
Introduction
딥러닝 스터디에서 진행하는 한 책이 끝나고 자유주제 발표를 위해 어떤 주제로 할까 찾아보다가, 책 뒷편에 있는 "화풍 변환"을 보고 논문을 읽고 이를 구현해보려 한다.
참고 논문 : A Nural Algorithm of artistic Style (2015. 08)
이미지 스타일 변환

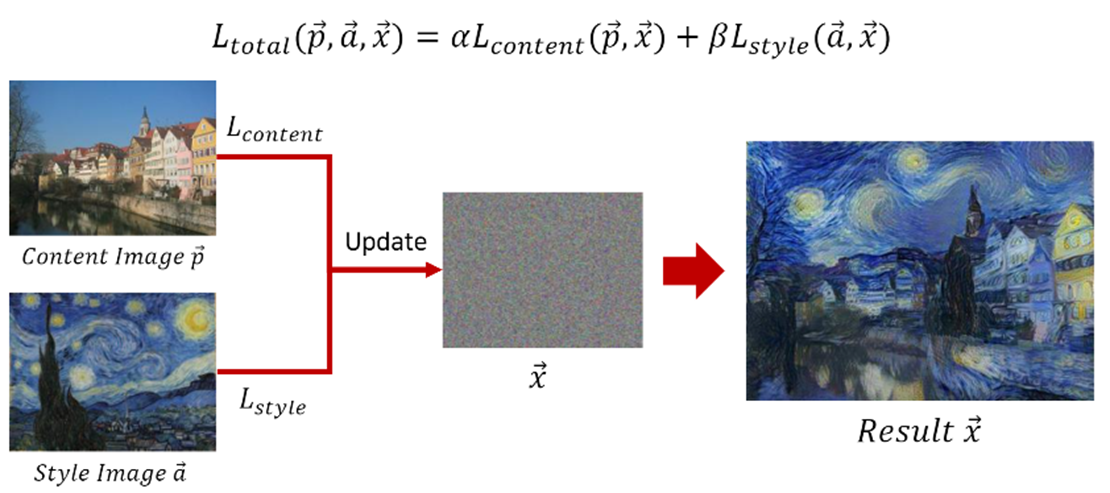
- Stlye Transfer은 윤곽과 형태를 위한 이미지인 Content image와 화풍을 위한 Style image를 가지고, 스타일을 바꾸어 자신만의 예술 작품을 만드는 것을 말한다.
ConvNets
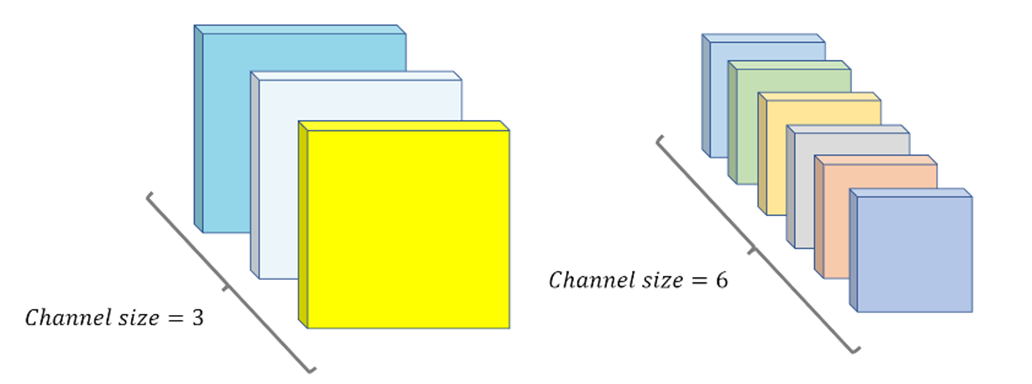
- Conv를 이용하여 학습을 할 때, 각 layer에서 추출하는 feature를 시각화하여 각 layer들의 unit들을 최대로 활성화 하는 특징이 무엇인지 파악할 수 있다.
- CNN의 특징상 Layer가 깊어질수록 채널의 수가 많아지고 너비와 높이는 줄어드는데, 각 필터들은 적절한 특징(feature) 값을 추출하도록 학습된다. (ex. 뾰족한 부분의 특징, 동그란 부분의 특징)
- 네트워크는 미리 Pre-train된 모델을 사용하기 때문에, Loss에 더 초점을 둔다.
Update

