#Transformer #ComputerVision
아키텍처 스터디 6주차
paper_link, github_code
A ConvNet for 2020 리뷰하려고 했는데 Swin Transformer 이야기가 자꾸 나와서 변경...
Abstract
- 컴퓨터 비전에서 범용적인 백본 역할을 수행할 수 있는 새로운 Vision Transformer인 Swin Transformer를 소개합니다!
Introduction
컴퓨터 비전은 오랜 시간 동안 CNNs(Convolutional neural network)에 의해 지배되어 있었다. AlexNet과 ImageNet 이미지 분류 챌린지의 혁신적인 성능을 시작으로 CNN은 더욱 스케일이 크고 광범위한 연결, 더 정교한 형태를 통해 점점 더 강력해지도록 진화했다.
반면 NLP 분야에서는 Transformer라는 다른 경로를 택하게 되었다.
- We seek to expand the applicability of Transformer such that it can serve as a general-purpose backbone for computer vision, as it does for NLP and as CNNs do in vision.
언어 모델의 높은 성능을 비전 도메인으로 이전하는 어려움은 두 모달리티의 차이점 떄문이다.
- scale 문제 : 언어 Transformer에서 기본적 요소로 활용되는 언어 토큰과는 달리 비전 요소는 scale에 따라 다양해질 수 있다. -> 이는 object detection과 같은 작업에서 주목받는 문제다! 기존의 Transformer 기반 모델에서 토큰은 모두 고정된 scale을 가지고 있으며, 이는 이러한 vision application에는 적합하지 않은 속성이다.
- resolution 문제 : image pixel은 텍스트 passage의 단어보다 해상도가 높다.
이러한 문제를 해결하기 위해 ==Swin Transformer== 을 제안한다.
계층적인 feature map을 구성하고 이미지의 크기에 대해 선형적인 computational complexity를 가지는 범용 Transformer backbone!
Swin Transformer VS ViT
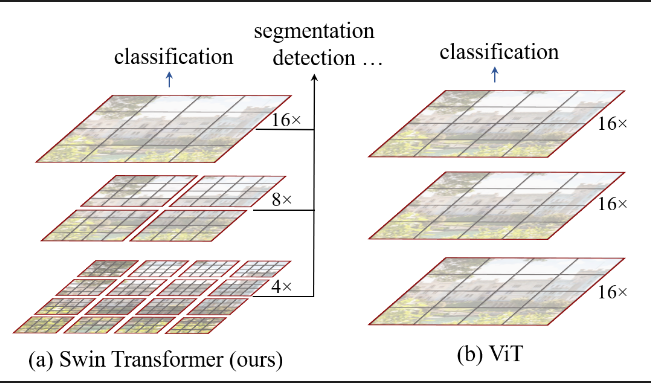
1. 다양한 해상도의 특정 맵을 만들기 때문에 고급 구조와 쉽게 연결할 수 있음
- PN, U-Net과 같은 고급 구조는 다양한 스케일(해상도)의 정보를 활용하기 때문!
2. 윈도우 기반 self-attention은 선형(linear) 복잡도를 가진다?
- 일반 Transformer의 경우 256X256 이미지를 16X16 패치로 나누면 총 256개의 패치가 생긴다. 모든 패치에 대해 self-attention을 하면 계산량은 256X256 = 65,536이 된다. ==계산량 O(N^2)==
- 하지만 Swin Transformer의 경우 이미지 전체를 보지 않고 예를 들어 7X7 패치로 구성괸 작은 윈도우로 나눠서 attentiond를 한다.
- > 즉 한 윈도우 안에서는 49개의 패치만 비교하면 됨. -> 49 X49 = 2,401
- 윈도우가 이미지 전체에 걸쳐 반복되니까 윈도우수는 256/49 = 5개
- 전체 계산량은 2,401X5=12,000.
- 패치 수는 고정되어 있기 때문에 이미지가 커지면 윈도우 수만 증가한다.
