Optimization
1. BackGround
1) Generalization
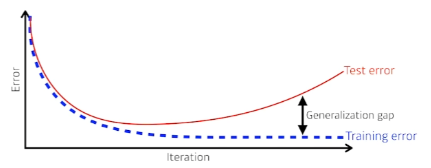
우리가 인공지능 모델을 실생활에서 사용할 때 접하는 데이터는 학습시킬 때 사용했던 데이터는 대부분이 모델을 훈련시킬 때 사용했던 데이터와 다른 데이터가 입력된다.
Generalization, 즉 일반화란 이러한 상황에서 우리 모델의 성능이 학습시킬 때와 비슷하게 나오도록 해주는 것이다.
따라서 Generalization성능을 높이는 것은 우리가 실제 이 모델을 사용하는데 있어 가장 중요하다고 할 수 있다.
2) Overfitting
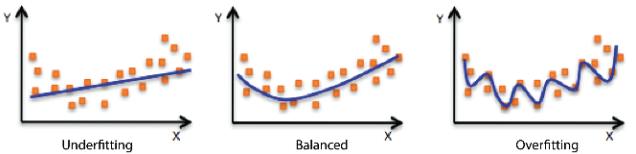
Overfitting
Overfitting이란, 학습이 Traindata Set에만 너무 정확하게 학습되는 것을 의미한다. 주로 딥러닝에서 학습 Epoch을 지나치게 늘릴 경우나, 딥러닝 모델의 Parameter의 수가 많아질 때 발생하게 된다.
이러한 경우 오히려 학습시킨적 없는 실제 Test data에서는 오히려 잘 동작하지 못한다.
Underfitting
Underfitting이란, Overfitting과는 다르게, 학습이 Traindata Set에서 조차 잘 되지 않은 것을 의미한다.
마찬가지로 성능이 떨어지게 되는 이유 중 하나가 된다.
3) Cross-Validation
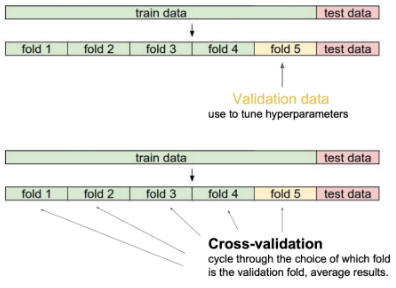
Generalization문제는 모델을 훈련할 때에 우리가 사용할 데이터를 받을 수 없기 때문에 발생한다.
이를 보완하기 위해 사용하는 방법이 Cross-Validation으로, 학습 시 Train Data의 일부를 성능 평가용으로 설정해 학습시키는 방법이다.
(이 때, 성능 평가용 Data, 즉 Validation Data는 절대로 학습에 사용해서는 안된다.)그리고 학습 과정 중 Validation Data Set에 대한 정확도가 높은 Parameter를 찾아 모델에 적용하여 Test하도록 한다.
이 Validation Data는 Data Set에서 하나로 고정시키지 않고 다른 Data Set과 번갈아 가면서 설정해 준다.
예시
우선 위의 그림과 같이 Train Data Set을 5개로 분할해 준다.
그 후, 처음에는2,3,4,5로 학습 후1로 평가,
두번째에는1,3,4,5로 학습 후2로 평가,
...
마지막으로는1,2,3,4로 학습 후5로 평가위와 같은 방식으로 학습시키는 것을 반복하면서 가장 평가가 잘 되었을 경우의 Parameter를 찾아 모델에 적용, 그리고 실제 Test Data Set에 대하여 Test한다.
4) Bootstrapping

Bagging
Bootstrapping aggregating의 약자로, 학습 데이터를 여러 Subsampling으로 나누고 이 Subsample을 여러 Model에 넣어 학습을 시키는 방법을 의미한다.
결과적으로는 이렇게 학습시킨 여러 Model의 결과값을 병렬적으로 활용해 결론을 도출하는 것을 의미한다.
(활용 방법은 평균, 다수결 등 많은 방법이 존재한다.)
Boosting
Bagging이 여러 모델을 병렬적으로 연결해 결론을 내는 방법이었다면 Boosting은 여러 모델을 직렬적으로 합쳐서 사용하는 방법을 의미한다.
