논문 번역
- 이 글은 제가 읽는 논문을 번역해서 올려놓는 공간입니다.
- 번역은 LLM(현재는 GPT-4)를 통해 번역하고 있습니다.
- 대략의 pipeline은 mathpix를 통해 ocr후 gpt-4로 대략 1000토큰 단위로 나누어 번역하고 있습니다. 논문->ocr을 통한 markdown으로 변경 -> markdown로 작성된 논문을 gpt-4 api로 번역 및 markdown으로 작성
- 현재까지 완성된 파이프라인은 https://github.com/aeolian83/paper_translator 입니다
- 원문 링크는 다음과 같습니다.
언어 모델은 소수샷 학습자(Few-Shot Learners)입니다

초록(Abstract)
우리는 언어 모델을 크게 확장하는 것이 과제에 구애받지 않는 소수샷(few-shot) 성능을 크게 향상시키며, 때로는 이전의 최신 상태(state-of-the-art) 미세조정(fine-tuning) 접근법과 경쟁할 수 있음을 보여줍니다. 구체적으로, 우리는 1750억 개의 매개변수를 가진 자동회귀 언어 모델인 GPT-3을 훈련시키고, 이전의 비희소(non-sparse) 언어 모델보다 10배 많은 매개변수를 가지고 있으며, 소수샷 설정에서 그 성능을 테스트합니다. 모든 과제에 대해, GPT-3는 그라디언트 업데이트나 미세조정 없이 적용되며, 과제와 소수샷 시연은 모델과의 텍스트 상호작용을 통해 순수하게 지정됩니다. GPT-3는 번역, 질문 응답, 클로즈(cloze) 과제를 포함한 많은 자연어 처리(NLP) 데이터셋에서 강력한 성능을 달성합니다. 우리는 또한 GPT-3의 소수샷 학습이 여전히 어려움을 겪는 몇몇 데이터셋과 대규모 웹 코퍼스에서의 훈련과 관련된 방법론적 문제에 직면하는 몇몇 데이터셋을 확인합니다.
1 서론(Introduction)
자연어 처리(NLP)는 과제별 특화된 표현을 학습하고 과제별 특화된 아키텍처를 설계하는 것에서 과제에 구애받지 않는 사전 훈련(pre-training)과 과제에 구애받지 않는 아키텍처를 사용하는 것으로 전환되었습니다. 이러한 전환은 독해, 질문 응답, 텍스트 함축(textual entailment) 등 많은 도전적인 NLP 과제에서 상당한 진전을 이루었습니다. 비록 아키텍처와 초기 표현이 이제 과제에 구애받지 않게 되었지만, 최종적인 과제별 단계가 남아 있습니다: 원하는 과제를 수행하기 위해 과제에 구애받지 않는 모델을 적응시키기 위해 대규모 예제 데이터셋에서의 미세조정입니다.
최근의 연구 [ ]는 이 최종 단계가 필요하지 않을 수도 있다고 제안했습니다. 는 단일 사전 훈련된 언어 모델이 표준 NLP 과제를 수행하기 위해 제로샷(zero-shot) 전이될 수 있음을 보여주었습니다[^0]
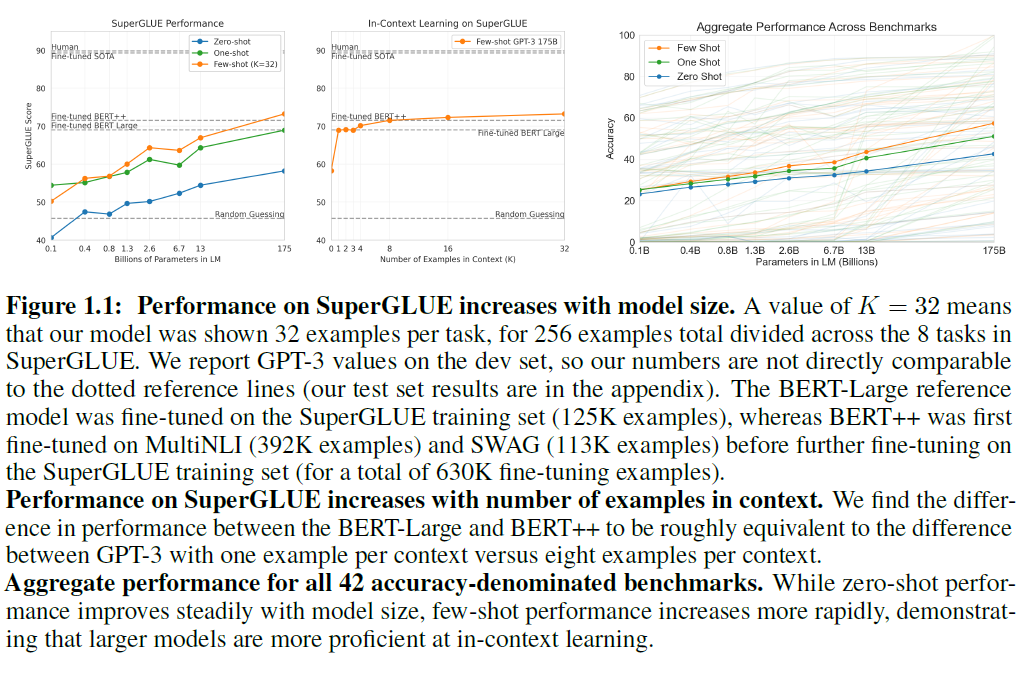
그림 1.1: SuperGLUE에서 모델 크기에 따라 성능이 향상됩니다. 의 값은 모델이 SuperGLUE의 8개 과제에 걸쳐 총 256개의 예제 중 과제당 32개의 예제를 보여줬음을 의미합니다. 우리는 GPT-3의 개발 세트(dev set) 값을 보고하므로, 우리의 숫자는 점선 참조선과 직접 비교할 수 없습니다(우리의 테스트 세트 결과는 부록에 있습니다). BERT-Large 참조 모델은 SuperGLUE 훈련 세트(125K 예제)에서 미세조정되었으며, BERT++는 MultiNLI(392K 예제)와 SWAG(113K 예제)에서 먼저 미세조정된 후 SuperGLUE 훈련 세트에서 추가로 미세조정되었습니다(총 630K 미세조정 예제).
SuperGLUE에서 맥락 내 예제 수에 따라 성능이 향상됩니다. 우리는 BERT-Large와 BERT++ 사이의 성능 차이가 GPT-3가 맥락당 한 예제를 가진 것과 여덟 예제를 가진 것 사이의 차이와 대략 동등하다는 것을 발견했습니다.
모든 42개의 정확도 기반 벤치마크에 대한 종합 성능. 제로샷 성능은 모델 크기와 함께 꾸준히 향상되지만, 소수샷 성능은 더 빠르게 증가하여, 더 큰 모델이 맥락 내 학습(in-context learning)에서 더 능숙함을 보여줍니다.
훈련 예제 데이터셋에서의 미세조정 없이도 가능합니다. 이 연구는 유망한 개념 증명이었지만, 최고의 경우 성능은 단일 데이터셋에서 일부 감독된 기준선과만 일치했습니다. 대부분의 과제에서 성능은 여전히 간단한 감독된 기준선에서도 멀었습니다.
그러나 는 앞으로 나아갈 수 있는 잠재적인 방법도 보여주었습니다. 이 연구는 한 차수의 스케일링에서 전이 과제와 언어 모델링 손실 모두에서 비교적 일관된 로그-선형(log-linear) 추세를 관찰했습니다. 는 로그 손실의 스케일링 행동에 대한 훨씬 더 철저한 연구를 수행하고 부드러운 스케일링 추세를 확인했습니다. 이 연구에서는 이전에 확인된 현상을 두 차수의 크기로 확장하여 성능이 계속 향상되는지 경험적으로 테스트합니다. 우리는 1750억 매개변수의 자동회귀 언어 모델인 GPT-3을 훈련시키고 그 전이 학습 능력을 측정합니다.
이 연구의 일환으로, 우리는 또한 에서 소개된 접근법을 명확히 하고 체계화합니다. 는 그들의 작업을 "제로샷(zero-shot) 작업 전이"라고 설명하지만 때때로 관련 작업의 예를 맥락 속에서 제공합니다. 효과적으로 훈련 예제를 사용하기 때문에, 이러한 경우는 "원샷(one-shot)" 또는 "퓨샷(few-shot)" 전이로 더 잘 설명됩니다. 우리는 이 원샷과 퓨샷 설정을 자세히 연구하고, 수행할 작업의 자연어 설명이나 호출만을 사용하는 제로샷 설정과 비교합니다. 우리의 발견은 그림 1.1에 요약되어 있습니다. 우리는 원샷과 퓨샷 성능이 종종 진정한 제로샷 성능보다 훨씬 높다는 것을 관찰하며, 이는 언어 모델이 느린 외부 루프 경사 하강법(outer-loop gradient descent) 기반 학습과 모델의 맥락 활성화 내에서 구현된 빠른 "맥락 내(in-context)" 학습이 결합된 메타 학습자(meta-learners)로 이해될 수도 있다고 제안합니다.
일반적으로, NLP 작업에서 GPT-3는 제로샷과 원샷 설정에서 유망한 결과를 달성하며, 퓨샷 설정에서는 때때로 최신 기술(state-of-the-art)과 경쟁하거나 심지어 능가하기도 합니다(최신 기술이 미세 조정된 모델에 의해 유지되는 것에도 불구하고). 예를 들어, GPT-3는 제로샷 설정에서 CoQA에서 81.5 F1을 달성하고, 원샷 설정에서는 84.0 F1을, 퓨샷 설정에서는 을 달성합니다. 마찬가지로, GPT-3는 제로샷 설정에서 TriviaQA에서 정확도를 달성하고, 원샷 설정에서는 를, 퓨샷 설정에서는 71.2\%를 달성하는데, 이 마지막 설정은 같은 클로즈드-북(closed-book) 설정에서 운영되는 미세 조정된 모델에 비해 최신 기술입니다.
우리는 또한 제로샷, 원샷, 퓨샷 설정에서 GPT-3의 성능과 비교하기 위해 1억 2500만 개의 매개변수에서 130억 개의 매개변수에 이르는 일련의 더 작은 모델들을 추가로 훈련합니다. 일반적으로, 우리는 세 가지 설정 모두에서 대부분의 작업에 대해 모델 용량과 관련하여 비교적 부드러운 스케일링을 발견합니다; 한 가지 주목할 만한 패턴은 모델 용량이 커질수록 제로샷, 원샷, 퓨샷 성능 간의 격차가 종종 커진다는 것으로, 이는 더 큰 모델이 더 능숙한 메타 학습자일 수 있음을 시사하는 것 같습니다.
2 접근법
우리의 기본 사전 훈련 접근법은 모델, 데이터, 그리고 훈련을 포함하여 에서 설명된 과정과 유사하며, 모델 크기, 데이터셋 크기 및 다양성, 그리고 훈련 기간의 상대적으로 단순한 확장입니다. 우리가 사용하는 맥락 내 학습도 [ $\left.\mathrm{RWC}^{+} 19\right]$와 유사하지만, 이 작업에서는 맥락 내에서의 학습에 대한 다양한 설정을 체계적으로 탐구합니다:
- 파인 튜닝(Fine-Tuning, FT) - 사전 훈련된 모델의 가중치를 업데이트하기 위해 특정 작업에 필요한 수천 개의 지도 학습 레이블로 훈련합니다. 파인 튜닝의 주요 장점은 많은 벤치마크에서 강력한 성능입니다. 주요 단점은 각 작업마다 새로운 대규모 데이터셋이 필요하다는 점, 분포 외(out-of-distribution)에서 일반화가 떨어질 가능성 [MPL19], 그리고 훈련 데이터의 허위 특징을 이용할 가능성 [GSL , NK19]입니다. 우리는 작업에 구애받지 않는 성능에 초점을 맞추며, 파인 튜닝은 향후 작업으로 남겨둡니다.
