
Introduction
논문 읽기 및 구현(1) - GAN
논문 읽기 및 구현(2) - GAN
이전 글에서 GAN의 이론적 내용과 코드 리뷰를 했다.
이번에는 GAN을 활용한 논문을 리뷰해본다. 가장 기본적인 GAN 논문인 DCGAN - Deep Convolutional Generative Adversarial Nets (ICLR 2016)의 내용을 보고 코드 실습을 해보자.
- CNN을 활용한 비지도학습으로 지도 학습과 비지도 학습의 차이를 줄인다.
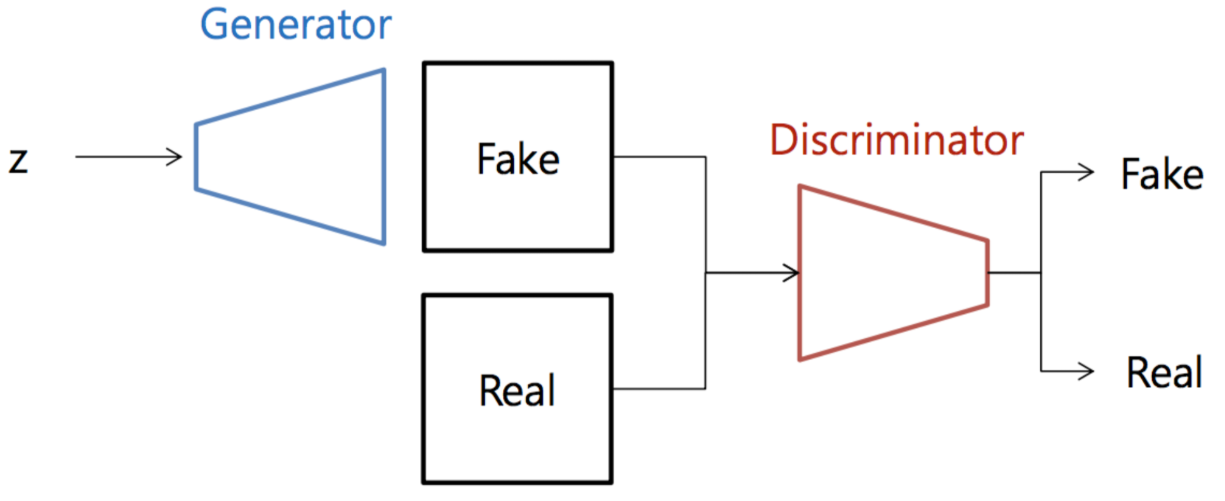
Simple GAN의 문제점
-
샘플에 blur가 되거나, 이해할 수 없는 이미지 생성 등, GAN의 결과가 불안정하다.

저번의 실습처럼 단순 신경망으로 구성한 GAN은 성능이 좋지 않았다.CIFAR-10과 같은 복잡한 영상에 대해서는 성능이 좋지 않다는 것을 확실히 알 수 있다.
-
Black-Box
사람이 사용할 수 있는 알고리즘 형태에서 네트워크가 어떻게 동작하는지 이해하기 어렵다. 이는 Neural Network 자체의 한계이기도 하다.
DCGAN에서 이루고자 하는 과제
- 논문 저자는 기존 SimpleGAN의 문제를 해결하기 위해, CNN을 적용하여 다양한 구조에 대한 실험을 하였고, 최적이라고 생각 되는 구조를 찾아냈다.
- DCGAN 이후 발표된 논문들 대부분 이 구조를 사용하고있다.
- 입력 데이터로 사용하는 input noise Z에 대한 의미를 발견했다.
- Generator의 입력으로 들어가는 z값을 살짝 바꾸면, 생성되는 이미지가 그것에 감응하여 살짝 변하게 되는 vector arithmetic의 개념을 찾아냈다.
- 논문에서는 z의 변동에 따른 Generate결과가 연속적으로 부드럽게 이루어져야 한다고 한다.
DCGAN 구조
기존 GAN의 모습은 Fully-connected로 연결 되어 있다.