예를들어 100개의 Data중 80개에 대해 잘 작동하는 모델과 나머지 20개에 대해 잘 작동하는 모델이 있으면 이 두 모델을 Sequential하게 합쳐서 사용하면 성능이 향상된다고 한다.
2. Optimization
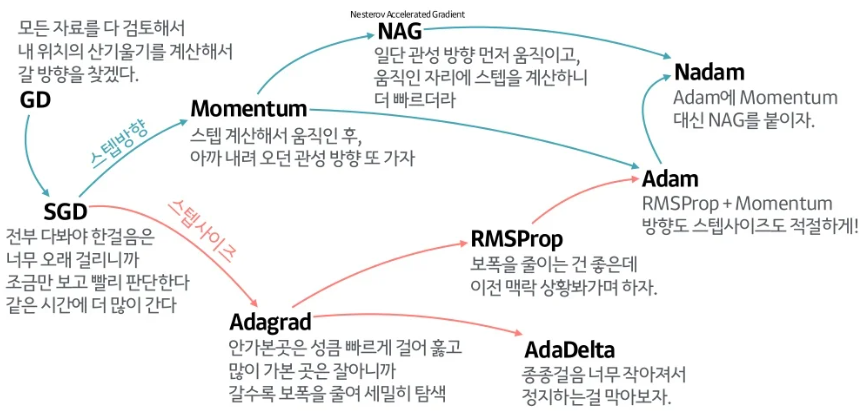
1) Stochastic Gradient Descent
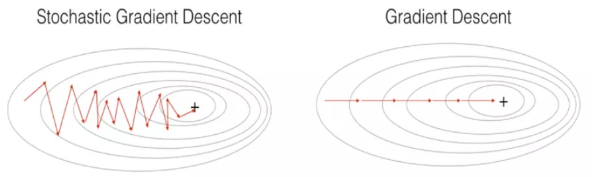
Gradient Descent
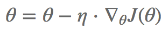
우리가 알고있다 싶이 일반적인 Gradient Descent의 식은 위와 같다.
이때, 이 Gradient Descent는 한가지 큰 문제가 있는데, 학습시 전체 Train Data를 기준으로 Error를 구하기 때문에 매우 많은 연산이 필요해 비효율 적이라는 것 때문이다.
Stochastic Gradient Descent
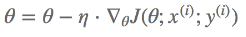
위의 문제를 를 보완하기 위해 등장한 것이 Stochastic Gradient Descent, 일명 SGD이다.
이 SGD는 전체가 아닌 일부 Train Data만을 사용하여 Error를 구하기 때문에 조금 더 효율적으로 Gradient를 구할 수 있다.
2) Momentum
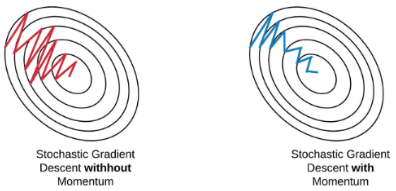
Momentum

SGD가 계산량을 많이 줄여 속도가 빨라졌음에도 불구하고, 여전히 Loss Function의 Minimum값을 찾아가는데에 오래걸린다는 문제가 존재했다.
Momentum은 이를 해결하기 위해 일명 관성, 즉 이전에 사용했던 Gradient를 활용해 그 흐름을 유지시키면서 학습 속도를 빠르게 하는 방법을 사용한다.
Nestrov Accelerated Gradient

위에서 제안되었던 Momentum 방법 또한 문제가 존재했는데, Minimum을 찾았다고 하더라도 그 관성에 의해 Minimum안쪽으로 빠지지 못한다는 문제가 있었다.
NAG는 이 문제를 해결하기 위해 Lookahead Gradient를 활용했는데, Lookahead Gradient는 현재 자리에서의 Gradient를 이용해 움직이는 것이 아니라, 이동 후의 Gradient를 이용하도록 하는 방법이다.
