[논문리뷰] Boosting Universal LLM Reward Design through Heuristic RewardObservation Space Evolution
paper-review
목록 보기
6/15
-
2025.04
-
LLMs이 어떻게 강화학습 보상 설계를 자동화하는 데 사용될 수 있는지를 설명하고 있음
- 보상관측 구간(ROS)을 구축 -> 관련 환경 상태 선택
- Reward Observation Space!
- We propose 테이블 기반 탐색 캐싱 메커니즘과 텍스트-코드 조정 전략을 통해 ROS를 발전시켜 LLM 기반 보상 설계를 개선하는 새로운 휴리스틱 프레임워크
Introduction
- poorly designed rewards can hinder the learning process or lead to unintended behaviors
- This work aims to build a universal RL reward design scheme with LLMs.
= 본 연구는 LLM을 활용한 보편적인 RL 보상 설계 방안을 구축하는 것을 목표로 함
==도전과제는 뭐냐?==
- RL 에이전트가 LLM의 planning을 이해할 수 있어야 함
- LLM code가 RL 에이전트 control할 수 있어야 함.
신기한 단어.. IRL : Inverse Reinforcement Learning
Related Work
[보상 디자인 문제]
- 보상은 에이전트가 주어진 환경에서 바람직한 행동을 배우는 주요한 매커니즘
- 연속 제어를 포함하는 로봇 조작의 경우에는 보상 디자인이 훨씬 어려워짐
- Eureka 프레임워크의 경우 원시 환경 설명 및 작업 코드에서 보상 함수를 생성함
- BUT Eureka에서 생성된 품질은 일관성이 없을 수 있음
[시뮬레이션에서 로봇 학습 확장]
= Scaling up Robotic Learning in Simulations
- 로봇 학습 확장의 핵심 문제는 시뮬레이션 환경 내에서 다양하고 의미 있는 작업을 생성하는 것
- Meta-World와 같은 프레임워크는 로봇이 전송 가능한 기술을 개발하도록 장려하는 조작 작업 모음을 제공함
Problem Formulation
- 일반적인 RL 환경에 대한 보상 함수 설계 문제(Reward Design Problem, RDP)
- 와 같은 튜플로 공식화 가능
- 모델 M이 주어졌을 때 최적의 보상 함수는
- : 피트니스 함수 = 정책을 통해 도출된 결과의 품질을 평가
- : 보상함수 R이 특정한 정책 을 통해 주어진 환경에서 얼마나 잘 작동하는지 나타내는 피드백 함수
Methodology
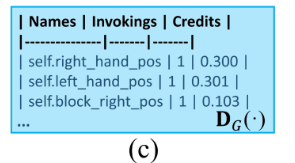
LLM을 활용해 자연어 기반이 보상 함수를 생성하고 점진적으로 개선하는 자동화된 시스템
강화학습 에이전트를의 보상 함수를 LLM이 생성하고, 시뮬레이션 피드백을 통해 점진적으로 진화시키는 자동화 루프로 구성됨.
| 항목 | 의미 | 역할 | 예시 |
|---|---|---|---|
| Task Desc U | 자연어로 된 과업 목표 | D_U로 정제되어 LLM_R의 입력에 사용 | 물체를 여기로 옮겨라! |
Task Code M | 환경과 로봇, 물리 시뮬레이션 전체 | RL 훈련을 위한 문제 정의와 실행 환경 제공 | 로봇팔, 물체, 중력, 초기 조건, 충돌 처리 등 |
Success Function F_sc | 이 task에서 "성공"이란 무엇인가? | RL 훈련 결과가 목표를 달성했는지 평가 | "물체가 목표 위치에 있다면 성공(1), 아니면 실패(0)" |
- 만약, BlockStatck task라면
# M(Task code)
class ShadowHandBlockStackVecTask:
def _init_(): ...
def _compute_obs(): ...
def _compute_reward(): ...
# F_sc(Success Function)
def F_sc(obs):
return 1 if block_height > threshold else 0- 학습 성능 평가에 사용되며 보상함수 R과는 별개임
🎃 보상함수 R과 성공함수 F
- 보상함수는 에이전트가 학습할 수 있는 신호를 주는 함수로 보통 연속적인 수치값이며 목적은 에이전트를 훈련시키는 것이다.
