
Semantic segmentation를 사용하는 프로젝트를 하기 위해 Backbone모델을 찾고 있는 와중에,
Cityscapes과제에서 SOTA 모델을 차지하고 있는 모델인 HRNet에 대해서 간단하게 논문 리뷰 및 코드 구현을 해보려고 한다.
Abstract
-
Computer vision task에서는 고해상도의 표현이 필수적임.
-
대부분의 방법은 컨볼루션 네트워크를 통해 고해상도에서 저해상도 표현으로 Encoding하고
Upsampling이나 Decoder를 통해 고해상도의 표현으로 복구한다. (ex. FCN, UNet) -
HRNet은 고해상도의 표현을 지속적으로 유지하는 방법을 제시했다.
- Stage를 지날수록 고해상도에서 저해상도 네트워크를 구성하되, 병렬로 연결하여 고해상도 네트워크를 유지
- 병렬로 연결된 네트워크간의 정보의 교환을 통해 전반적인 정보와 디테일한 정보를 풍부하게 포함
Introduction
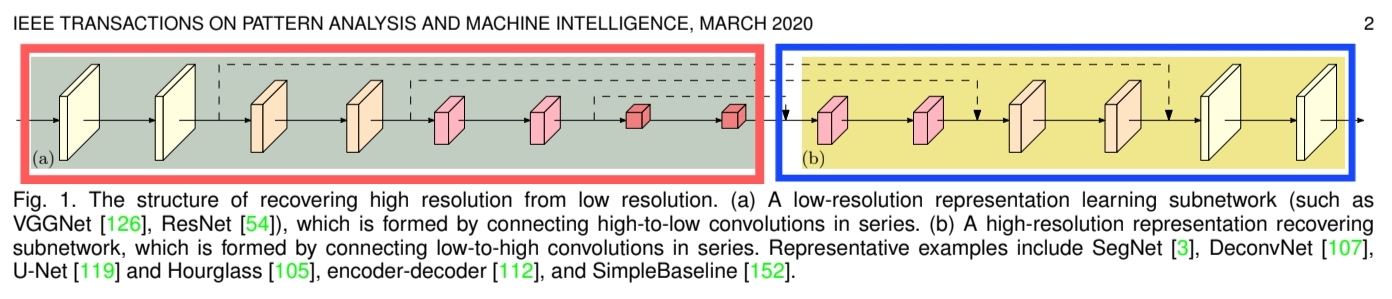
- 기본적으로 Conv Layer의 특징으로 정보가 압축되면서 Low-resolution의 표현으로 나타내어진다. (ex. VGG, ResNet, etc)
- 하지만 Classification을 제외한 Segmentation, Detection, Pose estimation에서는 고해상도의 회복이 필요하다.
- 그래서 Upsampling을 통해 다시 원래 상태로 복구한다. (ex. SegNet, DeconvNet, U-Net)
-
HRNet은 (1) High-resolution을 유지하면서도 low-resolution을 병행하여 직렬 형태의 Encoder-Decoder보다 더 공간적으로 정확하다.
-
또한 반복적으로 (2) multi-scale fusions을 병행하는 conv끼리 반복적으로 수행하여 High-level의 정보와 Low-level의 정보를 같이 가지고 있어 Semantically Strong하다.
단순 병렬로만 추가?
- HRNet은 high-to-low resolution convolution stream을 직렬이 아닌 병렬 구조로 연결하기 때문에, 높은 해상도에서 해상도를 떨어뜨리는 것이 아니라 전체 stage에서 높은 해상도를 유지할 수 있고 그에 따라 공간적으로 더욱 정확함.
