
Introduction
이전 글에서 DCGAN의 논문 리뷰를 했다.
논문 읽기 및 구현(1) - DCGAN
이번에는 직접 DCGAN을 만들어보고 MNIST 데이터셋으로 학습시킨 후에 SimpleGAN과 비교해 볼 것이다.
Discriminator
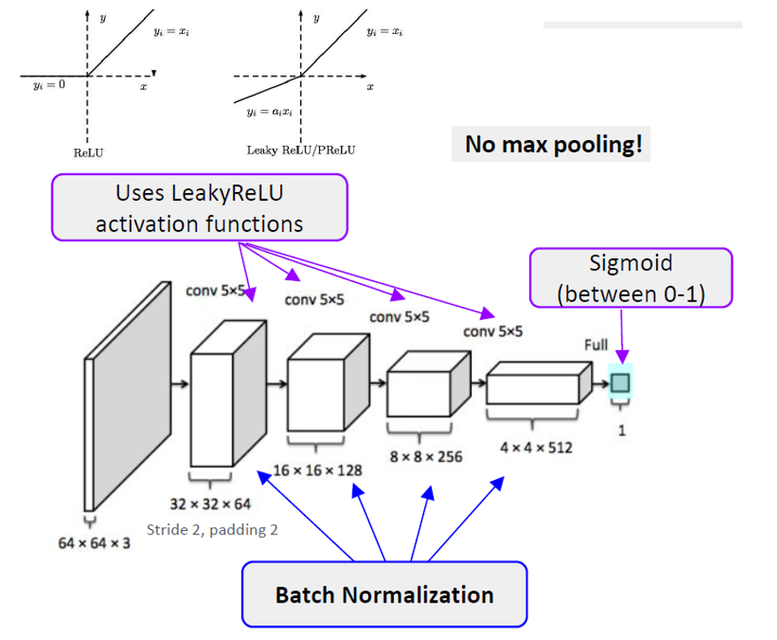
class Discriminator(nn.Module):
def __init__(self, channels_img, features_d):
super(Discriminator, self).__init__()
self.disc = nn.Sequential(
# input : N x channels_img x 64 x 64
nn.Conv2d(
channels_img, features_d, kernel_size=4, stride=2, padding=1 # N x features_d x 32 x 32
),
nn.LeakyReLU(0.2),
# _block(in_channels, out_channels, kernel_size, stride, padding)
self._block(features_d, features_d * 2, 4, 2, 1), # N x features_d * 2 x 16 x 16
self._block(features_d * 2, features_d * 4, 4, 2, 1),
self._block(features_d * 4, features_d * 8, 4, 2, 1), # N x features_d * 8 x 4 x 4
# After all _block img output is 4x4 (Conv2d below makes into 1x1)
nn.Conv2d(features_d * 8, 1, kernel_size=4, stride=2, padding=0),
nn.Sigmoid(),
)
def _block(self, in_channels, out_channels, kernel_size, stride, padding):
return nn.Sequential(
nn.Conv2d(
in_channels,
out_channels,
kernel_size,
stride,
padding,
bias=False,
),
nn.BatchNorm2d(out_channels),
nn.LeakyReLU(0.2),
)
def forward(self, x):
return self.disc(x)__init__
-
channels_img: 64 x 64 이미지 -
features_d: 첫 layer에서 나오는 features의 dim -
Discriminator의 input layer에는 BatchNorm을 사용하지 않기 때문에 따로 Conv를 만든다
-
Discriminator의 모든 layer에 LeakyReLU를 사용한다 leak값은 0.2
-
output의 마지막은 Sigmoid를 사용해야하기 때문에
N x features_d * 8 x 1 x 1 의 크기로 만든다.
