'25 아키텍처 스터디 3주차
- paper link
- 때로는 줄글이 설명에 나을 때가 있구나 싶었네요
CLIP은 zero-shot classification에서 뛰어난 성능을 보여주었지만, 여전히 한계가 있었다.
이러한 한계를 극복하고자 FLamingo는 few-shot learning에 중점을 두고 개발되었다.
Abstract
논문 뽀인트 : 소수의 예제(few-shot)로 다양한 task를 빠르게 적응 및 수행할 수 있는 VLM!
구조적인 특징
- 사전 학습한 모델들을 활용해 해당 모델들이 갖고 있는 이점을 활용
- 정해진 순서가 아닌 임의의 순서로 나열된 이미지, 텍스트 시퀀스를 처리할 수 있음!
- 이미지 뿐만 아니라 영상 또한 입력으로 받아 원활하게 소화!
Input prompt

사진을 보면 두 개의 예시만으로 마지막 사진을 묘사하는 것을 볼 수 있다. 더욱이 어떤 종인지 분류하는 걸 넘어서 이미지로는 알 수 없는 동물의 특징까지 이해하고 설명한다.

이렇게 특정 이미지를 가지고 대화를 나누는 모습도 볼 수 있다.
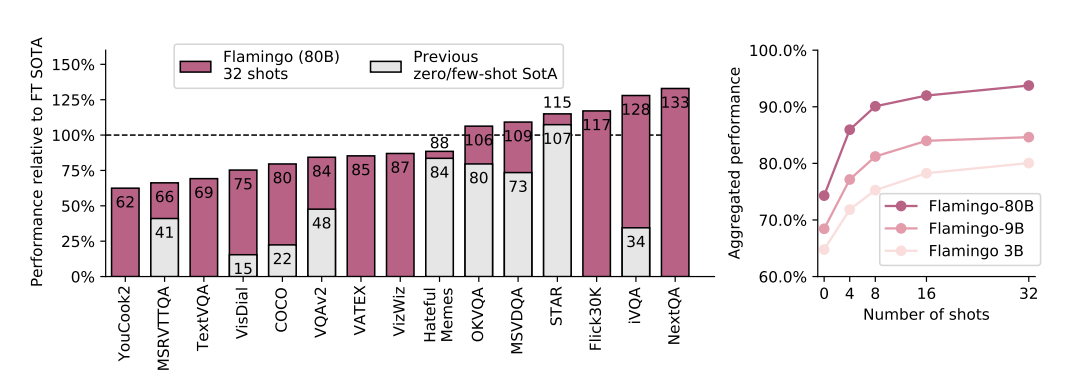
왼쪽 그림
- zero/few shot sota 모델과 비교했을 때 Flamingo-80B는 모든 15개의 task에서 sota 모델보다 뛰어난 성능을 보였다.
- 이때 그래프의 100%의 기준은 파인튜닝된 SotA로, 6개의 task에서는 플라밍고가 더 나은 성능을 보였다.
오른쪽 그림
- 예시(=shot)의 수에 비례하여 Flamingo의 성능이 얼마나 늘었는지는 보여주는 것.
🏀 성능부터 시작하는 논문이라니 신기함..
Architecture
This section describes Flamingo: a visual language model that accepts text interleaved with images/videos as input and outputs free-form text.
= VLM 모델에 대해서 설명! 여기서 text interleaved with images/videos는 text와 images/videos가 번갈아가며 섞여 나온다는 뜻. 이러한 input을 받으면 flamango는 output으로 자유로운 형식의 text를 내뱉는다.
