'25 아키텍처 스터디 1주차
- vision transformer를 한 줄씩 해부해보자~~(진짜 한 줄씩...)
- 250403 아키텍처 돌아가는 것까지 확인
- paper link
- ICLR 2021
Abstract
- 해당 논문은 컴퓨터 비전 분야에서 Transforemr 구조를 효과적으로 활용하는 법을 제시하며 특히 대규모 데이터셋에서 사전 학습된 Vision Transforer(ViT) 모델이 기존의 CNN 기반 모델보다 뛰어난 성능을 보여준다는 것을 입증한다.
Method
- 모델은 Transformer를 최대한 가깝게 했다구 함!
- 방법론은 크게 3가지로 나눌 수 있음.
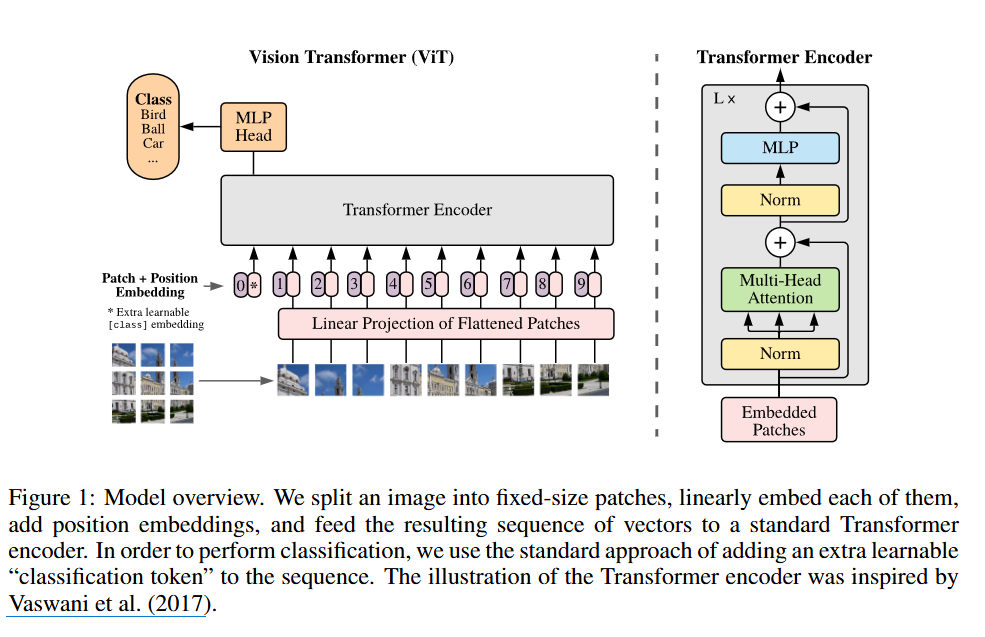
1 이미지 패치 분할 및 임베딩(Patch Extraction and Embedding)
- 원래 일반적인 Transformer는 토큰 임베딩에 대한 1차원의 시퀀스를 입력으로 받음!
- 이미지(x)를 고정 크기의 패치(xp)로 분할
ex. 224 X224 이미지에서 16X16 패치 추출하면 총 196개의 패치가 생김! - 각 패치를 Flatten
H X W X C->N X (P^2 X C)로 변환H: 이미지의 높이(Height)를 픽셀 단위로W: 이미지의 너비(width)를 픽셀 단위로!C: 이미지의 채널 수. 컬러이미지는 Red, Green, Blue, 세 개의 채널을 가지므로 C=3이 됨! 흑백이면 C=1겠죠?(P, P)는 이미지 패치의 크기- N = = 패치의 개수!!
- 그리고는 학습 가능한 선형 투영(linear projection)을 사용해 D 차원 벡터로 임베딩한다. 이 벡터를 패치 임베딩(Patch Embedding)이라고 부름!!
잠재 벡터 크기(Latent Vector Size) D : 트랜스포머 모델의 모든 레이어에서 일관되게 사용되는 고정된 크기의 벡터. 모델의 복잡도와 표현력을 결정하는 중요한 요소!!선형 투사(Linear Projection) : 평탄화된 패치를 D차원으로 매핑
🍪 ViT에서 D차원 매핑하면?
