1) 상관관계 분석 (테스트 데이터)
상관 분석이란 두 변수 간의 선형적 관계를 상관 계수로 표현하는 것을 말합니다.
상관 계수를 구하는 것은 공분산의 개념을 포함하는데, 공분산은 2개의 변수에 대한 상관 정도. 2개의 변수 중 하나의 값이 상승하는 경향을 보이면 다른 값도 상승하는 경향을 수치로 표현한 것입니다. 하지만 공분산만으로 두 확률 변수의 상관 관계를 구한다면 두 변수의 단위 크기에 영향을 받을 수 있습니다. 따라서 이를 -1과 1 사이 값으로 변환합니다. 이를 상관 계수라 합니다.
만약 상관 계수가 1에 가깝다면 서로 강한 양의 상관 관계가 있는 것이고, -1에 가깝다면 음의 상관 관계가 있는 것입니다.
Matplotlib는 파이썬에서 자료를 차트나 플롯으로 시각화하는 패키지입니다.Seaborn은 Matplotlib을 기반으로 다양한 테마와 기능을 추가한 시각화 패키지입니다.
데이터를 시각화하기위해서 Matplotlib만을 사용할 수도 있고, Seaborn을 사용할 수도 있으며, 이 두 가지를 함께 사용할 수도 있습니다. 처음에는 익숙하지 않겠지만 앞으로 5주차까지 이어지는 강의에서 지속적으로 차트를 그리다보면 점점 익숙해지게 될 거에요!
▶ [코드스니펫] 패키지 임포트
import pandas as pd
# matplotlib과 seabron 임포트!
import matplotlib.pyplot as plt
import seaborn as sns▶ [코드스니펫] test_df
test_df = pd.DataFrame({"v1":[100,200,300,400], "v2":[400,200,100,250], "v3":[40,60,60,100]})
test_df
데이터의 상관계수를 구하는 방법은 다음과 같습니다.
pearson은 상관계수를 구하는 계산 방법 중 하나를 의미하며, 가장 널리 쓰이는 방법입니다.
데이터프레임의 이름.corr(method='pearson')
corr = test_df.corr(method = 'pearson')
corr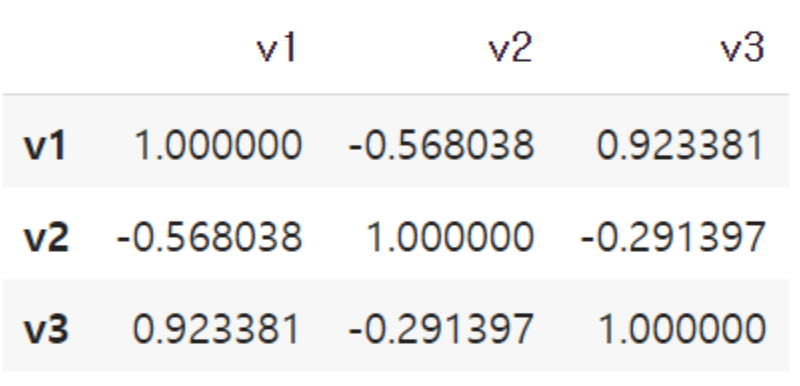
데이터프레임에서 .values를 하게되면 데이터프레임의 각 행이 마치 리스트 형태로 변환되어서 출력이 됩니다. 이를 뒤에 차트를 그릴 때, 입력으로 사용할 것입니다.
corr.values
>>>>>>>>>>>>>결과>>>>>>>>>>>>>>>>
array([[ 1. , -0.56803756, 0.92338052],
[-0.56803756, 1. , -0.29139712],
[ 0.92338052, -0.29139712, 1. ]])차트에 이름을 입력하기 위해서 다음과 같이 column_names라는 리스트를 만듭니다.
column_names = ['ver1', 'ver2', 'ver3']일반적으로 상관계수 차트를 그릴 때는 seaborn에서 제공하는 heatmap()을 주로 사용합니다. seaborn을 sns이라는 이름으로 임포트하였다면, 기본적인 사용 방법은 다음과 같습니다.
sns.heatmap(데이터프레임의 상관계수 데이터)
아래 코드에 heatmap에서 사용하는 각종 추가적인 설정값에 대해서 주석을 달아두었습니다. 이 설정값들은 필수적인 입력이 아니며, 좀 더 예쁘게 차트를 그리기 위해서 여러분들이 추가적으로 조작하는 것들입니다.
