CVPR 2022
paper_link
- ConvNeXt는 Vision Transformer의 디자인 원리를 ResNet에 적용하여 현대화한 순수 ConvNet 모델
Abstract
-
A vanilla ViT, on the other hand, faces difficulties when applied to general computer vision tasks such as object detection and semantic segmentation.
-
we reexamine the design spaces and test the limits of what a pure ConvNet can achieve.
-
원래 이미지는 ConvNet, NLP는 Transformer을 backbone으로 가고 있었으나 ViT의 등장으로 둘이 합쳐지게 됨
-
ViT는 이미지 분류 작업에는 강했지만 객체 탐지(object detection), 분할(segmentation)과 같은 복잡한 시각 작업에서 한계가 드러남.
-
질문 : 이제 CNN은 끝났을까?
-
Transformer의 좋은 성능이 모델 구조 때문인지, 아니면 학습 과정과 하이퍼 파라미터의 진화 덕분인지 명확하기 않음!
-
=> 현대의 트랜스포머처럼 CNN을 업데이트하면 성능을 따라잡을 수 있지 않을까?
Swin Transformer
이전 Swin Transformer 논문 리뷰 참고
Modernizing a ConvNet : a Roadmap
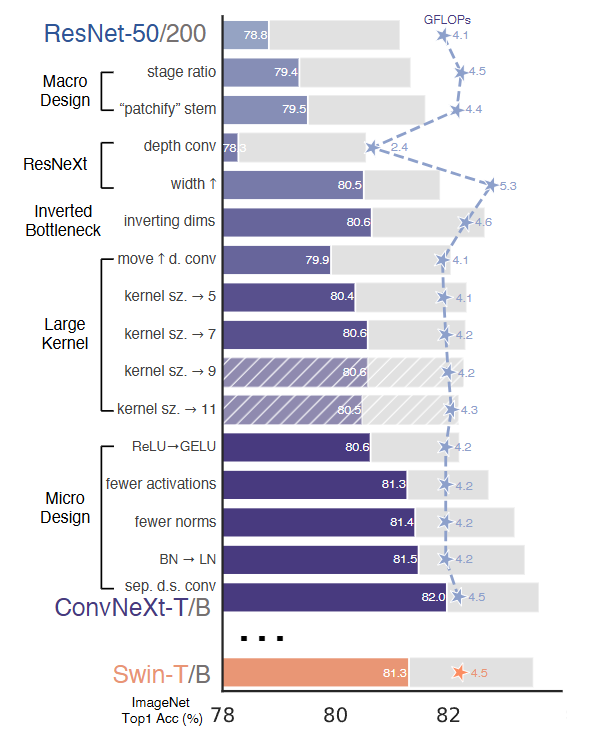
- ResNet-50/200 모델을 출발점으로 해서 ConvNeXt 모델을 만들기 위해 여러 부분에서 다양한 개선을 통해 성능을 향상시켰다.
- ViT에서 쓰는 학습 기법(AdamW 옵티마이저, Mixup, Cutmix RandAugment, Stochastic Depth 등)을 적용해 학습 안정성과 정확도를 높임
- Macro Design
- ResNeXt
- inverted bottleneck
- large kernel size
- various layer-wise micro design
1. Macro Design
- 이제 Swin Transformer의 전체 네트워크 설계를 분석하고자 함
- 여기서 주목할 것은 Stage간 연산 비율과 입력 처리 방식!
[Changing stage compute ratio]
- ResNet은 네트워클르 여러 'stage'로 나눠서 각 단계에서 연산량(FLOPs)이 다르게 설정됨
- ResNet에서 단계 간의 계산 분포에 대한 설계는 대부분 경험적이며 원래 ResNet-50은 블록 개수가 (3,4,6,3)으로, 중간의 res4 단계가 매우 무겁게 설계되어 있음
- 큰 Swin 의 경우 비율은 1:1:9:1이었음
- => 이걸 따라 ResNet-50의 블록 수를 (3,3,9,3)으로 조정
- => FLOPs는 Swin-T와 비슷, 정확도는 78.8% -> 79.4% 향상!!!