- 한장의 이미지가 들어왔을 때 우리가 미리 Pre-trained된 CNN모델을 사용하여, Noise 이미지를 업데이트 함으로써 우리가 원하는 이미지와 같은 형태를 얻을 수 있다.
Content Loss
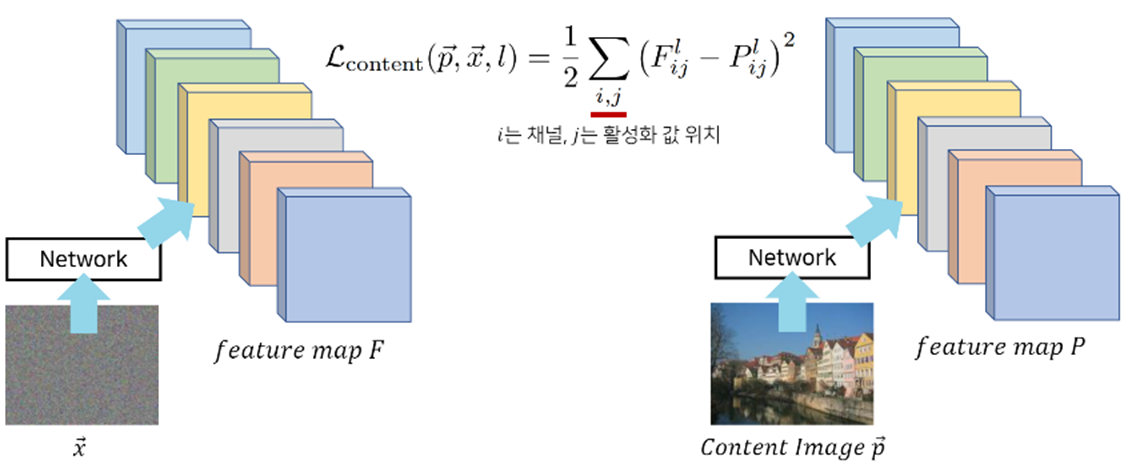
- Content Loss는 단순히 두 이미지의 특징값이 같아지도록 작동한다.
- 하나의 이미지 X를 특정 Layer에 넣었을 때 나온 각각의 feature의 값과 P를 같은 Layer에 넣었을 때 나온 각각의 feature의 값을 비교하여 Content Loss를 줄이는 방향으로 최적화한다.
Style Loss
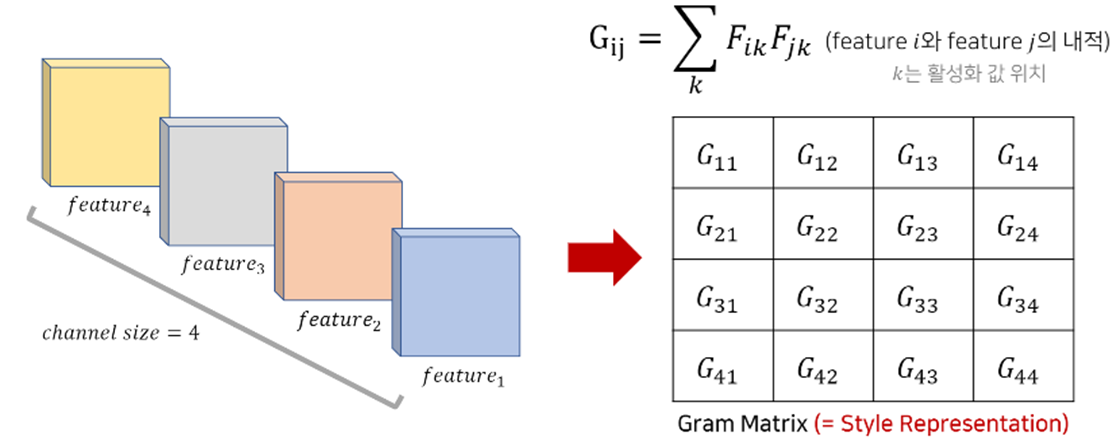