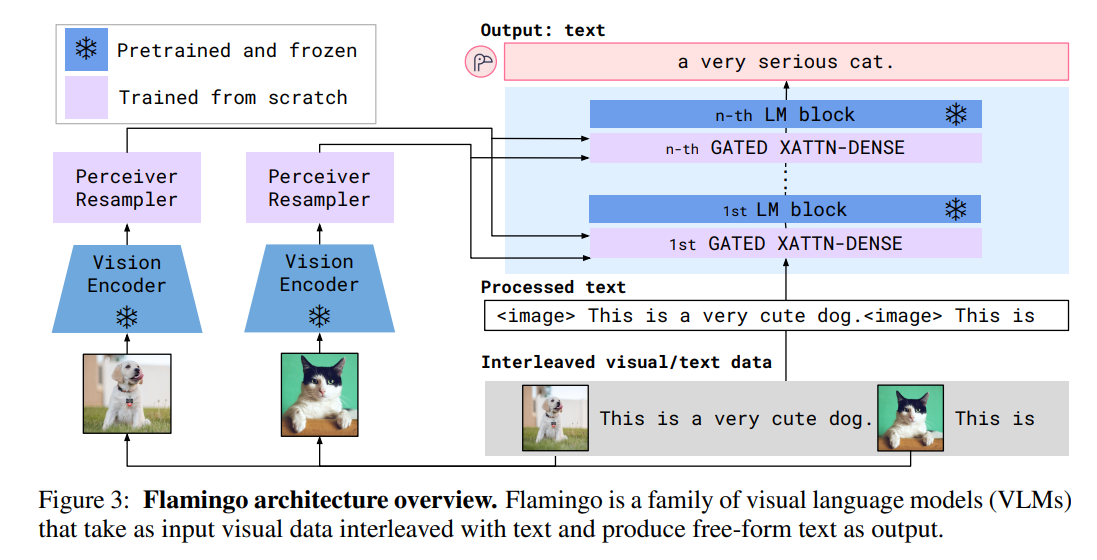
-
먼저
Perceiver Resampler가 Vision Encoder로부터 시공간적 특성을 받고, 고정된 숫자의 visual token을 내뱉는다. -
이러한 visual token은 새롭게 초기화된 cross-attention layers를 사전학습된 LM Layers 사이에 넣음으로서 고정된 언어 모델(LM)을 조정하는데 사용된다.
= 처음부터 잘 훈련된 사전학습된 LM을 가져다가 가중치를 얼려놓고, 대신에 사이사이에 cross attention layer를 새로 넣어서 시각 정보가 텍스트 처리에 영향을 주도록 조절하는 것! -
Flamingo는 text y가 나올 확률을 모델링하는데, 이때 이미지와 비디오가 섞인 입력 x를 조건으로 한다.
여기서 은 입력 text의 l번째 언어 토큰, 은 이전 토큰, 은 텍스트와 이미지가 섞여 있는 시퀀스에서 l 번째 토큰보다 앞쪽에 있던 시각 정보를 말한다.
🏓 좀 더 쉽게...!
- 입력
[이미지] This is a very cute dog. [이미지] This is ...이렇게 이미지와 텍스트가 순서대로 번갈아서(interleaved) 들어감!
- 비전 인코터 + Perceiver Resampler
- vision encoder에서는 사전 학습된 이미지 인코터(ex.clip, vit...)가 사용된다. 눈송이의 의미는 Frozen! 더 이상 학습되지 않는다는 의미
- Perceiver Resampler에서는 이미지 인코더에서 나온 고차원 feature들을 압축하고 재구성해서 텍스트 모델에 연결할 수 있는 정제된 feature로 바꾸는 것 (trained from scratch)
텍스트 처리
<image>토큰으로 이미지 위치를 명시해주면서 텍스트를 같이 처리!Language Model Block
- 텍스트와 이미지 피처들이 함꼐 들어가는 멀티모달 transformer 부분
- GATED XATTN-DENSE 블록 : 이미지 피처와 언어 정보를 융합
- LM BLock : 일반적인 텍스트 생성 블록
- 최종적으로 생성되는 텍스트
- a very serious cat
1. Visual processing and the Perceiver Resampler
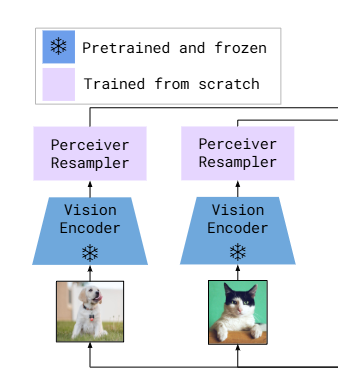
Vision Encoder: from pixels to features
- 사전학습된 F6 모델을 사용하며 학습 시에 수정하지 않는다.
- 이미지와 텍스트로 이루어진 자체 데이터셋에서 대조 학습 목적을 사용하여 vision encoder를 사전학습시킨다. 이때 CLIP 논문에서 제안한 양방향 대조 손실 함수를 사용한다.
- 마지막 계층의 출력, 2D 공간적 피처맵을 한 줄 시퀀스로 펼친(Flatten)다.