- ==계산량 O(N)==
Shifted Window
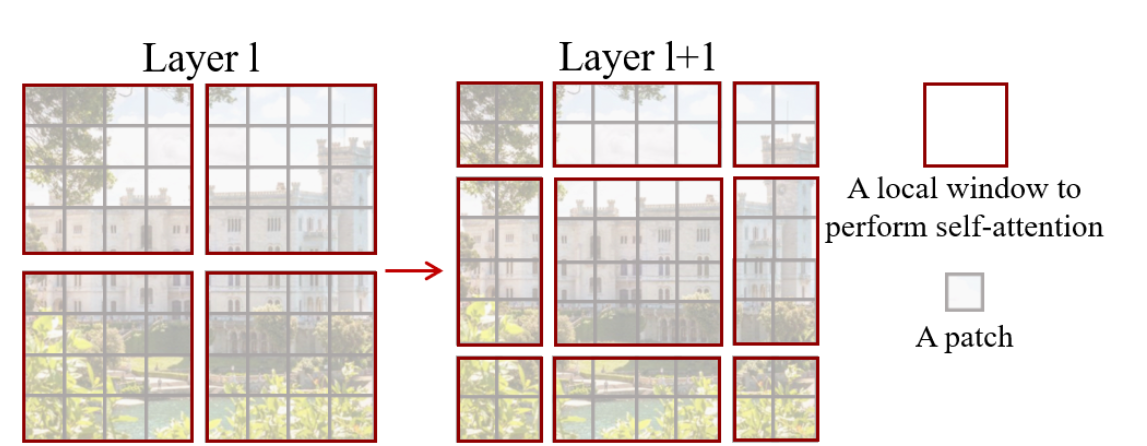
Attention 층이 하나 지나갈 때마다 윈도우를 일괄적으로 반 칸씩 이동하면 이전 층에서 나뉘어져 있는 윈도우 간 연결이 생기고 Attention 영역이 넓어진다.
Method
1 Overall Architecture
Architecture
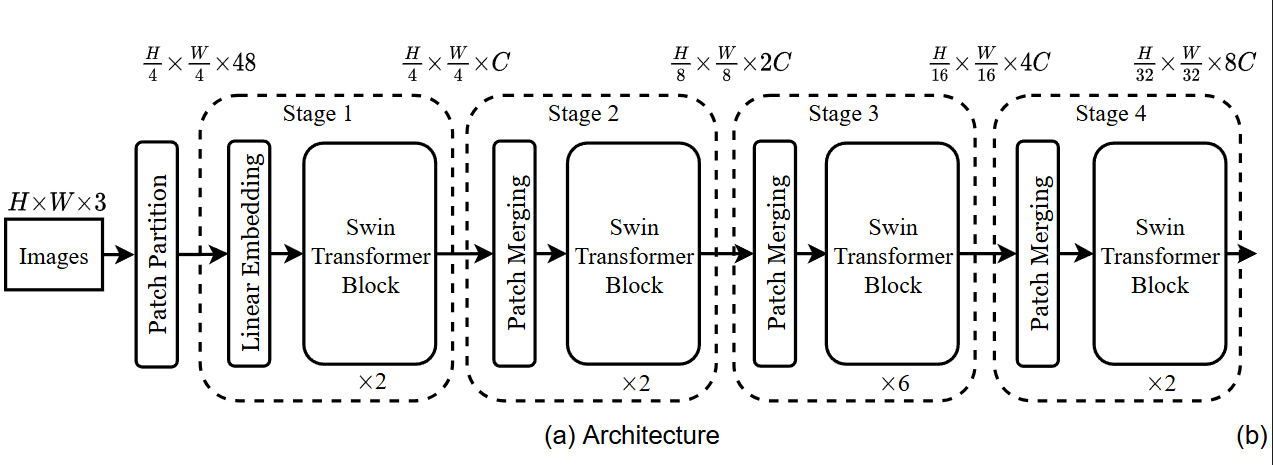
- 우선 ViT와 같이 패치 분할 모듈을 사용해 입력 RGB 이미지를 겹치지 않는 패치로 분할
- 각 패치는 'token'으로 취급되고 해당 특징은 원시 RGB 값의 연결로 설정됨
- 해당 구현에서는 4X4 패치 크기 이므로 각 패치의 특징 차원은
4X4X3=48
= 각 패치에는 48개의 픽셀값이 들어있다!