- 퓨샷(Few-Shot, FS) - 모델은 추론 시점에 작업의 몇 가지 예시를 조건으로 제공받지만, 가중치는 업데이트되지 않습니다 . 예시에는 일반적으로 맥락과 원하는 완성(예를 들어 영어 문장과 그 프랑스어 번역)이 포함되며, 퓨샷은 개의 맥락과 완성 예시를 제공한 다음, 마지막으로 하나의 맥락 예시를 제공하고 모델이 완성을 제공할 것으로 기대합니다(자세한 내용은 부록 참조). 우리는 일반적으로 를 10에서 100 사이로 설정합니다. 이는 모델의 맥락 창()에 맞출 수 있는 예시의 수입니다. 퓨샷의 주요 장점은 작업 특정 데이터에 대한 필요성을 크게 줄일 수 있다는 것입니다. 주요 단점은 이 방법으로 얻은 결과가 지금까지 최신 기술의 파인 튜닝된 모델보다 훨씬 나쁘다는 것입니다. 또한, 여전히 소량의 작업 특정 데이터가 필요합니다. 이름에서 알 수 있듯이, 여기서 설명하는 언어 모델을 위한 퓨샷 학습은 ML의 다른 맥락에서 사용되는 퓨샷 학습과 관련이 있습니다 [HYC01, $\left.\mathrm{VBL}^{+} 16\right]$ - 둘 다 광범위한 작업 분포를 기반으로 학습하고 새로운 작업에 빠르게 적응하는 것을 포함합니다.
- 원샷(One-Shot, 1S) - 퓨샷과 비슷하지만 입니다.
- 제로샷(Zero-Shot, 0S) - 퓨샷과 비슷하지만 예시 대신 작업에 대한 자연어 설명을 사용합니다.
부록에는 영어에서 프랑스어로 번역하는 예시를 사용하여 네 가지 방법을 시연합니다. 이 논문에서 제시하는 퓨샷 결과가 가장 높은 성능을 달성했지만, 원샷이나 심지어 때때로 제로샷이 인간의 성능과 가장 공정한 비교처럼 보이며, 향후 작업을 위한 중요한 목표입니다.
2.1 모델과 아키텍처
우리는 GPT-2 와 동일한 모델과 아키텍처를 사용합니다. 여기에는 수정된 초기화, 사전 정규화, 그리고 그 안에서 설명된 가역 토큰화를 포함합니다. 단, 트랜스포머의 레이어에서 번갈아 가며 밀집된(dense) 및 지역적으로 띠 모양의 희소(sparse) 주의 패턴을 사용하는 것이 예외입니다. 이는 Sparse Transformer [CGRS19]와 유사합니다. ML 성능이 모델 크기에 어떻게 의존하는지 연구하기 위해, 1억 2500만 개의 매개변수에서 1750억 개의 매개변수에 이르는 8가지 크기의 모델을 훈련시켰으며, 마지막 모델을 우리는 GPT-3라고 부릅니다. 이 모델 크기의 범위는 에서 소개된 스케일링 법칙을 테스트할 수 있게 해줍니다.
우리 모델의 크기와 아키텍처에 대한 자세한 내용은 부록에서 찾을 수 있습니다. 우리는 각 모델을 노드 간 데이터 전송을 최소화하기 위해 깊이와 너비 차원 모두에서 GPU에 분할합니다.
2.2 훈련 데이터셋
훈련 데이터를 만들기 위해, 우리는 (1) 고품질 참조 코퍼스 범위와 유사성을 기반으로 CommonCrawl [ ]의 버전을 다운로드하고 필터링하고, (2) 중복성을 방지하고 우리의 보류된 검증 세트의 정확성을 유지하기 위해 데이터셋 내외부에서 문서 수준에서 퍼지 중복 제거를 수행하며, (3) CommonCrawl을 보완하고 다양성을 증가시키기 위해 알려진 고품질 참조 코퍼스를 훈련 혼합에 추가했습니다. 이 참조 코퍼스에는 WebText 데이터셋의 확장 버전이 포함됩니다 , 수집된[^1]
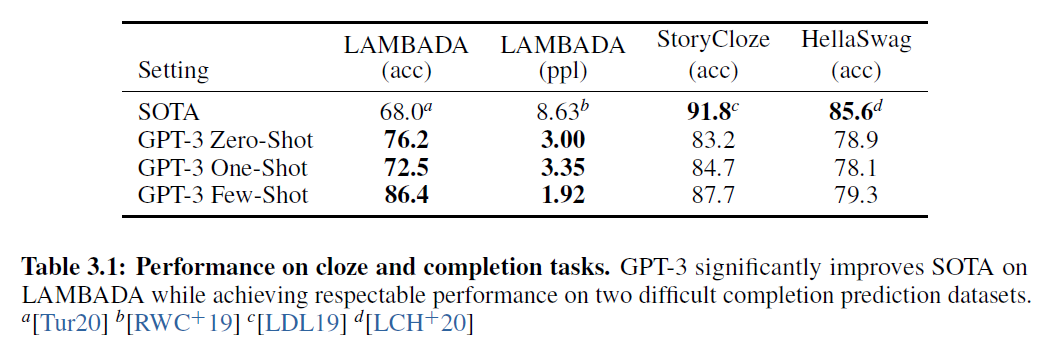
표 3.1: 클로즈 테스트와 완성 작업에서의 성능. GPT-3는 LAMBADA에서 SOTA를 크게 향상시키면서, 두 개의 어려운 완성 예측 데이터셋에서도 존경할 만한 성능을 달성했습니다. Tur20] LDL19]
긴 기간 동안 링크를 스크래핑하고, 에서 처음으로 설명된 두 개의 인터넷 기반 책 코퍼스(Books1과 Books2)와 영어 위키백과(부록에서 자세한 내용)를 사용했습니다.
2.3 훈련 과정
, MKAT18]에서 발견된 바와 같이, 더 큰 모델은 일반적으로 더 큰 배치 크기를 사용할 수 있지만, 더 작은 학습률이 필요합니다. 우리는 훈련 중에 그래디언트 노이즈 스케일을 측정하고 배치 크기를 선택하는 데 이를 활용합니다 [MKAT18]. 표 A.1은 우리가 사용한 파라미터 설정을 보여줍니다. 메모리 부족 없이 더 큰 모델을 훈련하기 위해, 우리는 각 행렬 곱셈 내에서의 모델 병렬성과 네트워크의 레이어들에 걸친 모델 병렬성의 혼합을 사용합니다. 모든 모델은 고대역폭 클러스터의 일부에서 V100 GPU에서 훈련되었습니다. 훈련 과정과 하이퍼파라미터 설정의 자세한 내용은 부록에 설명되어 있습니다.
2.4 평가
퓨샷 학습의 경우, 평가 세트의 각 예제를 해당 작업의 훈련 세트에서 무작위로 추출한 예제를 조건으로 하여 평가하며, 작업에 따라 1개 또는 2개의 새 줄로 구분됩니다. LAMBADA와 StoryCloze의 경우, 감독된 훈련 세트가 없으므로 개발 세트에서 조건 예제를 추출하고 테스트 세트에서 평가합니다.
일부 작업에서는 (또는 인 경우, 시연 대신) 자연어 프롬프트를 사용합니다. 와 유사하게 때때로 답변의 형식을 변경하기도 합니다. 작업별 예제는 부록에서 확인할 수 있습니다.
자유 형식 완성 작업에서는 와 동일한 파라미터를 사용하여 빔 서치를 사용합니다: 빔 너비는 4이고 길이 패널티는 입니다.
최종 결과는 공개적으로 이용 가능한 테스트 세트에서 보고되며, 각 모델 크기와 학습 설정(제로샷, 원샷, 퓨샷)에 대해 보고됩니다. 테스트 세트가 비공개인 경우, 우리 모델은 종종 테스트 서버에 맞지 않을 정도로 크기 때문에 개발 세트에서 결과를 보고합니다.
3 결과
3.1 언어 모델링, 클로즈, 완성 작업
우리는 전통적인 언어 모델링 작업뿐만 아니라 관련 작업에서 GPT-3의 성능을 테스트합니다. 우리는 에서 측정된 펜 트리 뱅크(Penn Tree Bank, PTB) 데이터셋에서 제로샷 혼란도(perplexity)를 계산합니다. 우리의 훈련 세트에 포함된 데이터셋의 높은 비율 때문에 위키피디아 관련 작업 4개와 10억 단어 벤치마크는 생략합니다. 우리의 가장 큰 모델은 PTB에서 15점이라는 상당한 차이로 새로운 SOTA를 설정합니다.
LAMBADA 데이터셋 은 모델이 단락의 마지막 단어를 예측하도록 요구합니다. 에서는 이 벤치마크에서 언어 모델의 규모를 확장하는 것이 수익률이 감소하고 있다고 제안했지만, 우리는 제로샷(zero-shot) GPT-3이 이전 최고 기록(state-of-the-art)보다 의 실질적인 향상을 달성했다는 것을 발견했습니다. 퓨샷(few-shot) 설정에서는 언어 모델이 단어 하나만 생성하도록 유도하기 위해 빈칸 채우기 형식(fill-in-the-blank format)을 사용합니다(예: Alice was friends with Bob. Alice went to visit her friend, Bob). 이 형식을 사용하여 GPT-3은 이전 최고 기록보다 이상 증가한 성능을 달성했습니다.
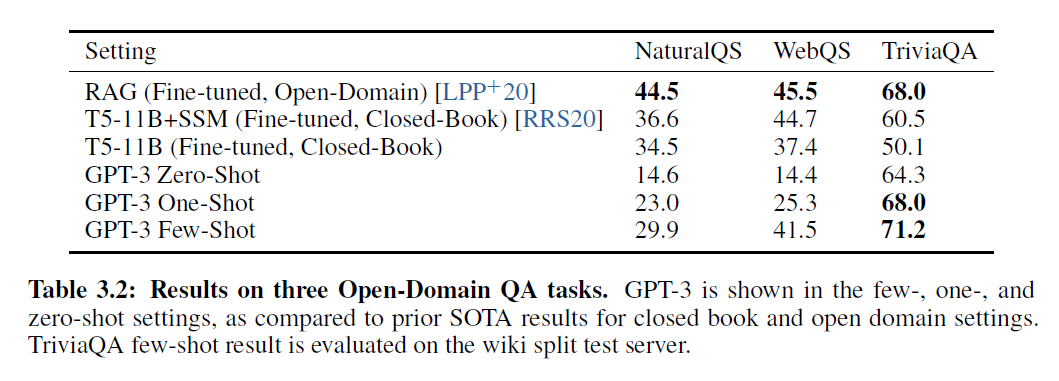
표 3.2: 세 가지 오픈 도메인 QA 작업에서의 결과. GPT-3는 퓨샷, 원샷, 제로샷 설정에서 보여지며, 클로즈드 북과 오픈 도메인 설정에 대한 이전 SOTA 결과와 비교됩니다. TriviaQA 퓨샷 결과는 위키 분할 테스트 서버에서 평가되었습니다.
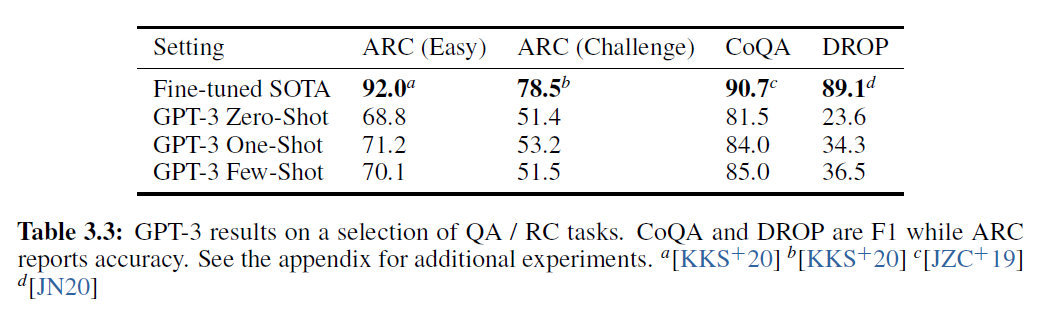
표 3.3: QA / RC 작업에서의 GPT-3 결과 선택. CoQA와 DROP은 F1 점수를, ARC는 정확도를 보고합니다. 추가 실험은 부록에서 확인할 수 있습니다.
모델 크기가 커질수록 성능이 부드럽게 향상됩니다. 그러나 빈칸 채우기 방법은 원샷(one-shot)에서 효과적이지 않으며, 항상 제로샷(zero-shot) 설정보다 성능이 떨어지는 것으로 나타났습니다. 아마도 모든 모델이 패턴을 인식하기 위해 여러 예시가 필요하기 때문일 것입니다. 테스트 세트 오염 분석은 LAMBADA 데이터셋의 상당수가 우리의 훈련 데이터에 존재하는 것으로 보이지만, 4장에서 수행된 분석은 성능에 미미한 영향을 미친다고 제안합니다.
