'25 아키텍처 스터디 2주차
- 이번에는 CLIP
- LlaVA를 하려고 했는데 CLIP이 언급되길래 이것부터...
- paper link
- ICML 2021
Paper
Abstract
- CV 시스템은 미리 결정된 객체 범주의 고정된 집합을 예측하도록 학습됨
- 이런 제한된 형태의 지도학습은 다른 시각적인 개념을 특정하는데 추가적인 데이터가 필요하므로 일반성과 유용성이 떨어짐
- 이미지에 대한 원시 텍스트 데이터에서 직접 학습하는 것은 더 넓은 지도 학습 소스를 활용하는 유망한 대안
- Text와 Image의 관계성을 모델링한 연구!!
Motivation
- 자연어 처리 분야에서 raw text를 이용해 사전 학습을 하는 방식은 계속 발전해왔다.
- 발전된 사전 학습 방법을 모두 적용한 모델인 GPT-3는 라벨링된 데이터셋 없이도 다양한 태스크에서 좋은 성능을 내는 모델이 되었다.
- = 자연어 처리 분야에서는 적은 양의 라벨이 붙은 고품질 데이터셋보다, 많은 양의 웹 상에서 수집된 라벨이 없는 데이터가 더 학습에 용이하게 사용된다.
- BUT~! 컴퓨터 비전 분야에서는
적은 양의 라벨이 붙은 고품질 데이터셋을 사용한다.
자연어처리 분야처럼 웹 상에서 수집된 테스트로부터 사전 학습을 하는 방식을 컴퓨터 비전 분야에 적용할 수 있을까?!
- 4억 개의 [이미지, 텍스트] 페어를 만들고 이를 ConVIRT의 간단한 버전을 이용해 학습
= Contrastive Language-Image Pre-training = CLIP
METHOD
대규모 데이터셋 구축
- ImageNet이나 MC-COCO 데이터셋은 고작 10만 장
- YFCC100M 100만 장이지만 퀄이 좋지 않아 전처리 하면 10만 장 정도
- OPENAI에서는 4억장의 이미지-텍스트 쌍을 인터넷에서 구함
- = WebImageText(WIT) 라 명명~
Contrastive Pre-training (대조적 사전 훈련)
Contrasitive learning
레이블링 없이 학습하는 Self-supervised learning 방법론 중 하나. 특정 입력을 embedding network를 통해 임베딩 공간으로 이동시키고, 같은 class라면 임베딩 값의 거리를 최소화(d+), 다른 class라면 임베딩 값의 거리를 최대화(d-)하도록 embedding network를 학습하는 방법.
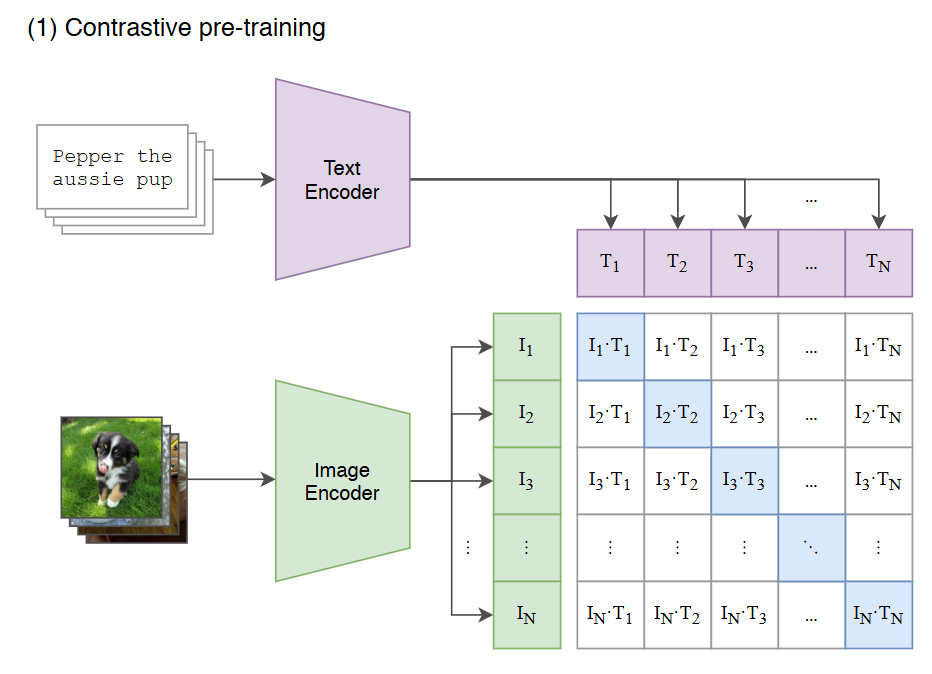
- 목표 : 이미지와 텍스트 간의 연관성을 학습하자!
