Introduction
2014년 Ian Goodfellow(.et al)은 Generative Adversarial Networks(줄여서 GAN)라는 생성 모델을 훈련하는 방법을 제시했다.
GAN 복습
GAN은 기본적으로 두 개의 다른 신경망(Generator와 Discriminator)간의 적대적인 관계로 대립(Adversarial)하며 서로의 성능을 점차 개선해 나가는 것이다.
- 생성 모델 G : 데이터의 분포를 학습하는 모델
- 판별 모델 D : 이미지를 실제(학습을 진행할 때 사용하는 Training Data) 또는 가짜(임의로 만든 Generated Data)인지 분류하는 모델
코드 구현
GAN을 구현하고 MNIST데이터셋을 통해서 새로운 MNIST를 만들어본다.
GAN 코드구현을 위해 기본적으로 torch 라이브러리를 import 한다.
Library
import torch
import torch.nn as nn
from torch.nn.modules import loss
import torch.optim as optim
import torchvision
import torchvision.datasets as datasets
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
from torch.utils.tensorboard import SummaryWriter기본적으로 신경망을 만들기 위해 torch.nn을 부르고,
데이터 셋, 아키텍처 모델, 이미지 변환 기능으로 구성되어 있는 패키지인 torchvision을 부른다.
Discriminator
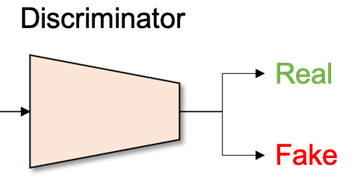
class Discriminator(nn.Module):
def __init__(self, in_features):
super().__init__()
self.disc = nn.Sequential(
nn.Linear(in_features, 128),
nn.LeakyReLU(0.1),
nn.Linear(128, 1),
nn.Sigmoid(),
)
def forward(self, x):
return self.disc(x)- Linear - LeakyReLU - Linear - Sigmoid로 구성한다. 아주 간단하다.
- sigmoid를 통해 0.5 기준으로 진짜와 가짜를 classification한다.
Pytorch
forward()는 모델이 학습데이터x를 입력 받아서 forward propagation을 진행시키는 함수이다.
반드시forward라는 이름의 함수여야 한다.
Generator
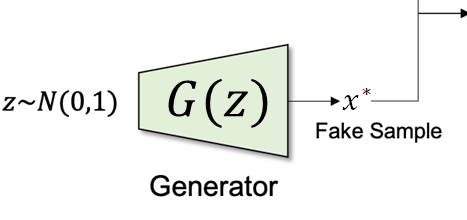
class Generator(nn.Module):
def __init__(self, z_dim, img_dim):
super().__init__()
self.gen = nn.Sequential(
nn.Linear(z_dim, 256),
nn.LeakyReLU(0.1),
nn.Linear(256, img_dim), # 28 * 28 * 1 -> 784
nn.Tanh(),
)
def forward(self, x):
return self.gen(x)- 입력값으로 벡터
z_dim과 출력인img_dim을 받는다. - Linear - LeakyReLU - Linear - Tanh로 구성한다. 이것도 간단!
Tanh( )함수를 쓰면 출력되는 값을 -1 ~ 1 사이로 맞출 수 있다.- MNIST 손글씨의 픽셀 범위도 -1 ~ 1로 맞추면 판별 조건이 모두 갖춰진다.
Hyperparameters
device = "cuda" if torch.cuda.is_available() else "cpu"
lr = 3e-4
z_dim = 64 # 128, 256
image_dim = 28 * 28 * 1 # 784
batch_size = 32
num_epochs = 50- GPU사용을 위해
torch.cuda.is_available()로 GPU를 활성화한다. - 누가 그랬는데 Adam optimizer에는 learning rate는 3e-4가 Best라 하였다. 이것은 여러분들이 구현하면서 조금씩 바꿔가면서 비교해봐도 좋을 것 같다. (예로, 1e-4, 1e-3 등등)
- 입력 벡터값으로 z_dim을 64로 한다.
batch_size는 32num_epochs는 50으로 학습한다.MNIST 데이터 특징
- 2차원의 이미지 데이터이지만, 실제로는 가로 28픽셀, 세로 28픽셀, 총 784픽셀의 각각에 화소값이 입력되어 있다.

- 2차원의 이미지 데이터이지만, 실제로는 가로 28픽셀, 세로 28픽셀, 총 784픽셀의 각각에 화소값이 입력되어 있다.
입력 벡터를 784로하는 것이 아니라 64로 하는 이유?
784차원의 캔버스에 이미지를 생성하는 의미를 생각해보자.
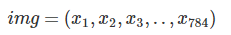
그런데, 생성모델 이란 각 픽셀 값이 임의의 값을 취했을 때의 동시확률분포(joint probability)를 구하는 것과 같다.