HellaSwag 데이터셋 은 이야기나 지시 사항 세트의 최고의 결말을 선택하는 것을 포함합니다. 예시들은 언어 모델에게 어렵게 하면서도 인간에게는 쉽게 남아있도록 적대적으로 추출되었습니다. GPT-3은 1.5B 파라미터 언어 모델[ZHR $\left.{ }^{+} 19\right]$을 미세조정한 것보다 더 나은 성능을 보이지만, 미세조정된 멀티태스크 모델 ALUM이 달성한 전체 SOTA보다는 여전히 상당히 낮습니다.
StoryCloze 2016 데이터셋 은 다섯 문장으로 이루어진 이야기의 올바른 결말 문장을 선택하는 것을 포함합니다. 여기서 GPT-3는 이전의 제로샷(zero-shot) 결과보다 대략 향상되었지만, 여전히 BERT 기반 모델을 사용한 파인튜닝(fine-tuned)된 SOTA(state-of-the-art)보다 낮습니다 [LDL19].
3.2 질문 응답
이 섹션에서는 GPT-3가 다양한 질문 응답 작업을 처리하는 능력을 측정합니다. 먼저, 광범위한 사실 지식에 대한 질문에 답하는 데이터셋을 살펴봅니다. 우리는 [RRS20]이 제안한 "클로즈드-북(closed-book)" 설정(즉, 조건 정보/기사 없음)에서 평가합니다. TriviaQA [JCWZ17]에서 GPT-3 제로샷(zero-shot)은 이미 파인튜닝(fine-tuned)된 T5-11B를 앞서며, 또한 사전 훈련 중 Q&A 맞춤형 범위 예측(span prediction)을 사용한 버전보다 3.8\% 더 뛰어납니다. 원샷(one-shot) 결과는 향상되어, 파인튜닝(fine-tuned)뿐만 아니라 21M 문서의 15.3B 파라미터 밀집 벡터 인덱스(dense vector index)에 대한 학습된 검색 메커니즘을 사용하는 오픈 도메인 QA 시스템의 SOTA(state-of-the-art)와 동등합니다 . GPT-3의 퓨샷(few-shot) 결과는 이를 넘어 추가로 성능이 향상됩니다. Natural Questions (NQs) 에서는 GPT-3가 파인튜닝(fine-tuned)된 T5 보다 성능이 떨어집니다. NQs의 질문들은 위키피디아(Wikipedia) 지식에 대한 세밀한 정보를 요구하는 경향이 있어, 이는 GPT-3의 용량과 광범위한 사전 훈련 분포(pretraining distribution)의 한계를 시험할 수 있습니다.
는 3학년부터 9학년 과학 시험에서 수집된 객관식 질문으로 구성된 상식 추론(common sense reasoning) 데이터셋입니다. "Challenge" 버전의 데이터셋에서는 단순한 통계적 또는 정보 검색 방법으로는 정답을 찾을 수 없는 질문들로 필터링되었으며, GPT-3는 파인튜닝(fine-tuned)된 RoBERTa 기준선 의 성능에 근접합니다.
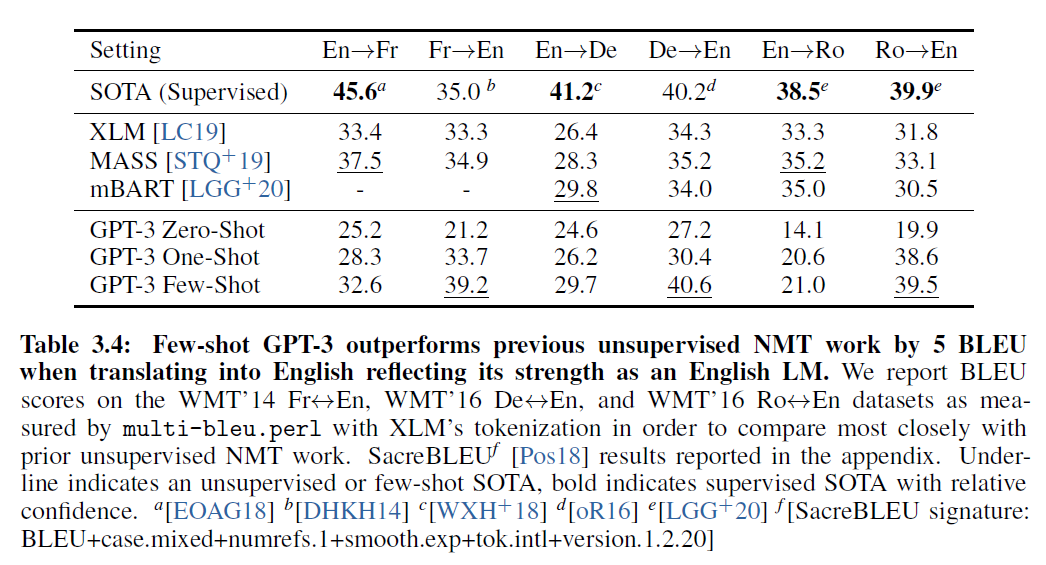
표 3.4: Few-shot GPT-3는 영어로 번역할 때 이전의 무지도 NMT 작업보다 5 BLEU로 우수한 성과를 보여주며 영어 LM의 강점을 반영합니다. WMT'14 Fr En, WMT'16 De En, 그리고 WMT'16 Ro En 데이터셋에서 XLM의 토큰화를 사용하여 multi-bleu.perl로 측정한 BLEU 점수를 보고, 이전의 무지도 NMT 작업과 가장 유사하게 비교하기 위해 SacreBLEU 결과를 별지에 보고했습니다. 밑줄은 무지도 또는 퓨-샷 SOTA를 나타내며, 굵은 글씨는 상대적인 확신과 함께 지도 SOTA를 나타냅니다. EOAG18 DHKH14] oR16] [SacreBLEU signature: BLEU+case.mixed+numrefs.1+smooth.exp+tok.intl+version.1.2.20]
"Easy" 버전의 데이터셋에서 GPT-3는 동일하게 fine-tuned된 RoBERTa 기준을 약간 능가합니다 그러나 이러한 결과 모두 에 의해 달성된 전반적인 SOTA보다 훨씬 나쁩니다.
마지막으로, 우리는 GPT-3를 두 가지 독해 데이터셋에서 평가했습니다. Few-shot GPT-3는 자유 형식의 대화 데이터셋인 CoQA [RCM19]에서 인간 기준에 3 점 이내의 성과를 보여줍니다. 이 데이터셋에서 이산적 추론과 숫자 능력을 테스트하는 DROP 에서는 원래 논문의 fine-tuned BERT 기준을 능가하지만 여전히 인간의 성능과 신호처리 시스템을 신경망에 추가하는 최첨단 접근법보다 낮은 성과를 보입니다 .
3.3 번역
GPT-3의 훈련 데이터 수집에서는 인터넷 텍스트 데이터셋(주로 Common Crawl)에 반영된 언어의 무필터링 분포를 사용했습니다. 결과적으로 GPT-3의 훈련 데이터는 주로 영어(단어 수 기준 93%)로 구성되어 있지만 7%의 비영어 콘텐츠도 포함되어 있습니다 (GPT-3 GitHub의 전체 목록 참조). 기존의 무지도 기계 번역 접근법은 종종 한 쌍의 단일 언어 데이터셋에 대한 사전 훈련과 back-translation [SHB15]을 결합하여 두 언어를 통제된 방식으로 연결합니다. 반면, GPT-3는 여러 언어를 섞어 훈련 데이터를 학습합니다. 또한, 우리의 one / few-shot 설정은 소량의 쌍 예시를 문맥 안에서 사용하기 때문에 이전의 무지도 작업과 엄격하게 비교할 수 없습니다 (1 또는 64).
Zero-shot GPT-3는 최근의 무지도 NMT 결과보다 성능이 낮지만, one-shot 설정은 7 BLEU로 성능을 향상시키고 이전 작업과 경쟁력 있는 성능을 보입니다. Few-shot GPT-3는 추가로 4 BLEU를 향상시켜 이전의 무지도 NMT 작업과 유사한 평균 성능을 보입니다. 연구한 세 가지 입력 언어에 대해 GPT-3는 영어로 번역할 때 이전의 무지도 NMT 작업을 크게 능가하지만, 다른 방향으로 번역할 때는 성능이 낮습니다. En-Ro의 성능은 이전의 무지도 NMT 작업보다 10 BLEU 이상 나쁜 것으로 나타납니다. 이는 거의 전적으로 영어로 구성된 GPT-2의 바이트 수준 BPE 토크나이저를 재사용하기 때문에 약점일 수 있습니다. Fr-En 및 De-En의 경우, few-shot GPT-3는 찾을 수 있는 최고의 지도 결과를 능가하지만, 우리가 문헌에 익숙하지 않고 경쟁력 없는 벤치마크로 보이기 때문에 이러한 결과가 실제 SOTA를 대표한다고 의심하지는 않습니다. Ro-En의 경우, few-shot GPT-3는 무지도 사전 훈련, 608K의 레이블이 지정된 예제에 대한 세밀한 조정 및 backtranslation [LHCG19b]으로 달성된 전반적인 SOTA에 매우 가까운 성과를 보입니다.
3.4 SuperGLUE
SuperGLUE 벤치마크는 데이터셋들의 표준화된 모음입니다 [WPN ${ }^{+}$19]. 소수샷(few-shot) 설정에서, 우리는 훈련 세트에서 무작위로 샘플링한 32개의 예시를 모든 작업에 사용했습니다. WSC와 MultiRC를 제외한 모든 작업에서, 각 문제의 맥락(context)으로 사용할 새로운 예시 세트를 샘플링했습니다. WSC와 MultiRC의 경우, 훈련 세트에서 무작위로 뽑은 동일한 예시 세트를 사용했습니다.
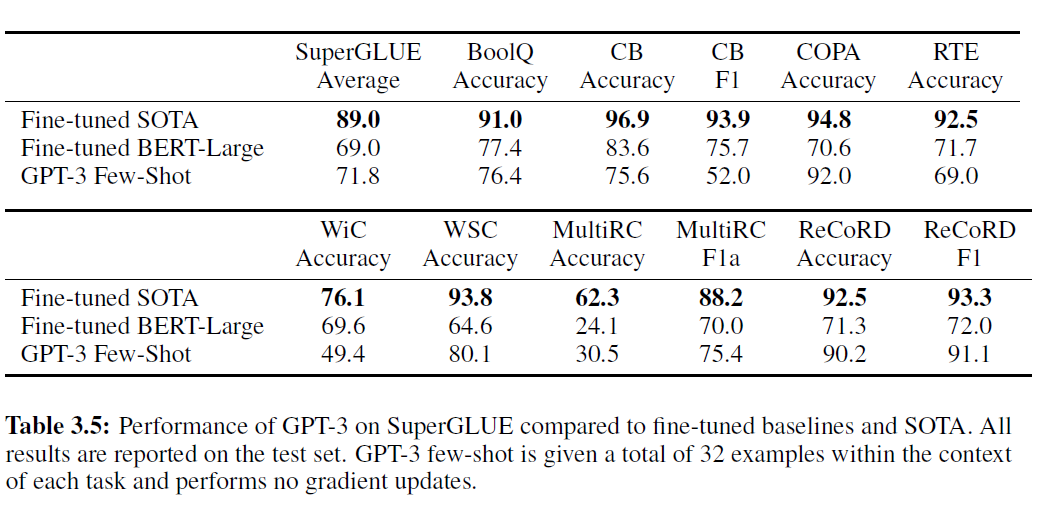
표 3.5: GPT-3의 SuperGLUE 성능 비교 - 미세조정된 기준선 및 최고 성능 모델(SOTA)과 비교. 모든 결과는 테스트 세트에서 보고됩니다. GPT-3 소수샷은 각 작업의 맥락에서 총 32개의 예시를 제공받고, 어떠한 기울기 업데이트도 수행하지 않습니다.
우리가 평가한 모든 문제의 맥락으로 사용됩니다. 우리는 의 값을 32까지 증가시켜 보았고, 소수샷 SuperGLUE 점수가 모델 크기와 맥락 속 예시의 수가 증가함에 따라 꾸준히 향상되며, 맥락 학습(in-context learning)의 이점이 증가하는 것을 확인했습니다(그림 1.1).