▶ [코드스니펫] 히트맵 코드
# 레이블의 폰트 사이즈를 조정
sns.set(font_scale=2.0)
test_heatmap = sns.heatmap(corr.values, # 데이터
cbar = True, # 오른쪽 컬러 막대 출력 여부
annot = True, # 차트에 숫자를 보여줄 것인지 여부
annot_kws={'size' : 20}, # 숫자 출력 시 숫자 크기 조절
fmt = '.2f', # 숫자의 출력 소수점자리 개수 조절
square = True, # 차트를 정사각형으로 할 것인지
yticklabels=column_names, # x축에 컬럼명 출력
xticklabels=column_names) # y축에 컬럼명 출력
plt.tight_layout() # 그래프 간격 유지 설정
plt.show() # 그래프 표시
각종 설정값이 어떻게 동작하는지 가장 쉽게 알 수 있는 방법은 해당 설정값을 지워서 재출력해보는 것입니다! 예를 들어서 fmt = '.2f'의 값을 fmt = '.3f'으로 바꿔서 재실행해보세요. 그러면 차트 위의 숫자가 소수점 셋 째자리까지 출력 될 것입니다.
다른 설정값에 대해서도 여러분들이 자유자재로 바꿔서 출력해보세요.
상관 분석을 시각화 할 수 있는 또 다른 방법을 산점도(scatter plot)를 그리는 것입니다. 산점도는 좌표상에 점들을 표시하는 방법으로 두 개 변수 간의 관계를 나타내는 그래프 방법입니다. 변수 A가 증가할 때 변수 B 또한 증가하는 어떤 상관 관계가 있는지, 아니면 아무런 관계가 없는지 산점도를 통해서 확인해 볼 수 있습니다.
seaborn을 sns란 이름으로 임포트하였다면, 산점도를 그리는 기본 방법은 다음과 같습니다. pairplot은 각 열의 조합에 대해서 산점도를 그리고, 같은 데이터가 만나는 대각선 영역에는 해당 데이터의 히스토그램을 그립니다.
sns.pairplot(데이터프레임)
# whitegrid = 배경에 하얗게 한다.
sns.set(style='whitegrid')
sns.pairplot(test_df)
plt.show()
지금은 데이터가 너무 적어서 산점도를 해석하기에는 무리가 있습니다. 산점도의 해석은 주류 데이터에 대해서 진행해보겠습니다!
2) 상관관계 분석 (주류 데이터)
주류 데이터의 각 특성(feature)에 대해서 상관계수를 계산하고, 이를 seaborn의 heatmap과 pairplot을 통해서 시각화해봅시다! 우선, 'beer_servings', 'wine_servings' 두 특성 간의 상관계수를 계산해보겠습니다.
# 'beer_servings', 'wine_servings' 두 피처간의 상관계수를 계산합니다.
# pearson은 상관계수를 구하는 계산 방법 중 하나를 의미하며,
# 가장 널리 쓰이는 방법입니다.
corr = drink_df[['beer_servings',
'wine_servings']].corr(method = 'pearson')
corr
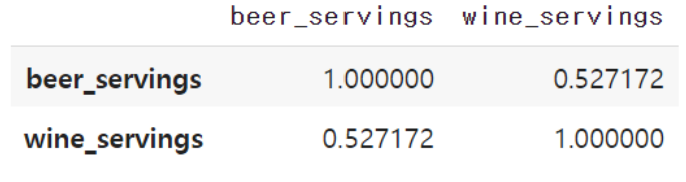
두 특성의 상관계수 값은 0.527172입니다. 이번에는 두 개의 특성이 아니라, 다른 모든 열에 대해서도 상관계수 값을 구해봅시다.