- 정보 압축 : 고차원 이미지 데이터를 효율적으로 처리할 수 있음
- 특징 추출 : 이미지의 중요한 시각적 특징을 효과적으로 표현
-> 데이터를 더 낮은 차원으로 변환하되 중요한 정보는 최대한 유지하는 과정!
- BERT의 [class] 토큰과 유사하게, 학습 가능한 분류 토큰(Classification Token)을 패치 임베딩 시퀀스 앞에 추가!
- 여기서 는 Transformer Encoder 안에 들어갈 입력값이고 는 학습이 가능한 classification token, 그리고 는임베딩된 이미지 패치들, 는 Position Embedding
- 핵심은 가 Transformer를 거치면서 이미지의 특징을 학습하고, 최종 단계에서 이미지 분류에 결정적인 역할을 한다는 점!
Classification Token: Transformer가 이미지 전체에 대한 정보를 집계하는데 도움을 주는 특별한 토큰.
2. Transformer Encoder
Multi-Head Self-Attention(MSA)레이어와MLP 블록이 번갈아 나타나는 구조- 각 블록 전에 Layer Normalization을 적용하고, 각 블록 후에는 잔차 연결(Residual Connection)을 사용함
🍪 Self-Attention 다시 정리하기
- 입력된 데이터 내에서 각 요소들이 서로 얼마나 중요한지를 계산하는 방법
- 이미지에서는? -> 각 패치들이 서로 어떻게 관련되어 있는지 파악하는 것
🍪 Self-Attention 계산과정
- Query(Q) : 내가 지금 주목하고 있는 패치
- Key(K) : 비교 대상 되는 친구들
- Value(V) : 실제로 정보를 가져올 패치들
- 먼저 입력된 패치들을 Q, K, V로 변환
- 각각의 패치는 학습 가능한 가중치를 통해 행렬로 변환
- 유사도 계산
- Query와 Key의 내적(dot product)을 계산!
- ex. 눈 패치와 코 패치는 관련이 높겠쥐?
- Softmax 적용해 정규화
- 중요한 패치에는 높은 점수, 덜 중요한 패치에는 낮은 점수
- Value를 곱해서 최종 결과 얻기
- 가중치를 적용한 Value 값들을 모두 더하면, 최종적으로 해당 패치의 새로운 표현을 얻을 수 있음!
🍪 MHSA는?
- 이 Self-Attention을 여러 번 수행하는 것
- 왜 여러 개의 Head 사용? -> 한 번으로는 모든 관계를 한꺼번에 파악하기 어려우므로 다양한 패턴을 학습하기 위해!
- MLP 블록은 GELU 비선형 함수를 사용하는 2개의 레이어로 구성!
- 는 MLP 블록의 최종 출력으로, 먼저 LN을 한 후에 MLP를 거친다!
🍪 Multilayer Perceptron(MLP)
- 여러 층의 퍼셉트론으로 구성된 인공 신경망의 한 종류
- 직접적으로 연결하면 선형성이 너무 강하기 때문에 은닉층을 배치!
- 마지막 출력!
- 는 최종 이미지 표현으로 모델이 이미지 분류를 하기 위해 사용되는 것
- : 트랜스포머 인코더의 L번째 레이어에서 Classification의 출력
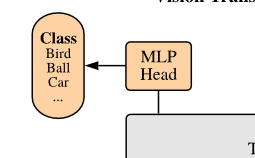
- 마지막으로 트랜스포머 최종 출력에서 [class] 토큰의 상태는 MLP Head를 통과해 최종 이미지 분류를 얻음!