_block
- Conv - BatchNorm - LeakyRelu를 하나의 함수로 모듈화
아주 심플하다
Generator
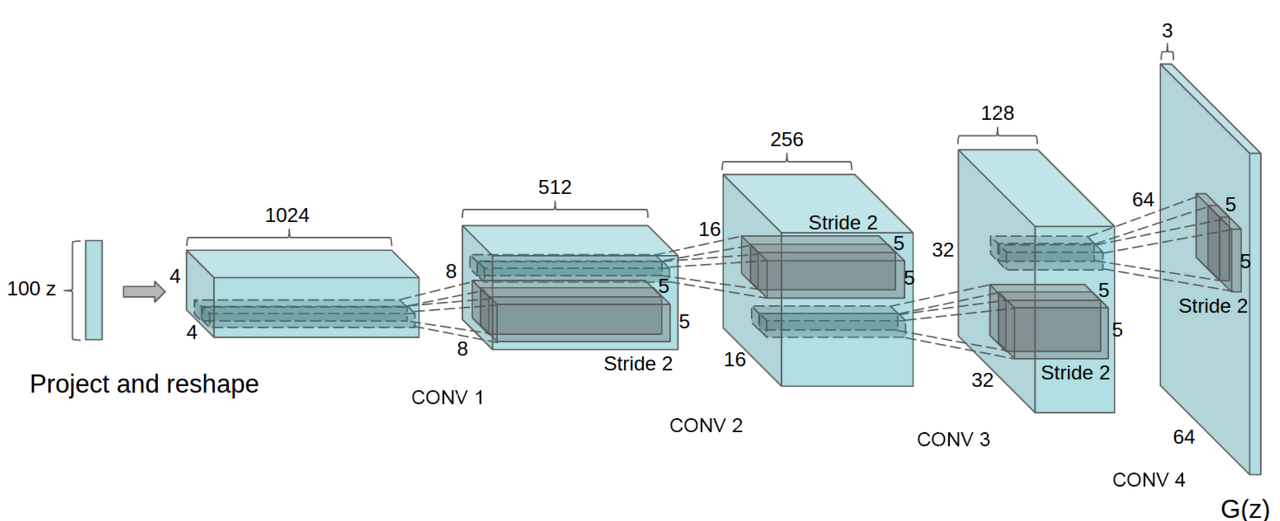
class Generator(nn.Module):
def __init__(self, channels_noise, channels_img, features_g):
super(Generator, self).__init__()
self.net = nn.Sequential(
# Input: N x channels_noise x 1 x 1
self._block(channels_noise, features_g * 16, 4, 1, 0), # img: 4 x 4
self._block(features_g * 16, features_g * 8, 4, 2, 1), # img: 8 x 8
self._block(features_g * 8, features_g * 4, 4, 2, 1), # img: 16 x 16
self._block(features_g * 4, features_g * 2, 4, 2, 1), # img: 32 x 32
nn.ConvTranspose2d(
features_g * 2, channels_img, kernel_size=4, stride=2, padding=1
),
# Output: N x channels_img x 64 x 64
nn.Tanh(),
)
def _block(self, in_channels, out_channels, kernel_size, stride, padding):
return nn.Sequential(
nn.ConvTranspose2d(
in_channels,
out_channels,
kernel_size,
stride,
padding,
bias=False,
),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
)
def forward(self, x):
return self.net(x)__init__
-
channels_noise: input noise의 z값 -
Input: N x channels_noise x 1 x 1
-
Fractionally-strided convolution을 위해 `
nn.ConvTranspose2d를 사용한다. -
Generator의 output layer에는 BatchNorm을 사용하지 않기 때문에 따로 ConvTranspose를 만든다
-
Output: N x channels_img x 64 x 64
-
Generator의 output에는 Tanh를 사용한다.
_block
- ConvTranspose - BatchNorm - ReLU를 하나의 함수로 모듈화
위의 그림을 그대로 구현하면 된다.
가중치 초기화
def initialize_weights(model):
# Initializes weights according to the DCGAN paper
for m in model.modules():
if isinstance(m, (nn.Conv2d, nn.ConvTranspose2d, nn.BatchNorm2d)):
nn.init.normal_(m.weight.data, 0.0, 0.02) # mean 0, std 0.02
initialize_weights
-
for문을 돌면서 isinstance로 Conv, ConvTranspose, BatchNorm이 있으면 가중치를 초기화 해준다
-
평균 0, 표준편차 0.02
학습
하이퍼파라미터
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
LEARNING_RATE = 2e-4 # could also use two lrs, one for gen and one for disc (0.001)
BATCH_SIZE = 128
IMAGE_SIZE = 64
CHANNELS_IMG = 1
NOISE_DIM = 100
NUM_EPOCHS = 10
FEATURES_DISC = 64
FEATURES_GEN = 64자세한 설명은 생략한다.
데이터 setting
transforms = transforms.Compose(
[
transforms.Resize(IMAGE_SIZE),
transforms.ToTensor(),
transforms.Normalize(
[0.5 for _ in range(CHANNELS_IMG)], [0.5 for _ in range(CHANNELS_IMG)]
),
]
)
# If you train on MNIST, remember to set channels_img to 1
dataset = datasets.MNIST(root="./dataset/", train=True, transform=transforms,
download=True)- dataset에 MNIST데이터를 다운하고 transforms으로 전처리를 해준다.(Resize, Tensor화, Normalization)
학습 준비
dataloader = DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True)
gen = Generator(NOISE_DIM, CHANNELS_IMG, FEATURES_GEN).to(device)
disc = Discriminator(CHANNELS_IMG, FEATURES_DISC).to(device)
initialize_weights(gen)
initialize_weights(disc)
# in the paper, it is stable when B1 is 0.5 than 0.9
opt_gen = optim.Adam(gen.parameters(), lr=LEARNING_RATE, betas=(0.5, 0.999))
opt_disc = optim.Adam(disc.parameters(), lr=LEARNING_RATE, betas=(0.5, 0.999))
criterion = nn.BCELoss()
fixed_noise = torch.randn(32, NOISE_DIM, 1, 1).to(device)
writer_real = SummaryWriter(f"./runs/DCGAN_MNIST/real")
writer_fake = SummaryWriter(f"./runs/DCGAN_MNIST/fake")
step = 0
# BN, Dropout Train mode
gen.train()
disc.train()-
DataLoader로 batch를 만들어준다.