# 피처간의 상관계수 행렬을 구합니다.
cols = ['beer_servings', 'spirit_servings', 'wine_servings', 'total_litres_of_pure_alcohol']
corr = drink_df[cols].corr(method = 'pearson')
corr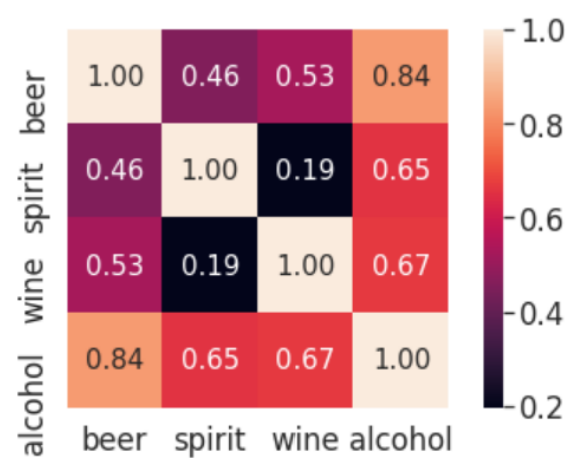
가장 상관계수 값이 높은 경우는 beer_servings와 total_litres_of_pure_alcohold의 상관계수 값으로 0.835839에 해당됩니다. 이를 seaborn의 heatmap을 통해서 시각화해봅시다. 우선 heatmap의 입력을 만들기 위해서 상관계수값에 .values를 적용시켜줍니다.
corr.values
>>>>>>>>>>>>>>>>>>>실행>>>>>>>>>>>>>>>
array([[1. , 0.45881887, 0.52717169, 0.83583863],
[0.45881887, 1. , 0.19479705, 0.65496818],
[0.52717169, 0.19479705, 1. , 0.66759834],
[0.83583863, 0.65496818, 0.66759834, 1. ]])히트맵 차트의 x축과 y축에 각각의 레이블을 달아주기 위해서 다음의 리스트를 만들어줍니다.
column_names = ['beer', 'spirit', 'wine', 'alcohol']seaborn의 heatmap 시각화를 진행해봅시다!
▶[코드스니펫] 주류데이터 히트맵
# 레이블의 폰트 사이즈를 조정
sns.set(font_scale=1.5)
hm = sns.heatmap(corr.values, # 상관계수 데이터
cbar=True,
annot=True,
square=True,
fmt='.2f',