- 성공함수는 어떤 시도가 성공했는지 평가하는 기준으로 보통 이진값이며 훈련 결과를 평가한다.
A. User-expert Mission Reconcling
==성공 기준이 있는 경우==
- 사용자는 자연어로 과제를 설명()하고, 전문가는 성공 조건을 코드로 정의한다.()
- 이 둘의 표현이 모순되면 LLM이 혼란스러울 수 있으므로 다른 LLM = LLMC를 이용해 양쪽 정보를 구조화된 템플릿(TU)로 조율
- 결과 : 보상설계에 사용하는 임무 설명 (DU(U))과 성공함수 F_sc가 일관성을 가짐.
==성공 기준이 없는 경우==
- 만약 전문가의 성공 조건이 없다면, 기존의 비슷한 과제를 참고해 새로운 성공 조건도 LLM이 생성할 수 있음
- 이 경우 LLM이 사용자 설명 U를 바탕으로 만든 정형화된 태스크 설명 DU(U)와, 그에 맞춰 자동으로 생성한 성공 기준 코드를 세트로 반환한다는 듯
- 기존에 정의된 유사 태스크를 참고해 현재 새로운 태스크에 맞는 성공 조건을 자동으로 생성해주는 과정
B. Observation Space Evaluation
Observation Space disentanglement
- ROS(Reward Obervation Space) : 보상 함수는 일련의 상태 및 상태 간 연산으로 구성
- 문제점 : 이전 보상 코드 예제를 다음 반복에 그대로 사용하면 탐색이 제한됨
- 해결 : ROS를 두 단계로 나눠 설계
- 어떤 상태(state)들을 사용할지 선택 ex. 로봇의 위치, 속도
- : 선택한 상태에서 어떤 연산(operation)을 수행할지 정의 ex. 얼마나 빠르면 보상을 줄 것인지!
- 처음에는 어떤 상태가 중요한지 모르니 다양한 상태들을 탐색하고, 상태 조합이 괜찮아졌다면 그 상태로 어떤 조건을 써야 할지 고민!
= 무엇을 볼 것인가, 그걸 어떻게 계산할 것인가
- 반복마다 조건에 따라 LLM이
ROSst또는ROSop중 하나를 수정하게 유도
- 홀수 반복 또는 낮은 성과 ->ROSst재설계 = 탐색 확대
- 짝수 반복이면서 성과 좋을 때 ->ROSop개선 = 성공도 향상
State execution table
- 열1 : M의 모든 상태 이름
- 열2 : 각 상태가 모든 과거 보상에서 채택된 횟수
- 열3 : 각 상태의 작업 성공에 대한 기여도
==LLM이 과거 보상을 어떻게 기억하고 정리하는지에 대한 공식==
- : 보상 기록을 요약하는 함수
- : n번째 반복에서 나온 k 번째 보상 함수
- : 보상 함수 R이 사용하는 환경 상태(state)들
- : 이전까지 쌓아온 State Execution Table
🎃 ROS_op는 저장하지 않는 것?
- 보상 전략은 연산 방식이 너무 다양하고 미묘해서 저장하지 않음
- LLM은 어차피 매 iteration마다 다양한 보상 전략을 생성할 수 있기 때문에 저장보다는 즉석 생성 + 성능 피드백(F_sc)을 통해서 진화시키는 것이 더 효율적
정리해보면
- : 사용자가 입력한 자연어 설명을 LLM_C가 받아들여 구조화된 목표구조로 바꿈
- LLM_R : DU와 과거 피드백 정보를 받아서 K개의 보상 함수를 생성함 = 메인 LLM
- Sim : 시뮬레이션 실행 : 각 보상 함수를 실제 RL에 넣고 에이전트가 학습하고 성공률을 측정함
- : 각 보상 함수가 실제 RL에서 얼마나 효과적이었는지 측정

- 이렇게 성능지표가 출력된다- : 보상 탐색 히스토리 저장 : 각 보상 코드에서 어떤 상태들을 사용했는지 확인하고
State Execution Table에 누적 저장 - : 보상 코드에서 핵심 정보를 추출하는 역할!