= 이미지 -> 2D 피처맵 -> 1D 시퀀스 - 비디오의 경우 초당 1장씩(=1FPS) 샘플링을 하고 따로따로 인코딩하면 그 결과 시공간적 3차원 피쳐맵이 만들어지고, 시간 순서 반영을 위해 temporal embedding을 추가한다. 이것도 1D 시퀀스로 변환하고 다음 모듈로 토스!
Perceiver Resampler : from varying-size large feature maps to few visual tokens
Perceiver 논문도 있음!
-> link
이 모듈은 vision encoder를 고정된 LM에 연결하는 작업을 한다. 언어 모델은 고정된 길이의 context를 원하기 때문에, 항상 64개나 32개의 고정된 길이의 latent 벡터로 변경해야 한다. 때문에 고정 개수의 학습 가능한 latent 벡터들을 초기화해둔 다음, 이 벡터들이 에 대해서 cross-attention을 수행한다. 이때 는 각 프레임의 피처를 평탄화(flatten)해서 모두 하나의 시퀀스로 concat해서 만든 것이다.
- Latents : 학습 가능한 고정된 수의 쿼리 벡터들
🥨 Perceiver Resampler 구조를 뜯어보자
먼저 처음에는
Latents: [L₁, L₂, ..., Lₖ] ← 학습 가능한 고정된 벡터들 (k=64 등) X_f: [x₁, x₂, ..., xₙ] ← CNN으로 뽑은 이미지 feature들 (n=수천 개 가능)이런 식으로 주어지고, 이제 latents가 X_f를 보면서 요약하는 단계가 필요하다.
[L₁, ..., Lₖ] ⬅️ cross-attend to ⬅️ [x₁, ..., xₙ]여기서 query는 latents이고, X_f는 key, value. 결과적으로 latent는 이미지의 일부를 요약한 표현이 된다.
그다음으로는 이 latents끼리 서로 대화하며 요약된 내용을 더 정제하는 단계!
[L₁, ..., Lₖ] → self-attend → [L₁′, ..., Lₖ′]일반적인 transformer block과 같다.
이렇게 여러 층을 쌓아가면서 점점 더 정제된 요약을 만들어간다. Cross-attention은 필요한 정보만 뽑아오고, Self-attention은 그것들을 더 조합해서 더 정제할 수 있는 것이죠.
2. Conditioning frozen language models on visual representations
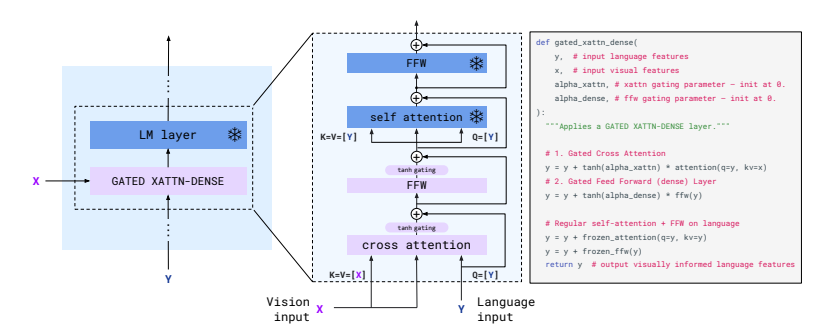
여기서 사용되는 건 frozen된 LM Layer와 그 사이에 들어가 있는 GATED XATTN-DENSE block이다.
GATED XATTN-DENSE
GATED XATTN-DENSE = Cross Attention + FFN (둘 다 gating됨)GATED XATTN-DENSE로 들어가는 input값은 두 개다. Vision input(X)와 Language input(Y).
- Language input은 현재 시점에서 모델이 주의 집중하려는 정보의 출처, 그러니까 무엇에 집중할거야? 를 의미하기 때문에 Query로 들어간다.
- 그것에 대한 답변을 제공하는 Vision input은 Key와 Value로 들어간다.
해당 블록은 먼저 시각 정보 X를 언어 정보 Y에 반영한 다음(=Cross attention), 언어 정보(Y) 비선형적으로 변환(=FFW)한다. 이때 이를 얼마나 반영할 지 alpha_xattn이라는 learnable scalar로 조절하는데 이를 게이트라고 한다.
y = y + tanh(alpha_xattn) * attention(q=y, kv=x)
y = y + tanh(alpha_dense) * ffn(y)🥐 게이팅이란?