- 대부분의 fusion scheme들은 고해상도 low-level representation과 저해상도 representation에 Upsampling을 가해 만들어진 high-level representation을 모아놓는데 반해, HRNet은 low-resolution representation이 high-resolution representation에 영향을 줘서 부스트할 수 있도록 multi-resolution fusion을 반복. (High-resolution representation이 low-resolution representation에 영향을 주기도 함) 그에 따라 HRNet의 모든 high-to-low resolution representation들은 모두 semantically strong
- HRNet은 최종 output의 도출 방법에 따라 V1, V2, (V2p)로 나뉜다.
Related Work
이전 포스팅 했던 글 -> Semantic Segmentation 정리
-
저해상도에서의 학습 - FCN
-
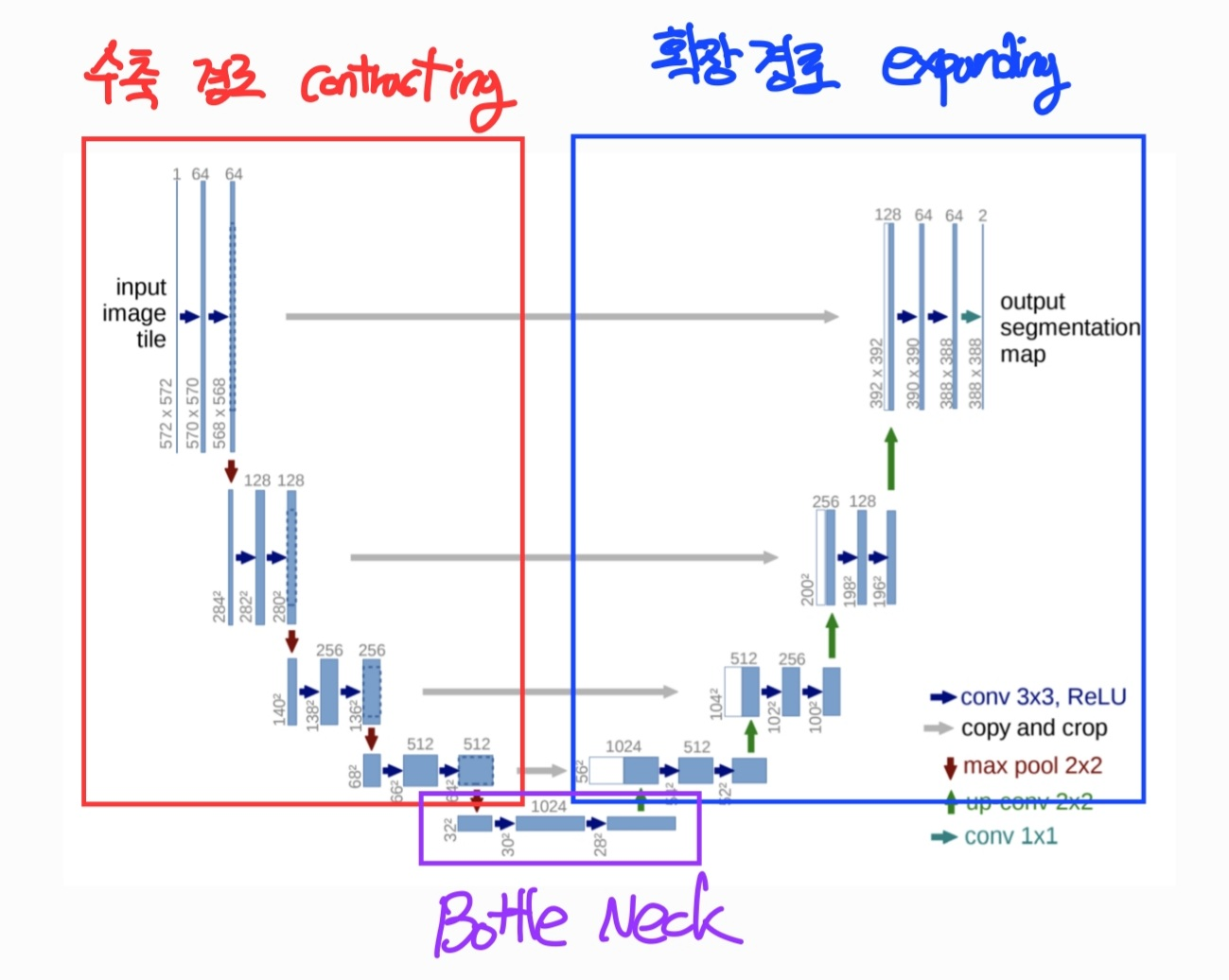
고해상도 회복 - UNet
-
고해상도 유지 - HRNet, GridNet, interlinked CNNs
- 기본적으로 병렬네트워크 구조를 가져간다.
