- Hierarchical Text-Conditional Image Generation with CLIP Latents
- https://3dvar.com/Ramesh2022Hierarchical.pdf
- 2022, 4
- 6300회 인용
- code: https://github.com/lucidrains/DALLE2-pytorch
- 11200 stars
초록
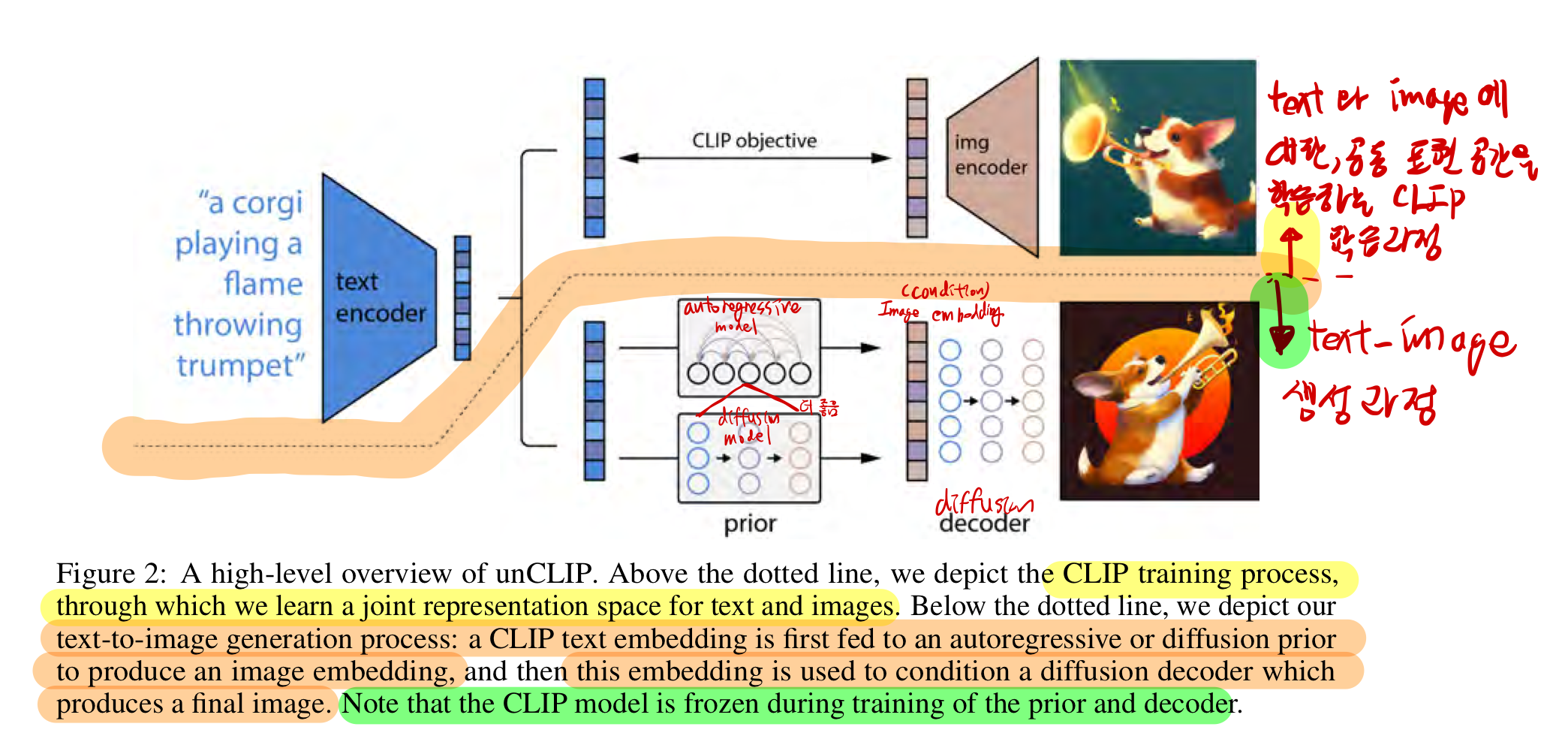
- CLIP과 같은 대조 모델은
이미지의 의미와 스타일을 모두 포착하는 강력한 표현을 학습할 수 있음이 입증됨 - 이러한 표현을 이미지 생성에 활용하기 위해, 우리는 두 단계 모델을 제안
- 하나는 텍스트 캡션을 입력으로 받아 ->
CLIP 이미지 임베딩을 생성하는 프라이어(prior), - 또 다른 하나는
이미지 임베딩을 조건으로이미지를 생성하는 디코더(decoder)
- 하나는 텍스트 캡션을 입력으로 받아 ->
- 우리는 image representation을 명시적으로 생성하면,
캡션과의 유사성과 포토리얼리즘(photorealism)의 손실을 최소화하면서이미지 다양성이 향상됨을 보여줍니다.
image representation을 조건으로 사용하는 디코더는 아래 특징을 가진 변형 이미지를 생성할 수 있습니다.- 이미지의 의미와 스타일을 보존하면서,
- image representation에 포함되지 않은 비필수적인 세부사항을 변화시킨
- 더 나아가, CLIP의 공동 임베딩 공간은, 제로샷 방식으로 언어를 활용한 이미지 조작을 가능하게 합니다.
- 우리는
디코더로 확산 모델(diffusion model)을 사용하고,- Prior 로는
오토회귀 모델(autoregressive model)과확산 모델을 모두 실험했으며,확산 모델이 계산적으로 더 효율적이며 더 높은 품질의 샘플을 생성함을 발견
- Prior 로는
1. 소개
-
CLIP 임베딩은
- 이미지 분포의 변화에 강인하며,
- 인상적인 제로샷(zero-shot) 성능을 보여주고,
- 다양한 비전 및 언어 과제에서 최첨단 결과를 달성하도록 fine-tuning 될 수 있습니다.
-
동시에, 확산 모델도 발전
-
최상의 결과를 얻기 위해 확산 모델은, 아래의 특징을 지닌 가이던스(guidance) 기법을 활용
- 이 연구에서는
텍스트 조건부 이미지 생성 문제를 해결하기 위해 이 두 가지 접근 방식을 결합 - 우리는 먼저 CLIP 이미지 인코더를 역변환하는
diffusion 디코더를 훈련- 우리의
인버터(inverter)는 비결정적이며, 주어진 이미지 임베딩에 해당하는 여러 이미지를 생성할 수 있습니다.
- 우리의
- 인코더와 그
대략적인 역변환 도구인 디코더의 존재는 -> 텍스트-이미지 변환을 넘어서 여러 기능을 제공 - GAN 역변환 [62, 55]에서처럼, 입력 이미지를 인코딩하고 디코딩하면 의미적으로 유사한 출력 이미지를 생성할 수 있습니다(그림 3).
- 우리는 또한 이미지 임베딩의 보간을 역변환하여 입력 이미지 간의 보간을 수행할 수 있습니다(그림 4).
- 그러나 CLIP 잠재 공간을 사용하는 주요 이점 중 하나는, 임의의 텍스트 벡터를 인코딩한 방향으로 이동함으로써 이미지를 의미론적으로 수정할 수 있다는 점입니다(그림 5).