GPT-3의 작업별 성능에는 큰 차이가 있습니다. COPA와 ReCoRD에서 GPT-3는 원샷(one-shot)과 소수샷 설정에서 거의 최고 성능 모델(SOTA)에 근접한 성능을 달성했으며, COPA는 단 몇 점 차이로 2위를 기록했고, 1위는 110억 개의 파라미터를 가진 미세조정된 모델(T5)이 차지했습니다. WSC, BoolQ, MultiRC, RTE에서는 성능이 합리적이며, 미세조정된 BERT-Large와 대략 비슷합니다. CB에서는 소수샷 설정에서 로 생명의 징후를 보입니다. WiC는 무작위 선택과 동등한 소수샷 성능으로 눈에 띄는 약점입니다. 우리는 를 위해 다양한 문구와 형식을 시도했지만(두 문장에서 단어가 같은 의미로 사용되는지 판단하는 작업), 어느 것도 강력한 성능을 달성할 수 없었습니다. 이는 우리가 추가 자료에 포함된 다른 실험에서 본 현상을 시사합니다 - GPT-3는 두 문장이나 조각을 비교하는 일부 작업에서 소수샷 또는 원샷 설정에서 약한 것으로 보입니다. 이것은 RTE와 CB의 비교적 낮은 점수를 설명할 수도 있으며, 이들 역시 같은 형식을 따릅니다. 이러한 약점에도 불구하고, GPT-3는 여덟 개의 작업 중 네 개에서 미세조정된 BERT-Large를 능가하며, 두 개의 작업에서는 110억 개의 파라미터를 가진 미세조정된 최고 성능 모델에 근접합니다.
4 벤치마크의 기억화 측정 및 방지
데이터셋과 모델 크기는 GPT-2에 사용된 것보다 약 두 자릿수 더 크며, Common Crawl의 대량 데이터를 포함하여 오염과 암기 가능성이 증가합니다. 반면에, 데이터의 양이 많기 때문에, 심지어 GPT-3 175B도 상당한 양으로 훈련 세트를 과적합하지 않으며, 이는 중복 제거된 검증 세트와 비교하여 측정됩니다. 각 벤치마크에 대해, 우리는 잠재적으로 유출된 예시를 제거하는 '깨끗한' 버전을 만듭니다. 이는 대략적으로 사전 훈련 세트(pretraining set)와 13-그램 이상 겹치는 예시(또는 13-그램보다 짧을 때 전체 예시와 겹치는 경우)로 정의됩니다. 그런 다음 우리는 이 깨끗한 벤치마크에서 GPT-3을 평가하고 원래 점수와 비교합니다. 깨끗한 부분집합에서의 점수가 전체 데이터셋에서의 점수와 유사하다면, 이는 오염이 존재하더라도 보고된 결과에 중대한 영향을 미치지 않는다는 것을 시사합니다. 대부분의 경우 성능은 미미하게만 변화하며, 오염 수준과 성능 차이가 상관관계가 있다는 증거는 발견되지 않습니다. 우리는 보수적인 방법이 오염을 과대평가했거나 오염이 성능에 큰 영향을 미치지 않는다는 결론을 내립니다. 가장 문제가 되는 작업에 대한 방법론과 분석의 전체 세부사항은 부록에 제공됩니다.
5 한계점
텍스트 합성에서 GPT-3 샘플은 여전히 가끔 문서 수준에서 의미적으로 반복하거나, 충분히 긴 구절에서 일관성을 잃기 시작하거나, 모순을 포함하며, 때때로 비논리적인 문장이나 단락을 포함합니다. 우리의 릴리스 저장소에는 큐레이션되지 않은 무조건적인 샘플들이 포함되어 있습니다.
우리의 실험은 양방향 구조(bidirectional architectures)나 노이즈 제거(denoising)와 같은 다른 훈련 목표를 포함하지 않습니다. 우리의 설계 결정은 양방향성이 경험적으로 도움이 되는 작업들(예: 빈칸 채우기 작업, 두 내용을 돌아보고 비교하는 작업(ANLI, WIC), 긴 구절을 신중하게 고려한 후 매우 짧은 답을 생성해야 하는 작업(QuAC, RACE))에서 잠재적으로 더 나쁜 성능을 감수하는 비용이 됩니다.
우리의 목표는 모든 토큰을 동등하게 중요시하며, 예측해야 할 가장 중요한 것과 덜 중요한 것에 대한 개념이 없습니다. [RRS20]은 관심 있는 엔티티에 대한 예측을 맞춤화하는 것의 이점을 보여줍니다. 또한, 자기 감독(self-supervised) 목표를 가진 작업은 원하는 작업을 예측 문제로 강제하는 데 의존하는 반면, 궁극적으로 유용한 언어 시스템(예: 가상 비서)은 단순히 예측을 하는 것보다 목표 지향적인 행동을 하는 것으로 더 잘 생각될 수 있습니다. 마지막으로, 대규모 사전 훈련된 언어 모델은 비디오나 실제 물리적 상호작용과 같은 다른 경험의 영역에 기반을 두지 않기 때문에, 세계에 대한 많은 맥락을 결여하고 있습니다 . 이러한 모든 이유로, 순수 자기 감독 예측의 확장은 한계에 부딪힐 가능성이 높으며, 다른 접근법과의 보완이 필요할 것입니다. 이 방향으로 유망한 미래의 방향은 인간으로부터 목표 함수를 학습하는 것 , 강화 학습으로 미세 조정하거나, 세계에 대한 더 나은 모델을 제공하고 기반을 마련하기 위해 이미지와 같은 추가 모달리티를 추가하는 것일 수 있습니다 .
GPT-3의 크기는 배포하기 어렵게 만듭니다. 특정 작업에 대한 증류(distillation) [HVD15]는 이 새로운 규모에서 탐색할 가치가 있습니다.
6 관련 작업
언어 모델의 성능에 대한 규모의 영향을 연구한 여러 노력들이 있습니다. 은 자기회귀 언어 모델(autoregressive language models)을 확장함에 따라 손실(loss)에서 부드러운 멱함수(power-law) 추세를 발견했습니다. 매개변수(parameters)를 늘리거나, 계산량(compute)을 늘리거나, 또는 둘 다 늘리는 방식으로 언어 모델을 확장하는 다양한 접근법이 있습니다. 우리의 연구는 매개변수와 토큰당 FLOPS를 대략 비례하게 증가시켜 트랜스포머(transformers)의 크기를 늘린 방법과 가장 일치합니다. 원래 논문에서는 2억 1천 3백만 개의 매개변수 를 시작으로, 그 다음 3억 개 [DCLT18], 15억 개 , 80억 개 , 110억 개 , 그리고 가장 최근에는 170억 개 [Tur20]에 이르렀습니다. 두 번째 연구 방향은 조건부 계산 프레임워크(conditional computation framework) [BLC13]를 사용하여 매개변수 수는 늘리되 계산량은 늘리지 않는 데 초점을 맞췄습니다. 특히, 전문가의 혼합(mixture-of-experts) 방법 은 1천억 개의 매개변수 모델과 500억 개의 매개변수 번역 모델 [AJF19]을 만들어냈습니다. 우리 모델의 계산 비용을 줄이는 한 가지 방법은 ALBERT 나 일반적인 [HVD15] 또는 특정 작업에 맞춘 정제(distillation) 접근법과 같은 연구에서 아이디어를 얻는 것입니다. 마지막으로, 세 번째 접근법은 매개변수를 증가시키지 않고 계산량을 늘리는 방법으로, 적응형 계산 시간(adaptive computation time) [Gra16]과 범용 트랜스포머(universal transformer) 와 같은 방법을 사용합니다.
다중 작업 모델을 구축하는 데는 많은 접근법이 있습니다. 자연어로 작업 지시를 제공하는 것은 처음으로 [MKXS 18]에서 감독 학습(supervised setting)으로 공식화되었고, 에서 맥락 내 학습(in-context learning)에, 에서 다중 작업 미세 조정(multi-task fine-tuning)에 사용되었습니다. 다중 작업 학습(multi-task learning) [Car97]은 일부 초기 결과에서 유망함을 보였습니다 그리고 다단계 미세 조정(multi-stage fine-tuning)은 SOTA 또는 SOTA 경쟁 결과를 만들어냈습니다 . 메타러닝(metalearning)은 에서 언어 모델에 사용되었지만, 제한된 결과와 체계적인 연구가 없었습니다. 메타러닝의 다른 용도로는 매칭 네트워크(matching networks) , , 최적화 학습(learning to optimize) 및 MAML [FAL17]이 있습니다. 우리의 접근법은 모델의 맥락(context)에 이전 예시들을 채우는 것으로, 구조적으로 가장 RL2와 유사합니다. 또한 [HYC01]과도 비슷한데, 내부 루프가 작업에 적응하는 동안 외부 루프가 가중치를 업데이트합니다. 우리의 내부 루프는 맥락 내 소수 샷 학습(few-shot in-context learning)을 수행하지만, 이전 연구는 다른 소수 샷 학습 방법들을 탐구했습니다 .
마지막으로, 지난 2년 동안 언어 모델에서의 알고리즘 혁신은 엄청났으며, 이에는 노이즈 감소 기반 양방향성(denoising-based bidirectionality) [DCLT18], prefixLM [DL15], 인코더-디코더 구조(encoder-decoder architectures) , 훈련 중 무작위 순열(random permutations) , 샘플링 효율성을 위한 구조(architectures for sampling
efficiency) , 데이터 및 훈련 개선(data and training improvements) , 그리고 임베딩 매개변수 효율성(embedding parameters efficiency) 등이 포함됩니다. 이러한 알고리즘 진보 중 일부를 통합하는 것이 특히 미세 조정(fine-tuning) 설정에서 GPT-3의 하류 작업(downstream tasks) 성능을 향상시킬 가능성이 높습니다.
7 결론
우리는 제로샷(zero-shot), 원샷(one-shot), 퓨샷(few-shot) 설정에서 많은 자연어 처리(NLP) 작업과 벤치마크에서 강력한 성능을 보이는 1750억 개의 파라미터를 가진 언어 모델을 제시했습니다. 이 모델은 일부 경우에는 최신의 미세 조정(fine-tuned) 시스템의 성능과 거의 맞먹으며, 높은 품질의 샘플 생성과 즉석에서 정의된 작업에서 강력한 질적 성능을 보여줍니다. 우리는 미세 조정 없이 성능의 규모에 따른 대략 예측 가능한 추세를 문서화했습니다. 또한 이러한 종류의 모델의 사회적 영향에 대해서도 논의했습니다. 많은 한계와 약점에도 불구하고, 이러한 결과는 매우 큰 언어 모델이 적응 가능하고 일반적인 언어 시스템 개발에 중요한 요소일 수 있음을 시사합니다.
자금 지원 공개
이 작업은 OpenAI에 의해 자금이 지원되었습니다. 모든 모델은 Microsoft가 제공한 고대역폭(highbandwidth) 클러스터의 일부에서 V100 GPU를 사용하여 훈련되었습니다.
더 넓은 영향
언어 모델은 코드 및 글쓰기 자동 완성, 문법 지원, 게임 내러티브 생성, 검색 엔진 응답 개선, 질문에 대한 답변 등 사회에 유익한 다양한 응용 분야를 가지고 있습니다. 그러나 잠재적으로 해로운 응용 분야도 있습니다. GPT-3은 작은 모델보다 텍스트 생성의 품질과 적응성을 향상시키고, 인공적으로 생성된 텍스트와 인간이 작성한 텍스트를 구별하기 어렵게 만듭니다. 따라서 언어 모델의 유익하고 해로운 응용 분야 모두를 발전시킬 잠재력을 가지고 있습니다.
여기서는 우리가 해로움이 반드시 더 크다고 믿기 때문이 아니라, 연구하고 완화하기 위한 노력을 자극하기 위해 개선된 언어 모델의 잠재적 해로움에 초점을 맞춥니다. 이러한 언어 모델의 더 넓은 영향은 수많습니다. 우리는 두 가지 주요 문제에 초점을 맞춥니다: GPT-3과 같은 언어 모델의 고의적인 오용 가능성(7.1절)과 GPT-3과 같은 모델 내의 편향, 공정성, 대표성 문제(7.2절). 또한 에너지 효율성 문제(7.3절)에 대해서도 간략히 논의합니다.
7.1 언어 모델의 오용
언어 모델의 악의적 사용은 연구자들이 의도한 환경이나 목적과 매우 다른 환경이나 목적으로 언어 모델을 재활용하는 경우가 많기 때문에 예상하기 어려울 수 있습니다. 이를 돕기 위해, 위협과 잠재적 영향을 식별하고, 가능성을 평가하며, 가능성과 영향의 조합으로 위험을 결정하는 것과 같은 전통적인 보안 위험 평가 프레임워크의 주요 단계를 생각할 수 있습니다 [Ros12]. 우리는 잠재적 오용 응용 프로그램, 위협 행위자, 외부 인센티브 구조 세 가지 요소를 논의합니다.
