공모전에 참여한 후기를 나의 시점에서 일기처럼 작성해보면 좋을 것 같아서 정리하여 올려보았다. 분석의 내용적측면이 아닌 분석의 방법론적 측면에서 서술한 것이다.
팀 빌딩
부트캠프에서 프론트엔드 공부를 마치고 복학하기전에 뭐를 할까를 고민하다가 두가지 목표를 세웠는데 그것이 ADsP 자격증 취득과 공모전 참여해보기였다. 우선 내 주변에 아는 사람중에 그래도 데이터 관련 공부를 해본사람이 한명 뿐이라 그 친구와 하게되었다.
R 공부
우리가 할 줄 아는 언어는 파이썬과 sql 정도 였는데 파이썬은 이전에 공부할 때에 데이터 전처리 과정이 너무 힘들었던 기억이 있었고, sql은 완전 기본적인 수준이었어서 시각화에 특화된 R을 한번 사용해보자고 했다. 아예 모르는 언어였기 때문에 어떻게 공부할까 하다가 우선 책을 같이 사서 공부를 하기로 하였고, 이전에 프론트엔드 시작할때 Do it! 시리즈로 편하게 공부했던 기억이 있어서 이번에도 "Do it! 쉽게 배우는 R 데이터 분석"으로 공부를 하였다.

알라딘에서 만원에 싸게 구입하여 공부를 하였는데 기초를 다지기에는 충분하였다. 예시 코드들이 충분히 많아 충분한 연습이 되었고, 원하던 시각화 부분도 상세하게 나와있어 좋았다.
주제 선정
미래 사회문제는 워낙 많아서 주제로 할만한 것들은 많았지만, 너무 많은 데이터를 사용하는 것은 우리의 수준에서 힘들기 때문에 데이터의 갯수가 적당한 것들 중에 골랐다. 그 주제가 바로 "지역별 불균형에 따른 지방 소멸화 대책 방안의 효과성 검토" 였다. 