- 이미지 인코더는 이미지 배치(I1, I2, I3...)를 입력받아 각 이미지의 특징 벡터를 추출
- 텍스트 인코더는 텍스트 배치(T1, T2, T3...)를 입력받아 각 텍스트의 특징 벡터를 추출
- 이후 각 이미지 특징 벡터와 텍스트 특징 벡터의 모든 가능한 쌍에 대해
유사도를 계산 - CLIP은 배치 내에서 실제로 연결된(image, text) 쌍의 유사도는 높이고, 잘못 연결된 쌍의 유사도는 낮추도록 학습
🥨 이미지 텍스트에서 추출한 특징 벡터는 어떤 형태로 저장될까?
- 실수 값으로 이루어진 1차원 배열 형태이며, L2 정규화를 거쳐 임베딩 공간에 표현됨
- 해당 특징 벡터는 이미지의 시각적 특징을 나타냄!
- 실제로 보고 싶당
Create dataset classifier from label text
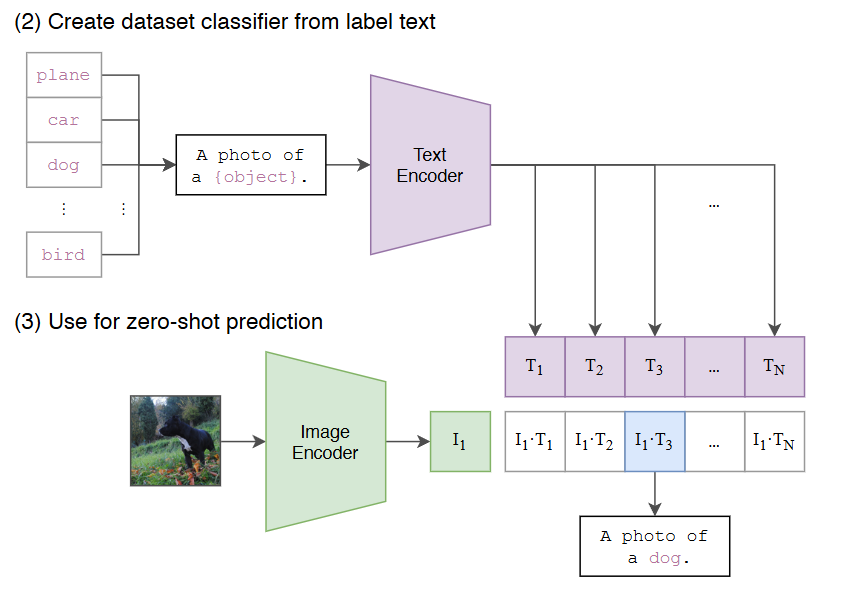
- 목표 : 제로샷 분류를 위해 텍스트 정보를 이용해 분류기를 만드는 것
- 분류하고자 하는 데이터셋의 클래스 이름(ex.plane, car, dog, bird)을 텍스트 인코더에 입력
- 각 클래스의 이름은 "A photo of a {object}"와 같은 템플릿을 사용! -> 그러면 더 잘된다~~
- 텍스트 인코더는 각 클래스에 대한 텍스트 특징 벡터(T1, T2, T3, ..., TN)를 생성
- 텍스트 특징 벡터들은 해당 클래스를 나타내는 분류기의 가중치로 사용됨
Use for zero-shot prediction
- 목표 : 학습 없이 새로운 이미지에 대한 분류를 수행하는 것
- 분류하고자 하는 이미지를 이미지 인코더에 입력해 이미지 특징 벡터(I1)을 추출
🥨CLIP이 이미지를 미리 학습하지 않고도 새로운 클래스를 인식할 수 있는 능력은 어디서 비롯된 걸까?