입력값에 어떤 스칼라(또는 벡터)를 곱해서 정보량을 조절하는 방식으로 필요한 정보만 통과시키고 모델의 안전성 유지를 위해 필요하다.
output = tanh(α) * some_input해당 예시에서 는 학습 가능한 파라미터고, 는 -1에서 1 사이의 값이 나온다. 결과적으로 입력값에 이 값을 곱했을 때 0에 가까우면 정보를 거의 막고 1에 가까우면 정보를 그대로 내보내는 것. 그리고 음수면 정보를 반전시켜서 보낸다.
LM Layer
y = y + frozen_attention(q=y, kv=y)
y = y + frozen_ffn(y)해당 부분은 사전 학습된 언어 지식을 유지하도록 도와주는 부분이며 학습되지 않는다.
최종 OUTPUT
이렇게 모든 block을 거치고 나면, 최종적으로 나오는 output은 시각 정보가 반영된 텍스트 토큰 시퀀스다.
a serious cat~
Experiments
- 16개의 유명한 image/video & language benchmark를 사용하였다.
- 사용한 데이터셋은 다음과 같음!
- M3W (MultiModal MassiveWeb): 이 데이터셋은 4,300만 개의 웹페이지에서 수집된 이미지와 텍스트 데이터로 구성되어 있으며, 각 웹페이지에서 이미지와 텍스트의 위치 관계를 기반으로 시각 데이터를 추출
- ALIGN: 18억 개의 이미지와 대체 텍스트(alt-text) 쌍으로 구성된 데이터셋
- LTIP (Long Text & Image Pairs): 3억 1,200만 개의 이미지와 긴 설명 텍스트 쌍으로 구성된 데이터셋
- VTP (Video & Text Pairs): 평균 22초 길이의 2,700만 개의 짧은 비디오와 해당 비디오에 대한 문장 설명으로 구성된 데이터셋
- M3W (MultiModal MassiveWeb): 이 데이터셋은 4,300만 개의 웹페이지에서 수집된 이미지와 텍스트 데이터로 구성되어 있으며, 각 웹페이지에서 이미지와 텍스트의 위치 관계를 기반으로 시각 데이터를 추출
Few shot
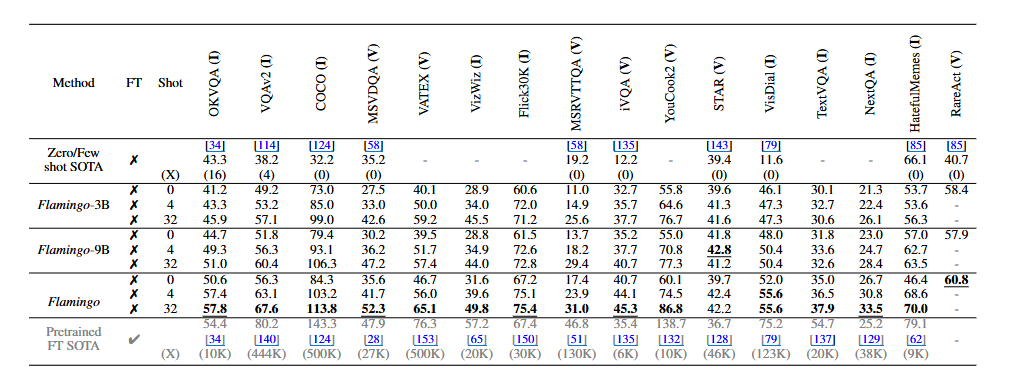
Flamingo outperforms by a large margin all previous
zero-shot or few-shot methods on the 16 benchmarks considered.
= 16개의 벤치마크에서 모든 zero/few shot SOTA를 큰 차이로 압도했다~
Pretrained FT SOTA: 해당 태스크에 맞춰서 모델 전체 또는 상당 부분을 파인튜닝한 경우로, 해당 task 데이터셋 전체를 써서 supervised learning 방식으로 훈련한 결과들!- 여기서 flamingo는 모델 대부분은 고정하고 적은 데이터로만 튜닝한 것
= task 전용 학습까지는 하지 않은 것!
