
혼공머신을 학습하게된 이유
학부 수업으로 과거에 머신러닝 수업을 들은 적이 있는데, 그때 당시에는 바쁘기도 했고 너무 수학적인 내용과 살인적인 과제량으로 인해 쉬운 부분은 이해를 하고 넘어갔지만, 어려운 부분은 코드만 대~충 작성하고 넘어갔던 것 같다. 그래서 방학기간동안 머신러닝의 기초를 좀 다지고 싶었고, 딥러닝도 배워보고 싶었다. 따로 사람들과 교류하며 하는 스터디는 방학 때에 시간이 그정도는 안되어서 포기할까 하다가 매주 과제만 작성하고 책의 저자에게 직접 질문도 할 수 있는 라이트한 스터디인 혼공 학습단을 발견하고 좋은 기회라고 생각해서 해보게 되었다.
Chapter 1 나의 첫 머신러닝
처음에 기본적으로 인공지능과 머신러닝이 무엇인지에 대해 설명하고 코랩을 어떻게 이용하는지 알려준다음 가장 기본적인 알고리즘인 k-최근접 이웃 알고리즘에 대해 설명이 되어있다.
코랩을 어떻게 사용하는지는 과거에 배워 금방 넘어갔고, knn도 과거에 굉장히 쉽게 이용하던 알고리즘이라 기억이 났다.
knn(k-최근접 이웃 알고리즘)
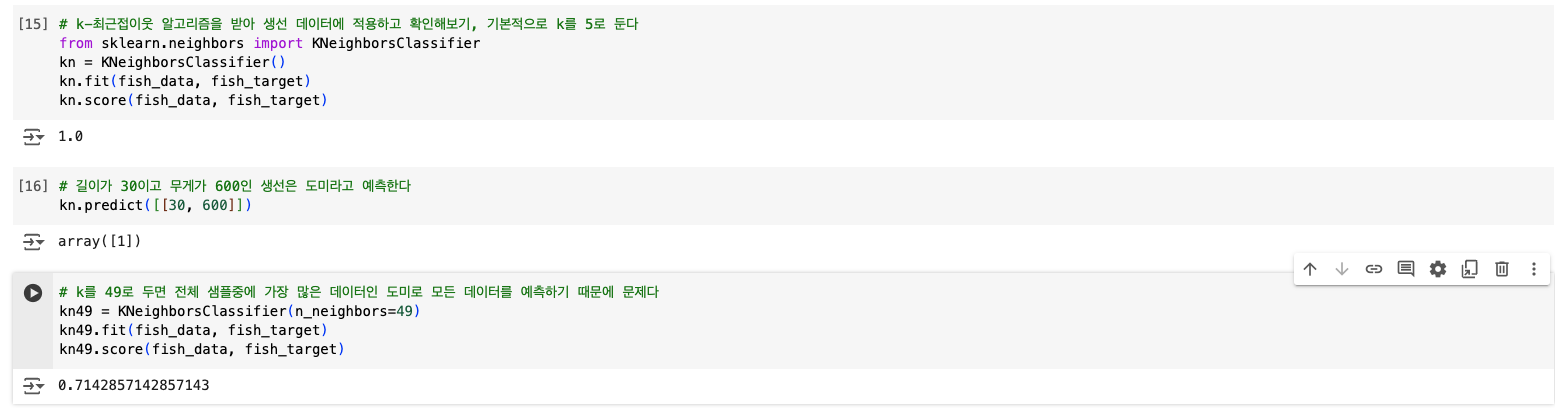
아주 간단하게 k-최근접 이웃 알고리즘은 주변에 값이 비슷한 데이터들로 판단하고 싶은 데이터가 무엇인지 판별하는 알고리즘이다. 여기서 k는 가장 가까운 데이터 몇 개를 확인 할 것인가를 설정하는 것이다. 데이터간의 거리를 모두 판별해야 하기 때문에 데이터가 조금만 늘어나도 속도가 확 느려지는 알고리즘이다.