- 대조 학습(Contrastive Learning)
- 방대한 양의 (이미지, 텍스트) 쌍 데이터셋을 사용해 대조 학습을 수행
- => 이 과정에서 모델은 이미지와 텍스트 간의 의미적 연관성을 학습
- 자연어 지도(Natural Language Supervision)
- CLIP은 이미지에 대한 텍스트 설명을 직접적인 지도 신호로 활용
- = 이미지의 객체, 속성, 스타일 등에 대한 텍스트 정보를 이용해 학습!
- "A photo of a [object]"와 같은 프롬프트 템플릿을 사용해 텍스트 설명을 생성하고, 이를 통해 다양한 클래스에 대한 일반화 능력 향상
- 의미적 임베딩 공간(Semantic Embedding Space)
- CLIP은 이미지와 텍스트를 공통의 의미적 임베딩 공간에 표현
- => 비슷한 의미를 가진 이미지와 테스트는 서로 가까이 위치하게 됨
- 새로운 클래스에 대한 텍스트 설명이 주어지면, CLIP은 해당 텍스트를 임베딩 공간에 투용하고, 가장 가까운 이미지를 찾음
=> 학습 데이터셋에 없는 새로운 클래스에 대해서도 이미지 분류를 수행할 수 있음!!=
비유: 외국어를 배울 떄 단어와 그림을 함꼐 보면서 단어의 의미를 학습
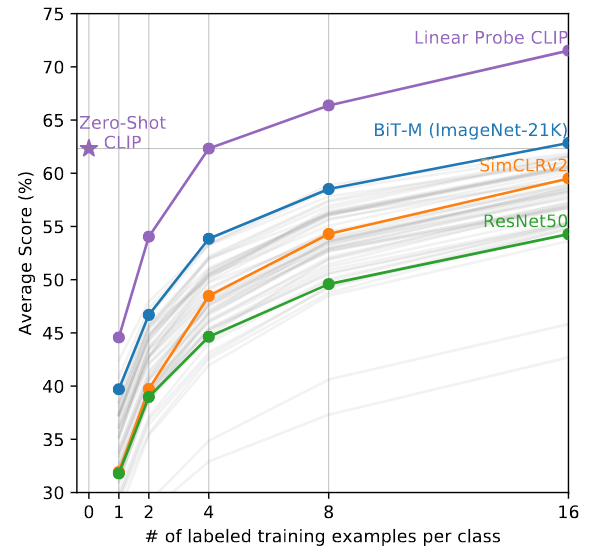
🥯 학습 데이터셋의 크기가 클 수록 성능이 계속 향상될까?
- YES : 과적합을 방지하고 더 많은 의미의 연관성을 학습할 수 있음
- NO : 하지만 데이터 품질이 낮거나 모델의 용량이 부족하면 성능 향상폭이 줄어들 것!
Pseudo code

Image encoder: ResNet이나 Vision Transformer 사용text encoder: Transformer 사용(CBOW는 뭐지)I[n, h, w, c]: 이미지의 미니 배치n: 배치 크기,h: 높이,w: 너비,c: 채널 수
T[n,1]: 텍스트의 미니 배치n: 배치 크기,1: 시퀀스 길이
🥨 배치 vs 미니 배치
배치(Batch)
- 전체 훈련 데이터셋을 한 번의 반복(Iteration)에서 모델에 입력해 학습하는 방식
= 모델이 한 번 업데이트 할 때 전체 데이터를 사용- 장점 : 1) 정확한 Gradient 계산 2) 수렴 안정성
- 단점 : 1) 높은 계산 비용 2) 학습 속도 저하
미니배치(Mini-batch)
- 전체 훈련 데이터셋을 작은 부분집합으로 나누어, 각 미니배치를 사용해 모델을 업데이트하는 방식
- 장점 : 1) 낮은 계산 비용 2) 빠른 학습 속도 3) Regularization : Gradient에 노이즈를 추가해 Regularization 효과를 주어 모델의 일반화 성능을 향상 4) Local Minima 탈출
- 단점 : 1) 불안정한 Gradient 계산 2) 추가적인 하이퍼파라미터 튜닝 필요
W_i[d_i, d_e]: 이미지를 임베딩하는 학습된 projection- 이미지를 임베딩한다 = 미지를 벡터 형태로 표현한다.