-
Generator와 Discriminator를 변수로 선언해준다음 위의 함수를 사용하여 가중치를 초기화한다.
-
Optimizer는 Adam으로하고 논문 내용에서 Momentum β1이 0.9일 때 학습이 불안정하고 0.5일 때 안정적이라 했으므로 설정해준다.
-
Loss는 Binary cross entropy
-
tensorboard로 loss값과 step당 이미지를 보기위해
fixed_noise로 noise값을 만들고, SummaryWriter로 기록 할 준비를한다. -
pytorch 특성 상 BatchNorm 혹은 Dropout이 있기에 train모드로 해준다.
학습
for epoch in range(NUM_EPOCHS):
# Target labels not needed! ~~ unsupervised
for batch_idx, (real, _) in enumerate(dataloader):
real = real.to(device)
noise = torch.randn(BATCH_SIZE, NOISE_DIM, 1, 1).to(device)
fake = gen(noise)
### Train Discriminator: max log(D(x)) + log(1 - D(G(z)))
disc_real = disc(real).reshape(-1)
lossD_real = criterion(disc_real, torch.ones_like(disc_real))
# fake.detach() <--
disc_fake = disc(fake.detach()).reshape(-1)
lossD_fake = criterion(disc_fake, torch.zeros_like(disc_fake))
lossD = (lossD_real + lossD_fake) / 2
disc.zero_grad()
lossD.backward()
opt_disc.step()
### Train Generator: min log(1 - D(G(z)) <-> max log(D(G(z))
output = disc(fake).reshape(-1)
lossG = criterion(output, torch.ones_like(output))
gen.zero_grad()
lossG.backward()
opt_gen.step()
# Print losses occasionally and print to tensorboard
if batch_idx % 100 == 0:
print(
f"Epoch [{epoch}/{NUM_EPOCHS}] Batch {batch_idx}/{len(dataloader)} \
Loss D : {lossD:.4f}, loss G: {lossG:.4f}"
)
with torch.no_grad():
fake = gen(fixed_noise)
# take out (up to) 32 examples
img_grid_real = torchvision.utils.make_grid(
real[:32], normalize=True
)
img_grid_fake = torchvision.utils.make_grid(
fake[:32], normalize=True
)
writer_real.add_image("Real", img_grid_real, global_step=step)
writer_fake.add_image("Fake", img_grid_fake, global_step=step)
step += 1-
학습 코드는 이전 GAN코드 구현과 동일하다
-
하지만 차이는
disc_fake = disc(fake.detach()).reshape(-1)이다.detach()는 우선적으로 fake를 복제하는데 Tensor의
requires_grad를 False로 만든다.
처음 D만을 학습시켜야 해서 G가 backpropagation이 되지 않도록 해야한다.
fake변수의 requires_grad를 False로fake = gen(noise)의 grad를 None으로 만들어 G의 backpropagation을 막는다.