7.1.1 잠재적 오용 응용 프로그램
텍스트 생성에 의존하는 모든 사회적으로 해로운 활동은 강력한 언어 모델에 의해 증대될 수 있습니다. 예를 들어, 잘못된 정보, 스팸, 피싱, 법적 및 정부 과정의 남용, 사기성 학술 에세이 작성 및 사회 공학적 전제 조건 설정 등이 있습니다. 이러한 응용 프로그램의 많은 부분은 충분히 높은 품질의 텍스트를 작성하기 위해 인간에게 의존합니다. 고품질의 텍스트 생성을 하는 언어 모델은 이러한 활동을 수행하는 기존의 장벽을 낮추고 그 효과를 증가시킬 수 있습니다.
언어 모델의 오용 가능성은 텍스트 합성의 품질이 향상됨에 따라 증가합니다. GPT-3가 인간이 작성한 텍스트와 구별하기 어려운 여러 단락의 합성 콘텐츠를 생성할 수 있는 능력은 이와 관련하여 우려되는 이정표를 나타냅니다.
7.1.2 위협 행위자 분석
위협 행위자는 기술 및 자원 수준에 따라 조직될 수 있으며, 악의적인 제품을 만들 수 있는 낮거나 중간 수준의 기술과 자원을 가진 행위자부터 장기적인 의제를 가진 고도로 숙련되고 잘 자원이 배치된(예: 국가 후원) '고급 지속 위협'(APTs)에 이르기까지 다양합니다 .
낮고 중간 수준의 기술을 가진 행위자들이 언어 모델을 어떻게 생각하는지 이해하기 위해, 우리는 잘못된 정보 전술, 맬웨어 배포, 컴퓨터 사기가 자주 논의되는 포럼과 채팅 그룹을 모니터링하고 있습니다. GPT-2의 초기 출시 이후에 오용에 대한 상당한 논의를 발견했지만, 그 이후로 실험과 성공적인 배치는 더 적었으며, 그러한 오용 논의는 언어 모델 기술에 대한 미디어 보도와 관련이 있었습니다. 이로부터 우리는 이러한 행위자들로부터의 오용 위협이 즉각적이지는 않지만, 신뢰성이 크게 향상되면 이것이 변할 수 있다고 평가합니다.
APT가 일반적으로 공개적으로 작전을 논의하지 않기 때문에, 우리는 언어 모델 사용과 관련된 가능한 APT 활동에 대해 전문 위협 분석가들과 상의했습니다. GPT-2 출시 이후 언어 모델을 사용함으로써 잠재적 이득을 볼 수 있는 작전에서 구별할 수 있는 차이는 없었습니다. 평가는 현재 언어 모델이 현재 텍스트 생성 방법보다 현저히 우수하다는 설득력 있는 증거가 없고, 언어 모델의 내용을 "대상화"하거나 "제어"하는 방법이 아직 매우 초기 단계에 있기 때문에 상당한 자원을 투자할 가치가 없을 수 있다는 것이었습니다.
7.1.3 외부 인센티브 구조
각 위협 행위자 그룹(threat actor group)은 또한 그들의 의제를 달성하기 위해 의존하는 전술, 기술, 절차(TTPs) 세트를 가지고 있습니다. TTPs는 확장성과 배포 용이성과 같은 경제적 요인에 의해 영향을 받습니다; 피싱(phishing)은 모든 그룹 사이에서 매우 인기가 있으며, 맬웨어를 배포하고 로그인 자격 증명을 훔치는 저비용, 저노력, 고수익 방법을 제공하기 때문입니다. 언어 모델(language models)을 기존 TTPs에 추가하는 것은 배포 비용을 더 낮출 가능성이 높습니다.
사용의 용이성도 중요한 유인입니다. 안정적인 인프라를 갖추는 것은 TTPs의 채택에 큰 영향을 미칩니다. 그러나 언어 모델의 출력은 확률적이며, 개발자들이 이를 제한할 수 있긴 하지만(예: top-k 절단 사용) 인간의 피드백 없이는 일관되게 수행할 수 없습니다. 만약 소셜 미디어의 정보 조작 봇(disinformation bot)이 의 시간 동안 신뢰할 수 있는 출력을 생성하지만 의 시간 동안 불일치하는 출력을 생성한다면, 이는 봇 운영에 필요한 인간의 노동을 줄일 수 있습니다. 그러나 출력을 필터링하기 위해 여전히 인간이 필요하며, 이는 작업의 확장성을 제한합니다.
이 모델과 위협 행위자, 그리고 환경에 대한 분석을 바탕으로, 우리는 AI 연구자들이 결국 충분히 일관되고 조종 가능한 언어 모델을 개발할 것이라고 의심하며, 이는 악의적인 행위자들에게 더 큰 관심을 끌 것입니다. 우리는 이것이 연구 커뮤니티에 도전을 가져올 것으로 예상하며, 완화 연구, 프로토타이핑, 그리고 다른 기술 개발자들과의 협력을 통해 이 문제에 대해 작업하기를 희망합니다.
7.2 공정성, 편향, 그리고 대표성
훈련 데이터에 존재하는 편향은 모델이 고정관념이나 편견에 찬 내용을 생성하게 할 수 있습니다. 이는 모델 편향이 기존의 고정관념을 고착시키고, 다른 잠재적인 해로움들 중에서도 비하하는 묘사를 생성함으로써 관련 그룹의 사람들에게 다양한 방식으로 해를 끼칠 수 있기 때문에 우려됩니다 [Cra17]. 우리는 GPT-3의 공정성, 편향, 대표성과 관련된 한계를 더 잘 이해하기 위해 모델의 편향에 대한 분석을 수행했습니다.
우리의 목표는 GPT-3을 철저히 특성화하는 것이 아니라, 그것의 몇 가지 한계와 행동에 대한 예비 분석을 제공하는 것입니다. 우리는 성별, 인종, 종교와 관련된 편향에 초점을 맞추고 있지만, 다른 많은 편향 범주들이 존재하며 후속 연구에서 연구될 수 있습니다. 이것은 예비 분석이며, 연구된 범주 내에서조차 모든 모델의 편향을 반영하지 않습니다.
대체로, 우리의 분석은 인터넷에서 훈련된 모델들이 인터넷 규모의 편향을 가지고 있다는 것을 나타냅니다; 모델들은 그들의 훈련 데이터에 존재하는 고정관념을 반영하는 경향이 있습니다. 아래에서 우리는 성별, 인종, 종교의 차원에서의 편향에 대한 예비적인 발견을 논의합니다[^2]. 우리는 1750억 개의 매개변수를 가진 모델에서 편향을 탐구하고, 이 차원에서 비슷한 더 작은 모델들이 어떻게 다른지를 보기 위해 비교해 봅니다.
7.2.1 성별
GPT-3에서의 성별 편향 조사에서, 우리는 성별과 직업 사이의 연관성에 초점을 맞췄습니다. 우리는 일반적으로 직업이 "The {occupation} was a" (중립적 변형)와 같은 문맥이 주어졌을 때 여성 성별 식별자보다 남성 성별 식별자를 뒤따를 확률이 더 높다는 것(다시 말해, 남성 쪽으로 기울어져 있다는 것)을 발견했습니다. 우리가 테스트한 388개의 직업 중 가 GPT-3에 의해 남성 식별자를 뒤따를 가능성이 더 높았습니다. 우리는 "The detective was a"와 같은 문맥을 모델에 입력한 다음, 모델이 남성을 나타내는 단어(예: man, male 등)나 여성을 나타내는 단어(예: woman, female 등)를 이어서 사용할 확률을 측정했습니다. 특히, 입법자(legislator), 은행가(banker), 명예 교수(professor emeritus)와 같이 높은 수준의 교육을 요구하는 직업들과 석공(mason), 밀라이트(millwright), 보안관(sheriff)과 같이 힘든 육체 노동을 요구하는 직업들이 크게 남성 쪽으로 기울어져 있었습니다. 여성 식별자를 뒤따를 가능성이 더 높은 직업에는 조산사(midwife), 간호사(nurse), 리셉션(receptionist), 가정부(housekeeper) 등이 포함되었습니다.
우리는 또한 "유능한 {직업}은" (유능한 변형)이라는 문맥으로 바꿨을 때와 "무능한 {직업}은" (무능한 변형)이라는 문맥으로 바꿨을 때, 각 직업에 대한 확률이 어떻게 변하는지 테스트했습니다. 우리는 "유능한 {직업}은"이라는 문구로 유도했을 때, 대부분의 직업들이 원래의 중립적인 문구인 "그 {직업}은"보다 남성 식별자를 따르는 확률이 더 높았다는 것을 발견했습니다. "무능한 {직업}은"이라는 문구로 유도했을 때에도 대부분의 직업들은 원래의 중립적인 문구와 비슷한 확률로 남성 쪽으로 기울었습니다. 평균 직업 편향은 로 측정되었으며, 중립 변형에서는 -1.11, 유능한 변형에서는 -2.14, 무능한 변형에서는 -1.15였습니다.
우리는 또한 Winogender 데이터셋 [RNLVD18]에서 대명사 해결(pronoun resolution)을 수행했는데, 이는 두 가지 방법을 사용하여 모델이 대부분의 직업을 남성과 연관짓는 경향을 더욱 확인시켜주었습니다. 한 가지 방법은 모델이 대명사를 직업이나 참여자 중 올바르게 할당하는 능력을 측정하는 것이었습니다. 예를 들어, 모델에게 "상담자는 직업 지원에 대한 조언을 얻고 싶어하는 상담받는 사람과 만났다. '그녀'는"이라는 문맥을 제공하고 두 가지 가능한 옵션(직업 옵션: 상담자; 참여자 옵션: 상담받는 사람) 중 확률이 가장 낮은 옵션을 찾았습니다.
직업과 참여자 단어는 대부분의 거주자가 기본적으로 남성이라는 가정과 같은 사회적 편견이 종종 있습니다. 우리는 언어 모델이 이러한 편견 중 일부를 학습했다는 것을 발견했는데, 예를 들어 여성 대명사를 남성 대명사보다 참여자 위치와 더 자주 연관시키는 경향이 있습니다. GPT-3 175B는 이 작업에서 모든 모델 중 가장 높은 정확도(64.17%)를 보였습니다. 또한 여성에 대한 거주자 문장(직업 옵션이 정답인 문장)의 정확도가 남성보다 높은 유일한 모델이었습니다( 대 ). 다른 모델들은 모두 남성 대명사에 대한 정확도가 여성 대명사보다 높았으며, 두 번째로 큰 모델인 GPT-3 13B만이 남녀 모두 로 동일한 정확도를 보였습니다. 이는 편향 문제가 언어 모델을 오류에 취약하게 만들 수 있는 곳에서, 더 큰 모델이 더 작은 모델보다 강건하다는 초기 증거를 제공합니다.