- 학습된 Projection : 모델이 데이터를 가장 잘 표현할 수 있도록 Projection 방법을 스스로 찾아냄.
- 주로 Fully Connected Layer나 선형 변환을 통해 projection을 구현하며, 이 Layer의 가중치들이 학습을 통해 조정됨
d_i: 이미지 특징의 차원,d_e: 임베딩 공간의 차원
W_t[d_t, d_e]: 텍스트를 임베딩하는 학습된 projectiont: 소프트맥스 함수에서 로짓의 범위를 조절하는 학습 가능한 온도 파라미터
-
#extract feature representations of each modality : 각 modallity에서 특징 representation을 추출
I_f = image_encoder(I) #[n, d_i]: 이미지 인코더를 통해 이미지 특징I_f추출n: 배치크기,d_t: 텍스트 특징 차원
T_f = text_encoder(T) #[n, d_t]: 텍스트 인코더를 통해 텍스트 특징T_f추출n: 배치크기,d_t: 텍스트 특징 차원
-
#joint multimodal embedding [n, d_e] : 이미지와 텍스트를 joint multimodal 임베딩 공간으로 임베딩
I_e : l2_normalize(np.dot(I_f, W_i), axis=1):I_f: 이미지 특징을W_i: 가중치 행렬로 투영한 후 L2 정규화 수행해서 이미지 임베딩을 얻음T_e : l2_normalize(np.dot(T_f, W_t), axis=1)
-
scaled pairwise cosine similarities [n, n] : 이미지와 텍스트 임베딩 간의 pairwise 코사인 유사도를 계산하고 온도 파라미터를 사용해 스케일링
logits = np.dor(I_e, T_e.T) * np.exp(t): 이미지 임베딩I_e와 텍스트 임베딩T_e간의 행렬 곱셈을 통해 코사인 유사도를 계산하고, 온도 파라미터의 지수 함수를 곱해 로짓을 얻기
🥨 로짓을 얻는다?
- 로짓(Logit)은 확률 p를 odds(성공 확률 대 실패 확률의 비율)로 변환한 다음, odds에 로그를 취한 값
- 확률을 모델링하기 위해 사용되는 함수로, 0과 1 사이의 확률 값을 실수 전체 범위로 확장시켜 줌
- 로짓 값이 0에 가까울수록 모델은 예측에 대해 불확실함
CLIP에서 로짓을 얻는 이유
- 로짓은 이미지와 텍스트 임베딩 간의 유사도를 나타내는 점수이며, 높을 수록 이미지와 텍스트가 잘 맞는다고 판단
- 온도 파라미터 t를 이용해 로짓의 스케일을 조정함으로써, 모델은 올바른 쌍을 더 잘 식별하고 잘못된 쌍을 더 잘 구별할 수 있음
- 이후 로짓은 Softmax 함수의 입력으로 사용 -> 로짓 값을 확률 분포로 변환하여 각 클래스에 대한 확률을 얻을 수 있음
- #symmetric loss function : 대칭 손실 함수
