Machine Learning
잘 정의된 Learning Task는 ⟨P, T, E⟩로 표현됨
- 어떤 작업 T에 대해
- 경험 E를 통해
- 성능 P를 향상시키는 알고리즘
— 톰 미첼 교수, 카네기 멜론 대학교(CMU), 1998년
예시
1)
T: 체스를 두는 것
P: 임의의 상대와의 경기에서 승리한 비율
E: 스스로 연습 경기를 하며 학습
2)
T: 시각 센서를 사용하여 고속도로 주행
P: 사람이 판단한 실수가 발생하기 전까지의 평균 주행 거리
E: 운전자를 관찰하면서 기록된 이미지들과 조향 명령 시퀀스
사용 사례
- 인간의 전문 지식이 존재하지 않을 때 (예: 화성에서의 항법)
- 인간이 자신의 전문 지식을 설명할 수 없을 때 (예: 음성/텍스트 인식)
- 모델이 개인 맞춤화되어야 할 때 (예: 개인 맞춤형 의약품 설계)
- 모델이 방대한 양의 데이터를 기반으로 할 때 (예: 유전체학)
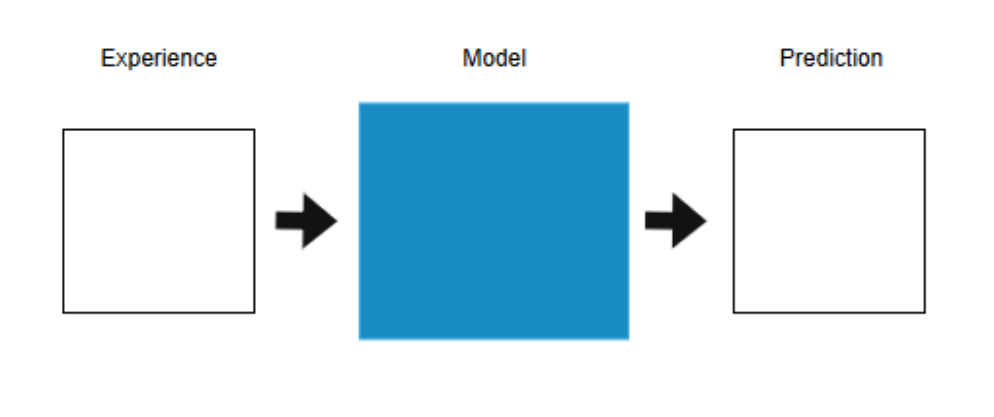
Concept
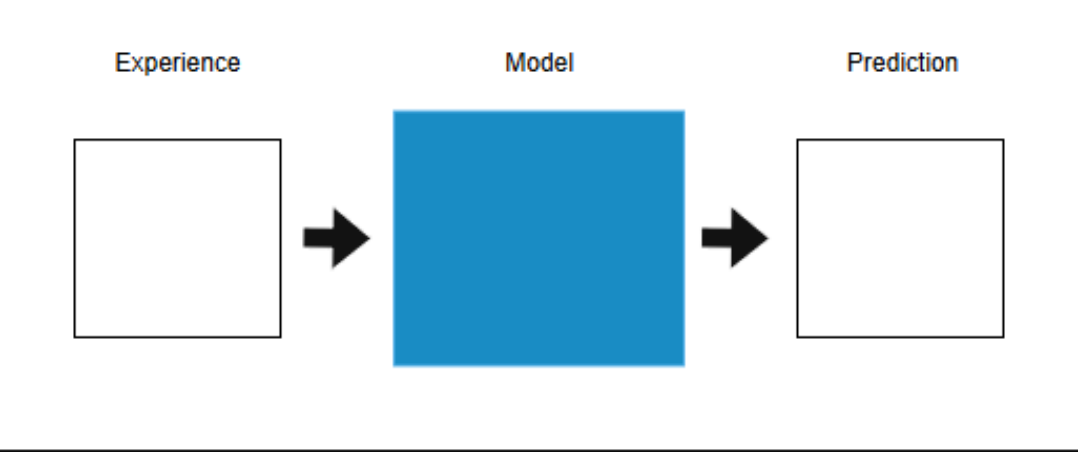
- Experience
- 머신러닝 모델이 학습에 사용하는 입력 데이터
- 레이블(label)이 포함되어 있어야 함 (지도학습 기준)
- 데이터는 수집 가능한 모든 형태의 지식
- 양질의 데이터가 많을수록 성능 향상에 유리함
- Model
- 입력 데이터와 정답(label)을 바탕으로 패턴을 학습하는 시스템
- 다양한 알고리즘(선형 회귀, 결정 트리, 신경망 등)으로 구성될 수 있음
- 학습 과정을 통해 입력과 출력 사이의 관계를 찾음
- Prediction
- 학습된 모델이 새로운 입력에 대해 내리는 출력값
- 실제 정답과 동일하길 기대하지만, 항상 보장되지는 않음
- 예측 결과의 정확도는 학습 데이터의 품질과 모델의 성능에 따라 달라짐
Difference
전통적 알고리즘
- 분석적(Analytical): 사람이 문제를 분석해서 규칙을 만듦
- 피팅 중심(Focused on fitting): 데이터를 기반으로 수학적으로 딱 맞는 함수를 찾음
- 출력을 직접 생성: 입력 → 코드 실행 → 출력
머신러닝 알고리즘
- 식별(discriminative) / 생성(generative): 데이터의 패턴을 분류하거나 생성함
- 일반화 중심(Focused on generalization): 새로운 데이터에도 잘 작동하도록 함
- 모델을 만들어냄: 즉, 학습 결과가 '모델'
Process

- 학습에 필요한 트레이닝 데이터셋을 수집하고 구성
- 모델이 학습해야 할 목표를 명확히 정의
- 목표를 측정할 수 있는 지표(metric)로 표현
- 주어진 경험을 바탕으로 목표 함수를 추론할 알고리즘 선택, 학습
Data Distribution
Training / Validation / Test 데이터셋은 같은 데이터 분포에서 독립적으로 샘플링되었다고 가정
- Training
- 모델이 정답(레이블)을 맞출 수 있도록 학습하는 과정
- Training Set: 모델의 파라미터를 조정하기 위한 데이터
- Validation
- 학습에 사용되지 않은 레이블된 데이터로 검증