아키텍처 구현해보기
Encoder 구현
# Encoder 클래스 구현하기
class encoder(nn.Module):
def __init__(self, embed_size=768, num_heads=3, dropout=0.1): # 드롭아웃 : 과적합 방지를 위해 일부 뉴런의 출력을 무작위로 0으로 만드는 정규화 기법
super().__init__()
self.ln1 = nn.LayerNorm(embed_size)
self.attention = nn.MultiheadAttention(embed_size, num_heads, dropout, batch_first=True) # 입력 텐서 차원 순서가 (배치 크기, 시퀀스 길이, 임베딩 차원)임을 명시
self.ln2 = nn.LayerNorm(embed_size)
self.ff = nn.Sequential(
nn.Linear(embed_size, 4*embed_size)
, nn.GELU()
, nn.Dropout(dropout)
, nn.Linear(4*embed_size, embed_size)
, nn.Dropout(dropout)
)
self.dropout= nn.Dropout(dropout)
def forward(self, x):
x = self.ln1(x)
x = x + self.attention(x, x, x)[0]
x = x + self.ff(self.ln2(x))
return xvision transformer부터 적기 시작해서 여기는 간단하게... forward 부분만...
def forward(self, x)- 실제 계산 과정!
- 여기서 x는 tensor. x의 형태는 (배치 크기, 시퀀스 길이, 임베딩 차원)
- n배치 크기는 한 번에 처리하는 문장의 개수. 시퀀스 길이는 각 문장(시퀀스)를 구성하는 토큰의 개수, 임베딩 차원은 각 토큰을 나타내는 벡터의 크기(여기서는 768)
x = self.ln1(x)첫 번째 레이어 정규화 적용
x = x + self.attention(x, x, x)[0]- 각 토큰은 스스로 query, key, value가 되어 서로 비교대상이 됨.
- 본래 multiheadattention의 반환값은
(어텐션 출력, 어텐션 가중치) - x를 더하는 것은 잔차 연결(Residual connection)을 의미. 원래정보를 보존하면서 새롭게 얻은 정보를 추가하는 과정.
x = x + self.ff(self.ln2(x))__init__ 에서 열심히 정의한 MLP를 ln2 이후에 적용시켜줍니다.
끝.
Vision Transformer 구현
class VisionTransformer(nn.Module):
def __init__(self, in_channels=3, num_encoders=6, embed_size=768, img_size=(324, 324), patch_size=16, num_classes=10, num_heads=4):
super().__init__()
self.img_size = img_size
self.patch_size = patch_size
num_tokens = (img_size[0]*img_size[1])//(patch_size**2)
self.class_token = nn.Parameter(torch.randn((embed_size,)), requires_grad=True)
self.patch_embedding = nn.Linear(in_channels*patch_size**2,embed_size)
self.pos_embedding = nn.Parameter(torch.randn((num_tokens+1, embed_size)), requires_grad=True)
self.encoders = nn.ModuleList([
Encoder(embed_size=embed_size, num_heads=num_heads) for _ in range(num_encoders)
])
self.mlp_head = nn.Sequential(
nn.LayerNorm(embed_size),
nn.Linear(embed_size, num_classes)
)
def forward(self, x):
batch_size, channel_size = x.shape[:2]
patches = x.unfold(2, self.patch_size, self.patch_size).unfold(3, self.patch_size, self.patch_size)
patches = patches.contiguous().view(x.size(0), -1, channel_size*self.patch_size*self.patch_size)
x = self.patch_embedding(patches)
class_token = self.class_token.unsqueeze(0).repeat(batch_size, 1, 1)
x = torch.cat([class_token, x], dim=1)
x = x + self.pos_embedding.unsqueeze(0)
for encoder in self.encoders:
x = encoder(x)
x = x[:,0, :].squeeze()
x = self.mlp_head(x)
return x한 줄 씩 봅시당
def __init__(self, in_channels=3, num_encoders=6, embed_size=768, img_size=(324, 324), patch_size=16, num_classes=10, num_heads=4):클래스 정의하고 초기화 함수를 시작!
파라미터를 한 번 살펴보자.
in_channels=3: 입력 이미지의 채널 수 (예: 3은 RGB 컬러 이미지)num_encoders=6: 사용할 트랜스포머 인코더 블록의 개수. 모델의 깊이를 결정!embed_size=768: 트랜스포머 내부에서 사용될 벡터(임베딩)의 차원(크기)img_size=(324, 324): 입력 이미지의 높이와 너비 (튜플 형태)patch_size=16: 이미지를 나눌 정사각형 패치의 한 변의 크기.num_classes=10: 최종적으로 분류할 클래스의 개수 (예: CIFAR-10 데이터셋이면 10).num_heads=4: 각 인코더 블록 내의 멀티헤드 어텐션에서 사용할 헤드의 개수.