- Conv neural fabrics, interlinked CNNs는 Low-resolution에 대한 효율성을 극대화하지 못함
- batch Normalization과 residual connections을 사용하지 않아 만족스러운 퍼포먼스가 안나옴 (HRnet이 좋다고 밑밥)
High-Resolution Network
HRNet은 input image를 2-stride 3*3 Convolution을 사용하여 1/4로 해상도를 감소시켜 진행한다.
다른 모델에 비해 굉장히 작은 Resolution 감소이다. 기존 model은 model들은 1/20, 1/16 정도로 유지
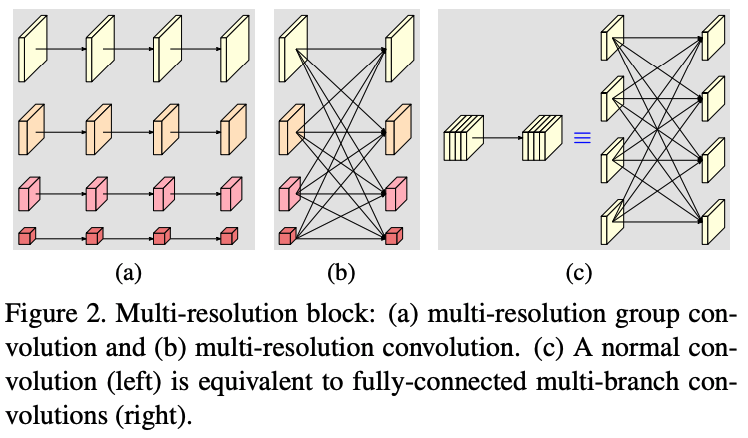
Parallel Multi-Resolution Convolutions
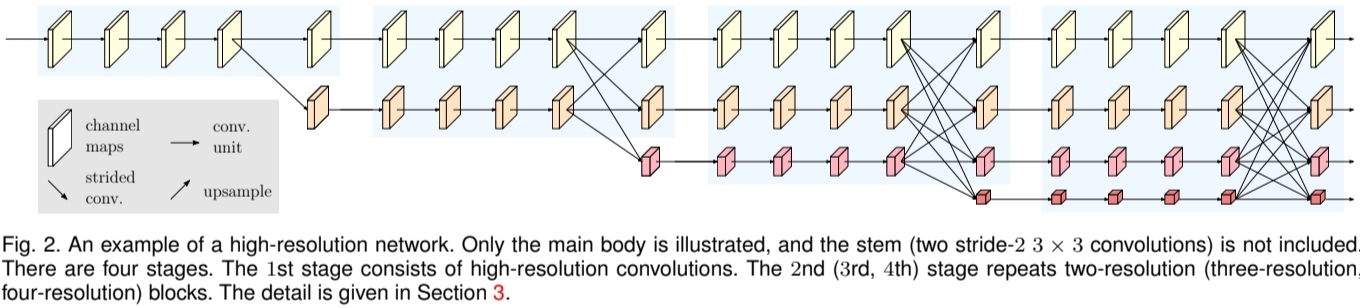
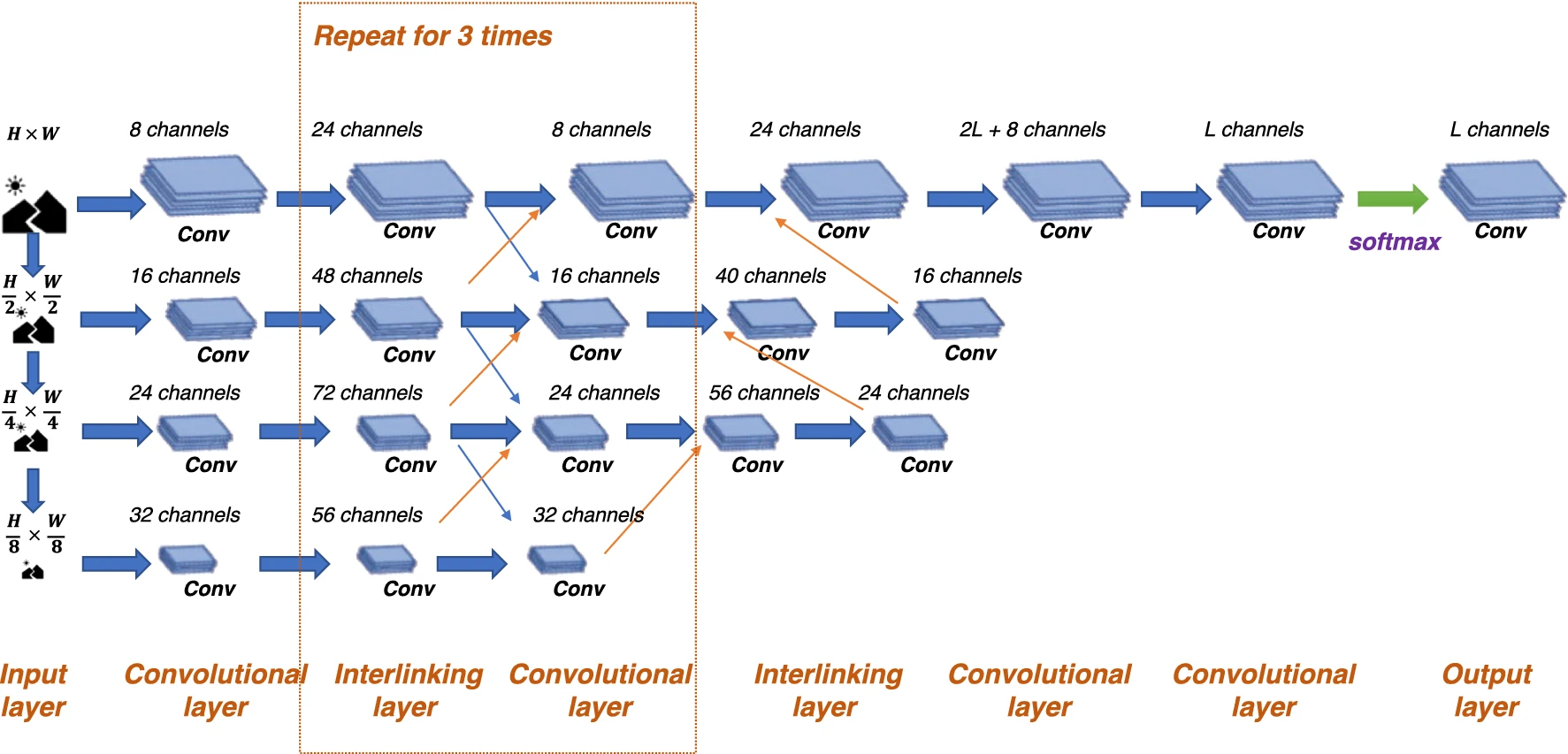
- 각각의 파란색 영역의 Stage를 multi-resolution block이라고 부름 high-to-low resolution conv가 병렬로 추가되어있음을 의미
- 노란색 채널 맵은 당연히 고화질 빨간색의 작은 채널은 당연 저화질의 채널맵(lowest resolution) 4개의 채널맵이 병행으로 처리된다.