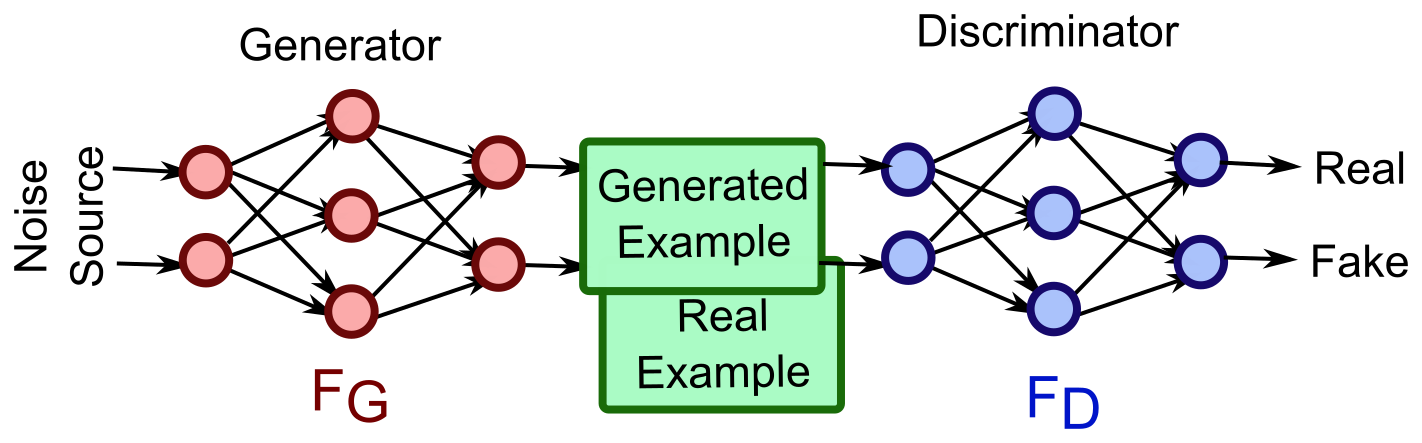
Generator
DCGAN은 다음과 같은 구조를 가진다.

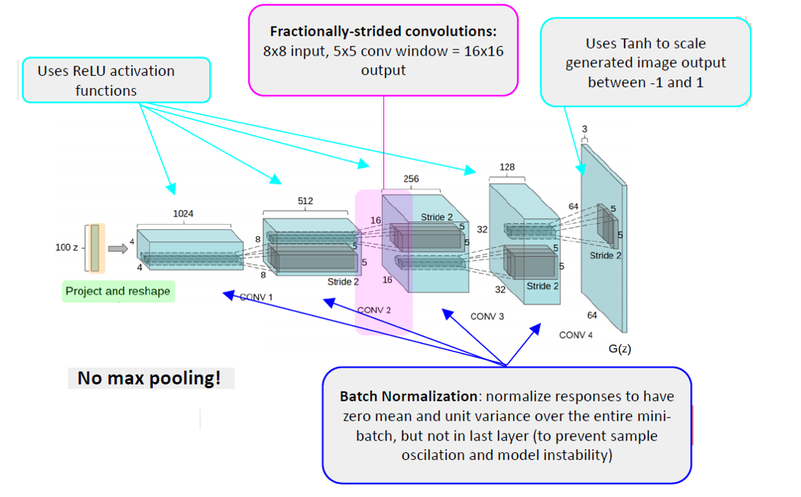
- 모든 max pooling layer를 Convolutional stride, fractionally-strided convolution으로 변환하여 feature-map의 크기를 조절
- Batchnorm 적용 (Generator의 output layer와 Discriminator의 input layer 제외)
- Fully connected layer 제거
- Generator의 output에는 Tanh를 사용하고, 나머지는 ReLU를 사용
- Discriminator의 모든 layer에 LeakyReLU를 사용
추가로 모델 튜닝에 대해서 아래와 같이 논문에서 소개한다.
- 128 size의 mini-batch를 SGD로 학습
- 모든 weights의 mean값은 zero-centered, std는 0.02로 초기화
- LeakyReLU의 leak은 0.2로 설정
- Optimizer는 Adam 사용.
- Learning rate는 Generator, Discriminator 2개가 쓰이며 0.001, 너무 높다면 0.0002를 사용
- Adam사용시 Momentum 이 0.9일 때 학습이 불안정하고 0.5일 때 안정적
All models were trained with mini-batch stochastic gradient descent (SGD) with a mini-batch size of 128. All weights were initialized from a zero-centered Normal distribution with standard deviation 0.02. In the LeakyReLU, the slope of the leak was set to 0.2 in all models. While previous GAN work has used momentum to accelerate training, we used the Adam optimizer with tuned hyperparameters. We found the suggested learning rate of 0.001, to be too high, using 0.0002 instead. Additionally, we found leaving the momentum term β1 at the suggested value of 0.9 resulted in training oscillation and instability while reducing it to 0.5 helped stabilize training.