- ROS_st와 ROS_op 둘 중 하나를 선택해서 다음 iteration에 전달
C. Implementation Details
- GPT-4 사용, Temperature = 1.0
- 각 evolution은 N=5 반복이고 K=16개의 샘플을 동시에 생성
- 8개의 NVIDIA RTX 3090 GPU 분산 훈련
- 최대 상호 작용 epoch는 LLMR 설계 프로세스에서 3000으로, 평가 프로세스에서 6000으로 설정됨
Experiment
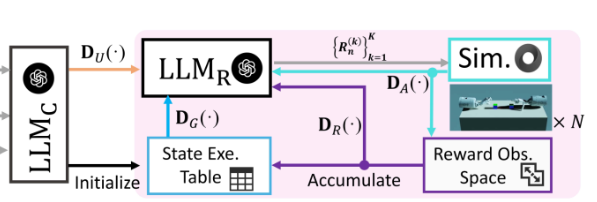
- 20가지의 태스크 중 9개의 태스크에서 Eureka보다 성능이 우수하고 5개의 극단적인 단순/어려운 태스크에서 Eureka의 성능과 일치함.
- 6개의 태스크(BlockPush, CatchAbreast, CatchOver2Underarm, DoorCloseOutward, ReOrientation, LiftUnderarm)에서만 약간 낮음
==Ablation Study==
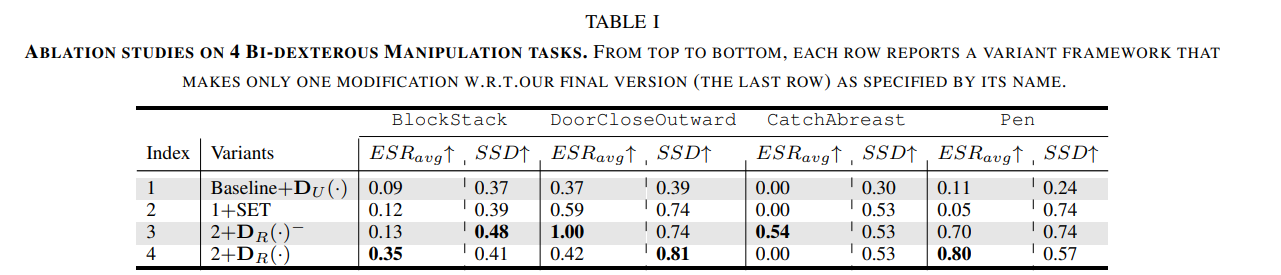
1: 사용자 설명을 구조화해서 입력하지만 다른 보조 요소는 없음.2: Baselione+D_U에서 시작해서 상태 실행 테이블(SET)이 도입되면DoorCloseOutward작업에서 EGR_avg가 0.37에서 0.59로 증가함3:2에서 Rward Observation Space(ROS) disentanglement를 고정된 임계값으로 추가4:3에서 고정 임계값 대신 작업별로 조정된 동적 임계값 사용
Conclusion
==기존 문제점==
LLM과 RL 간 보상 설계 커뮤니케이션이 어려움. 특히, 상태 선택이 일회성이며, 전문가 정의 성공 조건과 사용자 설명이 어긋나는 문제가 있음.
==제안 해결책==
- In this work, we introduced a novel framework that enhances the design of reinforcement learning (RL) rewards by harnessing the capabilities of large language models (LLMs).
- 보상 관찰 공간(ROS)를 휴리스틱하게 진화시킴
- 과거 상태 기록을 표로 정리(SET) -> LLM이 이전 보상을 잊지 않게 해줌
= By incorporating a table-based exploration caching mechanism, we alleviate the Markovian constraint commonly found in LLM dialogue - 사용자의 설명과 전문가 기준을 LLM으로 조율
==향후 연구==
- 더 복잡한 실제 시나리오에 프레임워크 확장하고, 피드백 루프를 더욱 정교하게 다듬는 방향으로 연구를 확장

얍얍