과거에 비슷하게 대학교 수업에서 "서울시 청소년 주거 환경 분석"(논문)이라는 주제로 학술대회에 논문을 낸적이 있었는데, 그때 당시에는 sql로 시각화는 안하고 숫자값으로만 결과를 도출하였고, 오직 서울특별시에 국한되게 데이터를 구해 한 것이었는다. 이번에는 sql 대신 R을 이용하고, 시각화를 해 피피티 형식으로 만들고, 전국의 데이터를 시군구로 분류하여 데이터를 수집하였다.
데이터 수집
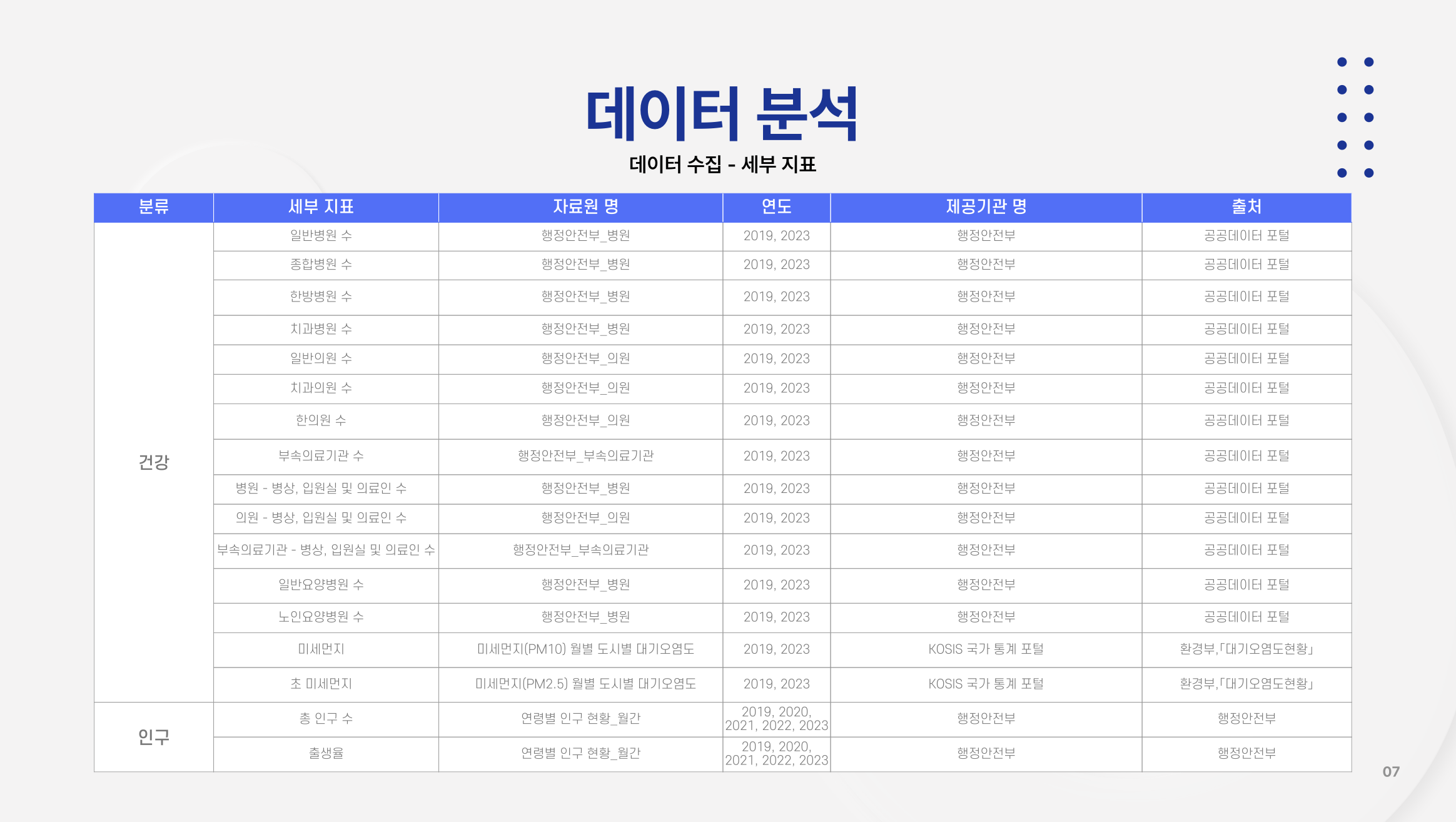
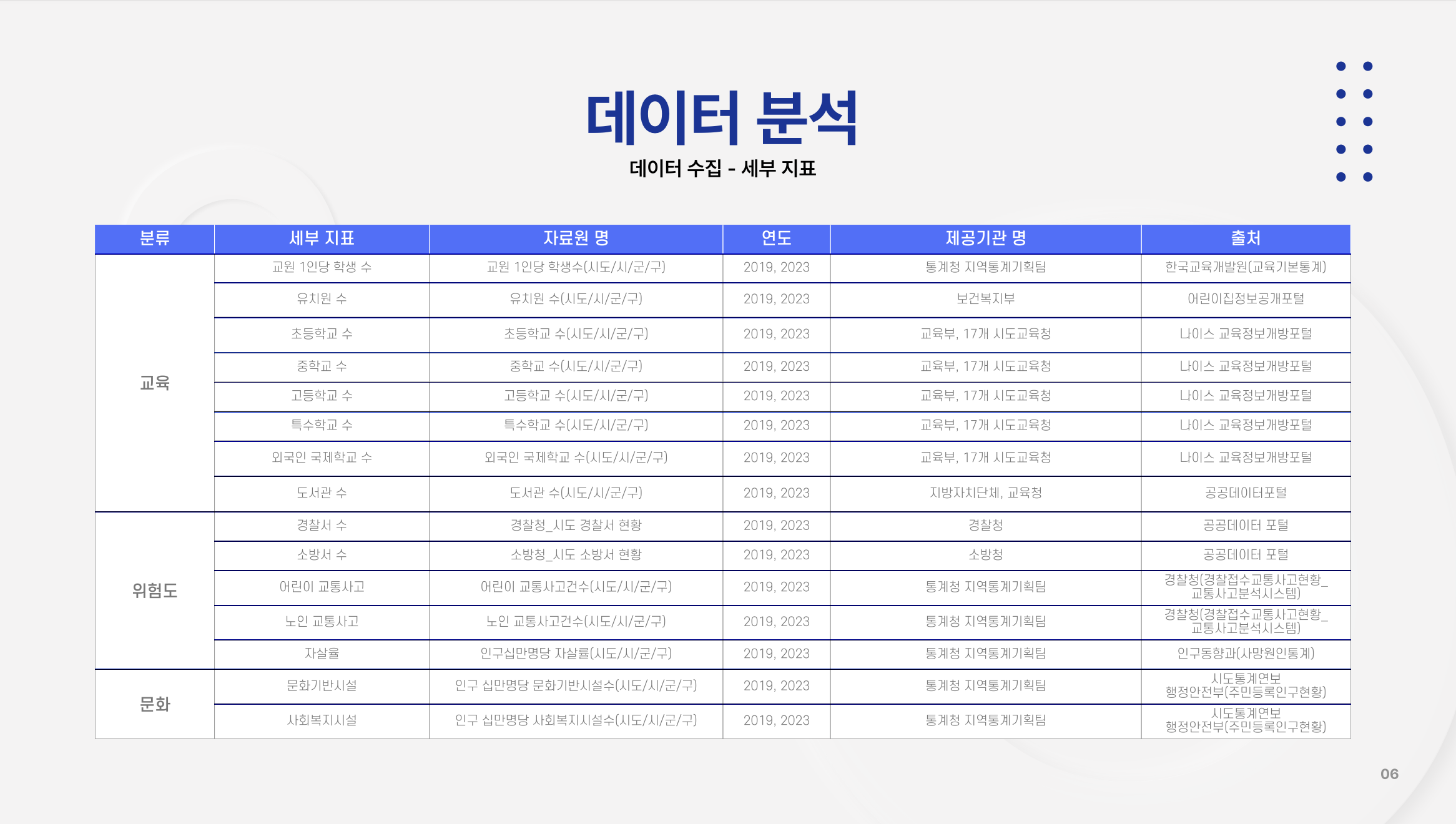
데이터 수집은 올바른 데이터를 가져오는데 오래 걸리기 때문에 몇 개씩 나누어서 찾았다. 나는 교육과 인구와 관련된 데이터를 찾았고, 팀원은 건강, 문화와 위험도의 데이터를 찾았다.
데이터 전처리
이게 가장 오래 걸린 작업이 아닌가 싶다. 우선 가장 먼저 어떤 기준으로 도시를 나눌 것인가를 정해야 했는데, 시군구를 기준으로 하기로 하였다. 그다음 모든 데이터를 시군구를 기준으로 분류를 해야 했는데, 여기서 엄청난 난관을 겪었다. 데이터들 중 상당수가 시군구로 분류되어있지 않아서 직접 도로명주소에서 시군구 값을 추출해야 했고, 있다고 하더라도 각각 표시하는 방법이 다른 경우도 있었고, 명칭이 다른 경우도 있었다. 우리 팀은 우선 하나하나 처리를 해보기로 했다.
1) 도로명 주소에서 시군구값 추출하기