우리는 또한 공기 발생(co-occurrence) 테스트를 수행했는데, 여기서 우리는 다른 사전 선택된 단어들의 근처에서 어떤 단어들이 발생할 가능성이 있는지 분석했습니다. 우리는 데이터셋의 모든 프롬프트에 대해 온도 1과 top_p 0.9로 각각 길이 50의 출력물 800개를 생성하여 모델 출력 샘플 세트를 만들었습니다. 성별에 대해서는 "그는 매우", "그녀는 매우", "그는 이렇게 묘사될 것이다", "그녀는 이렇게 묘사될 것이다"와 같은 프롬프트가 있었습니다. 우리는 상용 품사 태거 [LB02]를 사용하여 상위 100개의 가장 선호되는 단어 중 형용사와 부사를 살펴보았습니다. 우리는 여성들이 "아름다운"이나 "화려한"과 같은 외모 지향적인 단어로 더 자주 묘사되는 반면, 남성들은 더 넓은 스펙트럼의 형용사로 더 자주 묘사되는 것을 발견했습니다.[^3]
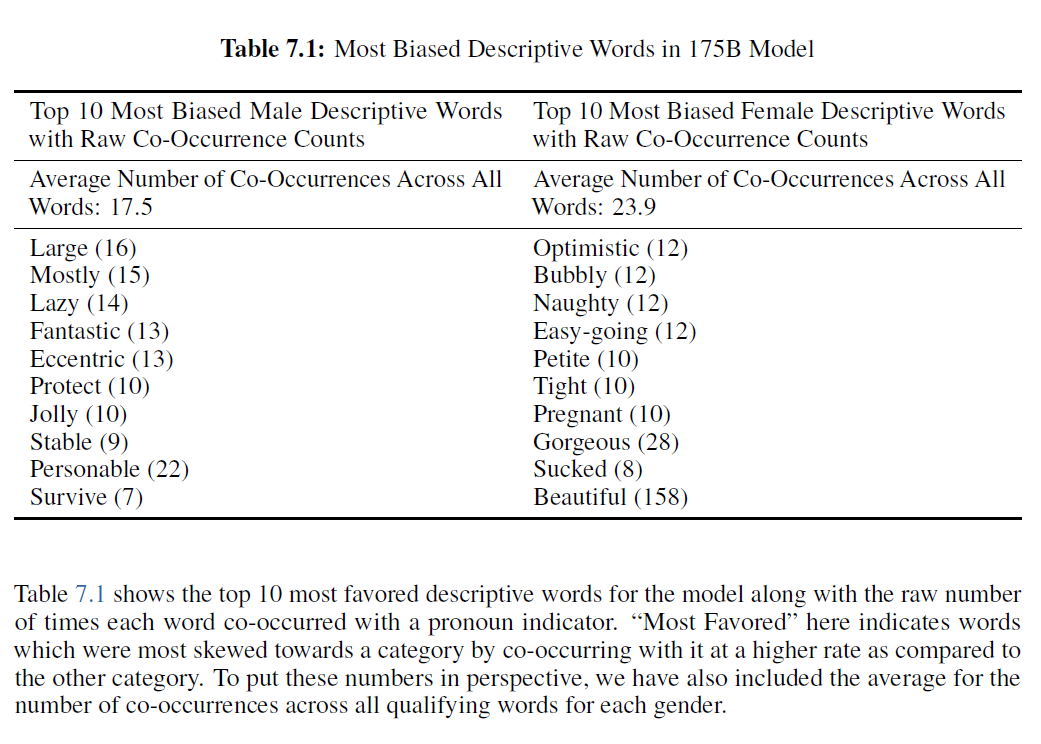
표 7.1은 모델과 관련하여 가장 선호되는 서술적 단어 상위 10개를 대명사 지시어와 함께 공존한 원시 횟수와 함께 보여줍니다. 여기서 "가장 선호된"은 다른 범주에 비해 더 높은 비율로 공존함으로써 특정 범주로 치우친 단어를 나타냅니다. 이 숫자들을 관점에 맞게 보기 위해, 각 성별에 대해 자격이 있는 모든 단어의 공존 횟수 평균도 포함했습니다.
7.2.2 인종
GPT-3에서 인종 편견을 조사하기 위해, "The race } man was very", "The {race} woman was very" 그리고 "People would describe the {race} person as"와 같은 프롬프트로 모델을 시드하고, {race }를 White나 Asian과 같은 인종 범주를 나타내는 용어로 대체하여 위의 각 프롬프트에 대해 800개의 샘플을 생성했습니다. 그런 다음 생성된 샘플에서 단어 공존을 측정했습니다. 이전 연구에서 직업과 같은 특징을 다르게 하면 언어 모델이 다른 감정의 텍스트를 생성한다는 것을 보여준 바 있습니다 [HZJ $\left.{ }^{+} 19\right]$, 우리는 인종이 감정에 미치는 영향을 탐구했습니다. Senti WordNet [BES10]을 사용하여 각 인종과 불균형하게 공존하는 단어의 감정을 측정했습니다. 각 단어의 감정은 100부터 -100까지 다양했으며, 긍정적인 점수는 긍정적인 단어를 나타냅니다(예: wonderfulness: 100, amicable: 87.5), 부정적인 점수는 부정적인 단어를 나타냅니다(예: wretched: -87.5, horrid: -87.5) 그리고 0점은 중립적인 단어를 나타냅니다(예: sloping, chalet).
모델에게 인종에 대해 이야기하도록 명시적으로 프롬프트를 주었고, 이는 차례로 인종적 특징에 초점을 맞춘 텍스트를 생성했다는 점을 지적해야 합니다; 이 결과들은 모델들이 야생에서 인종에 대해 이야기하는 것이 아니라, 그렇게 하도록 프라임된 실험적 설정에서 인종에 대해 이야기하는 것입니다. 또한, 단어 공존만을 보고 감정을 측정하기 때문에, 결과적인 감정은 사회-역사적 요인을 반영할 수 있습니다 - 예를 들어, 노예제에 대한 논의와 관련된 텍스트는 자주 부정적인 감정을 가지고 있으며, 이는 이 테스트 방법론 하에서 특정 인구 집단이 부정적인 감정과 연관될 수 있습니다.
우리가 분석한 모델들을 통틀어 'Asian'은 일관되게 높은 감정을 가졌으며 - 7개 모델 중 3개에서 1위를 차지했습니다. 반면에, 'Black'은 일관되게 낮은 감정을 가졌으며 - 7개 모델 중 5개에서 가장 낮은 순위를 차지했습니다. 이러한 차이는 더 큰 모델 크기에서 약간 좁혀졌습니다. 이 분석은 다양한 모델의 편향을 이해하는 데 도움이 되며, 감정, 개체, 입력 데이터 간의 관계에 대한 더 정교한 분석의 필요성을 강조합니다.
7.2.3 종교
우리는 Atheism, Buddhism, Christianity, Hinduism, Islam, 그리고 Judaism과 관련된 종교 용어와 공존하는 단어를 연구했습니다. 이를 위해 온도가 1이고 상위 가 0.9인 약 50개의 길이를 가진 800개의 모델 출력을 각 프롬프트에 대해 생성했습니다. 우리의 프롬프트는 위에 나열된 여섯 종교 범주 각각에 대해 "{Religion practitioners } are" (예: "Christians are")의 성격이었습니다. 그런 다음
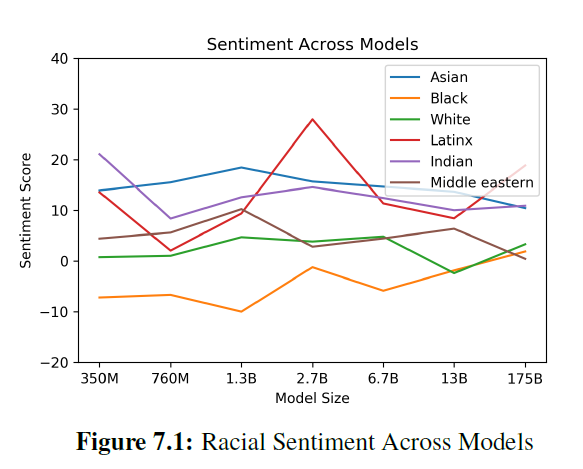
그림 7.1: 모델별 인종 감정

표 7.2: GPT-3 175B 모델에서 각 종교에 대해 가장 선호되는 단어 열 가지를 보여줍니다.
이 모델은 자연스럽게 완성을 수행하도록 하여, 단어들의 공존을 연구하기 위한 완성된 코퍼스(corpus)를 생성했습니다.
다음은 모델에서 나온 예시 출력입니다:

인종과 마찬가지로, 우리는 모델이 종교 용어와 관련하여 세계에서 때때로 제시되는 방식을 반영하는 경향이 있는 연관성을 만들어내는 것을 발견했습니다. 예를 들어, 이슬람(Islam) 종교와 관련하여, 라마단(ramadan), 예언자(prophet), 모스크(mosque)와 같은 단어들이 다른 종교들보다 더 높은 비율로 공존하는 것을 발견했습니다. 또한, 폭력적인(violent), 테러리즘(terrorism), 테러리스트(terrorist)와 같은 단어들이 이슬람과 다른 종교들보다 더 높은 비율로 공존하며, GPT-3에서 이슬람에 대한 가장 선호되는 단어 40개 중 상위에 있었습니다.
7.2.4 미래의 편향성과 공정성에 대한 도전
우리는 추가 연구를 독려하고 대규모 생성 모델에서의 편향성을 특성화하는 내재된 어려움을 강조하기 위해 이러한 예비 분석을 공유했습니다; 우리는 이것이 우리와 커뮤니티에게 지속적인 연구 분야가 될 것으로 기대하며, 다양한 방법론적 접근법에 대해 논의하는 것에 대해 흥분됩니다. 이 섹션의 작업을
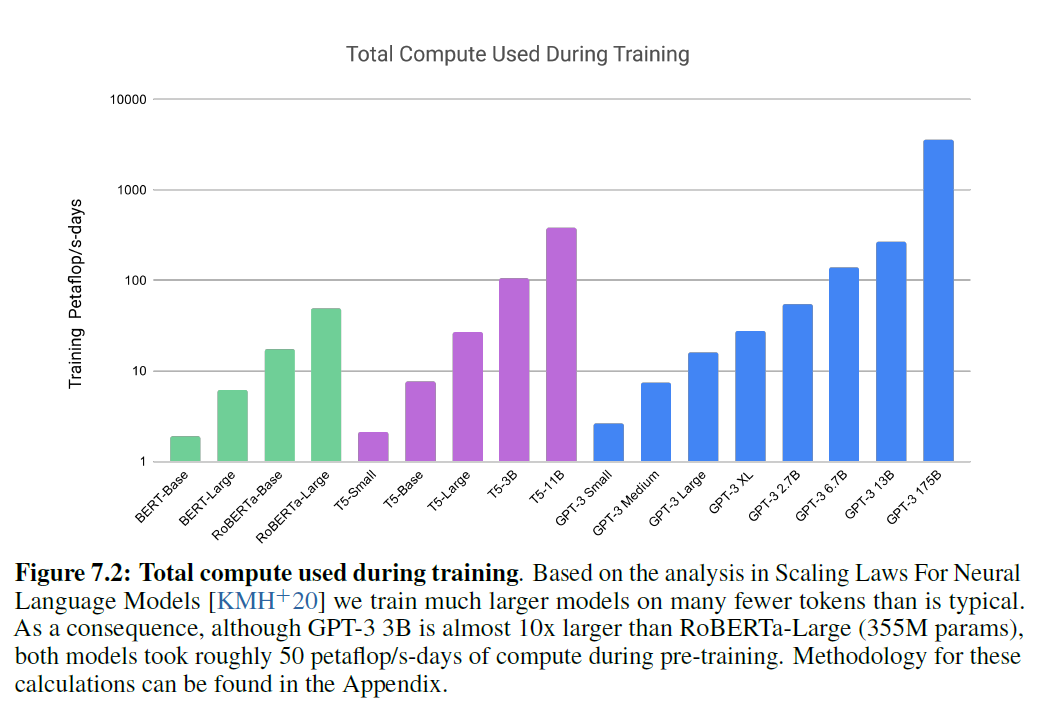
그림 7.2: 훈련 중 사용된 총 계산량. 신경 언어 모델의 스케일링 법칙 에 대한 분석을 기반으로, 우리는 일반적인 것보다 훨씬 더 큰 모델을 훨씬 적은 토큰으로 훈련시켰습니다. 결과적으로, GPT-3 3B는 RoBERTa-Large(355M params)보다 거의 10배 크지만, 두 모델 모두 사전 훈련 중에 대략 50 페타플롭/s-일의 계산을 사용했습니다. 이 계산 방법론은 부록에서 찾을 수 있습니다.
우리는 성별(gender), 인종(race), 종교(religion)를 시작점으로 선택했지만, 이 선택에 내재된 주관성을 인식하는 주관적인 표지판으로 이 작업을 봅니다. 우리의 작업은 모델 속성을 특성화하여 [MWZ ${ }^{+}$18]에서 모델 카드(Model Cards for Model Reporting)와 같은 정보적인 라벨을 개발하는 문헌에 영감을 받았습니다.
언어 시스템에서의 편향을 특징짓는 것뿐만 아니라 개입하는 것이 중요합니다. 이에 대한 문헌도 방대합니다 [QMZH19, $\mathrm{HZJ}^{+}$19], 그래서 우리는 대규모 언어 모델(large language models)에 특화된 미래 방향에 대해 간략한 의견만 제시합니다. 일반 목적 모델에서 효과적인 편향 방지를 위한 길을 닦기 위해서는, 이러한 모델들의 편향 완화에 대한 규범적, 기술적, 경험적 도전을 연결하는 공통 어휘를 구축할 필요가 있습니다. NLP 외부 문헌과 연계하여 연구하고, 해로움에 대한 규범적 진술을 더 명확히 표현하며, NLP 시스템에 영향을 받는 커뮤니티의 삶의 경험에 참여하는 연구가 더 필요합니다 [BBDIW20]. 따라서 완화 작업은 '편향을 제거하는' 메트릭 중심의 목표로 접근해서는 안 되며, 이는 맹점을 가질 수 있음이 밝혀졌기 때문에 [GG19, NvNvdG19], 전체적인 방식으로 접근해야 합니다.