요약
- Momentum
:Momentum 방향으로 이동->이동 전 Gradient 방향으로 이동
- NAG
:Momentum 방향으로 이동->이동 후 Gradient 방향으로 이동
3) Adagrad
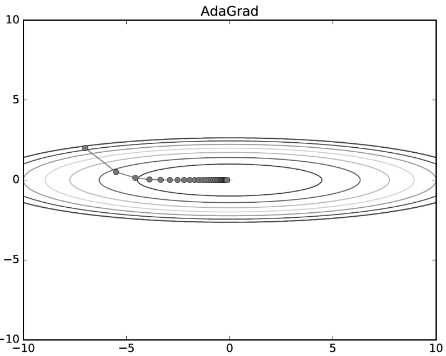
Adagrad
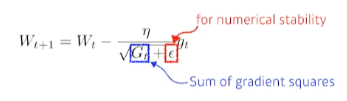
Adaptive Learning Rate, 즉 적응형으로 Parameter를 변화시키는 방법으로, 지금까지 많이 변해왔었던 Parameter들은 적게 변화시키고, 반면에 지금까지 별로 변화가 없었던 Parameter들은 많이 변화시키는 것을 의미한다.
RMSprop

Adagrad는 반복을 하면 할수록 오히려 학습이 점점 느려지고 결국 변화량이 0에 수렴해 간다는 단점이 존재하였다.
RMSProp은 Geoff Hinton이 그의 강의 도중 소개했던 방법으로 Adagrad의 문제를 개선하기 위해 지수이동평균을 도입하여 계산식을 바꾸어 주었고, 나름 성능이 좋아 자주 사용된다.
4) Adam
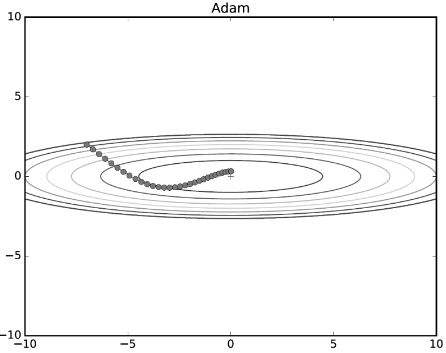
Adam
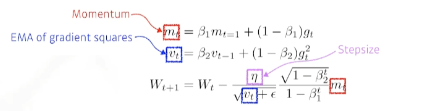
Momentum계열의 방법과 Adaptive계열의 방법을 합친 방법으로 현재 가장 널리 사용되는 방법이다.
물론 Adam이 항상 나머지 방법보다 성능이 좋다는 것은 아니지만, 복잡한 문제가 아닐 경우 Adam이 그래도 평균 이상의 성능을 보여주는 경우가 많기 때문에 현재 가장 많이 사용하고 있는 Optimizer이다.
위의 식에서 입실론의 기본값은 10^-7정도인데 이 값을 잘 조절한는 것이 practical한 문제를 해결하는데 중요한 역할을 한다고 한다.
5) Batch-Size Matter
Batch
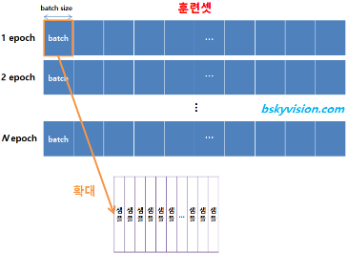
보통 딥러닝에서 데이터셋에 대한 계산을 처리할 때, 하나하나 계산하지 않는다.
일정 크기의 Data를 포함하도록 Batch를 설정한 후 전체 Data Set을 이 Batch로 나누어 이 Batch단위로 계산하게 된다.
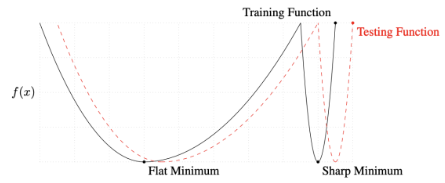
Flat Minimum
"On Large-batch Training for Deep Learning Generalization Gap and Sharp Minima, 2017"
위 논문에 의하면 실험적으로 Batch Size가 커질 수록 Sharp Minimum에 도달할 가능성이 커지고, Batch Size가 작아질 수록 Flat Minimum에 도달할 가능성이 커진다고 한다.
이때, Train Function에서 Flat Minimum에 도달하는 것이 중요한 이유는 위의 그림과 같이 그 주변 위치에서 또한 Testing Function의 Minimum 근처에 존재하기 때문이다.
반면에 Sharp Minimum의 경우에는 그 주변이 Testing Function의 Minimum과는 전혀 다른 공간에 존재한다는 것을 확인할 수 있다.
