Single Layer Neural Networks
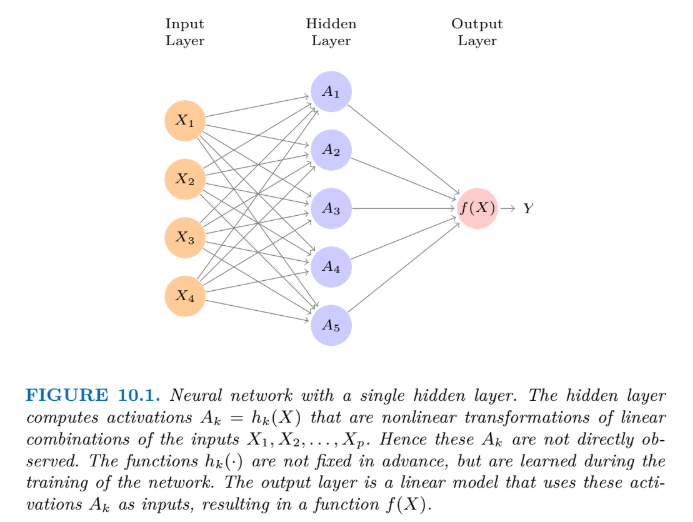
딥러닝을 차근차근 공부해보도록 하자. 먼저 가장 간단한 구조인 Single Layer Neural Network를 먼저 보도록하자.
Single layer neural network의 기본 구조는 위의 사진과 같다. 간단하게 표현하자면, 개의 변수로 이루어진
input vector 를 받고(보통 이것을 Input Layer라고 칭한다), 각 들을 Hidden Layer의 노드로 하나씩 보낸다. 그런 다음 hidden layer의 각 노드에서 activation fuction을 통과시키면 각 노드 들만의 값이 계산되는데, 이 값들의 결합이 가 되는 것이다. 수식으로 표현하면 아래와 같다.
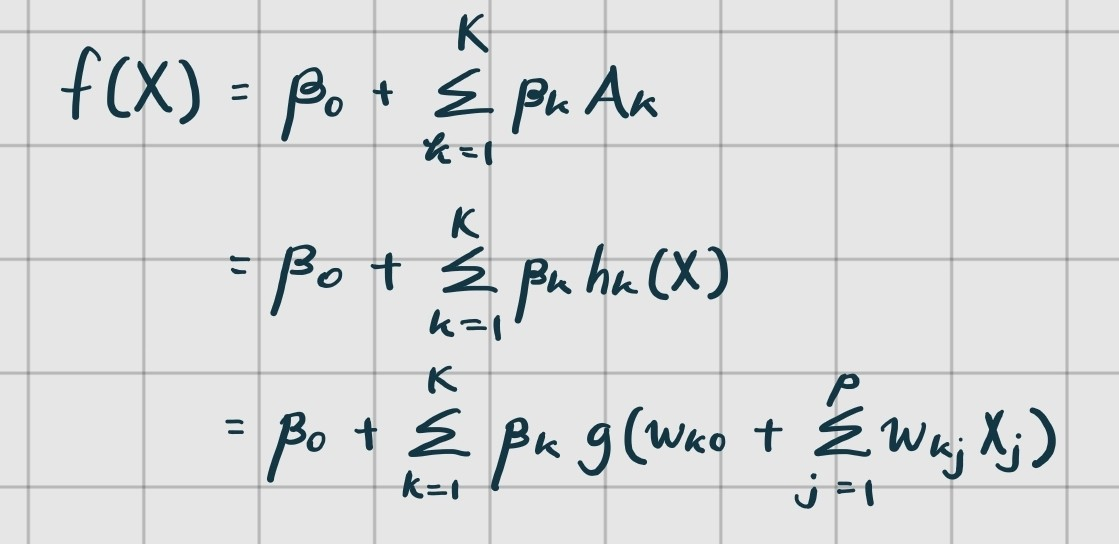
위의 함수식에서 g(z)는 Nonlinear Activation Function이라고 부르며, 어떤 함수를 사용할지 사용자가 정해야한다.