- Style은 Content와 다르게 특징(feature)간의 상관관계(Correlation)을 말하는데, 이를 위해서 Gram Matrix를 활용할 수 있다.
- 예로, 특정 레이어에서 나온 출력 feature맵에서 2개의 channel(i,j)들의 각각의 원소들(k)의 값을 서로 곱하여 더한다.
- 값이 크다는 것은 두 feature간에 상관관계가 높다는 것을 의미한다.
- 그래서 Style을 추출하기 위해 네트워크를 통해 나온 이미지의 feature map에서 Gram Matrix로 서로간의 상관관계를 수치화하고, 이는 곧 스타일이 된다.

- 스타일 손실(style loss)는 두 이미지의 특징 상관관계를 유사하게 만든다.
- 하나의 이미지 X를 특정 Layer에 넣었을 때 나온 각각의 feature의 Gram Matrix값과 A를 같은 Layer에 넣었을 때 나온 각각의 feature의 Gram Matrix값을 비교하여 Style Loss를 줄이는 방향으로 최적화한다.
- Content와 다르게 Style은 1개의 Layer가 아니라 보통 3~4개의 Layer에서 각각 Gram Matrix를 구하고 각각 Layer에서 Gram Matrix가 유사해지도록 한다.
Style Reconstruction & Content Reconstruction