labels = np.arange(n): 0부터 n-1까지 숫자를 담은 배열을 생성loss_i = cross_entropy_loss(logits, labels, axis=0)cross_entropy_loss: 교차 엔트로피 손실 함수 계산. 두 확률 분포 간의 차이를 측정하는게 사용. 여기서는 예측된 유사도(logits)와 실제 레이블(labels) 간의 차이를 계산logits: 이미지와 텍스트 임베딩 간의 유사도 점수 = 얼마나 잘 매칭되는지labels: 정답 레이블axis=0: logits의 0번째 축을 기준으로 계산. 즉, 각 이미지에 대한 손실 계산
loss_t = cross_entropy_loss(logits, labels, axis=1): 위와 동일하지만 텍스트에 대한 손실을 계산loss = (loss_i + loss_t)/2: 두 손실의 평균- 이렇게 손실 함수를 정의
Training
- 5개의 ResNets와 3개의 ViT를 가지고 train
Result
실험을 정말 엄청나게 많이 하심
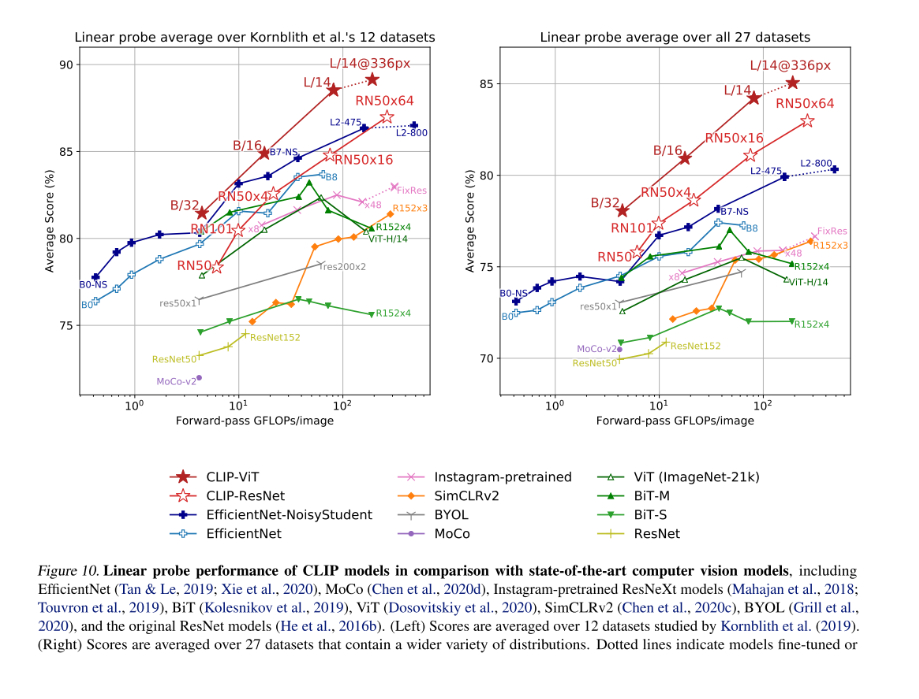
- x축 (Forward-pass GFLOPs/image) : 모델이 이미지 하나를 처리하는 데 필요한 계산량. 오른쪽으로 갈수록 계산량이 많고 무거운 모델.
- y축(Average Score %): 모델의 성능
Linear Probe평가 : 사전 학습된 모델의 인코더 부분(특징 추출기)은 고정시키고, 간단한 선형 분류기를 추가로 학습시켜 성능을 평가하는 방식.
- 모델이 사전 학습 단계에서 데이터의 본질적인 특징을 얼마나 잘 학습했는지
🥨 Linear Probing
가장 단순한 분류기(ex. 특징만 보고 사진을 분류하는 알바생)를 붙여서 테스트 했을 때 성능이 얼마나 잘 나오는지 테스트해서 원래 있는 모델(ex. 사진의 특징을 뽑아내는 전문가)이 얼마나 데이터를 잘 이해하고 핵십 특징을 잘 뽑아내는지 평가하는 방법!
- Zero-shot transfer의 경우 이미지 분류에서 압도적인 성능을 낼 수 있음
모델 돌려보기
pip install git+https://github.com/openai/CLIP.git일단 clip 모델을 설치해주고
import torch
import clip
from PIL import Image
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device) # preprocess 함수model은 ViT 모델 가져옴!
preprocess 하는 함수는 ViT에게 특화된 파이프라인!
# 이미지 로드 및 전처리
image = preprocess(Image.open("danbibest.jpg")).unsqueeze(0).to(device)
queries = [
"basketball player", "a tylenol ER", "woman basketball player dribbling", "a runner", "so many basketball players"
]
text = clip.tokenize(queries).to(device) # torch.Size([5, 77])- preprocess(...) : CLIP 모델을 로드할 때 함께 제공하는 함수
- 이미지를 CLIP 모델이 학습된 특정 크기로 조정
- 이미지를 pytorch 텐서 형태로 변환
- 이미지 픽셀 값을 특정 평균과 표준편차로 정규화!