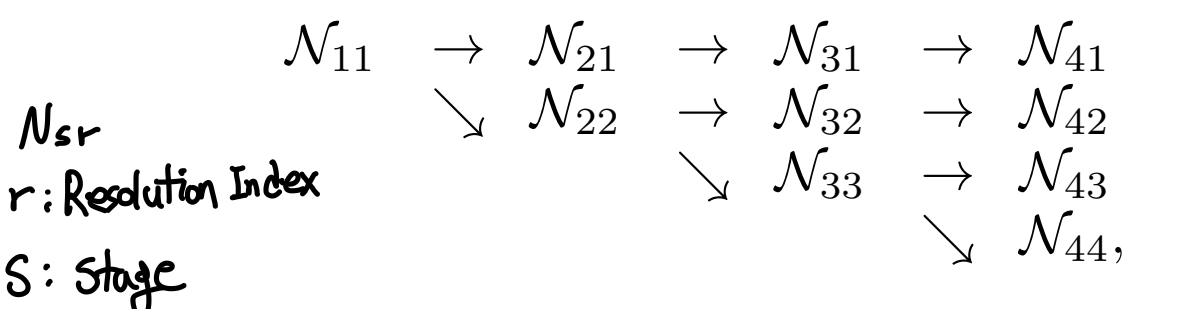
Repeated Multi-Resolution Fusions
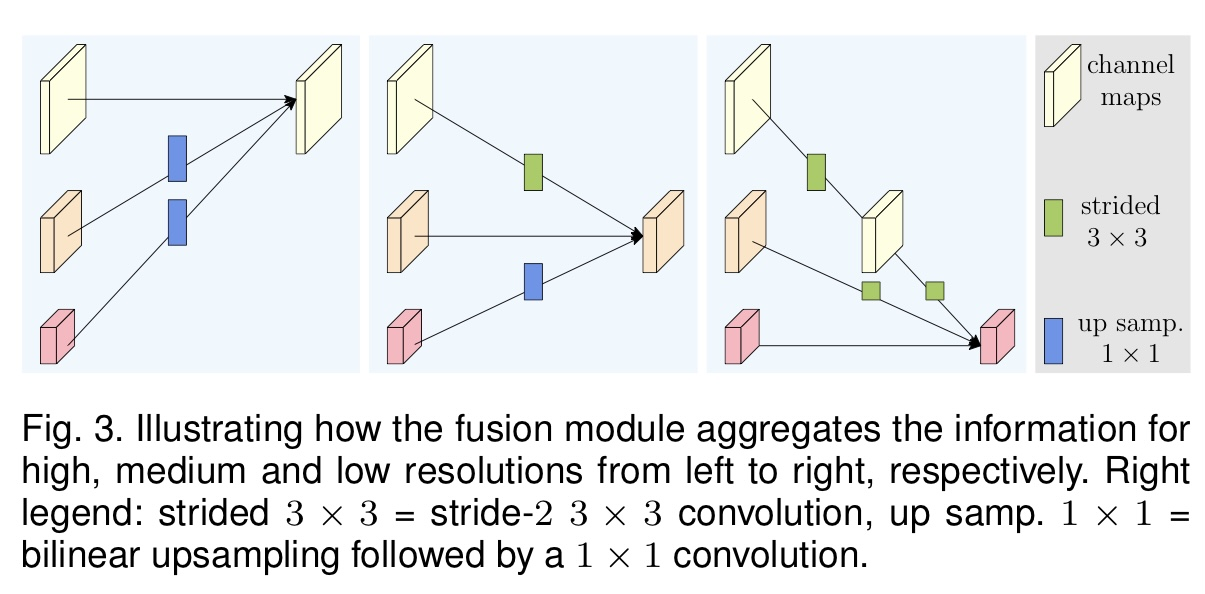

- 각 resolution feature를 각 stage마다 sum해서 다양한 feature를 고려할 수 있음
- 다양한 scale을 반복적으로 fusion하는 과정에서 Exchage Unit이 사용된다. (Exchange Unit은 Parallel Net간 정보를 전달)
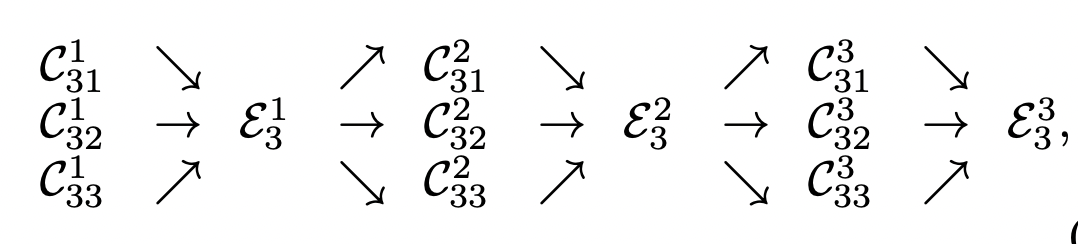
r: r번째 Resolution
s: s번째 stage
b: b번째 Convolution Unit (그림 1, 2, 3)
- 설명을 위해 에서 s와b를 제거 (resolution에 따른 차이만을 본다.)
- Input response maps: {} (resolution 단계는 1~S)
- Output response maps: {}
Resolutions and Widths are the same to the input. - Each output is an aggregation of the input maps
- extra output map(마지막으로 다 계산된 값에 한번 더 넣어줌.)
Heatmap estimation
- high-resolution representations output을 사용하여 heatmap regress함.