- Validation Set: 학습된 모델의 성능을 평가 및 튜닝하기 위한 데이터
- Test
- 학습에 사용되지 않고, 레이블이 없는 데이터로 테스트
- Test Set: 최종 모델의 일반화 성능을 측정하기 위한 데이터
- 대회 및 프로젝트를 수행하다보면 Test Set 또한 레이블이 있지만, 원칙적으로 Test는 학습된 모델이 실제로 쓰이는 상황임. 즉, 사람이 판단해야 함
Types of Learning
- Supervised Learning
- Training data + desired outputs (labels)
- ex) Regression
- Unsupervised Learning
- Training data (without desired outputs)
- ex) Clustering
- Semi-supervised Learning
- Training data + a few desired outputs
- Reinforcement Learning
- Rewards from sequence of actions
Practice (Simple Regression)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegressionx = np.array([5, 15, 25, 35, 45, 55]).reshape((-1, 1))
y = np.array([5, 20, 14, 32, 22, 38])
plt.scatter(x, y, color='blue', label='Data points')
plt.xlabel('x')
plt.ylabel('y')
plt.title('Scatter Plot of x vs y')
plt.legend()
plt.grid(True)
plt.show()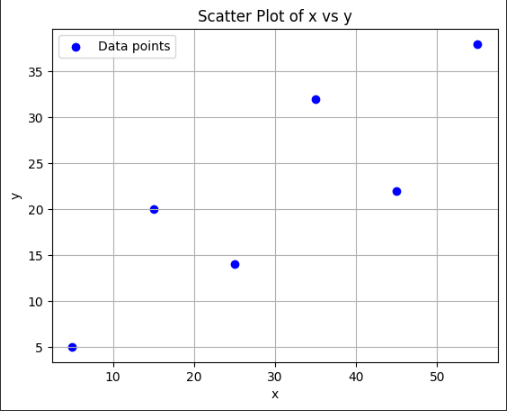
model = LinearRegression()
model.fit(x, y)coeff = model.score(x, y)
print(f"coefficient of determination: {coeff}")
print(f"intercept: {model.intercept_}")
print(f"slope: {model.coef_}")
y_pred = model.predict(x)
print(f"predicted responses: \n{y_pred}")
plt.scatter(x, y, color='blue', label='Actual data')
plt.plot(x, y_pred, color='red', label='Regression line') # 회귀선
plt.scatter(x, y_pred, color='orange', marker='x', label='Predicted points') # 예측값
plt.xlabel('x')
plt.ylabel('y')
plt.title('Linear Regression Result')
plt.legend()
plt.grid(True)
plt.show()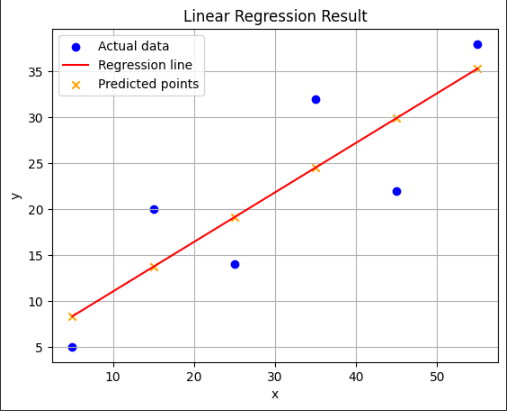

데이터 속에 숨겨진 가치를 발견하고, 사람들의 일상을 더 가치 있게 만드는 AI 엔지니어 조현준입니다.