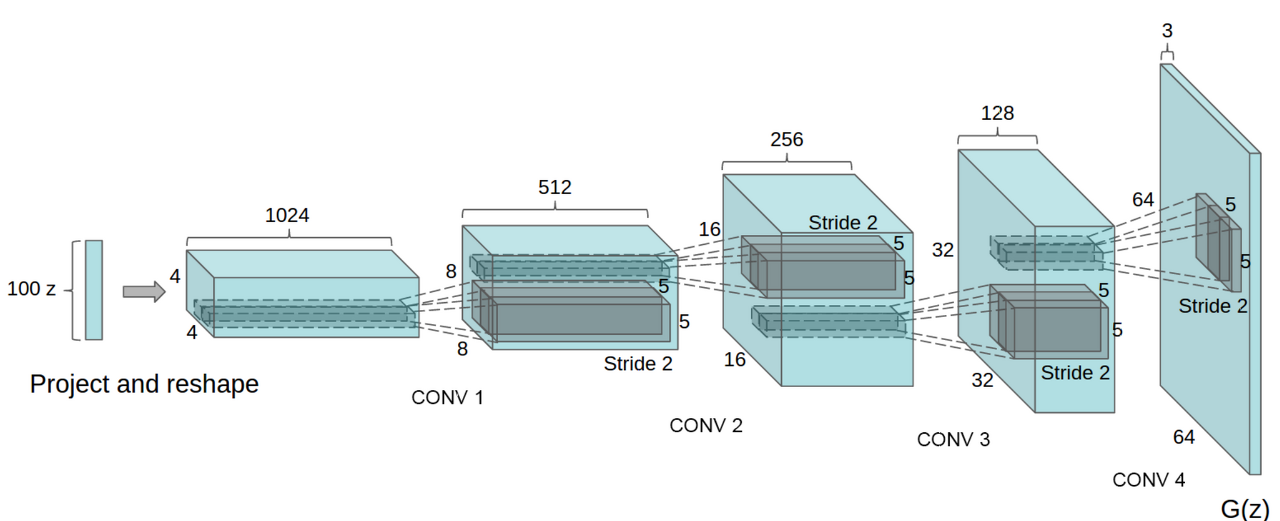
위 그림은 최적의 Generator구조이며, random input을 받아들여, Discriminator에서 사용할 수 있는 image를 생성해야하기 때문에 64x64 크기의 컬러 image가 나와야 한다.
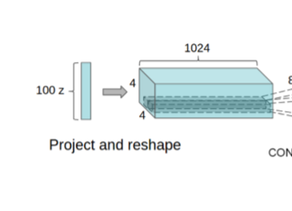
입력으로 사용하는 latent variable이 "가로X세로"의 형태가 아니기 때문에, CNN 연동을 위해 image feature-map 형태로 변형시킬 수 있는 "Project and reshape" Block이 필요하다.
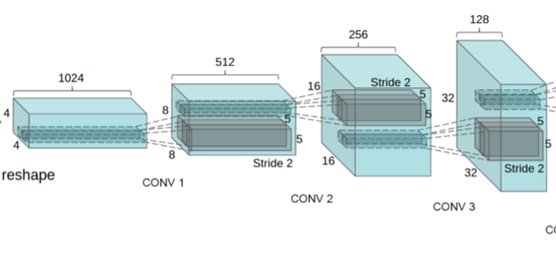
feature-map의 크기가 작아지는 일반적인 CNN과 다르게 크기를 키워야 한다. 그래서 fractionally-strided convolution이 필요하다.
Fractionally-strided convolution
Strided convolution
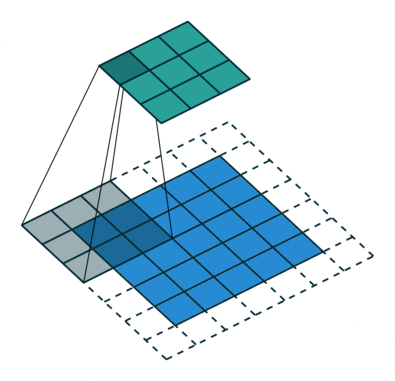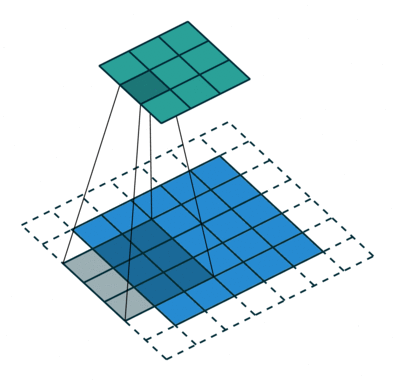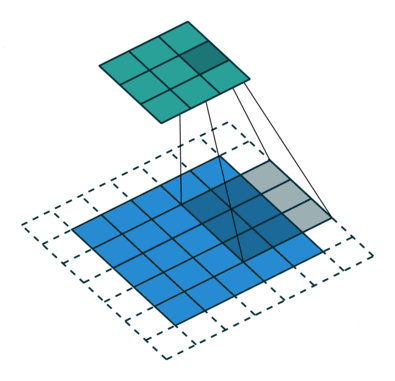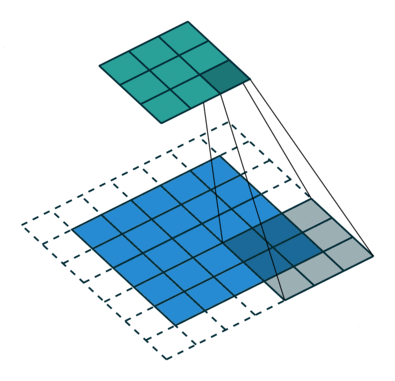
Fractionally-strided convolution
![]()
- 기존의 Stride는 필터를 거치며 크기가 작아진다.
