[논문] ON DECODER-ONLY ARCHITECTURE FOR SPEECH-TO-TEXT AND LARGE LANGUAGE MODEL INTEGRATION
paper-review
Abstract
- text-based model과 speech proceeing을 통합한 Speech-LLaMA 방법을 소개한다
- Speech-LLM 통합의 실용적인 요소들을 조사하였는데, 음향 특징의 압축이나 어탠션 마스크 선택, 파인튜닝 전략 등이다.
- Decoder-only 아키텍쳐가 Encoder-Decoder보다 Speech-to-text task 에서경쟁적인 모습을 보였으며 parameter가 더 효율적임
Motivation
Cascade
해당 방식에 대해 좀 더 추가하기
- 기존에는 ASR -> LLM 방식: 음성을 텍스트로 바꾼 후, 그 텍스트로 LLM이 downstreatm 작업을 진행했다
- 그러나 이 경우 음성 정보가 사라지고 텍스트 오류를 LLM이 복구할 수 없는 문제가 발생한다. 애초에 틀린 부분을 고칠 단서를 잃어버리기 때문이다.
그럼 어떻게?
- 음성을 텍스트로 바꾸기 전에 LLM이 직접 음성 정보를 받아서 이해한다.
- 음성을 LLM의 embedding 공간에 매핑
- LLM embedding 공간은 단순한 숫자 벡터 공간이 아니라 LLM이 방대한 텍스트를 학습하면서 만들어낸 semantic 기반의 구조적 공간
- 그래서 음성을 discrete token(자모, 음절, 음소...)으로 바꾸지 않고 continuous vector(연속 벡터)로 만든 뒤, 바로 LLM embedding 공간으로 매핑함
- 그렇게 하면 = Deep integration
- 음성의 미세한 정보(억양, 발음 전환, prosody)까지 보존
- 의미 공간에서 텍스트와 바로 비교/결합 가능
- LLM이 기존 구조를 그대로 활용해 음성 이해 가능
| 음성 특징 | 텍스트 변환 시 | 연속 벡터 유지 시 |
|---|---|---|
| 억양 | 사라짐 | pitch-related dimension에 남음 |
| 발음 길이 | 사라짐 | time-compressed sequence 안에 남음 |
| 음절 간 연결 | 사라짐 | acoustic transitional feature로 남음 |
| 발화 패턴 | 사라짐 | embedding의 특정 방향으로 encode 가능 |
- e.g. 발음이 아주 조금 다른 음성 = embedding에서 약간 다른 위치
-
pitch-related dimension
- LLM embedding 공간이 있다고 할 때, 각 차원 각각은 컴퓨터가 학습과정에서 스스로 특정 정보를 담당하게 됨
- e.g. 문맥 관련, 단어 의미 관련, 발화 특성 관련, 관계....
- pitch-related dimension은 그 차원의 일부터 높낮이 정보(음의 높이)를 표현하는 데 사용된다는 뜻
-
time-compressed sequence
- CTC compressor나 CNN 기반 인코더는 긴 음성 신호를 암축된 연속 벡터들의 시퀀스로 바꿈
- 원래 길이가 1000 프레임이면 CTC-frame-averging을 거쳐 50개 벡터 정도로줄임
- 중요한 점은 원래 길이가 길면 더 많은 벡터로 남음
- 벡터의 duration(길이)는 compressed sequence의 벡터 개수나 연속 벡터 패턴으로 나음
-
acoustic transitional feature
- 음성은 연속적인 파형. 음절과 음절 사이에 부드러운 이동구간이 존재해.
- 예: “가 + 나”를 빨리 말하면 “간아” 비슷하게 연결
- “가 음절의 끝”에서 “나 음절의 시작”으로 바뀌는 중간 전이(transition) 패턴이 벡터 값으로 남아.
- 벡터가 갑자기 바뀌는게 아니라 연속적으로 방향이 바뀌는 패턴이 생기는 것 = 벡터의 부드러운 변화
- '가' 다음에 그냥 '나'가 아니라 '가'->전이->'나' - 두 벡터 사이의 미세한 차이·방향 변화가 음절 간 연결 정보를 담게 된다.