3. Regularization
BackGround부분에서는 Generalization의 중요성과 이 Generalization을 방해하는 Overfitting이 무엇이고 왜 발생하는지 살펴보았다.
그 후에는 딥러닝 모델의 학습을 가능하게 하는 Optimization의 방법또한 알아 보았다.
여기서는 Overfitting을 방지하고 딥러닝의 성능을 올리는 몇가지 방법에 대해서 소개하고자 한다.
1) Early Stopping
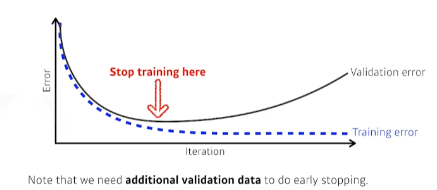
일반적으로 학습의 횟수가 많아질수록 Overfitting이 일어난다.
즉 간단하게 생각해 보면, Cross Validation을 활용해 Stop Point를 지정하고 더이상 학습을 하지 못하도록 방해하는 방법을 사용할 수 있다.
2) Parameter norm penalty
Network의 Parameter의 크기를 줄이는 것을 말한다.
이 경우, 데이터의 Parameter의 변화율을 최대한 줄여 Loss Function을 좀 더 부드러운 함수로 만들 수 있다.
3) Data Augmentation
데이터와 딥러닝의 성능관계
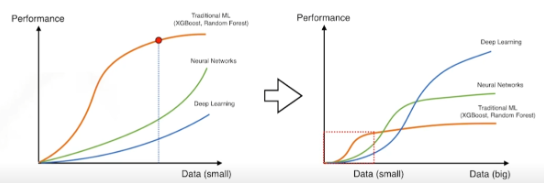
위의 그래프를 보면 알 수 있듯이, 데이터가 적을 때에는 전통적인 기계학습이 더 잘 작동되는 경우가 많았다.
하지만, 데이터가 많아질 수록 딥러닝의 성능은 비약적으로 상승하여 다른 방법들보다 더 좋은 성능을 가지는 것을 확인할 수 있다.
즉 딥러닝에서는 이만큼 데이터가 중요한데,
Data Augmentation은 이를 위해 데이터에 약간의 변형을 주는 작업을 통해 데이터의 개수를 늘리는 것을 의미한다.
자세한 방법들은 뒤에서 다뤄볼 것이다.
4) Noise Robustness

학습시 입력 데이터와 Network의 weight에 매번 Noise를 집어 넣는 방법을 말한다.
5) Label Smoothing

데이터를 늘리기 위해 input데이터들을 섞어 추가하는 것을 말한다.
대표적으로 Mixup, Cutout, CutMix가 있는데, 이중 CutMix의 방법은 간단하면서도 성능을 올리는데에 매우 효과적이라고 한다.
6) Dropout
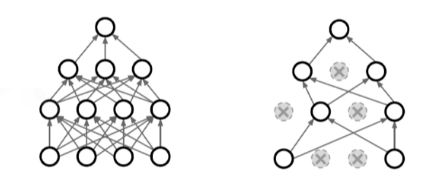
학습 시 Forward과정에서 몇가지 뉴런들을 비활성화상태로 만드는 것을 말한다.
여기서 비활성화된 뉴런들은 모델의 결과를 도출하는데에 전혀 관여하지 않게 된다.
7) Batch Normalization
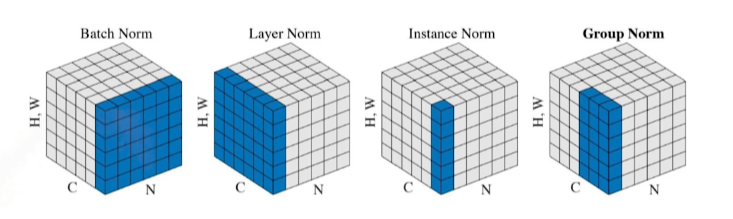
Model의 각 층에서 Parameter들에 대해 정규화를 적용하는 것을 말한다.
(평균=0, 표준편차=1)"Batch Normalization Accelerating Deep Network Training by Reducing Internal Covariate Shift, 2015"
위 논문에서 소개한 방법으로 이 경우 각 Feature의 상호 의존도를 줄여 잘 학습을 시킨다고 한다.
(이에 대해서는 아직까지 많은 논쟁이 있다고 한다.)