전부 내가 바꿀 수 있는 파라미터들. 일단은 기본적으로 하는 파라미터를 사용함
super().__init__()nn.Module의 초기화 함수를 호출하는 것. 파이토치 모델을 만들어봤다면 해봤을!
self.img_size = img_size
self.patch_size = patch_size
num_tokens = (img_size[0]*img_size[1])//(patch_size**2)이미지랑 패치 크기를 저장하고, 패치 개수를 계산한다.
img_size의 [0]과 [1]는 너비와 높이니까 거기에 패치 사이즈 제곱한 걸 나누면 개수가 나오지요~
클래스 토큰 정의!!!!
self.class_token = nn.Parameter(torch.randn((embed_size,)), requires_grad=True)- ViT의 핵심 아이디어 중 하나인 [CLS] 토큰을 정의해줍니다.
그런데 그냥 아~ 하고 넘어가기 좀 그래서 저기 안에 있는 게 무슨 말인지 알아봤다.
torch.randn((embed_size,)): 주어진 embed_size의 길이를 가지는 1차원 텐서(벡터)를 생성하는 것. randn을 썼기 떄문에 처음에는 특별한 의미가 없는 랜덤한 값들로 채워진다. 아무래도 앞으로 채워질 친구니까 일단 랜덤으로 채우는 듯?nn.Parameter(...): torch.randn으로 생성된 랜덤 텐서를 이걸로 감싸주면 해당 텐서가 모델의 학습 가능한 파라미터임을 파이토치에게 알려주는 것!- 모델이 데이터를 통해 스스로 이 벡터의 의미를 학습하게 된다구 함.
🍪 Class_token이 필요한 이유
- ViT는 이미지를 여러 개의 패치로 나누고, 각 패치를 하나의 토큰처럼 다룬다. 하지만 이미지 전체를 분류하기 위해서는 이 시퀀스 정보들을 '하나의 대표 벡터'로 요약해야 한다.
- BERT의 [CLS] 토큰처럼, 이 토큰에 해당하는 최종 출력 벡터가 문장 전체를 대표!
- 작동방식
- self.class_token을 이미지 패치 임베딩 시퀀스의 맨 앞에 추가
- 이제 시퀀스는 (클래스 토큰, 패치1 토큰....) 이렇게 됨
- 전체 시퀀스가 인코더들을 통과
- Self-Attention 매커니즘을 통해 클래스 토큰은 모든 패치 토큰들과 상호작용하며 이미지 전체의 정보를 스스로 학습하며 요약함(nn.Parameter 쓰는 이유)
- 모든 인코더 통과 후, 시퀀스 맨 앞에 있던 클래스 토큰만 가지고 와서 최종 분류기에 입력
갈 길이 멀군요. 다음!
패치 임베딩 레이어 정의
self.patch_embedding = nn.Linear(in_channels*patch_size**2,embed_size)- 무슨 말이냐 하면... 트랜스포머 모델은 원래 텍스트를 처리하기 위해 설계되었음! 컴퓨터는 이미지 패치를 바로 이해하지 못하기 때문에 트랜스포머가 이해할 수 있는 고정된 크기의 벡터 형태로 바꿔줘야 한다.
- 즉 1) 이미지를 잘게 나눈 각각의 패치 조각을 2) 1차원 벡터로 쭉- 펼친 다음 3) 선형 레이어에 통과시켜서 4) 트랜스포머가 이해하고 처리할 수 있는 고정된 크기(embed_size)의 벡터(embedding)로 변환하는 5) 신경망 레이어를 만드는 것!