-
embedding의 특정 방향으로 encode 가능
- 4096차원 벡터 공간(LLaMA embedding 차원 수)은 단순히 숫자들의 집합이 아니라 의미적인 방향성을 가지고 있음
- king – man + woman = queen → 이는 embedding 공간에서 특정한 “성별 방향(gender direction)”이 있음을 의미
- embedding("king") - embedding("man") ≈ embedding("queen") - embedding("woman") - 감정 방향이나 pitch 높낮이 방향, 발화 속도 방향
Related Work
LoRA
- Speech-LLaMA는 LLaMA의 대부분을 그대로 두고, 각 Transformer 층의 attention 가중치 부분에 LoRA를 붙임
Approch

1. CTC Compression
Alignment 문제 정의
프레임1 프레임2 프레임3 프레임4 ... 프레임2000
["가", "나", "다"]- 프레임 ↔ 글자를 1:1 매핑할 수 없다. 또한 정확히 어느 프레임이 "가"에 해당하는지 정답에 없다.
인코더의 중간 벡터가 작동하는 방법
소리 파형 → [프레임별 특징 f1, f2, f3, ...] → [은닉 벡터 h1, h2, h3, ...]음성 신호는 시간에 따라 변하기 때문에 보통 짧은 시간을 frame으로 나눈다. 각 프레임은 pitch, 스펙트럼 형태, 음소 특징 등으로 이뤄져 있으므로 f_t는 t번째 순간의 음향 정보 요약본이라는 것.
Neural encoder가 f_t를 입력받으면 더 고차원적인 의미 정보가 담긴 벡터 h_t로 변환
는 시간 t 부근의 소리 구간이 어떤 음소나 글자 정보를 담고 있는지 추상적으로 표현한 벡터. 이 순간이 어떤 음소인지, 말소리 전환이 일어나는 중인지, 음절의 시작인지, 발음이 강한 구간인지에 대한 정보들을 답고 있음.
여기서 CTC는 각 은닉 벡터 h_t를 받아서 "이 벡터는 현재 어떤 글자를 나타낼 확률이 높은가?"를 계산함.
=> 요것이 바로 CTC branch. 각 벡터가 지금 시점의 '가장 가능성 높은 글자'를 예측하도록 만드는 것
- W: 에서 글자 확률로 매핑해주는 weight, b는 bias, 는 글자 분포(a, b, c, blank...)
어떤 구간의 소리를 들으면 계속 비슷한 파형이 반복되는데, 정답 문장을 듣고 나면(e.g. 가나다) 이 비슷한 구간들은 같은 글자겠구나~라고 판단해서 그 구간의 벡터들을 비슷한 방향으로 만듦. 그리고 파형이 바뀌면 새롭게 다른 벡터로 변경함
CNN 압축과 어떻게 다른가?
- CNN은 stride=2인 경우 시간축을 반으로 줄여버리고, 이 프레임이 어떤 글자인지는 고려하지 않음. 의미 없는 downsampling
- CTC는 먼저 “이 프레임의 글자 후보”를 뽑고 그 후보 중 blank는 버리고 같은 글자 구간은 묶어서 평균냄 -> 의미 기반 압축
그럼 어떤 방식이 존재하지?
- Blank-Removal(공백 제거)
- blank로 예측된 모든 프레임을 버리고 남은 프레임만 audio encoder에 전달
- 간결하지만 잃는 정보가 많음.
- Frame-averaging(프레임 평균)
- 같은 글자로 예측된 연속 프레임들을 평규내어 한 벡터로 만듦
- blank 프레임은 버리지 않거나 완전히 무시하지 않고 평균에 반영할 수도 있음
- 연속된 같은 글자 구간을 평균
| 프레임 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| CTC 예측 | 가 | 가 | 가 | blank | 나 | 나 | 다 | 다 |
- 프레임 1~3은 전부 '가'이므로 은닉 벡터 평균냄
- 프레임이 8에서 3으로 줄어듦.
CTC Loss
-
CTC Loss는 각 프레임이 어떤 글자인지 맞추도록 학습시키는 것
-
CTC Loss는 ‘한 문장’을 비교하는 것이 아니라, 그 문장을 만들 수 있는 모든 가능한 프레임 라벨링 시퀀스 전체를 평가한다.
-
예를 들어 정답이 '가나'라면 가능한 프레임 라벨 시퀀스는
가능한 예시:
1) [가, 가, blank, 나, 나]
2) [blank, 가, 가, 나, blank]
3) [가, blank, 가, blank, 나]
4) [가, 가, 가, blank, 나]
…
수십만 개Frame 1 → '가' 확률 0.8, blank 0.2
Frame 2 → '가' 확률 0.7, blank 0.3
Frame 3 → '나' 확률 0.9, blank 0.1
Frame 4 → blank 확률 0.95- CTC loss는 이 모든 가능한 라벨 시퀀스가 최종적으로 '가나'를 만들 확률의 합'을 최대화함.