Chapter 2 데이터 다루기
훈련 데이터와 테스트 세트
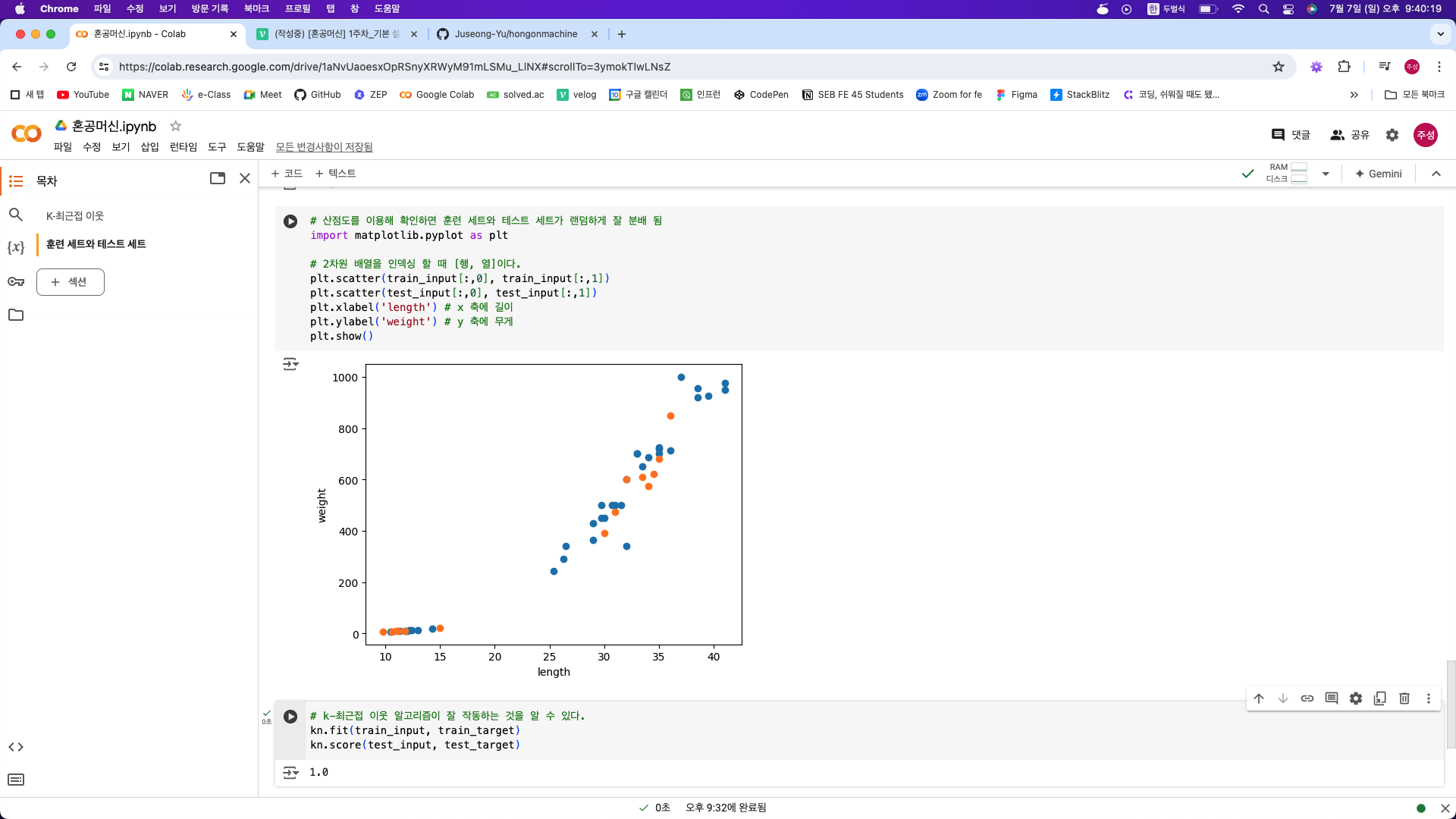
훈련 데이터와 테스트 세트가 동일하면 사실 알고리즘을 돌리는 의미가 없기 때문에 훈련 데이터와 테스트 데이터를 분리하여 사용한다. 데이터를 분할 할 때에 데이터가 편향되면 모델의 훈련에 문제가 생기기 때문에 데이터를 잘 분리하여 훈련 데이터와 테스트 데이터에 넣어 주는 것이 중요하다.
데이터 전처리
책에서 나온 전처리는 거리 기반 알고리즘을 사용할 때에 데이터를 표현하는 기준이 다른 경우 이용하는 데이터 전처리 방법으로 평균점수라는 것을 제시하였다.
평균점수 = (특성값 - 평균) / 표준편차
과제
1. 코렙 실습 화면 캡처하기
2. 2-1 확인 문제 풀고, 풀이 과정 정리하기
-
머신러닝 알고리즘의 한 종류로서 샘플의 입력과 타깃(정답)을 알고 있을 때 사용할 수 있는 학습 방법은 무엇인가요?
A: 지도 학습
R: 정답을 모르는 경우에는 비지도 학습이지만, 정답을 알고 있는 경우 지도 학습이다. -
훈련 세트와 테스트 세트가 잘못 만들어져 전체 데이터를 대표하지 못하는 현상을 무엇이라고 부르나요?
A: 샘플링 편향
R: 데이터가 한쪽으로 쏠려서 분리되면 샘플링 편향이 나타난다. -
사이킷런은 입력 데이터(배열)가 어떻게 구성되어 있을 것으로 기대하나요?
A: 행 - 샘플, 열 - 특성
R: 행은 엑셀로 치면 가로고 열은 세로이다. 행이 샘플, 열이 특성이다.