- 여기서
patch_size는 패치 한 변의 픽셀 수,in_channels * patch_size**2는 패치 하나를 1차원으로 쭉 펼쳤을 때의 총 픽셀 값 개수! - 예를 들어
- 각 패치(16x16 픽셀, 3개 채널)를 1차원으로 쭉 펼치면(11*16*3=768)
- 이 벡터를 미리 정해진 embed_size(768로 정해둠) 차원의 벡터로 변경!
self.pos_embedding = nn.Parameter(torch.randn((num_tokens+1, embed_size)), requires_grad=True)각 토큰의 순서 또는 위치 정보를 학습하기 위한 파라미터!
torch.randn: 텐서 생성num_tokens+1: +1이 의미하는 건 클래스 토큰이 있어야 하기 때문embed_size: 각 위치 정보를 나타낼 벡터의 크기.패치 임베딩 크기랑 동일해야 함! 왜냐면 나중에 더해줄 것이기 때문이죠~~- 나머지는
class_token해줬던 거랑 비슷
인코더 블록 리스트 생성
self.encoders = nn.ModuleList([
Encoder(embed_size=embed_size, num_heads=num_heads) for _ in range(num_encoders)
])우리가 앞에서 정의한 Encoder 클래스를 사용해서 num_encoder 만큼 인코더 블록을 형성해야 함! 초기에 6으로 정의했었음!
nn.ModuleList: 파이토치 모듈들을 담는 리스트와 유사한 컨테이너
최종 분류를 위한 MLP 헤드 정의
self.mlp_head = nn.Sequential(
nn.LayerNorm(embed_size),
nn.Linear(embed_size, num_classes)
)- 클래스 토큰의 최종 벡터를 받아서 최종 클래스 예측 확률을 출력하는 부분!
nn.Sequential은 여러 레이러를 순서대로 실행하는 컨테이너!- 벡터를 먼저 정규화한 후에
embed_size차원의 벡터를 입력받아num_classes개수의 클래스 점수로 변환하는 최종 선형 레이어!!
이제 순전파 함수 정의를 시작합니다.
def forward(self, x):입력 x는 보통 (배치 크기, 채널 수, 높이, 너비) 형태의 이미지 텐서
batch_size, channel_size = x.shape[:2]위에서 말했듯... 배치 크기와 채널 수를 가지고 와주기
patches=x.unfold(2,self.patch_size, self.patch_size).unfold(3, self.patch_size, patch_size)주어진 이미지 x를 패치화
- unfold(2, ...)는 높이(H) 차원을 따라
self.patch_size간격으로 잘라내기 - unfold(3, ...)는 너비(W) 차원을 따라 잘라낸 것
좀 더 상세히 설명하면
- 일단 unfold라는 함수는
unfold(dimension, size, step)인 것! - 첫 unfold는 지정된 차원(=dimension)을 따라 P 크기(=size)의 조각들을 P간격(=step)으로 잘라내내고 이 조각들은 새로운 차원으로 쌓인다.
- 그럼 원래의 H 차원은 두 개의 차원으로 나뉜다.
- 패치의 개수(=
num_patches_h) : 높이 H를 P 크기로 몇 번 잘라낼 수 있는지. H//P - 각 패치의 높이(=
patch_height) : 잘라낸 각 조각의 크기 P - unfold는 새로운 차원
patch_height=P를 텐서 맨 마지막에 추가함
- 패치의 개수(=
- 결과 :
(B, C, num_patches_h, W, P) - 두 번쨰 unfold도 한다면?
- 결과 :
(B, C, num_patches_h, num_patches_w, P, P)
=(배치 크기, 채널 수, 패치 개수(높이), 패치 개수(너비), 패치 높이, 패치 너비)
패치 텐서 형태 변경
patches = patches.contiguous().view(x.size(0), -1, channel_size*self.patch_size*self.patch_size)- unfold로 얻은 패치들을 트랜스포머 입력 형식에 맞게
(배치 크기, 시퀀스 길이, 특징 차원)형태로 변경! - 이 친구를 ViT의 맥락에 맞게 바꿔보면
(배치 크기, 총 패치의 개수, 각 패치의 특징 벡터 차원)이 된다. contiguous(): 먼저 메모리 상에서 조각들을 연속적으로 배치view: 텐서의 형태를 재구성하는 것x.size(0): 배치 크기는 그대로 유지하고-1두 번째 차원인 시퀀스 길이(=패치 개수)는 자동으로 계산(=패치 개수(높이)*패치 개수(너비))- view 함수에서 차원 크기를 -1로 지정하면 파이토치가 '나머지 원소들을 모두 여기서 맞춰서 알아서 계산해줘'라고 이해한다.