- CTC는 프레임 정답 없이도 이렇게 생각한다:
“이 모델이 낸 프레임별 글자 확률들을
어떻게 조합하면 최종적으로 ‘가나’라는 문장이 만들어질까?”
즉, CTC Loss는 아래를 평가한다:
- “이 프레임들의 예측을 조합하면 ‘가나’를 만들 수 있는가?”
- 만들 수 있다면 그 경로들의 확률을 높여라
- 만들 수 없다면 그 확률을 낮춰라
그래서 수식이 “여러 경로의 총 확률” 구조가 되는 것.
- 정답 문장을 만들 수 있는 모든 경로 중 높은 것을 강화하는 것
구성
- 2개의 2D Conv Layer, 4개의 Transformer layer
- 4배의 시퀀스 길이 축소(subsampling)을 수행하며 전체 파라미터 수는 약 15.8M
- 각 Transformer 층은 512차원의 self-attention 모듈(8개의 head)과 2048차원의 FFN으로 구성
- 각 Conv Layer는 stride 2, kernel 3
CTC Compressor는 음성 프레임을 짧게 줄이면서 의미를 유지하는 모듈
- 앞단의 Conv2D 2층 -> 입력 스펙트로그램을 시간적으로 절반씩 줄임(stride=2 -> 두 번이면 1/4)
- 뒤의 transformer 4층 -> 줄어든 시퀀스에서 문맥적 특징 요약
- 초기 실험에서 음성->텍스트 번역(ST)으로 학습시키면 성능이 떨어졌고, 먼저 음성->같은 언어 텍스트(ASR)로 훈련시킨 모델의 압축기능이 훨씬 안정적이라 ASR 데이터(13개의 언어)를 사용해 CTC Compressor를 먼저 사전학습한 것
Q. 이유가 뭘까?
CTC는 음성의 시간적 프레임을 줄이면서 각 구간이 어떤 단어에 해당하는지 정렬해야함. 그러니까 발음 단위 정렬이 잘 되어 있어야 하는데 ST 데이터는 프랑스어 ↔ 한국어가 1:1 프레임 정렬이 불가능하기 때문에 CTC loss가 잘 작동하지 않는다.
비교 Baseline
| 항목 | CTC Compressor | Conv-based Subsampling |
|---|---|---|
| 구조 | Conv2D + Transformer | Conv2D + Transformer (+1D Conv 3층) |
| 학습 방식 | CTC Loss (ASR 학습) | Cross-Entropy (LLM과 함께 joint 학습) |
| 학습 데이터 | Speech–Text (정렬 학습용) | Speech–Text (전체 joint 학습) |
| 배운 것 | 프레임–글자 정렬 정보 | 단순 feature 요약 |
| 출력 의미 | “글자 단위로 압축된” 음성 벡터 | “시간적으로 줄인” 요약 벡터 |
| 장점 | 의미 보존, 경계 명확 | 단순, 빠름 |
- 1D convolution은 시간 축만 따라 연산하므로 시퀀스 길이는 빠르게 줄지만 문맥 정렬 정보는 유지되지 않음.
2. Audio encoder
CTC Compressor가 길이를 맞추는 역할이었다면, Audio Encoder는 의미 공간으로 매핑하는 역할임. CTC가 언제 말했는가를 담당한다면, 얘는 무슨 의미인가를 담당.
CTC Compression이 만들어낸 표현을 텍스트 LLM이 사용하는 text embedding 공간으로 연결
- 여기서의 transformer: 이 소리 조각들이 합쳐지면 어떤 의미인가?
- 학습 목표: Cross-Entropy(LLM 출력 vs 정답 문장)