[Stage 1]
- 입력:
H/4 × W/4 × 48 - 구성: Swin Transformer Block × 2개
- 출력 채널 수:
C
[Stage 2]
- Patch Merging: 이웃한 2×2 패치를 합쳐 해상도 절반으로 줄이고, 채널 수는 2배로 증가 →
H/8 × W/8 × 2C
- 본래는 4개의 패치를 합치기 때문에 채널 수가 4C여야 하지만 너무 많으므로 압축한 것 - Swin Transformer Block × 2개
[Stage 3]
- Patch Merging →
H/16 × W/16 × 4C - Swin Transformer Block × 6개
[!question] 왜 Stage3만 Swin Transformer Block이 6개?
- 가장 핵심적인 특징 학습 단계이기 때문!
- 이 단계에서의 특성 맵은 해상도는 어느 정도 줄어들고 채널 수는 많이 증가해 정보를 정제하기에 좋은 밀도를 가졌으므로 더 많은 블록을 써서 복잡한 패턴을 학습한다.
- 이건 저자들이 다양한 block 수를 조합한 결과 나온 결론
[Stage 4]
- Patch Merging →
H/32 × W/32 × 8C - Swin Transformer Block × 2개
Swin Transformer Block
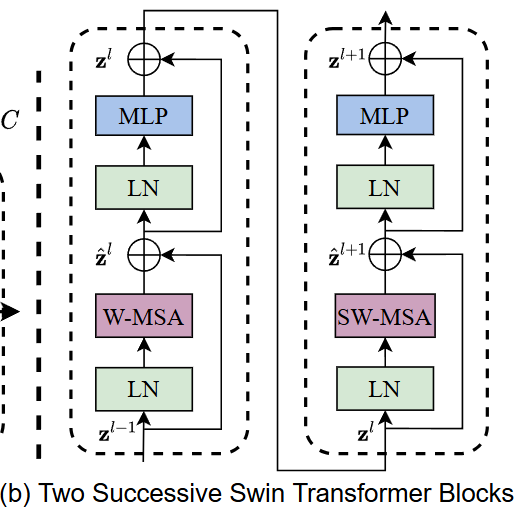
- Transformer Block 안에 있는 MSA(Multi-head self attention) 모듈을 Shifted windows 기반 모듈로 바꿨다.
- Swin Transformer 블록은 shifted window 기반의 MSA 모듈과 그 뒤에 GELU 비선형을 가진 2-layer MLP로 구성된다. LN은 각각 MSA와 MLP 이전에 실행!
- W-MSA는 윈도우 안에서만 attention을 진행하고 SW-MSA는 윈도를 반칸 옮겨서 새로운 윈도우를 구성한다.
2 Shifted Window based Self-Attention
[Self-attention in non-overlapped windows]
= 겹치지 않는 윈도우 안에서 self-attention
위의 경우 (hw)^2 항 때문에 패치 수가 많을 수록 계산량 제곱으로 늘어나지만
아래(Window 기반)의 경우 M은 윈도우 크기니까 고정되어 있으므로 전체 복잡도는 O(hw)
=> 이미지 크기가 커져도 계산량이 폭증하지 않음
[Shifted Window Partitioning in successive blocks]
= 윈도우를 밀어 연결성 확장
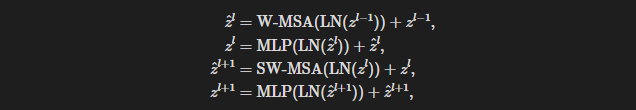
W-MSA -> MLP -> SW-MSA -> MLP 이렇게 번갈아서 사용!!
[Efficient batch computation for shifted windows]
= 효율적인 계산 방식
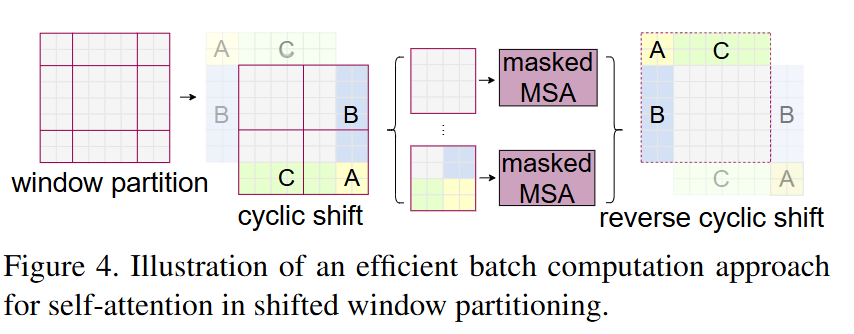
문제 상황 : 윈도우를 Shift하면 윈도우 수가 늘어난다.