- view는 전체 원소 개수(B)와 다른 차원들의 크기(C*P*P)를 보고 두 번째 차원의 크기가
num_patches_h*num_patches_w라는 것을 자동으로 계산!!! 대박.
channel_size*self.patch_size*self.patch_size: 하나의 패치 안에 들어있는 모든 정보의 개수를 의미한다. 패치 하나를 완전히 펼치면 C*P*P가 된다.
x = self.patch_embedding(patches)- 1차원으로 펼친 patch 벡터를 patch_embedding 선형 레이어에 넣어주면 embed_size 차원의 임베딩 벡터 완성
- x의 형태는
(배치 크기, 채널 수, 높이, 너비)->(배치 크기, 패치 개수, embed_size)
class_token = self.class_token.unsqueeze(0).repeat(batch_size, 1, 1)각각의 이미지 패치 시퀀스 맨 앞에 self.class_token이라는 벡터를 하나씩 추가해야 한다. x 텐서와 합치기 위해서는(concat) class_token을 (배치 크기, 1, embed_size)로 맞춰야 한다. (1인 이유는 하나의 위치만 차지하니까)
- self.class_token의 시작 형태는 (embed_size, ) ->
(1,embed_size)unsqueeze(0): 텐서의 0번째 위치(맨 앞)에 크기가 1인 새로운 차원을 추가
repeat함수는 각 차원을 몇 번 반복할지 알려줌- 가상의 (1, 1, embed_size)에 repeat(batch_size, 1, 1)을 적용
- 최종 결과
(batch_size, 1, embed_size)ex. (B, 1, 768)- 의미 : batch_size 개의 동일한 클래스 토큰이 만들어졌고, 각 토큰은 시퀀스 상에서 하나의 위치(크기 1)를 차지하며, 각각 embed_size 차원의 벡터를 가짐.
🍪 repeat 특징
- input 텐서가 2차원인데 repeat 에는 3개의 인자, 3차원일 경우
- 파이토치는 "사용자가 더 높은 차원을 원하는군"이라고 생각하고 입력 텐서의 맨 앞에 크기가 1인 차원을 필요한 만큼 자동으로 추가해서 적용!
x=torch.cat([class_token, x], dim=1)준비한 클래스 토큰과 x를 이어붙여줍니다~
이때 잘 붙여지라고 앞에서 그런 고생을 한 것..
- 결과 :
(batch_size, 패치 개수 +1, embed_size)
위치 임베딩 추가!
x = x+self.pos_embedding.unsqueeze(0)- 각 토큰(이제는 클래스+패치 토큰)에 해당 위치 임베딩을 더해준다
- self.pos_embedding :
(패치 개수+1, embed_size)형태의 파라미터(__init__에서 그렇게 지정해줌!) - unsqueeze(0) : 이걸로
(1, 패치 개수+1, embed_size)가 됨 - 앞에서 만든 x는 말했듯이
(batch_size, 패치 개수+1, embed_size) - 두 개를 더하면
(batch_size, 패치 개수+1, embed_size)
이제 트랜스포머 인코더 통과!!
for encoder in self.encoders:
x=encoder(x)self.encoders리스트에 있는 각 인코더 불록을 순서대로 통과- encoder 클래스를 돌리는 것
- 모든 인코더를 통과시킨 후에, 최종 분류를 위해 시퀀스의 맨 앞에 있던 클래스 토큰([CLS])의 최종 백터만 추출!