Q. 상대적으로 작은 규모로 설계된 이유는?
- 직접적으로 나와 있지는 않으나, 파라미터 효율성, 학습 안정성, 비용 절감, 오버피팅 방지 등의 이유가 있을 것으로 보임
- 기존 연구: 오디어 인코더가 먼저 음성 신호를 Discrete token으로 변환 -> 그 토큰을 LLM에 입력
- tokenizing 과정에서 정보가 손실, discrete이므로 미세 발음·감정 표현이 불가능, token→embedding 두 단계 변환이 필요해서 error propagation 발생 - 제안: 압축된 음향 신호를 바로 LLM의 연속적 의미 공간으로 매핑하도록 직접 최적화
LLAMA 입력 수정 방식
"Translate the following speech into English:" (text prompt) + [음성 임베딩 시퀀스]
→ LLaMA
→ "Good morning, everyone." (output)구조
- 4개의 Transformer Layer, 각 층의 설정은 CTC Compressor와 동일
- 마지막 층의 출력은 4096차원으로 변환되어 LLaMA의 semantic embedding dimension과 일치시킴
- = CTC의 512차원 음성 표현을 LLaMA의 4096차원 의미 벡터로 변환하는 브릿지 역할
- 학습되는 것
- Multi-head attention weight, FFN weight, Projection Layer weight
- 이 weight가 학습되면서 어떤 음성 패턴은 embedding 공간의 특정 방향으로 매핑되고 길이, pitch, 감정 같은 미세 정보도 벡터에 자연스럽게 encode됨
Mask Strategies
- 먼저 Attention Mask가 왜 필요한지
- LLM은 기본적으로 autoregressive 방식이라 미래를 보면 안됨. 그런데 음성은 시퀀스 전체가 한번에 들어오고 미래의 음성 정보(e.g. 단어의 끝, 발음 전환, 억양 패턴)가 지금의 해석에 도움이 될 수 있음
- 때문에 논문은 prefix(프롬프트+음성) 구간에만 Non-casual Mask를 적용함
- 미래 음성 프레임도 볼 수 있다
- blank 제거로 사라진 정보도 복원 가능
- 발음 전환(transition) 같은 미세 정보 해석 가능
- 전체 문맥을 동시에 볼 수 있어 embedding 매핑이 더 안정적
| 구분 | Prefix(프롬프트+음성) | Output(텍스트 생성) |
|---|---|---|
| Causal Mask | causal | causal |
| Non-Causal Mask (Proposed) | non-causal (full attention) | causal |
[1] Lower triangle attention mask (하삼각 기법)
t0 t1 t2 t3
t0 ▶︎ X
t1 ▶︎ O X
t2 ▶︎ O O X
t3 ▶︎ O O O X[2] Non-causal mask
모든 토큰이 모든 토큰(미래 포함)을 볼 수 있는 상태. 주로 인코더 구조나 양방향 모델(BERT)에서 사용
- prefix(텍스트 프롬프트 + 음성 벡터) 는 non-causal로 두어 음성 전체 문맥을 자유롭게 통합하도록 함
논문에서 제안하는 것은?
- prefix(프롬프트 + 음성) : Non-causal
- output(텍스트 생성): Causal
- 텍스트 생성까지 Non-causal이면 모델이 미래 단어를 그대로 볼 수 있기에 정상적인 생성이 불가능함
3. LoRA Fine-tuning
[ Text Prompt ] + [ Audio Encoder Outputs ] + [ 이전에 생성한 텍스트들 ] → Decoder- LLaMA는 원래 음성 입력을 받도록 만들어진 모델이 아님
- Audio Encoder가 아무리 잘 매핑해줘도 LLaMA 내부 attention들이 “음성 특성을 반영한 방식”으로 작동하지 않음
- 그래서 LLaMA의 attention 구조 일부를 조금 고쳐야 함 -> 최소한의 파라미터 조정 방법이 LoRA.
“LLaMA 전체를 fine-tune하면 학습비용이 너무 비싸고 위험하다. 대신 파라미터 0.03% 정도만 추가해서 LLaMA가 음성 embedding을 더 잘 이해하도록 조정하자.”