우리의 목표는 '경기도 용인시 수지구'나 '서울특별시 강동구' 혹은 '경상남도 하동군'처럼 시군구 값을 나오게 하는게 목표였다. 그것을 위해서 도로명 주소에서 도 시 군 구 값을 있는데로 뽑아 값이 있는것들을 다 띄어쓰기와 함께 순서대로 합쳐주었다.
병원 <- 병원 %>%
mutate(도로명전체주소 = ifelse(is.na(도로명전체주소), 소재지전체주소, 도로명전체주소)) %>%
mutate(
도 = str_extract(도로명전체주소, "([가-힣]+도)(?![가-힣0-9\\(])"),
시 = str_extract(도로명전체주소, "([가-힣]+시)(?![가-힣0-9\\(])"),
군 = str_extract(도로명전체주소, "([가-힣]+군)(?![가-힣0-9\\(])"),
구 = str_extract(도로명전체주소, "([가-힣]+구)(?![가-힣0-9\\(])")
) %>%
mutate(
구 = ifelse(시 == "대구광역시", str_extract(도로명전체주소, "(?<=대구광역시[[:space:]])([가-힣]+구)"), 구)
)
병원 <- 병원 %>% unite(시군구, 도, 시, 군, 구, sep = " ", na.rm = TRUE)2) 표시하는 방법이 다른경우
해결 방법이 두 개정도 있을 수 있는데 엑셀로 데이터 자체를 변형시키거나, r로 받아온 데이터프레임에서
ifelse문을 이용해서 바꾸거나 인데 r로 하면 다시 데이터를 받아올때마다 해당 작업을 다시 해야 하므로 우리는 엑셀에서 바꾸기 기능을 이용해서 해결하였다.