x=x[:,0,:].squeeze()
x=self.mlp_head(x)
return xx[:,0,:]: 모든 배치 샘플에 대해 시퀀스의 0번째 인덱스의 모든 임베딩 차원을 선택squeeze(): 원래 (배치 크기, 1, embed_size)였는데 1인 차원을 제거해서 (배치 크기, embed_size)가 됨.- 마지막으로 MLP 헤드를 통과해서 최종 분류
- 결과 x의 형태 :
(배치 크기, num_classes)
Test하기
from torchinfo import summary
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"device : {device}")
model = VisionTransformer(in_channels=1, img_size=(28, 28), patch_size=7, embed_size=64, num_heads=4, num_encoders=3).to(device)
summary(model, [2, 1, 28, 28])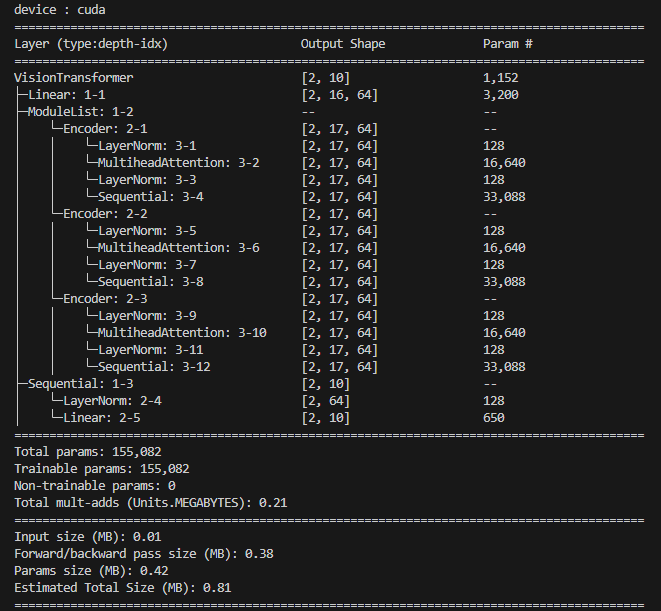
암튼 잘 돌아간다!!
아키텍처 자체는 괜찮다!!!! (ㅠㅅㅡ)
학습 & 평가
🛠 아직 뚝딱뚝딱... 🛠
학습 단계
- 필요한 라이브러리 임포트 (torch, torchvision, torchinfo 등)
- Encoder 및 VisionTransformer 클래스 정의 (이전 코드 사용)
- 하이퍼파라미터 설정 (학습률, 배치 크기, 에폭 수 등)
- 장치 설정 (GPU 우선 사용)
- MNIST 데이터셋 로드 및 변환 (Transform) 정의
- 데이터 로더(DataLoader) 생성
- 모델 인스턴스 생성 (MNIST에 맞는 파라미터 사용) 및 장치로 이동
- 손실 함수(Loss Function) 및 옵티마이저(Optimizer) 정의
- 훈련 루프(Training Loop) 정의
- 평가 루프(Evaluation Loop) 정의
- 훈련 및 평가 실행
모델 만드는게 끝이 아니라는 이 절망감... 처음이 힘든거라고 생각하고 마음을 다잡음...
필요한 라이브러리 임포트
import torch
import torchvision
import torch.nn as nn
import torchvision.transforms as transforms
import torch.optim as optim
import torchvision.datasets as datasets
from torch.utils.data import DataLoader
import time클래스 정의
from ViT import encoder, VisionTransformer다른 파일에 만들어뒀기 때문에 import를 시켜줍니다.
하이퍼 파라미터 설정
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using Device : {device}")
# ViT 파라미터 설정하기
img_size = (28, 28)
patch_size = 7
in_channel = 1 #MNIST 흑백
num_classes = 10 # MINST 0~9
embed_size = 128
num_head = 4
num_encoders = 3
dropout =0.1
# 학습 파라미터
batch_size = 128
learning_rate = 1e-4
epochs = 10 MNIST 데이터셋에 맞춰준다....이런 데이터셋인지는 Gemini가 알려줌.
MNIST 데이터셋 및 반환
transform = transforms.Compose([
transforms.ToTensor(), # 이미지를 Tensor로 변환하고 [0, 1] 범위로 스케일링
transforms.Normalize((0.1307,), (0.3081,)) # MNIST 평균 및 표준편차로 정규화
])
train_dataset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transform)데이터 로더
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=2, pin_memory=True)
test_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False, num_workers=2, pin_memory=True)데이터셋 가지고 왔는데 로더는 무엇이냐...
datasets. 은 MNIST 데이터셋 전체를 불러와서 파이썬 객체로 만든 것.
DataLoader가 있으면 딥러닝 모델을 효율적으로 훈련시키기 위해 필요한 추가적인 요구 사항을 자동화해줌.