- LLaMA Transformer의 각 layer에 있는 네 가지 attention 행렬()에 적용
- 훈련 안정화를 위해 두 단계 학습 전략 사용
1. Audio Encoder 학습: CTC compression과 LLaMA 본체 Frozen
2. LoRA를 도입해 잘 학습된 모델에 추가하고 두 번째 최적화 단계 수행 - LLM의 출력과 정답 전사 사이의 Cross-Entropy Loss로 학습됨.
- Rank는 2이며 2.1M 파라미터만 추가됨. 이때 CTC compressor와, LLaMA는 Freeze
4. From Scratch Training
Decoder-only 구조도 음성-텍스트 작업에서 충분히 강력하다
논문은 두 가지 모델을 비교함
1. Speech-LLaMA
- LLaMA(텍스트 LLM) + Audio Encoder + CTC compressor
- pretrained LLM 사용 + LoRA
2. From Scratch Training
- LLaMA X, CTC Compressor X, 모든 걸 랜덤 초기화로 학습
- 순수한 CNN 2층 + Decoder transformer 12층
= 텍스트 LLM 지식 없음, 언어 모델링 능력 없음, 오디오 compressor 없음
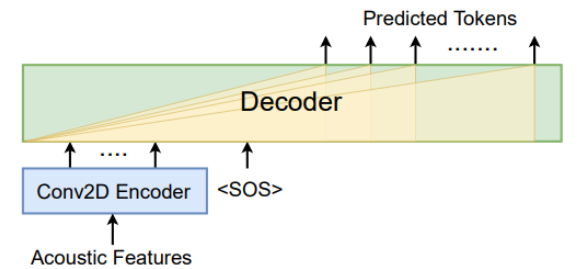
- Decoder only라는 형태만으로도 음성->텍스트 end-to-end 학습이 성립한다는 사실을 보여주기 위해 LLaMA, CTC Compression, Audio Encoder를 제거한 순수 디코더 구조를 실험함
- 대신 무작위로 초기화된 2D convoultion Encoder 대체
- 음성 시퀀스의 끝에는 \ 토큰을 추가하여 텍스트 생성 시작을 알렸음
- 텍스트 시퀀스 y의 생성은 오로지 음성 신호 와 이전까지 생성된 단어 에 의해 조건화됨. 는 CNN과 Transformer 모두 포함한 weight 집합
Experiment
DATA
- 13개의 외국어 → 영어로 번역
- 해당 언어들은 훈련 및 평가용 데이터의 가용성(Availability)을 기준으로 선택됨
- 각 언어에 대해 사내(in-house)에서 수집된 1,000시간 분량의 음성 데이터를 학습에 사용
- 모델의 강건성(Robustness)을 높이기 위해 영어(EN) 음성 데이터 1,000 시간을 추가로 포함시켜, 총 14,000 시간 규모의 학습 데이터를 구성함
Q. 왜 이러면 강건성이 높아짐?
- 단순히 데이터 양이 느는게 아니라 모델의 표현 학습 방식과 훈련 안정성에 관련된 문제
- 강건성이랑 다양한 입력에서도 모델이 잘 작동하는 능력.
- 영어 데이터가 주는 효과
1. 공통 표현을 학습:
2. 영어 음성 -> 영어 텍스트라는 데이터가 포함되면 음성 -> LLaMA 의미 공간 변환이 훨씬 안정적으로 학습됨
3. 디코더 학습 안정성 향상: 모든 ST 모델의 출력은 영어 텍스트이기 때문에 입력 음성이 영어인 데이터가 일부 있으면 모델이 언어별 음성 특징 -> 영어 문장 생성의 mapping 더 잘 배움
- 영어가 아닌 언어의 원문 전사 텍스트는 사내 번역 시스템에 입력되어, 문장 부호(Punctuation)와 대소문자(Capitalization)가 포함된 영어 번역문(English Transcription)으로 변환
- 생성된 의사 라벨(Pseudo-label) 영어 전사문을 음성 번역(ST:Speech Translation) 학습의 목표 텍스트로 사용
- 각 언어의 테스트 세트는 CoVOST2 Dataset에서 선정
- 평가 지표 BLUE 점수
Baseline - Whisper
[음성 입력 (spectrogram)]
→ Encoder (Audio Transformer)
→ Decoder (Text Transformer)
→ [텍스트 출력]Whisper는 전형적인 Transformer encoder-decoder 구조로 되어 있음.
- Encoder: 음성을 인코딩
- Decoder: 그 벡터를 보고 텍스트를 순차 생성
Q. Audio Encoder도 Encoder 아닌가? input을 의미론적으로 바꾸니까
기능적으로는 encoder-decoder가 맞긴 하지만 구조적 관점의 정의 차이다.
LLaMA는 오직 Decoder block으로만 이루어진 모델이다.
기존 음성 모델(Whisper, SpeechT5) 등은 encoder-decoder 구조였음.
해당 연구자들은 LLaMA 구조를 그대로 두고 거기에 음성 입력을 붙일 수 있을까?를 알아보고자 한 것.
- 14,000시간 규모의 데이터로 학습. 12층짜리 음성 Trasnformer 인코더와 디코더로 구성. Attention 차원은 768, head 수는 12.
- Cross-Entropy 손실을 주된 학습 목표로 사용. 인코더 부분에 CTC 손실을 부가하여 학습.