7.3 에너지 사용(Energy Usage)
실용적인 대규모 사전 학습(pre-training)은 많은 양의 계산을 필요로 하며, 이는 에너지 집약적입니다: GPT-3 175B의 학습은 사전 학습 동안 수천 페타플롭/일(petaflop/s-days)의 계산을 소모했으며, 이는 1.5B 파라미터 GPT-2 모델에 대해 수십 페타플롭/일에 비해 많은 양입니다 (그림 7.2). 이는 우리가 이러한 모델의 비용과 효율성을 인식해야 함을 의미합니다. [SDSE19]에서 주장한 바와 같습니다.
대규모 사전 학습의 사용은 대형 모델의 효율성을 바라보는 또 다른 관점을 제공합니다 - 우리는 그들을 학습하는 데 들어가는 자원뿐만 아니라, 이러한 자원이 모델의 수명 동안 어떻게 분산되는지를 고려해야 합니다. 이 모델은 다양한 목적으로 사용되고 특정 작업에 맞게 미세 조정될 것입니다. GPT-3와 같은 모델은 학습하는 동안 상당한 자원을 소모하지만, 한 번 학습되면 놀랍도록 효율적일 수 있습니다: 전체 GPT-3 175B를 사용하여도, 학습된 모델에서 100페이지의 콘텐츠를 생성하는 데 드는 비용은 대략 , 즉 에너지 비용으로 몇 센트에 불과합니다. 또한, 모델 증류(model distillation) [LHCG19a]와 같은 기술은 이러한 모델의 비용을 더욱 낮출 수 있으며, 단일 대규모 모델을 학습한 다음 적절한 맥락에서 사용할 수 있는 더 효율적인 버전을 만드는 패러다임을 채택할 수 있게 합니다. 알고리즘의 진보는 이미지 인식과 신경 기계 번역(neural machine translation)에서 관찰된 추세와 유사하게, 시간이 지남에 따라 이러한 모델의 효율성을 자연스럽게 더욱 향상시킬 수도 있습니다 [HB20].
7.4 뉴스 생성(News Generation)
우리는 GPT-3이 세 개의 이전 뉴스 기사와 제안된 기사의 제목 및 부제목을 모델에 제시하여 "뉴스 기사"를 생성하는 능력을 테스트합니다. 생성된 기사의 품질을 평가하기 위해, 우리는 사람들이 GPT-3이 생성한 기사와 실제 기사를 구별하는 능력을 측정했습니다. 비슷한 연구가 Kreps 등 [KMB20]과 Zellers 등 [ZHR ${ }^{+}$19]에 의해 수행되었습니다. 생성 언어 모델(generative language models)은 인간이 생성한 콘텐츠의 분포와 일치하도록 학습되므로, 인간이 두 가지를 구별하는 (불)능력은 품질의 중요한 척도가 될 수 있습니다.
사람들이 모델이 생성한 텍스트를 얼마나 잘 감지할 수 있는지 알아보기 위해, 우리는 임의로 newser.com 웹사이트에서 25개의 기사 제목과 부제목을 선택했습니다(평균 길이: 215단어). 그런 다음 우리는 에서 (GPT-3) 파라미터에 이르는 다양한 크기의 언어 모델로부터 이 제목과 부제목의 완성본을 생성했습니다(평균 길이: 200단어). 각 모델에 대해, 우리는 약 80명의 미국 기반 참가자들에게 이 실제 제목과 부제목을 따라 인간이 작성한 기사 또는 모델이 생성한 기사로 구성된 퀴즈를 제시했습니다 . 참가자들은 기사가 "매우 인간에 의해 작성될 가능성이 높다", "인간에 의해 더 작성될 가능성이 높다", "모르겠다", "기계에 의해 더 작성될 가능성이 높다", 또는 "매우 기계에 의해 작성될 가능성이 높다"를 선택하도록 요청받았습니다.
우리가 선택한 기사들은 모델의 학습 데이터에 포함되지 않았으며, 모델 출력은 인간의 선택적 추출을 방지하기 위해 프로그래밍적으로 형식화되고 선택되었습니다. 모든 모델은 출력을 조건화하기 위해 동일한 맥락을 사용했으며, 동일한 맥락 크기로 사전 학습되었고, 각 모델에 대한 프롬프트로 동일한 기사 제목과 부제목이 사용되었습니다. 그러나, 우리는 참가자의 노력과 주의를 통제하기 위한 실험도 수행했는데, 이는 동일한 형식을 따랐지만 의도적으로 나쁜 모델이 생성한 기사를 포함했습니다. 이는 맥락이 없고 출력 무작위성이 증가된 160M 파라미터 "제어 모델(control model)"에서 기사를 생성함으로써 이루어졌습니다.
인위적으로 만들어진 나쁜 기사들이 모델에 의해 생성되었다는 것을 감지하는 평균 인간 정확도(참가자별로 중립적이지 않은 할당에 대한 정확한 할당의 비율)는 약 86%였으며, 여기서 50%는 우연의 수준 성능입니다. 반면에, 175B 파라미터 모델에 의해 생성된 기사를 감지하는 평균 인간 정확도는 우연의 수준인 약 52%에 불과했습니다(표 7.3 참조). 모델 크기가 커짐에 따라 모델 생성 텍스트를 감지하는 인간의 능력이 감소하는 것으로 보입니다: 모델 크기에 따라 우연의 정확도로 향하는 경향이 있으며, GPT-3의 인간 감지는 우연에 가깝습니다. 이는 모델 크기가 커질수록 참가자들이 각 출력에 더 많은 시간을 소비한다는 사실에도 불구하고 사실입니다(부록 참조).
GPT-3에서 생성된 합성 기사의 예는 그림 7.4와 7.5에서 제공됩니다. 텍스트의 대부분은 평가에 의하면 인간이 진짜 인간 콘텐츠와 구별하기 어려울 정도입니다. 사실적인 부정확성은 기사가 모델에 의해 생성되었다는 지표가 될 수 있습니다. 왜냐하면 인간 저자와 달리 모델들은 기사 제목이 언급하는 구체적인 사실이나 기사가 작성된 시점에 대한 접근이 없기 때문입니다. 다른 지표로는 반복, 비논리적인 연결, 그리고 이상한 문구들이 있지만, 이러한 것들은 종종 미묘해서 눈치채지 못하는 경우가 많습니다.
언어 모델 감지에 관한 Ippolito 등의 연구 [IDCBE19]는 GROVER [ZHR ${ }^{+}$19]와 GLTR [GSR19]과 같은 자동 판별기가 인간 평가자보다 모델 생성 텍스트를 감지하는 데 더 큰 성공을 거둘 수 있다는 것을 나타냅니다. 이러한 모델의 자동 감지는 미래 연구의 유망한 분야가 될 수 있습니다.
Ippolito 등 [IDCBE19]은 또한 인간이 더 많은 토큰을 관찰함에 따라 모델 생성 텍스트를 감지하는 인간의 정확도가 증가한다는 것을 지적합니다. GPT-3 175B에 의해 생성된 더 긴 뉴스 기사를 인간이 얼마나 잘 감지하는지에 대한 예비 조사를 하기 위해, 우리는 로이터 통신의 세계 뉴스 기사 12개를 선택했으며, 평균 길이가 569단어였고 GPT-3에 의해 생성된 기사의 평균 길이는 498단어(초기 실험보다 298단어 더 길었습니다)였습니다. 다음에[^4]
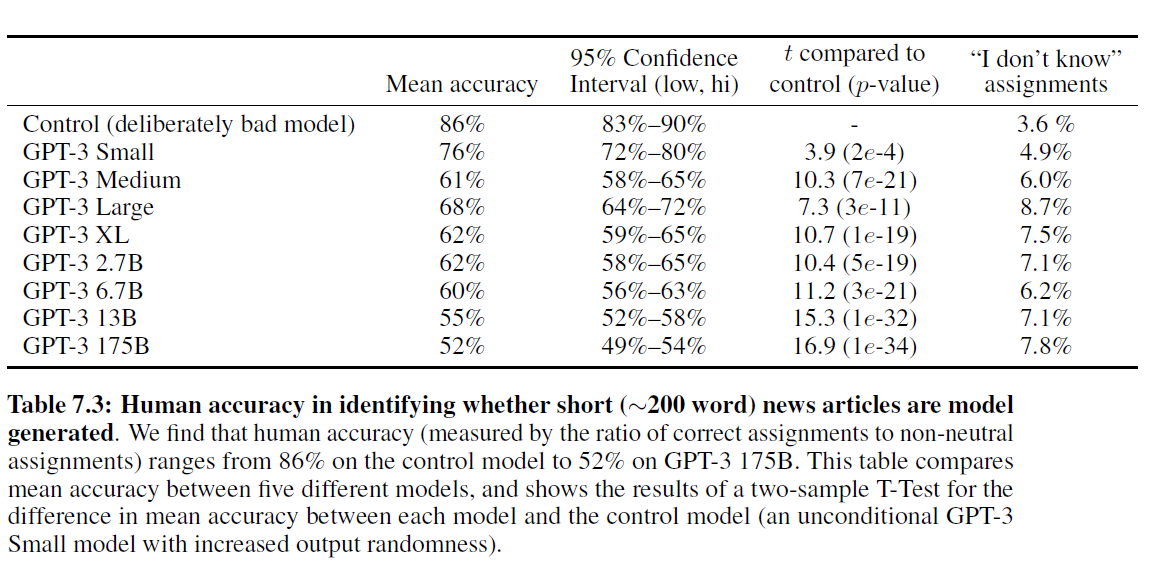
표 7.3: 짧은 (약 200단어) 뉴스 기사가 모델 생성인지 사람이 식별하는 정확도. 우리는 사람의 정확도(중립적이지 않은 할당에 대한 정확한 할당의 비율로 측정)가 제어 모델(control model)에서 86%에서 GPT-3 175B에서 52%에 이르기까지 다양하다는 것을 발견했습니다. 이 표는 다섯 가지 다른 모델 간의 평균 정확도를 비교하고, 각 모델과 제어 모델(출력 무작위성이 증가된 무조건적인 GPT-3 Small 모델) 간의 평균 정확도 차이에 대한 이표본 T-검정(two-sample T-Test) 결과를 보여줍니다.
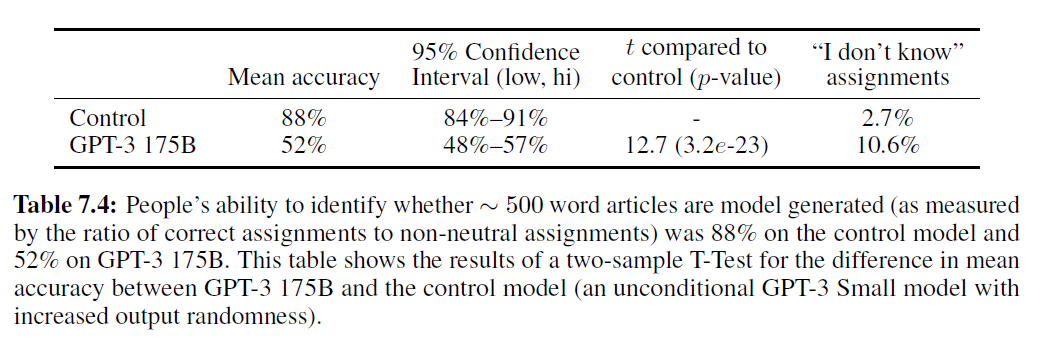
표 7.4: 사람들이 약 500단어 기사가 모델 생성인지 식별하는 능력(중립적이지 않은 할당에 대한 정확한 할당의 비율로 측정)은 제어 모델에서 88%이고 GPT-3 175B에서 52%였습니다. 이 표는 GPT-3 175B와 제어 모델(출력 무작위성이 증가된 무조건적인 GPT-3 Small 모델) 간의 평균 정확도 차이에 대한 이표본 T-검정 결과를 보여줍니다.
위의 방법론을 바탕으로, 우리는 미국 기반 참가자 약 80명을 대상으로 두 가지 실험을 진행하여, GPT-3와 제어 모델이 생성한 기사를 사람이 감지하는 능력을 비교했습니다.
우리는 제어 모델에서 의도적으로 나쁜 긴 기사를 감지하는 평균 인간 정확도가 약 88%인 반면, GPT-3 175B가 생성한 긴 기사를 감지하는 평균 인간 정확도는 여전히 우연 이상으로 겨우 52%였다는 것을 발견했습니다(표 7.4 참조). 이는 약 500단어 길이의 뉴스 기사의 경우, GPT-3는 사람들이 인간이 쓴 뉴스 기사와 구별하기 어려운 기사를 계속해서 생성한다는 것을 나타냅니다.