- ex. 8X8 이미지에 4X4 윈도우를 쓰면 윈도우 총 4개.
- BUT 윈도우를 (M/2, M/2)만큼 밀면, 경계에 걸쳐서 분할되는 경우가 생겨 9개가 생길수도!
해결법 : Cyclic Shift + Masked MSA
1. Window partition
- 원래 윈도우 위치에서 non-overlapping하게 나눔
- A, B, C는 서로 다른 윈도우에 속한 패치들
2. Cyclic shift
- 윈도우 전체를 오른쪽 아래로 M/2 만큼 이동
- 이때 일부 윈도우는 두 개 이상의 윈도우 조각으로 구성
3. masked MSA(self-attention)
- 각 윈도우 안에서 attention 계산
- 서로 다른 원래 윈도우 출신끼리는 연결하지 않도록!
-> masking을 사용해서 자기 그룹끼리만 attention 계산
4. Reverse cyclic shift
- 계산이 끝난 후 다시 원래 위치로 복원
3. Architecture Variants
- Swin-T: C = 96, layer numbers = {2, 2, 6, 2}
- ResNet-50과 유사 - Swin-S: C = 96, layer numbers ={2, 2, 18, 2}
- ResNet-101과 유사 - Swin-B: C = 128, layer numbers ={2, 2, 18, 2}
- Swin-L: C = 192, layer numbers ={2, 2, 18, 2}
C는 첫 stage에서 hidden layers의 채널 수
Experiment
- 실험 : ImageNet-1K 이미지 분류, COCO 객체 감지, ADE20K semantic segmentation
1. Image Classification on ImageNet-1K
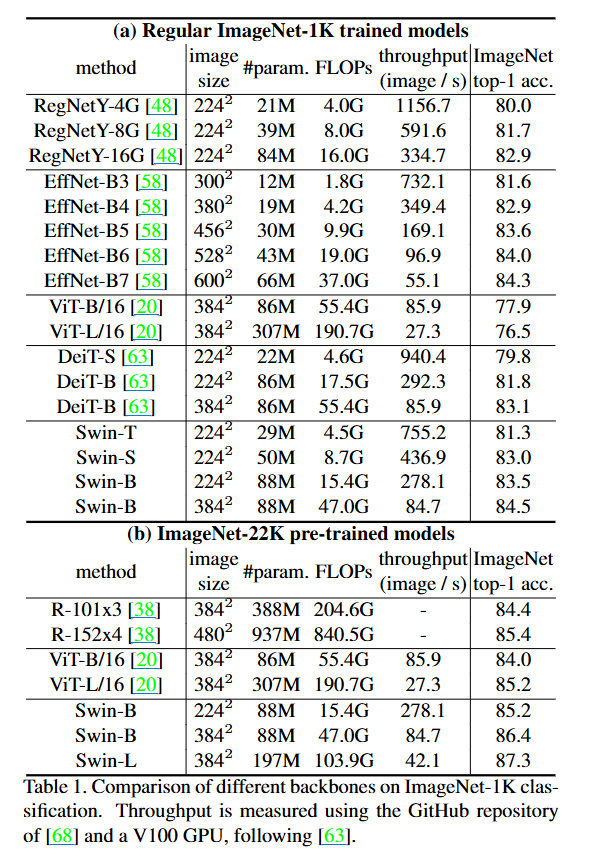
🍳 혼자 북적북적...
==[Float32]가 의미하는 것==
컴퓨터가 부동소수점을 저장하고 계산하는 방식 중 하나. 32비트 부동소수점 의미
float32는 총 32비트(4byte)로 구성되고 3가지로 나뉨
- 1비트 : 부호(sign)
- 8비트 : 지수부(exponent) : 소수점의 위치를 결정 (2의 몇 제곱?)