- 공정한 비교를 위해 from scratch 학습하며 공개된 가중치 사용하지 않음
공정한 비교
Beam search, CTC joint-decoding, LLaMA rescoring
- Beam Search
- 확률이 높은 상위 N 개 문장 후보(beam)를 동시에 유지하면서 확률 합이 가장 높은 문장 찾음
- n=5 -> 5개의 문장 후보를 동시에 탐색
- CTC joint-decoding
- CTC branch: 인코더가 프레임별로 글자 확률 예측 <- 발음 정렬을 잘 맞추지만 문장 문맥 약함
- seq2seq decoder: 전체 문장 확률 예측 <- 문맥은 좋지만 글자 정렬 흐트러질 수 있음
- 두 점수를 합쳐서 문장을 선택 $$ score=α⋅logPseq2seq+(1−α)⋅logP_{CTC} $$
- 각각 계산하여 후보 문장에 점수를 매김
- n-best rescoring with LLaMA
- beam search로 나온 상위 n개 후보 문장을 모두 완성한 뒤, LLaMA 언어모델이 평가
- seq2seq 모델이 준 확률 점수(발음, 번역 중심) + LLaMA의 점수(문법, 자연스러움 중심)
- Log-linear interpoliaton
- 점수가 가장 높은 문장을 최종 출력으로 선택(re-ranking)
Q. 이렇게 복잡하게 하는 이유
- 기존 seq2seq 모델은 언어 모델이 약하기 때문에 문장 자연도를 보완해야만 공정한 비교가 된다.
From-scratch training
Speech-LLaMA의 Decoder-only가 pre-trained LLM 없이도 잘 학습되는가?
- 2차원 합성곱(Conv2D) 인코더 구조를 사용하였으며 CTC compressor와 동일하게 2개의 Conv로 구성
= CTC가 하던 음성 길이 축소 + 특징 요약을 단순히 복제- Transformer Decoder는 LLaMA의 구현 구조를 그대로 따름
- Pre-normalization: LayerNorm을 attention/FFN 앞에 두는 방식
- SwiGLU activation function: LLaMA에서 쓰이는 활성화 함수
- Rotary Positional Embedding(RoPE): 위치 정보 인코딩 방식- 각 디코더 층은 12개의 Attention head, 차원은 768, FFN 차원은 4076
| 구성요소 | 설명 | 역할 |
|---|---|---|
| Conv2D Encoder (2층) | stride=2, kernel=3 → 총 4배 subsampling | 음성 프레임 길이 축소 |
| Transformer Decoder (LLaMA-style) | pre-norm + SwiGLU + RoPE | LLaMA와 동일한 디코더 구조 |