- 반면 Fractionally-strided convolutions은 input에 padding을 하기 때문에 오히려 크기가 더 커진다. 이를 Transposed convolution이라고 불린다.
코드 리뷰때 Generator model은
nn.ConvTranspose2d를 사용한다.
종합
Discriminator
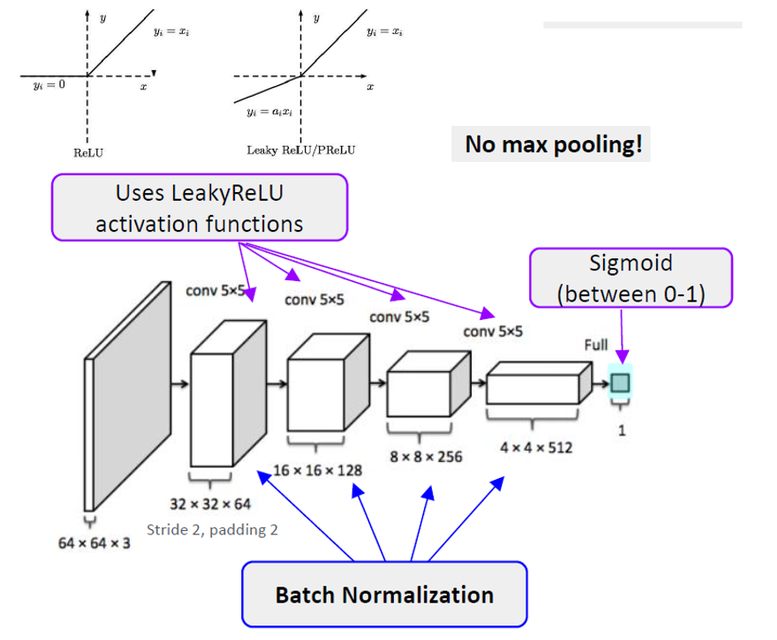
Discriminator는 64 X 64의 image를 입력 받아 CNN을 거쳐 Sigmoid에서 진짜 혹은 가짜를 판별한다.
학습
저자는 LSUN, ImageNet-1K, Face dataset을 이용하여 학습을 했다.
- 5-pass를 거친 후 생성 이미지

Latent 변수 z의 변화
생성 모델 연구에서 중요한 핵심은 다음과 같다.
1. Generator가 이미지를 단순히 외우는 것이 아니라 특징들을 학습해서 생성한다는 것을 보여줘야 한다.
2. Generator의 input 공간인 latent z의 변화에 대해 결과의 급작스런 변화가 아닌 부드러운 변화를 보여야 한다.
Generator가 이미지를 외웠다는 것은 overfitting으로 training data와 z의 1:1 매핑을 했다는 의미이다.
이는 z의 변화에 대해서 부드러운 변화(일부 특징의 변화)가 아닌 급작스런 변화(아예 다른 데이터와의 매핑)를 보인다.

- 학습 후에 latent 변수 z 값을 조금씩 변화시켜보면, 생성 이미지가 조금씩 달라진다.
- 마지막 사진은 텔레비전에서 서서히 창문으로 변하는 것을 볼 수 있다.
Discriminator로 얻은 특징에 대한 시각화

- 그림처럼 각각 filter들이 침대나 창문과 같이 침실의 일부분을 학습할 수 있다는 것을 알 수 있다.
Vector arithmetic

- 학습을 통해서 얻어진 z 값을들 이용한 vector arithmetic이 가능하다는 사실을 발견했다.
- 단어들에 대한 representation을 벡터 공간에 매핑시키면 linear arithmetic이 가능하다는 것을 알 수 있다.
DCGAN 정리
DCGAN은 새로운 이론에서 얻어진 것은 아니지만, 성능을 높이는데에 큰 역할을 했다.
- 안정적인 학습과 성능이 뛰어난 Convolutional GAN 구조 제안했다.
- Generator가 벡터 산술 연산이 가능하다. (word2vec과 같은 성질)
- Unsupervised learning을 통해 학습된 discriminator가 image의 정보를 잘 파악하며 좋은 성능을 보인다.
다음에는 코드 리뷰를 해본다.