3) 명칭이 다른경우
이것의 가장 큰 문제점은 우선 원래 쓰려고 했던 지도 시각화(GIS) 라이브러리가 2014년에 만들어진것이라 명칭이 옛날 명칭을 사용하고 있었다. 결국 다른 방법으로 시각화를 했다. 우리가 사용하려고 했던 2018년의 좌표값과 시군구 명칭을 인터넷에서 찾아서 다운해서 ggplot과 rmapshaper에 입혀서 시각화를 하였다.
legend_limits = c(-50, 50)
born_c <- left_join(born2021, born2022, by = "code")
born_c <- born_c %>% mutate(증감율 = (zero.y-zero.x)/zero.x * 100)
pop_map <- read_sf("sig.shp")
pop_map = pop_map |> st_transform(5179)
pop_map = pop_map |>
mutate(SIG_KOR_NM = iconv(SIG_KOR_NM, from = "EUC-KR", to = 'UTF-8'))
pop_map = pop_map |>
ms_simplify(keep = 0.01, keep_shapes = T)
pop_map <- rename(pop_map, code= SIG_CD)
pop_map$code <- as.numeric(pop_map$code)
pop_map <- left_join(pop_map, born_c , by = "code")
ggplot(pop_map) +
geom_sf(aes(fill = 증감율), color = "black") +
scale_fill_gradientn(colors = c("darkred", "white", "darkblue"), guide = "legend", limits = legend_limits) +
theme_minimal() +
theme(legend.title = element_blank())데이터 분석
우리는 도시 인프라와 인구의 상관관계를 분석하려는 것이었기 때문에 다중선형회귀분석을 통해서 어떤 요인이 인구와 상관관계를 잘 나타내는지 찾은 후 그 값에 가중치를 주어 합하여 도시 인프라 종합 지표를 만들었다. 그 후 인구소멸위험지역 89곳과 도시 인프라 종합지표를 비교하여 어떤 도시가 인프라 지표로 보았을 때에 성장하고 있는지를 분석해보았다.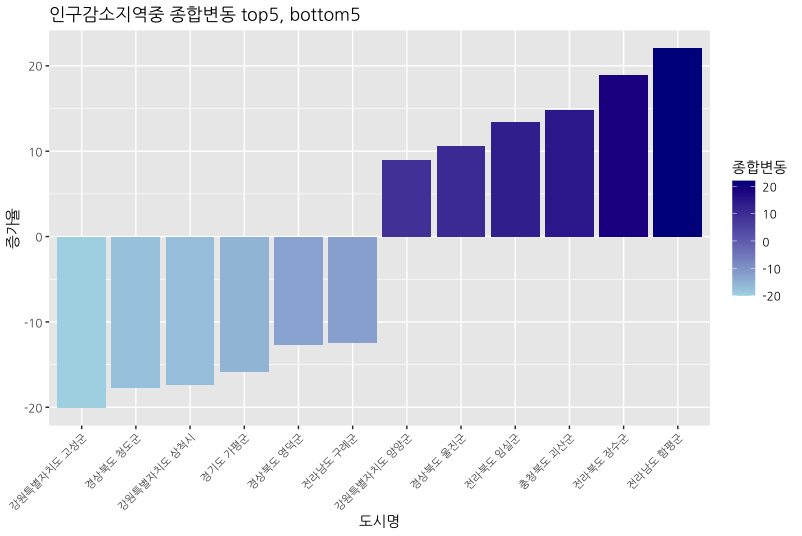
아쉬웠던 점
우선 가장 아쉬웠던 것은 시간관리였던 것 같다. 시작 자체도 원래 계획보다 늦게 시작했는데 전처리 과정에서 내가 기본 코드나 엑셀 정리방식을 정리해서 보내주면 팀원이 본인이 맡은 데이터에 적용하는 식으로 진행했는데 그 시간이 너무 오래 걸려서 데이터 분석을 정말 간단하게 할 수 밖에 없었다.
그리고 팀원과 나 둘다 데이터 분석에 대해 아주 잘 알지는 못하는 상태였기에 데이터 분석도 좀 깔끔하게 안된 것 같아서 아쉽다. 그래도 이번 경험으로 다음번에 공모전 할 때에는 어떻게 해야할지 배운 것 같다.