| Self-Attention | 12 heads, dim=768 | Whisper와 같은 크기 |
| Feed-Forward | 4076 dim | 정보 확장 및 비선형 변환 |
| Training | from scratch | 사전학습 X, 데이터만으로 새로 학습 |
Training and evaluation
Results and Discussion
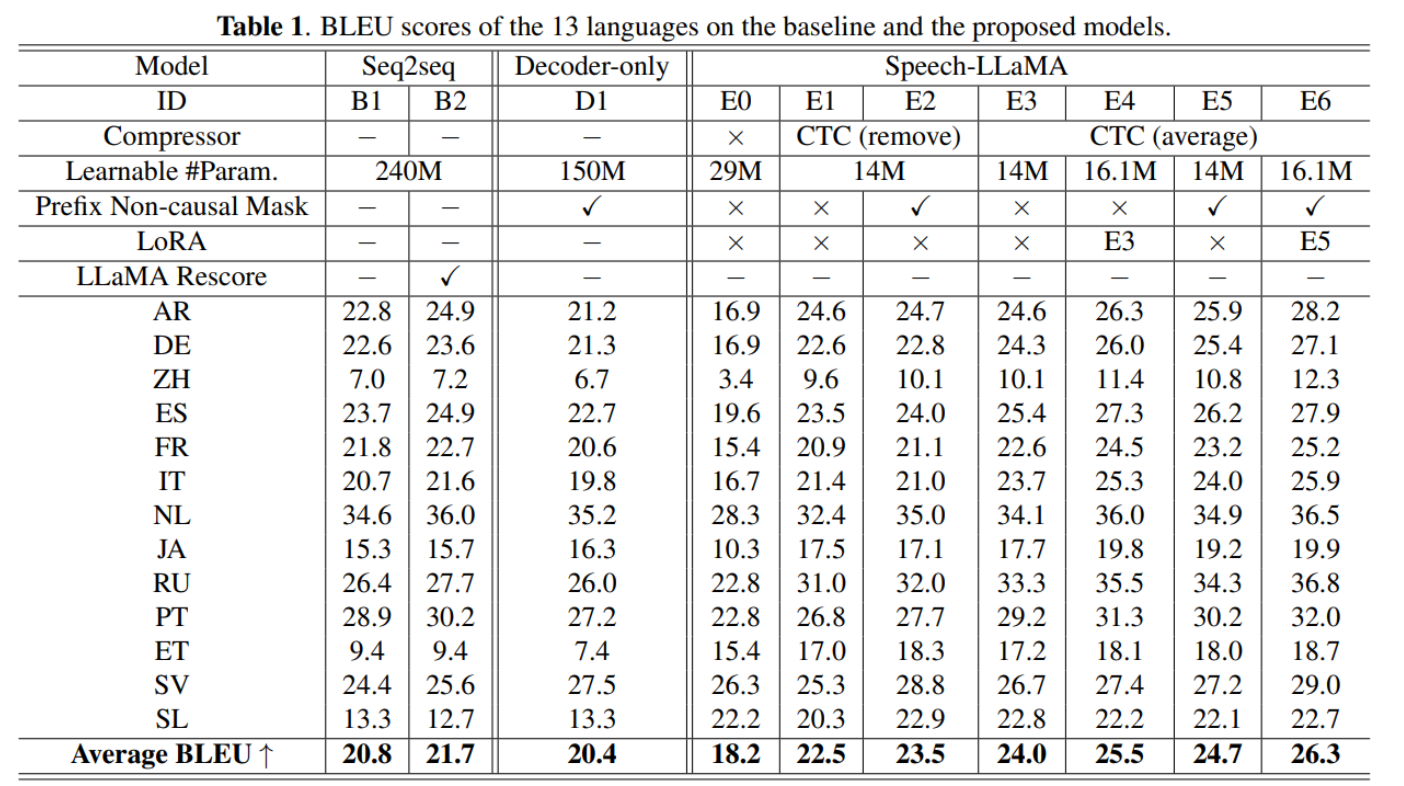
CTC Compression
-
E0 ↔ E1
- CTC 압축기의 성능이 훨씬 좋음
- CTC 압축기는 학습 중에 고정되었고, 합성곱 압축기는 오디오 인코더와 함께 미세 조정되었음에도
- 사전학습 중에 각 언어의 음성-전사 데이터를 사용했기에 더 잘 작동했다고 제시함
- ST(번역) 라벨로 학습한 CTC 모델을 사용했을 때 BLEU 점수가 더 나빠졌다는 예비 실험 결과도 이 가설을 뒷받침Q. 합성곱 압축기가 뭐임
- 둘다 목적은 음성 시퀀스가 길어서 Transformer가 감당하기 힘든 것을 줄이는 모듈
- 합성곱 압축기는 Conv1D 또는 Conv2D를 여러 층 쌓고 stride를 2로 설정.
- 그냥 시간축을 일정 비율로 압축하는 필터
- CTC는 어떤 프레임이 의미 있고 어떤 프레임이 불필요한지 스스로 배움
-
E1 ↔ E3
- frame-averaging 방식이 blank-removal 방식보다 평균 1.5 BLEU 높았음
- CTC가 모든 유용한 정보를 비-blank 프레임만으로 완전히 압축하지 못하기 때문이라고 봄
- CTC가 선택한 프레임들이 일부 음향 정보를 잃게 되어 성능 저하가 발생
Non-causal attention mask
텍스트 프롬프트와 음성 표현에 대해 Full Attention을 허용하면 일반적으로 더 나은 음성 표현과 더 높은 성능이 예상됨
- E2 > E1: 1.5point증가
- E5 > E3: 0.7 증가
- 미래의 음향 정보를 참조할 수 있게 되면, blank 프레임 제거로 인해 손실된 정보를 보완할 수 있기 떄문.
Q. blank 프레임 제거로 인해 어떤 정보가 손실되고, 그걸 어떻게 보완할 수 있다는 거지?
- blank는 단순한 무음이 아니라 발음 전환 구간, 음절 간 연결부 같은 미묘한 음향 특징을 포함할 수 있음
- non-causal mask를 쓰면, LLaMA가 미래 프레임까지 모두 참조할 수 있음
- blank로 제거된 구간의 앞뒤 프레임을 모두 볼 수 있기 때문에 누락된 정보를 문맥적으로 복원 가능
- 앞뒤 소리 패턴을 다 보니 중간에 어떤 전환이 있었는지 유추 가능
- blank 제거 전략은 손실이 크지만 non-casual attention을 쓰면 문맥 대체 가능
- 발음 전환 구간을 더 잘 해석할 수 있음
- LLM embedding 공간으로 매핑이 더 안정적!