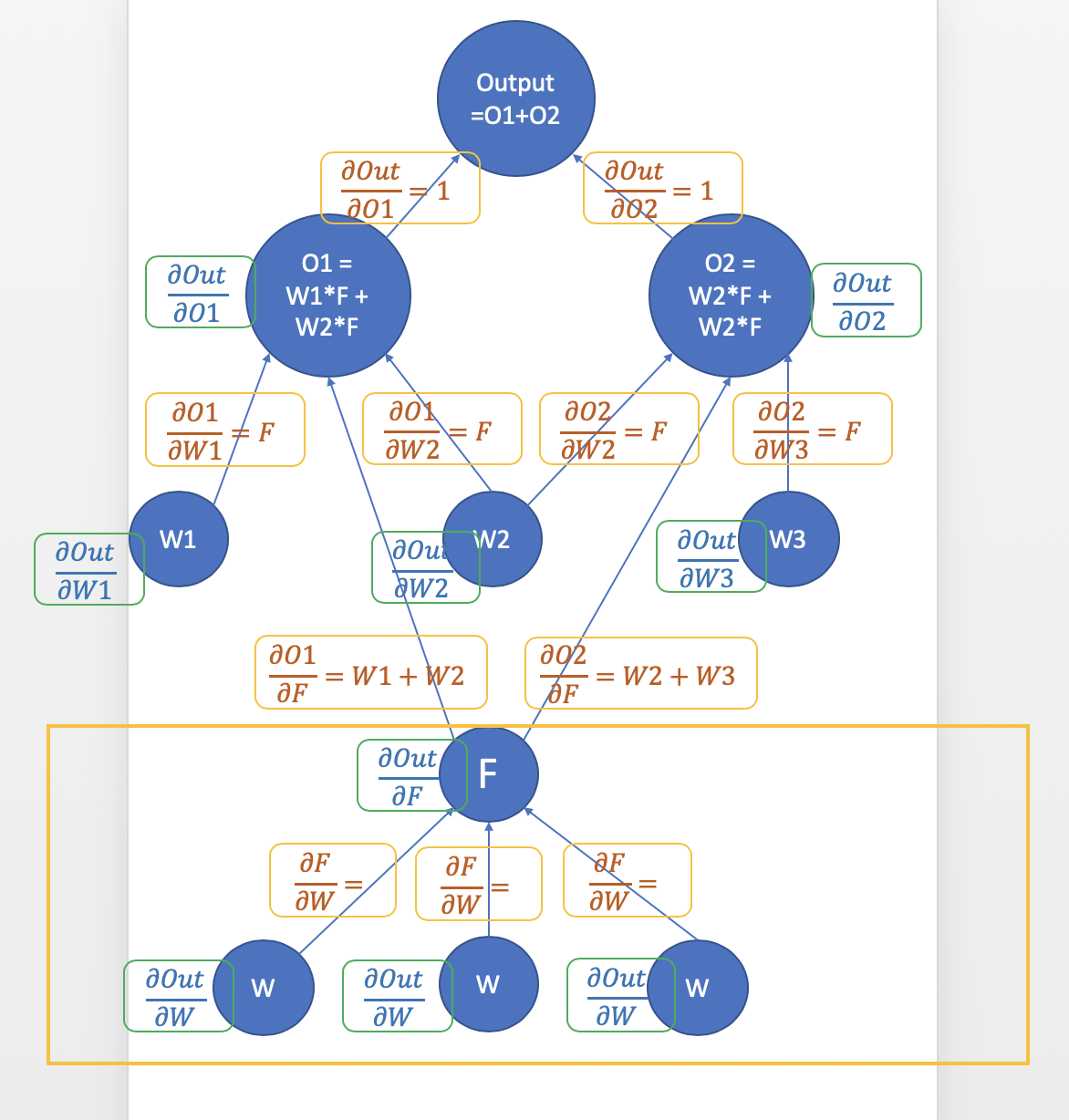
노란색 박스 부분이 빠짐 -
Discriminator를 학습한 후에 Generator를 학습하며, batch_idx를 100단위로 끊어 Loss를 출력해준다.
-
이와 동시에 tensorboard에 학습 상황을 보기 위해 만들어 두었던, fixed_noise(32개의 noise)를 gen을 사용해 생성한다.
학습 결과
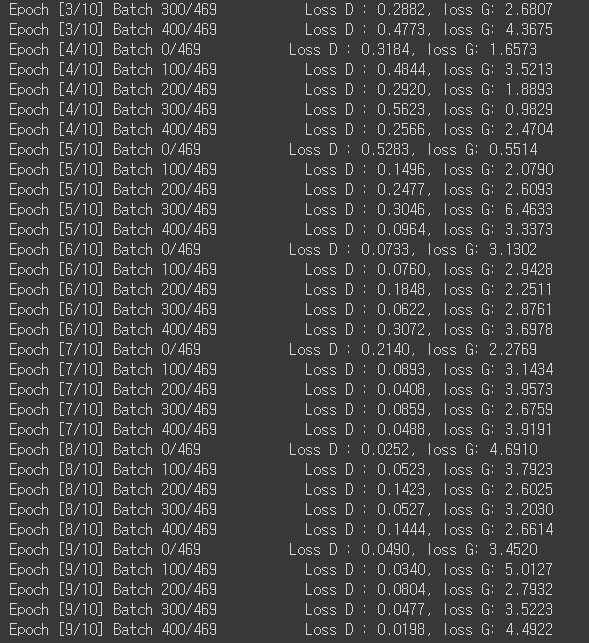
- 총 10 epochs를 돌렸다.
Tensorboard로 확인해본 결과

- 기존의 SimpleGAN과 비교했을 때, 성능이 확실히 좋아진 것을 알 수 있다.

latent z값을 변경하였을 때 생성되는 이미지가 어떻게 변하는지에 대한 코드는 아주 쉬우니 직접 생각해서 구현해보고 시험 해 보자.