결론: stage 간 연산 분포를 바꾸면 성능이 좋아질 수 있음. ResNet의 기존 비율은 실험적으로 정해졌기 때문에 최적은 아닐 수 있음
[Changing stem to 'Patchify']
- Stem은 이미지가 네트워크에 처음 들어올 때 어떻게 처리되는지를 말함
- ResNet은 7x7 conv + max pooling을 사용 → 이미지 크기를 처음에 1/4로 줄임
- Vision Transformer 계열(ViT, Swin)은 입력 이미지를 패치로 자르는 방식을 사용 =
patchify - => Swin처럼 patchify layer 사용: 4x4 커널, 스트라이드 4, 겹치지 않는(non-overlapping) 컨볼루션
- => 정확도 79.4% → 79.5% 로 소폭 향상
결론: 복잡한 ResNet의 초기 처리 대신, 간단한 patchify 방식으로도 성능을 유지하거나 소폭 향상 가능
2. ResNeXt-ify
= ResNeXt 스타일로 바꾸기
=> 핵십 아이디어는 grouped convolution
- 하나의 convolution연산을 여러 그룹으로 나눠서 병렬로 처리
- = 그룹 수를 늘리고, 네트워크 폭(width)도 같이 늘리자!
Depthwise Convolution사용
- 각 채널별로 독립적으로 convolution을 수행(group 수 = 채널 수)
- 공간 정보만 섞고, 채널 간 정보는 섞지 않음
- 이후 1x1 conv로 채널 정보 섞기 -> ViT처럼 spatial/채널 분리된 연산 구조- FLOPs 줄어들었음 -> BUT 연산량만 줄이면 성능 저하 발생할 수 있음 -> 채널 수를 늘림 -> 정확도 80.5%, 연산량 5.3G FLOPs으로 성능%효율 개선!
3. Inverted Bottleneck
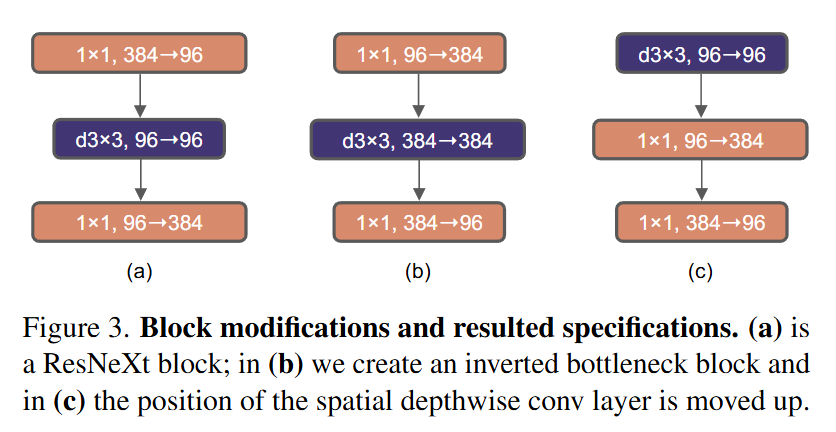
- Transformer의 MLP Block은 입력보다 4배 넓은 차원(hidden dim)을 사용함
- ex. 입력이 96차원이면 MLP는 384차원까지 호가장했다가 다시 96으로 줄임 - = Inverted Bottlenect
- 이처럼 폭을 넓혔다가 다시 줄이는 구조로 변경함!
- 처음에는 FLOPs가 증가할 것처럼 보이지만 실제로는 1x1 conv의 FLOPs 감소 덕분에 전체 네트워크 5.3G -> 4.6G으로 감소
- Top-1 정확도도 80.5% -> 80.6%으로 증가
4. Large Kernel Sizes
- 왜 큰 커널이 중요한가?