- Loss function: mean squared error (MSE)
- heatmap은 표준편차가 1pixel인 2D 가우시안분포를 적용해 구함
Representation Head
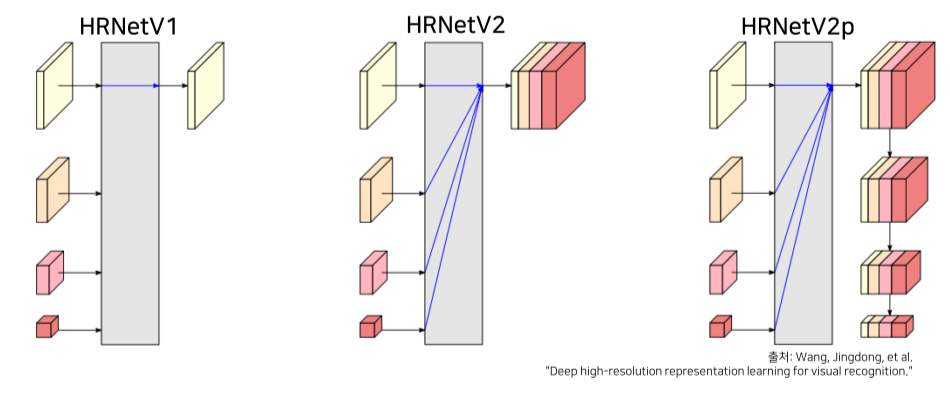
V1: high-resolution stream에서 계산된 high-resolution representation만을 결과로 사용해서 pose estimation, keypoint detection에 활용
V2: 병렬로 구성된 high-to-low resolution stream들 전체의 representation을 더함. 더해진 high-resolution representation에서 segmentation map을 예측해 semantic segmentation에 적용함.
V2p: HRNet2의 high-resolution representation 결과물을 최신 detection framework (Faster R-CNN, Cascade R-CNN, FCOS, CenterNet)이나 joint detection and instance segmentation framework (Mask R-CNN, Cascade Mask R-CNN, Hybrid Task Cascade) 등에 적용
Next
다음은 구조 설명과 함께 HRNet 코드를 구현해 보겠다.