annot_kws={'size': 15},
yticklabels=column_names,
xticklabels=column_names)
plt.tight_layout()
plt.show()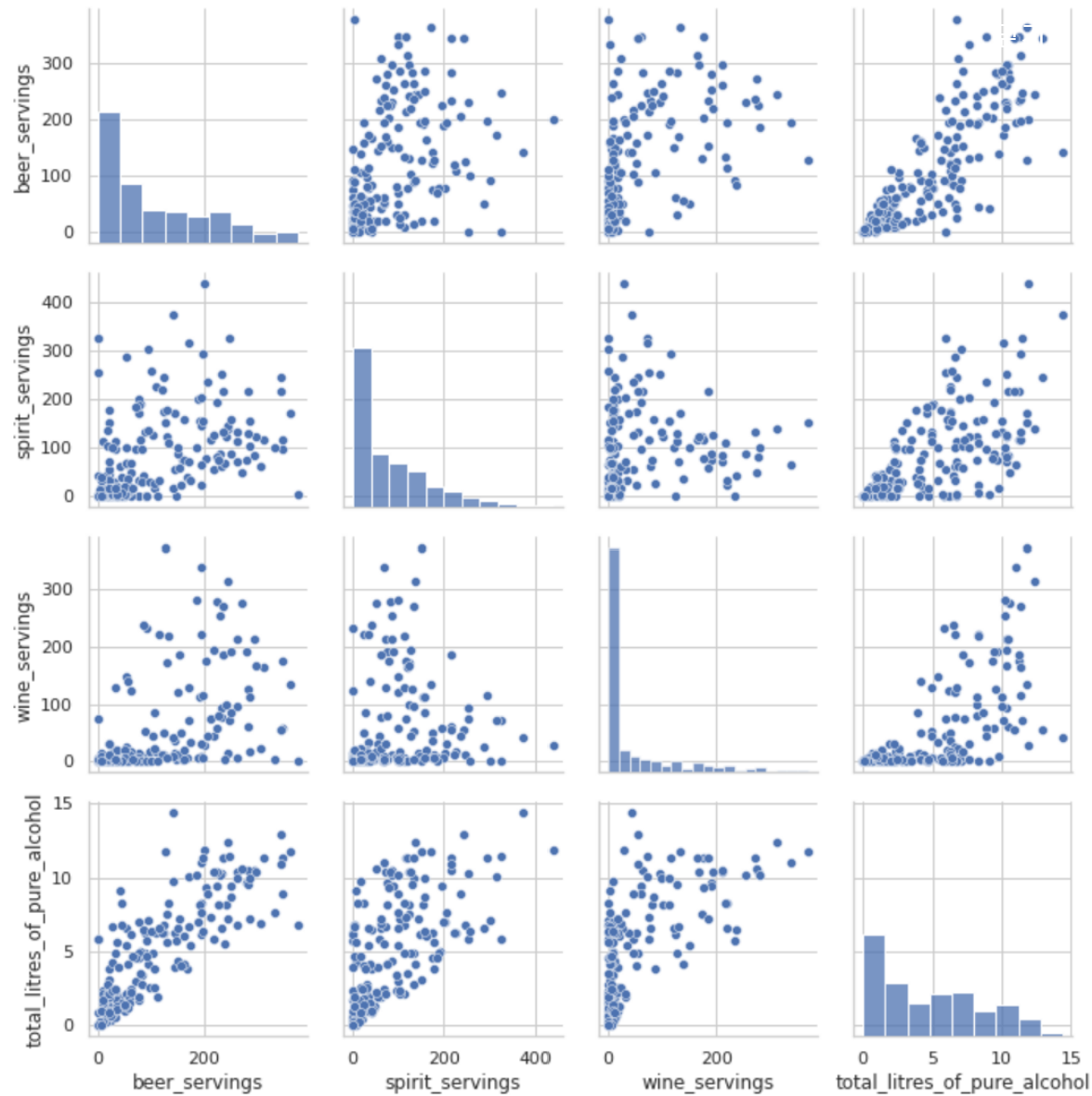
alcohol은 대체적으로 다른 특성들과 모두 상관 계수가 높습니다.
이미 시각화를 진행하기 전에도 확인한 내용이기는 하지만, 그 중에서도 0.84로 beer와 상관 계수값이 가장 높습니다. 앞서 확인하였을 때는 0.835839였지만, 여기서는 소수점 두 자리까지만 출력하면서 반올림되어 0.84로 출력된 것이라 보면 됩니다.
주류 데이터의 산점도. 즉, pairplot을 확인해봅시다. pairplot은 데이터프레임을 인수로 받아 그리드(grid) 형태로 각 데이터 열의 조합에 대해 산점도를 그립니다. 같은 데이터가 만나는 대각선 영역에는 해당 데이터의 히스토그램 (범위 별 데이터의 빈도를 그래프로 나타낸 것) 을 그립니다.
▶[코드스니펫] 주류데이터 산점도
# 시각화 라이브러리를 이용한 피처간의 scatter plot을 출력합니다.
sns.set(style='whitegrid')
sns.pairplot(drink_df[['beer_servings', 'spirit_servings',
'wine_servings', 'total_litres_of_pure_alcohol']])
plt.show()total_litres_of_pure_alchol는 대체적으로 모든 특성과 상관 관계가 있는 것으로 보입니다.
그 중에서도 bear_servings의 상관성이 매우 높은 것으로 나타납니다. 이는 앞서 확인했듯이 이 둘의 상관 계수 값이 0.84인 점과도 일치합니다.
(위 산점도에서 가장 맨 위, 가장 맨 우측에 있는 부분을 확인해보시면 됩니다.)