- 배치, 셔플링, 병렬 처리, 메모리 고정 등의 효과를 누릴 수 있다~~
모델 가져오기
model = VisionTransformer(
in_channels=IN_CHANNELS,
num_encoders=NUM_ENCODERS,
embed_size=EMBED_SIZE,
img_size=IMG_SIZE,
patch_size=PATCH_SIZE,
num_classes=NUM_CLASSES,
num_heads=NUM_HEADS,
dropout=DROPOUT
).to(DEVICE)그리고 criterion 과 optimizer를 정의한다.
criterion = nn.CrossEntropyLoss()- 목적: 모델의 예측이 실제 정답과 얼마나 다른지 측정하는 기준을 정의
- 모델이 입력 이미지를 보고 클래스에 대한 점수를 출력하면 CrossEntropyLoss는 모델의 출력 점수와 실제 정답 레이블을 비교한다.
- 내부적으로는 모델의 점수를 확률 분포로 변환(Softmaz)하고, 실제 정답 레이블과의 차이를 계산해서 손실값(loss)로 반환
optimizer = optim.AdamW(model.parameters(), lr=LEARNING_RATE)- 위에서 계산된 loss 값을 줄이는 방향으로 모델 내부의 학습 가능한 파라미터를 어떻게 업데이트할지 방법을 정의!
loss.backward(): 손실값을 계산한 후 이 메소드를 호출optimizer.step(): 파라미터값을 조금씩 업데이트model.parameters(): 옵티마이저에게 "이 모델 안에 있는 파라미터 네가 알아서 관리해"라고 하는 것LEARNING_RATE: 얼마나 큰 폭으로 수정할지~~
딥러닝 모델 학습은 모델이 예측하고(=forward), 성적을 매기고(=criterion) -> 오답 노트를 만들고(loss.backward()) -> 그걸 보고 개선(=optimizer.step())하는 것의 반복!
드디어 훈련
0403 여기서 막힘...
def train_one_epoch(model, loader, criterion, optimizer, device):
model.train()
running_loss = 0.0
correct_predictions = 0
total_samples = 0
start_time = time.time()
for i, (images, labels) in enumerate(loader):
images = images.to(device)
labels = labels.to(device)
# 순전파
outputs = model(images)
loss = criterion(outputs, labels)
# 역전파 및 최적화
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 통계 업데이트
running_loss += loss.item() * images.size(0)
_, predicted = torch.max(outputs.data, 1)
total_samples += labels.size(0)
correct_predictions += (predicted == labels).sum().item()
# 진행 상황 출력 (선택 사항)
if (i + 1) % 100 == 0:
print(f" Batch {i+1}/{len(loader)}, Loss: {loss.item():.4f}")
epoch_loss = running_loss / total_samples
epoch_acc = correct_predictions / total_samples
epoch_time = time.time() - start_time
print(f"Epoch Training Time: {epoch_time:.2f}s")
return epoch_loss, epoch_acc평가 단계
def evaluate(model, loader, criterion, device):
model.eval() # 모델을 평가 모드로 설정
running_loss = 0.0
correct_predictions = 0
total_samples = 0
with torch.no_grad(): # 기울기 계산 비활성화
for images, labels in loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
running_loss += loss.item() * images.size(0)
_, predicted = torch.max(outputs.data, 1)
total_samples += labels.size(0)
correct_predictions += (predicted == labels).sum().item()
epoch_loss = running_loss / total_samples
epoch_acc = correct_predictions / total_samples
return epoch_loss, epoch_acc훈련 및 평가를 실행
print("Starting Training...")
for epoch in range(EPOCHS):
print(f"--- Epoch {epoch+1}/{EPOCHS} ---")
train_loss, train_acc = train_one_epoch(model, train_loader, criterion, optimizer, DEVICE)
print(f"Epoch {epoch+1} Training - Loss: {train_loss:.4f}, Accuracy: {train_acc:.4f}")
test_loss, test_acc = evaluate(model, test_loader, criterion, DEVICE)
print(f"Epoch {epoch+1} Validation - Loss: {test_loss:.4f}, Accuracy: {test_acc:.4f}")
print("Finished Training.")결과는! 디버깅 이슈로 담에,,,,,,,,
- 너무나도 많이 참고한 블로그