책에서는 다음 두 가지가 소개됐다.
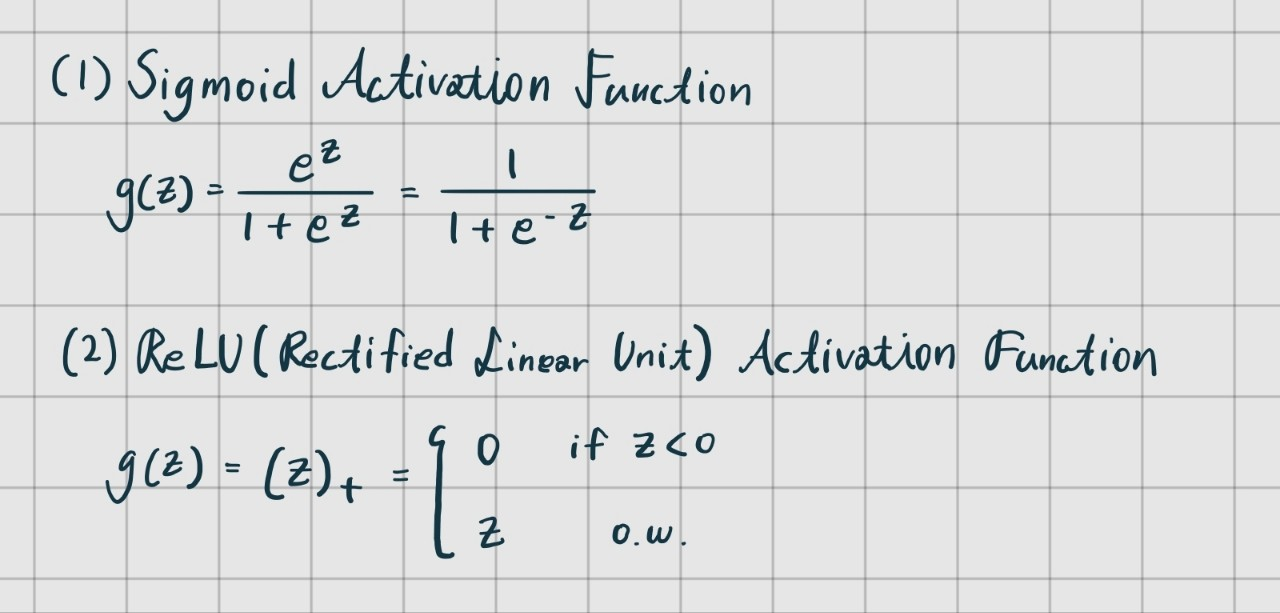
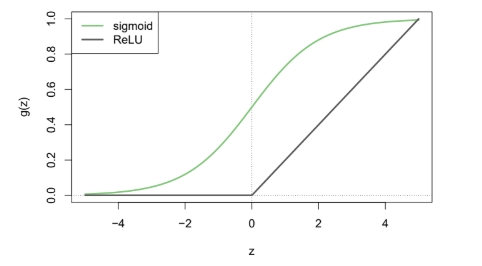
Sigmoid Activation Function은 딥러닝 초기 때 많이 사용됐다하고, 요즘에는 ReLU Activation Function을 많이 사용한다고 한다.
위 함수에서 는 unknown parameter이며 데이터를 통해 estimate해야 한다. 주로 squared-error loss를 이용해 추정한다.
- 책에서 nonlinearity에 대해 조금 강조를 하던데, 잘 이해가 되지 않았다. 이 부분은 추가적으로 공부가 필요하다.
Reference: An Introduction to Statistical Learning: with Applications in Python by Gareth James
질문, 조언 환영합니당 ■

즐겁게 살자