- 23비트 : 가수부(mantissa)
- 부호 1비트 + 지수 8비트 + 가수 23비트 = 32비트
🌱 가수부?
- 숫자의 실제 유효 숫자(정밀도)를 담고 있는 부분
==부동소수점 연산==
컴퓨터가 소수점을 포함한 수를 가지고 수행하는 계산
- 고정소수점:
0001.1010(소수점 위치 고정됨)- 부동소수점:
1.101 × 2^3(소수점 위치가 지수로 표현됨)==FLOPs란?==
컴퓨터가 1초 동안 수행할 수 있는 부동소수점 연산의 횟수 => 연산량
2. Object Detection on COCO
![[Pasted image 20250509124210.png]]
여기서 backbone이란 해당 모델로 이미지의 특징을 추출했다는 것, 그리고 Method는 객체 탐지와 인스턴스 분할을 어떻게 수행할 것인지에 대한 전략을 뜻함!
AP: Average Precision : 객체 탐지 모델이 예측한 박스가 실제 객체와 얼마나 잘 맞는지 측정함. 정확도와 재현율의 곡선을 기반으로 한 면적(AUC)을 계산한 값.
-APbox: 다양한 IoU(Intersection over Union) 임계값을 평균낸 종합적인 성능 지표
-APbox50: IoU가 0.50 이상일 때만 정확도로 평가한 AP이며 느슨한 기준
-APbox75: 엄격한 기준. 거의 다 맞아야 정답! 모델의 정밀도를 강조하는 지표
backbone에서 ResNet과 비교했을 때 모든 method와 평가방법에서 더 나은 성능을 보임!
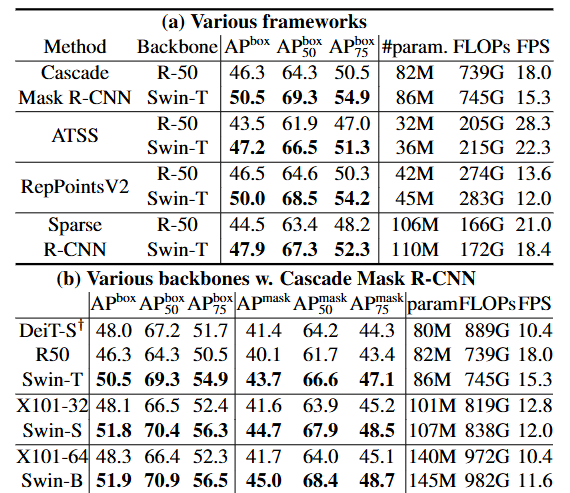
다른 SoTA 모델과 비교했을 때도 높은 성능을 보임.
3. Semantic Segmentation on ADE20K
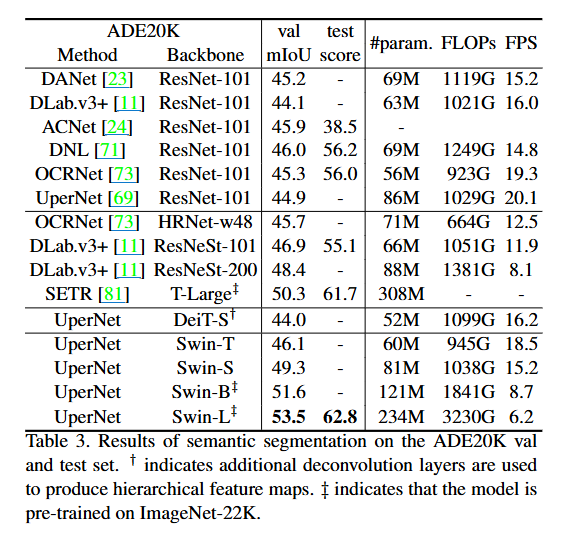
4. Ablation Study
Conclusion
This paper presents Swin Transformer, a new vision Transformer which produces a hierarchical feature reprsentation and has linear computational complexity with re-
spect to input image size.
Swin Transformer achieves the state-of-the-art performance on COCO object detection and
ADE20K semantic segmentation, significantly surpassing previous best method.
핵심은 Shifted-Window based self-attention! -> vision problem에 있어 효과적이고 효율적이다!