- unsqueeze(0) : 전처리된 이미지 텐서는 보통 [c, h, w]인데 모델은 batch단위로 받으므로 앞에 1추가
- [5,77] : 텍스트 5개에 대해 각각 77개의 토큰 ID를 가진다는 의미 : 내가 queries에 5개를 넣었으니까!
참고로 내가 쓴 사진은 킹단비

with torch.no_grad():
image_features = model.encode_image(image) # [1. embed_dim] = [1, 512]
text_features = model.encode_text(text) # [5,512] <- [5,77]에서 변환
logits_per_image, logits_per_text = model(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()이미지와 텍스트의 특성을 가지고 와준다
- 처음에 텍스트의 토큰 ID 시퀀스는 [5,77]!
- 텍스트 인코더의 역할은 입력으로 받은 토큰 ID 시퀀스 [5,77]을 분석해서 각 텍스트가 담고 있는 실제 의미를 나타내는 고정된 크기의 벡터로 변환하는 것
- [5,77] -> [5,77, 내부차원] -> (전체 시퀀스 하나로 압축) -> [5, 내부차원] -> (projection. 대표 벡터를 이미지 임베딩과 동일한 최종 임베딩 차원으로 매핑하는 선형 레이어 통과) -> [5,512]
- 결국 5개의 텍스트 각각에 대한 512차원의 의미를 담은 벡터가 됨
# normalized features
# 유사도 계산에 코사인 유사도 사용하기 위해 각 특징 벡터의 크기를 1로 만듦
image_features = image_features / image_features.norm(dim=1, keepdim=True) #shape:[1,1]
text_features = text_features / text_features.norm(dim=1, keepdim=True) #shape:[5,1]
# 유사도 계산 및 스케일링
logit_scale = model.logit_scale.exp()
logits_per_image = logit_scale * image_features @ text_features.t() # (1, 512) @ (512, 5)
logits_per_text = logits_per_image.t() # 텍스트 관점에서의 유사도 [5,1]
이미지 특징 벡터와 텍스트 특징 벡터들을 사용해 이미지와 각 텍스트 설명 간의 유사도를 계산하고 확인하는 부분!
logit_scale=model.logit_scale.exp(): 모델 내부의 학습 가능한 파라미터인logit_scale에 지수 함수exp()적용- 그리고 정규화된 이미지 벡터[1,512]와 전치된 텍스트 벡터[512,5(=텍스트 개수)] 간의 행렬 곱셈 수행
print(logits_per_image.shape, logits_per_text.shape)
print(logits_per_image) # 원시 유사도 점수
print(logits_per_image.softmax(dim=-1)) #softmax 적용
---
>>> torch.Size([1, 5]) torch.Size([5, 1])
>>> tensor([[26.5781, 16.3438, 30.6094, 20.7812, 19.9844]], device='cuda:0',
dtype=torch.float16, grad_fn=<MmBackward0>)
>>> tensor([[1.7441e-02, 6.5565e-07, 9.8242e-01, 5.2989e-05, 2.3901e-05]],
device='cuda:0', dtype=torch.float16, grad_fn=<SoftmaxBackward0>)유사도 계산 결과!
# 최종 확률 추출
confidences = logits_per_image.softmax(dim=-1).detach().cpu().numpy().ravel()
for confidence, query in zip(confidences, queries):
print(query, ":", confidence)
basketball player도 점수가 낮네...신기

woman 넣으니까 점수 확 늘어남...신기22..
모델 구조 확인
VisionTransformer(
(conv1): Conv2d(3, 768, kernel_size=(32, 32), stride=(32, 32), bias=False)
(ln_pre): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(transformer): Transformer(
(resblocks): Sequential(
(0): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=768, out_features=768, bias=True)
)
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=768, out_features=3072, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=3072, out_features=768, bias=True)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(1): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=768, out_features=768, bias=True)
)
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=768, out_features=3072, bias=True)
(gelu): QuickGELU()
...
)
)
(ln_post): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)Transformer(
(resblocks): Sequential(
(0): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=512, out_features=512, bias=True)
)
(ln_1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=512, out_features=2048, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=2048, out_features=512, bias=True)
)
(ln_2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
(1): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=512, out_features=512, bias=True)
)
(ln_1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=512, out_features=2048, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=2048, out_features=512, bias=True)
)
(ln_2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
...
(ln_2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
)
)끝~
