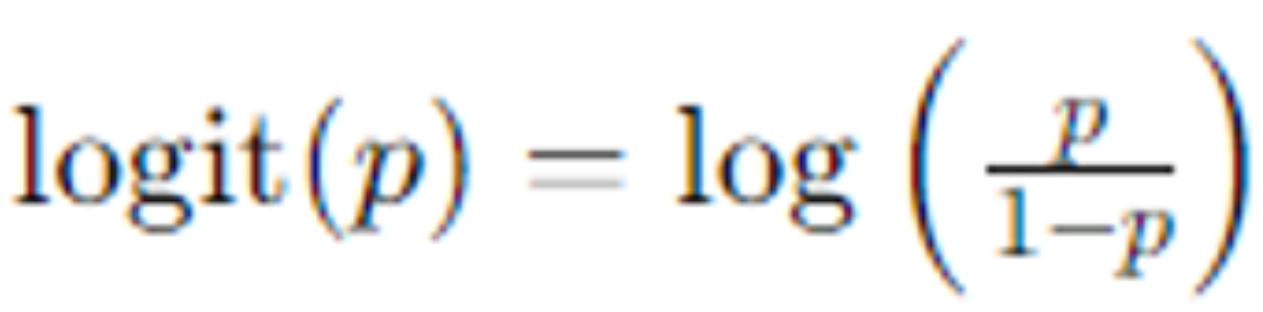
딥러닝 모델의 출력값은 로짓(logit)이라고 불리는 값으로 결과를 내놓는다. 여기서 로짓값은 모델의 마지막 선형 레이어에서 나온 예측값으로, 활성화함수를 거치지 전의 값이라고 생각할 수 있다. 보통 해당 로짓값에 소프트맥스(softmax) 함수를 사용해서 크로스 엔트로피(Cross Entropy)를 구하곤 한다.
여지껏 그냥 자연스럽게 해당 개념을 인지하고 모델링을 해오곤 했는데, 문득 class model()을 구현 할 때 마지막 x값이 그냥 linear 결괏값이지 않나? 왜 로짓값이지? 로짓함수를 씌우지 않는데? 라는 궁금증이 생겼고, 통계학에서 로지스틱과 딥러닝간에 '애매한' 연결고리가 아닌 '확실한' 연결고리를 찾고 싶었다.
"둘다 로짓함수 쓰잖아" 라는 말로 뭉뚱거리고 싶지 않아진 것이다.
통계학에서의 로짓
일반적으로 통계학에서 로짓값은 확률을 odds로 변환한 후, 이 odds에 자연로그를 취한 값이다.
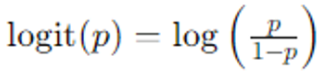
- p : 성공 확률, 0 < p < 1
- p/(1-p) : odds
그리고 해당 로짓값을 타겟으로 하여 회귀분석을 하면 로지스틱 회귀분석이 된다. 이로부터 확률값을 예측할 수 있으며, 그 확률값을 로짓 함수의 역함수인 로지스틱 함수(=시그모이드 함수)에 반영하여 0과 1의 예측값을 산출하는 것이다.
딥러닝에서의 로짓?
딥러닝에서 각 layer는 선형회귀의 연속으로 이해할 수 있다. 여러 개의 linear layer을 겹겹이 쌓고 각 layer마다 activation function을 추가함으로써 non-linearity를 부여하는 것이다. 아래 예시코드는 예전에 내가 한번 짜본건데, 보통 def forward(self,x)의 결괎값으로 x를 리턴한 후, 이를 softmax에 씌워 crossentropyloss를 구한다.
(torch.nn.crossentropyloss() 내부적으로 softmax()가 내장되어 있기에 원시 x값을 그대로 리턴하면 torch.nn.crossentropyloss()가 알아서 계산해준다. 만약 굳이 softmax(x)로 리턴하고자 한다면 torch.nn.NLLLoss()를 사용하는 방법도 있다.)
class Net(nn.Module):
def __init__(self):
super().__init__()
# 입력 이미지 크기: 3x200x200
self.conv1 = nn.Conv2d(3, 6, 5) # Output: (6, 196, 196)
self.pool = nn.MaxPool2d(2, 2) # Output: (6, 98, 98)
self.conv2 = nn.Conv2d(6, 16, 5) # Output: (16, 94, 94)
# 다시 pooling 적용: (16, 47, 47)
self.conv3 = nn.Conv2d(16, 32, 5) # Output: (32, 43, 43)
# 다시 pooling 적용: (32, 21, 21)
# fully connected 레이어의 입력 크기를 계산
# 3번의 maxpool 레이어를 거치고 나면 크기가 200 -> 100 -> 50 -> 25
self.fc1 = nn.Linear(32 * 21 * 21, 120) # 32 * 21 * 21 from last conv layer
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 2) # 최종 클래스는 2개
def forward(self, x):
x = self.pool(F.relu(self.conv1(x))) # Output: (6, 98, 98)
x = self.pool(F.relu(self.conv2(x))) # Output: (16, 47, 47)
x = self.pool(F.relu(self.conv3(x))) # Output: (32, 21, 21)
x = x.view(-1, 32 * 21 * 21) # flatten all dimensions except the batch
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x) # 마지막 레이어에서는 softmax 또는 log-softmax를 사용합니다 (CrossEntropyLoss 사용 시 생략 가능)
return x결국 리턴되는 output도 각 layer의 결괏값과 같이 회귀식의 결과로써 해석할 수 있다.
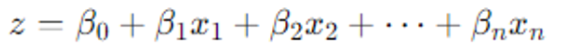
그럼 non-linearity를 부여하기 전의 값은 그저 선형회귀의 결괏값이 아닌가? 맞는 말이다. 다만, 이를 로짓값으로 보는 것은 특별히 로짓함수를 사용해서 도출하는 것이 아니라, 출력값을 로짓값으로써 해석하자!라고 생각하는 것이 편하다.
결국 관점의 문제였다.
출력값을 로짓값으로 바라보게 되면 결국 로지스틱 분석과 마찬가지로 모델 출력을 확률적으로 해석할 수 있다. 해당 값을 로지스틱 함수(로짓함수의 역함수 = 시그모이드 함수 = 이진분류에서 소프트맥스 함수)에 적용함으로써 0~1 사이의 확률값으로 변환가능하기 때문이다.
딥러닝을 계속 다루다보면 기본적인 부분에서 계속 사소한 궁금증이 발생하게 된다. 그리고 통계적으로 연결지음으로써 기초통계 ~ 딥러닝까지의 관계가 그려지는 것에 재미를 느낀다.