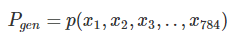
예로 각 픽셀이 전부 0이 될 확률이라던가, 전부 1이 될 확률이라던가, 더욱 중간에 가까운 값, 784차원의 모든 값의 분포에 대해서 확률을 구하는 것이 된다.
즉, 전부 x분포에 대한 밀도 분포를 알 수 있게 된다.
그렇다면, MNIST는 처음에 넣을 때 784차원으로 지정해야하나?
아니다.
- 10종류의 숫자를 표시하는 것으로 MNIST데이터의 분포는 이것보다 낮은 차원으로 집약되어 있을 것이다. 그래서 입력차원을 낮게 하는 것
- MNIST가 해상도가 커져도 집약된 정보는 변하지 않기 때문에 더 많은 차원의 벡터가 필요하지 않다.
준비
disc = Discriminator(image_dim).to(device)
gen = Generator(z_dim, image_dim).to(device)
fixed_noise = torch.randn((batch_size, z_dim)).to(device)
transforms = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,)),]
)
dataset = datasets.MNIST(root="dataset/", transform=transforms, download=True)
loader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
opt_disc = optim.Adam(disc.parameters(), lr=lr)
opt_gen = optim.Adam(gen.parameters(), lr=lr)
criterion = nn.BCELoss()
writer_fake = SummaryWriter(f"runs/GAN_MNIST/fake")
writer_real= SummaryWriter(f"runs/GAN_MNIST/real")
step = 0Discriminator와Generator를 선언하고 noise를 만든다.transform을 통해서 Tensor형으로 바꾸고 정규화해준다.dataset을 불러온다.Adam을 Optimizer로 설정Loss(criterion)는 논문에서 나왔듯 Real/Fake를 구분하기 위해 Binary cross entropy를 사용한다.
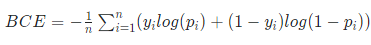
- tensorboard 사용을 위해 SummaryWriter를 선언한다.
학습
for epoch in range(num_epochs):
for batch_idx, (real, _) in enumerate(loader):
real = real.view(-1, 784).to(device)
batch_size = real.shape[0]
### Train Discriminator: max log(D(x)) + log(1 - D(G(z)))
noise = torch.randn(batch_size, z_dim).to(device)
fake = gen(noise)
disc_real = disc(real).view(-1)
lossD_real = criterion(disc_real, torch.ones_like(disc_real))
disc_fake = disc(fake).view(-1)
lossD_fake = criterion(disc_fake, torch.zeros_like(disc_fake))
lossD = (lossD_real + lossD_fake) / 2
disc.zero_grad()
lossD.backward(retain_graph=True)
opt_disc.step()
### Train Generator: min log(1 - D(G(z))) <-> max log(D(G(z))
# where the second option of maximizing doesn't suffer from
# saturating gradients
output = disc(fake).view(-1)
lossG = criterion(output, torch.ones_like(output))
gen.zero_grad()
lossG.backward()
opt_gen.step()
if batch_idx == 0:
print(
f"Epoch [{epoch}/{num_epochs}] Batch {batch_idx}/{len(loader)} \
Loss D: {lossD:.4f}, loss G: {lossG:.4f}"
)
with torch.no_grad():
fake = gen(fixed_noise).reshape(-1, 1, 28, 28)
data = real.reshape(-1, 1, 28, 28)
img_grid_fake = torchvision.utils.make_grid(fake, normalize=True)
img_grid_real = torchvision.utils.make_grid(data, normalize=True)
writer_fake.add_image(
"Mnist Fake Images", img_grid_fake, global_step=step
)
writer_real.add_image(
"Mnist Real Images", img_grid_real, global_step=step
)
step += 1- Discriminator의 목표는
- 에포크를 돌면서 noise를 만들고 이미지를 생성(
fake) lossD_real = criterion(disc_real, torch.ones_like(disc_real))(진짜 이미지에 대한 Loss)와lossD_fake = criterion(disc_fake, torch.zeros_like(disc_fake))(가짜 이미지에 대한 Loss)를 구해서
평균을 구하고, backward해준다.- Generator의 목표는
lossG를 구하고 backward
결과
TensorBoard로 학습 진행 상황을 볼 수 있다.

성능이 그렇게 좋지는 않다.
당연하다. 신경망을 단순하게 구현 했으니...
이걸 SimpleGAN이라고도 한다.
실제 GAN은 종류가 엄청 많은데
CNN을 통하여 구현한 DCGAN
Wasserstein distance를 적용한 WGAN
CycleGAN, ESRGAN, Pix2Pix, ProGAN, SRGAN, StyleGAN 등등....
목표는 GAN에 대한 여러가지 기법을 구현해보고 내 벨로그에 모두 올리는 것이다.
GAN에 관심을 가지고 공부하고 싶어하는 사람들에게 도움이 되고싶다...ㅎㅎ
다음은 아마 DCGAN과 StyleGAN, 그리고 요즘 공부하는 SinGAN에 대해서 업로드할 예정이다.
기대하시라~~!~!