LoRA fine-tuning
E4와 E6은 LoRA 미세조정을 적용한 시스템
- E3 < E4: casual mask 상황에서의 LoRA 효과
- E5 < E6: non-causal mask 상황에서의 LoRA 효과
- 이때 추가된 파라미터는 210만 개이며, 더 큰 Rank를 사용하면 성능이 향상될 가능성이 있음.
Decoder-only vs Encoder-Decoder
- seq2seq 기준 대비 0.4정도만 낮음
Q. Non-casual mask가 check 되어 있는데 이게 문제를 일으키지는 않았을까?
- non-casual mask는 약간의 추가 이득을 주기 때문에, 정확히 동일한 조건 비교라기 보다는 최적화된 설정끼리의 비교에 가깝다고 함.
- 전체 파라미터 수는 seq2seq 기준보다 훨씬 적었음
- decoder-only 구조에서는 하나의 모듈이 입력과 출력 표현을 동시에 학습하지만 encoder-decoder 구조에서는 서로 다른 두 모듈을 사용하기 때문
- 입력, 출력을 하나의 모듈이 공유하는 구조가 더 나은 파라미터 효율성을 가져옴
[!summary] 최종
- B1 / B2: Whisper-style baseline, LLaMA rescoring 시 +0.9 BLEU
- E1~E6 (Speech-LLaMA): 최대 +4.6 BLEU 향상, deep integration 효과 입증
- CTC compressor: 사전학습된 CTC가 단순 Conv보다 우수
- frame-averaging > blank-removal
- Non-causal mask: 평균 +0.7~+1.5 BLEU 향상
- LoRA fine-tuning: 적은 파라미터(2.1M)로 추가 +1.5 BLEU 개선
- Decoder-only (from scratch): 성능 거의 동일하지만 훨씬 더 파라미터 효율적
Conlcusion
- 기존 대형 언어모델(LLM)에 음향 정보를 주입하는 방법을 제안
- 음향 표현을 LLM의 의미 공간(semantic space)에 직접 매핑함으로써, 오디오와 LLM 간의 깊은 통합을 구현
- 모델 성능 향상을 위해 음향 특징의 압축 방법, attention mask 설계, LoRA fine-tuning 등 여러 측면 탐구
- 13개 언어 -> 영어 (ST) 과제에서 seq2seq 기준 모델보다 유의미하게 나은 성능
- 처음부터 학습된(decoder-only) 모델 역시 약 40% 적은 파라미터로도 기준 모델과 비슷한 성능을 달성함을 보여주어, decoder-only 구조가 일반적인 음성-텍스트 모델링에도 잠재력이 있음을 입증
[!question] 질문
1. 왜 seq2seq 모델과 비교한 것인가?
- 논문의 핵심 주장을 검증하기 위해 대조군 역할
- 논문이 풀고 싶은 문제는 "음성 입력을 다루면서도 LLM (decoder) 구조를 유지할 수 있을까?"
- 기존의 seq2seq 구조 대신 decoder-only로도 같은 성능을 내고자 하였음2. Audio encoder도 Encoder 아님?
- Encoder는 입력을 의미 벡터로 바꾸는 역할
- Encoder-Decoder 구조에서는 Encoder가 입력 전체를 고정된 의미 벡터 또는 벡터 시퀀스로 바꾸는 것이고 Decoder는 그 벡터를 조건으로 autoregressive하게 출력 y를 생성 = Decoder는 입력 x를 절대 직접 보지 못함
- Decoder-only의 경우 입력x와 출력 y를 하나의 시퀀스로 붙여 넣기에 Decoder는 prefix 전체(음성+프롬프트)를 그대로 본다.
- 그럼 왜 다른가. Encoder는 입력을 자기 공간으로 바꾸지만 Audio Encoder는 LLaMA의 embedding 공간으로 바꾼다. encoder가 아니라 그냥 adapter의 역할을 할 뿐.
- 그래서 Audio Encoder의 output은 입력 x에 대한 인코딩 결과가 아니라 LLM이 이해할 수 있는 형태로 바꾼 입력 token들에 가까움.