- Vision Transformer는 non-local self-attention으로 글로벌 recep
- 큰 커널을 쓰면 한 번의 convolution 연산으로 더 넓은 범위의 정보를 처리해 self-attention이 전역 정보를 한 번에 계산하는 것과 유사한 효과를 낼 수 있음
- 전통적인 ConvNet은 대부분 3X3 커널을 사용 -> 지역적 정보 처리만 가능
- => ConvNet에서도 더 큰 커널을 써보자!
- Depthwise Conv 위치 변경
- 기존에는 채널 확장 후 depthwise conv를 적용했는데 Transformer처럼 처음에 depthwise conv를 먼저 적용하도록 구조를 변경 (Figure3에서 (b)->(c))
- FLOPs 5.3G -> 4.1G로 감소
- 정확도 80.6% -> 79.9%로 잠깐 감소
- 커널 크기 확장
- depthwise conv의 커널 크기를 키워서 성능을 끌어올림
- 실험한 커널 크기 : 3, 5, 7, 9, 11
- 그 결과 7X7이 최적점으로 더 키워도 성능 좋아지지 않음
결론: 7X7 depthwise convolution을 각 블록에서 사용! ViT의 넓은 시야를 흉내내면서 ConvNet으로 구현할 수 있는 현실적인 방식
5. Micro Design
= 아주 작은 단위의 아키텍처 변경이 전체 성능에 어떻게 영향을 주는가?
[Replacing RELU with GELU]
- 기존 ConvNet은 ReLU를 주로 사용 (간단하고 빠름)
- BUT! Transformer는 대부분 GELU를 사용
- GELU는 ReLU보다 부드럽고 확률적인 곡선 형태의 활성화 함수
실험 결과: ReLU -> GELU로 바꿔도 정확도 변화 없음
[Fewer activation functions]
= 활성화 함수 줄이기
- ResNet 블록은 conv마다 activation을 쓰는데 Transformer는 MLP 블록에 단 1개만 씀
- GELU를 단 하나만 남기고 나머지 제거
실험 결과: 정확도 80.6 -> 81.3% 상승- 너무 많은 비선형은 오히려 방해될 수 있음!
[Fewer normalization layers]
= 정규화 레이어 줄이기
- 기존 ResNet은 한 블록에 BatchNorm 2~3개씩 넣음
- BN을 1개로 남겼더니 성능이 81.4%로 증가
[Substituting BN with LN]
- ConvNet은 일반적으로 BN, Transformer는 LN을 사용함
- 과거에는 LN을 ConvNet에 적용하면 성능이 낮아졌지만, 여기선 다른 구조 변경을 적용한 후 LN을 써봤더니 성능이 오히려 더 좋아짐 (81.5%)
- => 이제 각 블록에 LayerNorm 하나만 사용
[!note] BN과 LN 내가 보려고 아카이빙한 BN vs LN
- 정규화란? : 딥러닝 네트워크의 학습 안전성과 수렴 속도를 높이기 위해 입력 데이터를 일정한 분포로 조정하는 과정
==Batch Normalization(BN)==
한 배치 안에서 채널별로 정규화 한다.