- 반면, GAN 잠재 공간에서 이러한 방향을 발견하려면 운과 많은 수작업이 필요
- 또한 이미지를 인코딩하고 디코딩하는 과정은 CLIP이 이미지의 어떤 특징을 인식하거나 무시하는지 관찰할 수 있는 도구를 제공


- 전체 이미지 생성 모델을 얻기 위해, 우리는
CLIP 이미지 임베딩 디코더와텍스트 캡션에서 가능한 CLIP 이미지 임베딩을 생성하는 프라이어 모델을 결합 - 우리는 우리의 텍스트-이미지 시스템을 DALL-E 40 및 GLIDE 35와 비교했으며,
- 우리 샘플이 GLIDE와 품질이 비슷하지만, 생성 다양성은 더 뛰어나다는 것을 발견
- 또한
잠재 공간에서 diffusion 프라이어를 훈련하는 방법을 개발했으며,- 이들이
오토회귀 프라이어와 유사한 성능을 내면서도 계산 효율성이 더 높음을 증명
- 이들이
- 우리는 CLIP 이미지 인코더를 역변환하여 이미지를 생성하기 때문에,
- 우리의 전체 텍스트 조건부 이미지 생성 스택을 "unCLIP"이라고 부릅니다.
7. 한계와 위험
CLIP 임베딩에 기반한 이미지 생성을 조건화하면- 다양성이 개선되지만, 이러한 선택에는 특정 한계가 존재
- 특히, unCLIP은 (GLIDE 모델에 비해) 객체에 속성을 결합하는 데 약합니다.
- 그림 14에서, unCLIP은
두 개의 개별 객체(큐브)(objects)에두 개의 개별 속성(색상)(attributes)을 결합해야 하는 프롬프트에서 GLIDE보다 더 고전하는 것을 확인할 수 있습니다. 
- 이는
CLIP 임베딩 자체가속성을 객체에 명시적으로 결합하지 않기 때문이라고 가정하며,디코더로부터의 재구성이 속성과 객체를 자주 혼합한다는 것을 그림 15에서 보여줍니다.
- 이와 유사하고 관련이 있을 가능성이 높은 문제는,
unCLIP이 일관된 텍스트를 생성하는 데 어려움을 겪는다는 점으로, 이는 그림 16에 나타나 있습니다.
- CLIP 임베딩이 렌더된 텍스트의 철자 정보를 정확히 인코딩하지 않을 가능성이 있습니다.
- 이 문제는 우리가 사용하는 BPE(BYTE Pair Encoding) 인코딩이, 모델에서 캡션의 단어 철자를 흐리게 만들기 때문에 더욱 악화될 수 있습니다.
- 모델은
학습 이미지에서 각 토큰을 독립적으로 봐야만이를 렌더링하는 법을 학습할 수 있습니다.
- 또한, 우리의 모델 스택이, 복잡한 장면의 세부사항을 생성하는 데 여전히 어려움을 겪고 있음을 언급(그림 17).

- 이는 디코더 계층이 64 × 64의 기본 해상도로 이미지를 생성한 후 업샘플링하는 방식의 한계라고 가정
- 더 높은 기본 해상도에서 unCLIP 디코더를 훈련하면 이를 완화할 수 있지만,
- 추가적인 학습 및 추론 계산 비용이 필요

ad_official