Style Reconstructions
- Gram Matrix는 채널의 크기만큼 커지게 된다.
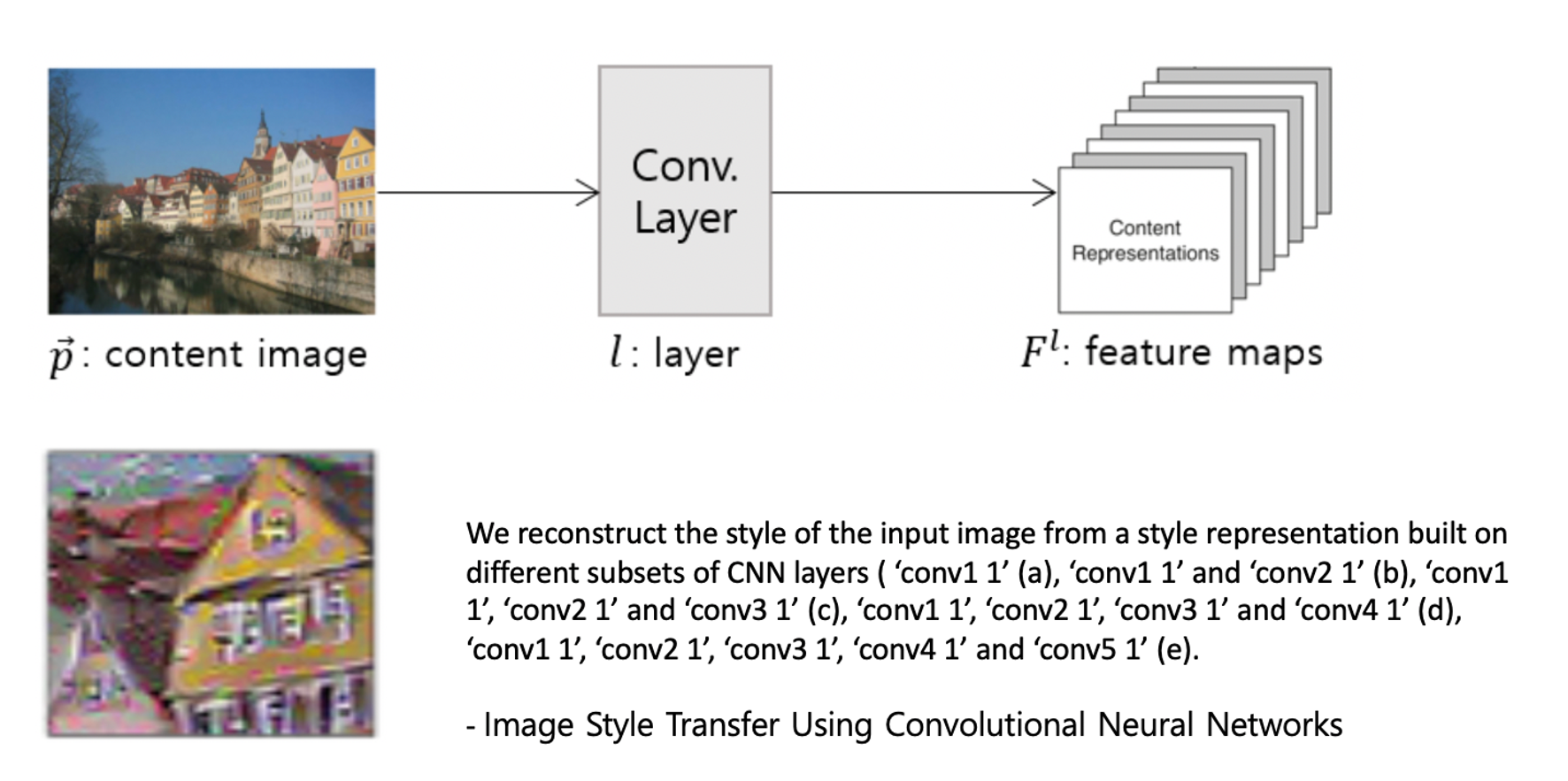
(a) Conv1_1
(b) Conv1_1, Conv2_1
(c) Conv1_1, Conv2_1, Conv3_1
(d)Conv1_1, Conv2_1, Conv3_1, Conv4_1
(e) Conv1_1, Conv2_1, Conv3_1, Conv4_1, Conv5_1
Content Reconstructions
- 깊어질수록 구체적인 픽셀 정보는 소실
(a) Conv1_2
(b) Conv2_2
(b) Conv3_2
(d) Conv4_2
(e) Conv5_2
실제로는 이 두가지의 과정이 CNN에서 동시에 진행되는데, 편의상 각각 나누어서 시각화하여 보여준다.
-
Content image(우측 하단 Image) 의 경우, layer가 깊어 질수록 원본 대비 detail한 pixel information은 소실되지만 high-level image, 즉 전체적인 윤곽인 건물의 모습은 유지된다.
-
Style image(우측 상단 Image)의 경우, layer가 깊어 질수록 style image 원본에 가까워지게 된다.
이러한 현상이 발생하는 이유는 같은 layer의 feature map의 channel간 correlation(Gram Matrix)으로 정의하였기 때문이라고 한다.
Algorithm

- 합성할 이미지인 X는 백지로 noise image로 초기화한다.
- 각각 p, a, x를 ImageNet pretrained된 VGG19에 forward pass한다.
- Content loss는 이미지 p와 x에 대해 계산한다. (그림상으로는 Conv4에서 계산)
- 반면에 Style loss는 여러가지 Layer를 사용가능한데 논문에서는 5개의 Layer로 정의한다. 각각의 feature의 Gram Matrix를 구하고 a와 p에 대해 계산한다. 서로 일치해질 수 있는 부분으로 최적화한다.

- Total loss를 적용하여 Style 중심적일지(베타값이 클경우), Content 중심적일지(알파값이 큰경우)를 정할 수 있다.


AI 엔지니어가 되고싶은 대학생 입니다.

다음은 Tutorial code를 리뷰하는 글을 올려보겠습니당