- ex. 32장의 이미지(batch size=32), 채널 수가 64라고 하면, 각 채널에서 32장의 값을 모아서 평균/표준편차 계산하여 정규화를 함
- = 이미지 4장이 있고, 각 이미지의 1번 채널만 본다면 BN은 "4장의 이미지"의 "1번 채널 값"들로 계산
==Layer Normalization(LN)==
각 샘플의 모든 채널을 한번에 정규화
- ex. 하나의 이미지 안에서 모든 채널을 보고, 그 이미지의 채널 전체에 대해 평균/표준편차 계산
[Separate downsampling Layers]
= 다운샘플링을 블록에서 분리
- ResNet : stage마다 블록 안에서 stride=2로 다운샘플링 수행
- Swin Transformer : 블록 바깥에 따로 다운샘플링 레이어가 있음
- ConvNeXt도 2X2 stride=2 conv레이어로 다운샘플링르 따로 적용
- 처음에는 학습이 불안정했지만 정규화 레이어를 추가하니 Swin-T의 81.3%보다 더 높은 82.0%까지 증가함
[Closing remarks]
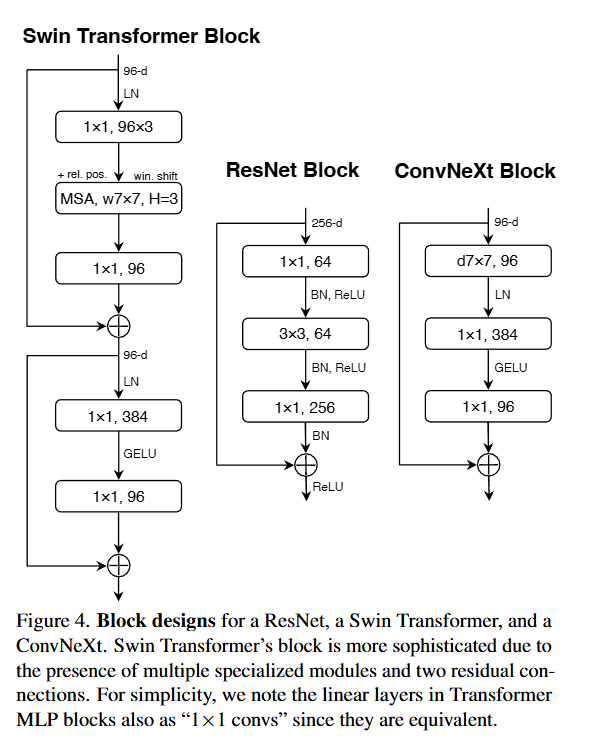
- ConvNeXt는 완전한 ConvNet 기반임에도 Transformer 수준의 성능을 냄
- 하지만 진짜 경쟁력을 확인하려면 더 큰 모델, 더 어려운 태스크에서도 성능을 보여줘야 함
Empirical Evaluations on ImageNet
목표 : ConvNeXt 모델이 기존 ConvNet과 Vision Transformer와 ImageNet-1K 및 22K에서 얼마나 잘 작동하는지 평가하기
ImageNet-1K 결과 요약
- ConvNeXt는 Swin Transformer보다 일관되게 높은 정확도를 보임
- 예: ConvNeXt-T (82.1%) > Swin-T (81.3%)
- ConvNeXt-B(384×384) (85.1%) > Swin-B(384×384) (84.5%)
- 추론 속도(FPS)도 ConvNeXt가 더 빠름 (Dense conv 덕분)
결론: 동일한 연산량(FLOPs) 대비 정확도 및 처리 속도 모두 우수
ImageNet-22K 결과 요약
- ConvNeXt는 대규모 데이터셋에서 Transformer와 같은 확장성(scaling)을 가짐
- ConvNeXt-XL은 87.8%로 최고 정확도 달성
- Swin-L이나 ViT-L보다 정확도에서 우수하거나 동등, 처리 속도는 더 빠름
Conclusion
- 2020년대 들어서 Swin Transformer 같은 계층적 구조의 Vision Transformer들이 기존의 ConvNet을 넘어 범용 비전 백본(backbone)으로서 자리를 차지했다.
- 일반적으로는 ViT가 ConvNeㅅ보다 더 정확하고, 효율적이며, 확장성도 뛰어나다는 인식이 널리 퍼져 있다.
- 이에 대해 위 논문은 ConvNeXt라는 순수 ConvNet 기반 모델을 제안하며 이는 여러 벤치마크에서 ViT와 견줄 수 있는 성능을 냈다.
- 완전한 새로운 아이디어가 아닌 지난 10년간 개별적으로 이미 연구되어 왔던 것들!