Fine-tuning
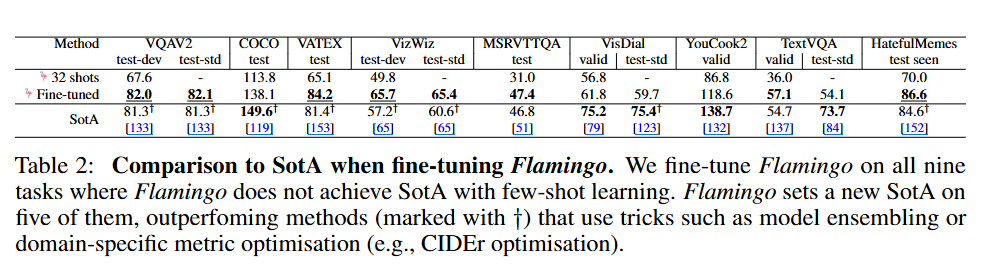
Flamingo가 Pretrained SOTA를 넘지 못한 9개의 테스크에 대해, Flamingo를 파인튜닝했다. 그 중 5개의 테스트에서 SOTA 성능을 찍었다~
= few shot만으로는 부족했던 task에 대해서 flamingo를 조금 튜닝해보니까! 더 잘했다~
= flamingo는 few shot만으로도 상당히 잘하지만! 일부 task에서는 조금의 fine-tuning만으로도 SOTA를 능가했다!
😯 FLamingo를 파인튜닝했다는 건, 각 task에 맞춰서 flamingo에게 few shot을 집어넣었다는 건가?? 정확히 어느 부분을 파인튜닝했다는 거지???
[Vision Encoder (CLIP)] → (frozen) ↓ [Perceiver Resampler] → (frozen) ↓ [Flamingo multimodal layers (Gated XAttn-Dense)] ← fine-tuned ⬅️ ↓ [Language Model (Chinchilla)] → (frozen)
Ablation Studies
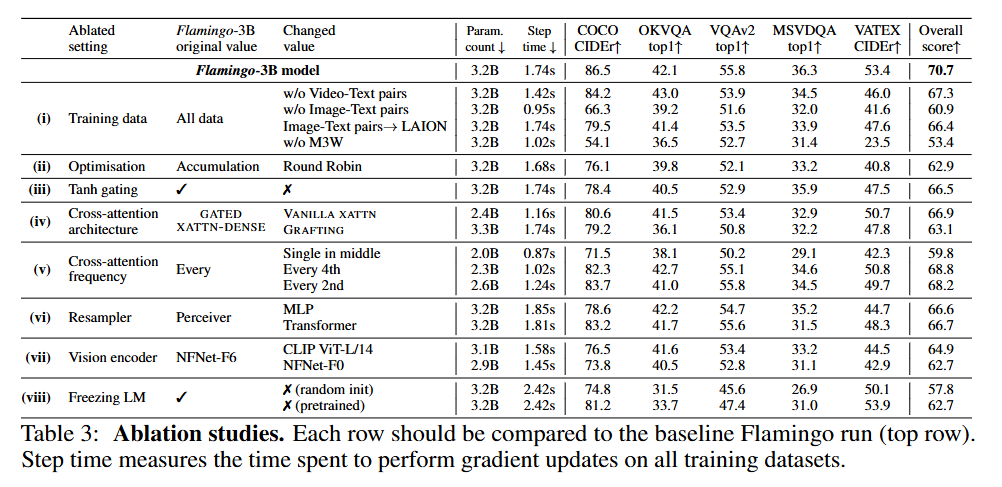
- 맨 위에 있는 것이 baseline model
- (i)의 경우 training data에서 M3W를 뺐을 때 가장 그 성능이 낮았음
- (ii)는 최적화 방식 : round-robin 업데이트를 사용하는 것보다, gradient accumulation 전략이 더 좋다는 것을 볼 수 있음!
- (iii)는 cross-attention 결과를 LM 출력과 함칠 때 사용하는 0으로 초기화된 tanh 게이팅 제거 실험 -> 전체 성능 4.2% 하락 ->
tanh 게이팅은 모델 성능에 영향을 미친다! - (iv)에서 vanila xattn과 grafting을 사용하자 성능이 떨어졌다. 그러므로 GATED XATTN-DENSE 구조가 더 적합하고 우수하다!
- (viii) : 언어 모델(LM)을 동결하는 것이 얼마나 좋을가?
- LM을 처음부터 학습하니 성능 하락 = 거대 언어 모델을 처음부터 학습시키는 건 비효율적이고 효과도 없다
- X pretrained : 사전 학습 가중치로 초기화한 후 학습 : 크게 하락
= 사전 학습된 언어 모델을 동결하는 것이절대적으로 중요하다!!!
Conclusion
이미지 및 비디오 작업에 최소한의 태스크별 훈련 데이터만으로도 적용 가능한 범용 모델인 Flamingo~
후기
열심히 하나하나 읽어보자! 했는데 넘 힘들어서 중간에 gpt 와의 심도깊은 대화를 함.