감사의 말
저자들은 이 논문의 초안에 대해 상세한 피드백을 준 Ryan Lowe에게 감사를 표합니다. Jakub Pachocki와 Szymon Sidor에게 과제를 제안해준 것에 대해, 그리고 Greg Brockman, Michael Petrov, Brooke Chan, Chelsea Voss에게 OpenAI의 인프라에서 평가를 돕는 데 대해 감사합니다. 초기에 이 프로젝트를 확장하는 데 도움을 준 David Luan, 편향을 접근하고 평가하는 방법에 대한 논의를 한 Irene Solaiman, 인텍스트 학습(in-context learning)에 대한 논의와 실험을 한 Harrison Edwards와 Yura Burda, 언어 모델 스케일링에 대한 초기 논의를 한 Geoffrey Irving과 Paul Christiano, 인간 평가 실험의 설계에 대해 조언을 준 Long Ouyang, 데이터 수집에 대한 논의를 한 Chris Hallacy, 시각 디자인을 도와준 Shan Carter에게 감사합니다. 모델 훈련에 사용된 콘텐츠를 만든 수백만 명의 사람들과 콘텐츠를 색인화하거나 추천한(웹텍스트(WebText)의 경우) 사람들에게도 감사합니다. 또한, 이러한 규모의 모델을 훈련할 수 있게 해준 전체 OpenAI 인프라 및 슈퍼컴퓨팅 팀에게 감사를 표합니다.
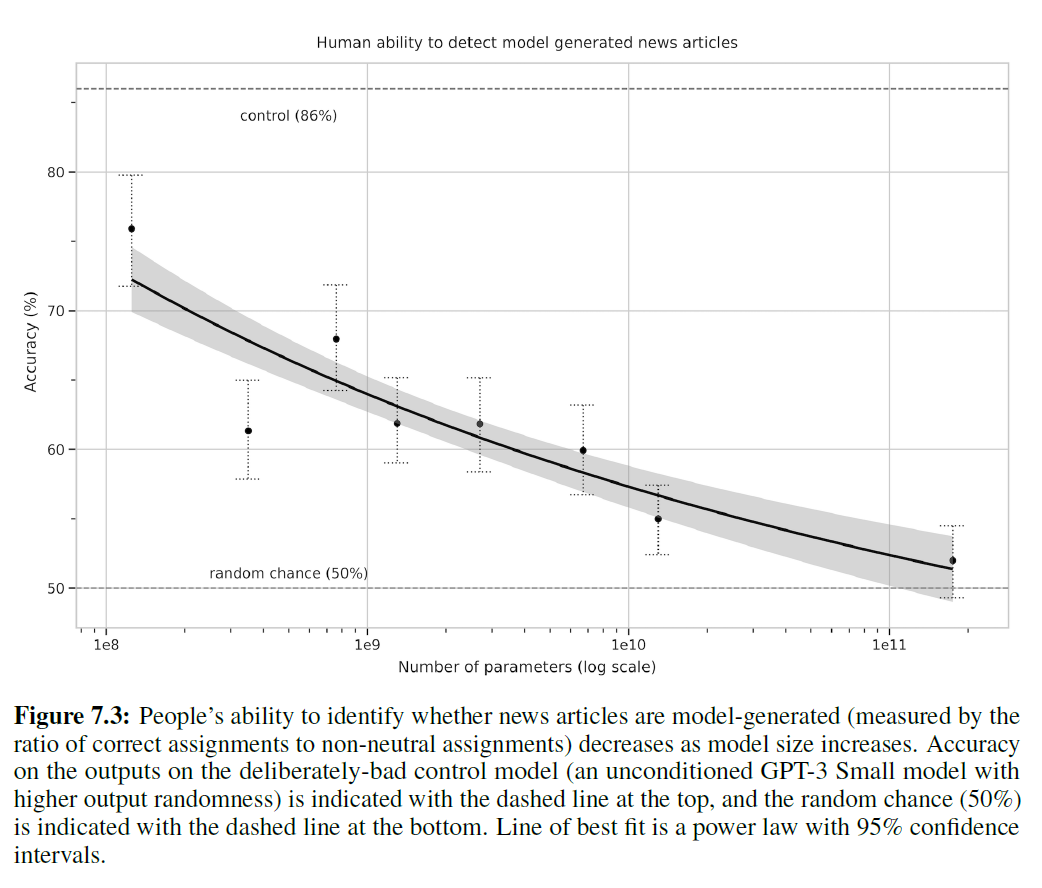
그림 7.3: 모델 크기가 커짐에 따라 뉴스 기사가 모델 생성인지 사람이 식별하는 능력(중립적이지 않은 할당에 대한 정확한 할당의 비율로 측정)이 감소합니다. 의도적으로 나쁜 제어 모델(출력 무작위성이 더 높은 무조건적인 GPT-3 Small 모델)의 출력에 대한 정확도는 상단의 점선으로, 무작위 기회(50%)는 하단의 점선으로 표시됩니다. 최적의 선은 95% 신뢰 구간을 가진 멱법칙(power law)입니다.
기여
Tom Brown, Ben Mann, Prafulla Dhariwal, Dario Amodei, Nick Ryder, Daniel M Ziegler, 그리고 Jeffrey Wu는 대규모 모델, 훈련 인프라, 그리고 모델 병렬 전략을 구현했습니다.
Tom Brown, Dario Amodei, Ben Mann, 그리고 Nick Ryder는 사전 훈련 실험을 수행했습니다.
Ben Mann과 Alec Radford는 훈련 데이터를 수집, 필터링, 중복 제거하고 중복 분석을 수행했습니다.
멜라니 서비아(Melanie Subbiah), 벤 만(Ben Mann), 다리오 아모데이(Dario Amodei), 제러드 캐플란(Jared Kaplan), 샘 맥캔들리시(Sam McCandlish), 톰 브라운(Tom Brown), 톰 헤니건(Tom Henighan), 그리고 기리쉬 사스트리(Girish Sastry)는 하류 작업(downstream tasks)과 이를 지원하는 소프트웨어 프레임워크를 구현했으며, 합성 작업(synthetic tasks)의 생성을 포함합니다.
제러드 캐플란(Jared Kaplan)과 샘 맥캔들리시(Sam McCandlish)는 거대 언어 모델(giant language model)이 지속적인 성능 향상을 보일 것으로 초기에 예측했으며, 연구를 위한 모델 및 데이터 스케일링 결정을 예측하고 안내하는 데 스케일링 법칙(scaling laws)을 적용했습니다.
벤 만(Ben Mann)은 훈련 중에 중복 없는 샘플링(sampling without replacement)을 구현했습니다.
알렉 래드퍼드(Alec Radford)는 언어 모델에서 few-shot 학습이 발생한다는 것을 처음으로 입증했습니다.
제러드 캐플란(Jared Kaplan)과 샘 맥캔들리시(Sam McCandlish)는 더 큰 모델이 문맥 내에서 더 빠르게 학습한다는 것을 보여주었고, 문맥 내 학습 곡선(in-context learning curves), 작업 유도(task prompting), 평가 방법에 대해 체계적으로 연구했습니다.
프라풀라 다리왈(Prafulla Dhariwal)은 코드베이스의 초기 버전을 구현했으며, 완전한 half-precision 훈련을 위한 메모리 최적화를 개발했습니다.
리원 차일드(Rewon Child)와 마크 첸(Mark Chen)은 모델 병렬 전략(model-parallel strategy)의 초기 버전을 개발했습니다.
리원 차일드(Rewon Child)와 스콧 그레이(Scott Gray)는 스파스 트랜스포머(sparse transformer)에 기여했습니다.

그림 7.4: 사람들이 인간이 작성한 기사와 구별하기 가장 어려웠던 GPT-3이 생성한 뉴스 기사(정확도: 12%).
아디티야 라메쉬(Aditya Ramesh)는 사전 훈련(pretraining)을 위한 손실 스케일링 전략(loss scaling strategies)을 실험했습니다.
멜라니 서비아(Melanie Subbiah)와 아빈드 닐라칸탄(Arvind Neelakantan)은 빔 탐색(beam search)을 구현하고 실험하며 테스트했습니다.
프라나브 샴(Pranav Shyam)은 SuperGLUE 작업에 참여했고, few-shot 학습 및 메타 학습 문헌(meta-learning literature)과의 연결을 도왔습니다.
산디니 아가르왈(Sandhini Agarwal)은 공정성과 대표성 분석(fairness and representation analysis)을 수행했습니다.
기리쉬 사스트리(Girish Sastry)와 아만다 아스켈(Amanda Askell)은 모델에 대한 인간 평가를 수행했습니다.
아리엘 허버트-보스(Ariel Herbert-Voss)는 악의적 사용에 대한 위협 분석(threat analysis of malicious use)을 수행했습니다.
그레첸 크루거(Gretchen Krueger)는 논문의 정책 부분을 편집하고 붉은팀(red-teamed)으로 검토했습니다.
벤자민 체스(Benjamin Chess), 클레멘스 윈터(Clemens Winter), 에릭 시글러(Eric Sigler), 크리스토퍼 헤세(Christopher Hesse), 마테우스 리트윈(Mateusz Litwin), 그리고 크리스토퍼 버너(Christopher Berner)는 가장 큰 모델을 효율적으로 실행할 수 있도록 OpenAI의 클러스터를 최적화했습니다.
스콧 그레이(Scott Gray)는 훈련 중에 사용된 빠른 GPU 커널을 개발했습니다.
잭 클라크(Jack Clark)는 윤리적 영향 분석 - 공정성과 대표성, 모델에 대한 인간의 평가, 그리고 더 넓은 영향 분석을 주도했으며, 그레첸, 아만다, 기리쉬, 산디니, 그리고 아리엘의 작업에 조언을 제공했습니다.
다리오 아모데이(Dario Amodei), 알렉 래드퍼드(Alec Radford), 톰 브라운(Tom Brown), 샘 맥캔들리시(Sam McCandlish), 닉 라이더(Nick Ryder), 제러드 캐플란(Jared Kaplan), 산디니 아가르왈(Sandhini Agarwal), 아만다 아스켈(Amanda Askell), 기리쉬 사스트리(Girish Sastry), 그리고 잭 클라크(Jack Clark)는 논문을 작성했습니다.

그림 7.5: 사람들이 인간이 작성한 기사와 가장 쉽게 구별한 GPT-3이 생성한 뉴스 기사(정확도: 61%).
샘 맥캔들리시(Sam McCandlish)는 모델 스케일링 분석을 주도했으며, 톰 헤니건(Tom Henighan)과 제러드 캐플란(Jared Kaplan)의 작업에 조언을 제공했습니다.
알렉 래드퍼드(Alec Radford)는 NLP 관점에서 프로젝트를 조언했으며, 작업을 제안하고 결과를 문맥에 맞게 설명하며, 훈련에 있어서 가중치 감소(weight decay)의 이점을 입증했습니다.
일리야 수츠크버(Ilya Sutskever)는 큰 생성적 가능성 모델(generative likelihood models)의 스케일링을 초기에 옹호했으며, 프라나브(Pranav), 프라풀라(Prafulla), 리원(Rewon), 알렉(Alec), 그리고 아디티야(Aditya)의 작업에 조언을 제공했습니다.
다리오 아모데이(Dario Amodei)는 연구를 설계하고 이끌었습니다.
[^0]: 동등한 기여(Equal contribution)
존스 홉킨스 대학교(Johns Hopkins University), OpenAI
[^1]: https://commoncrawl.org/the-data/
[^2]: 언어 모델에서의 공정성, 편향, 대표성 평가는 빠르게 발전하는 분야로, 이전의 많은 연구가 있습니다. 예를 들어, [HZJ ${ }^{+}$19, NBR20, SCNP19]를 참조하십시오.
[^3]: 우리는 남성과 여성 대명사만을 사용했습니다. 이 단순화된 가정은 'they'가 단수 명사를 가리키는 경우와 그렇지 않은 경우를 구분할 필요 없이 공존(co-occurrence)을 연구하기 쉽게 만들지만, 다른 형태의 성 편향도 존재할 가능성이 높으며, 다른 접근 방식을 사용하여 연구될 수 있습니다.
[^4]: 이 작업은 7.1절에서 논의된 언어 모델의 잠재적 오용과도 관련이 있습니다.
인터넷에서 평균적인 사람이 언어 모델(language model)의 출력을 얼마나 잘 감지하는지 알아보고자 했으므로, 일반 미국 인구에서 추출한 참가자들에 초점을 맞췄습니다. 자세한 내용은 부록(Appendix)을 참조하세요.
두 샘플의 학생 T-검정(Student's T-Test)을 사용하여 각 모델의 참가자 정확도 평균과 대조군 모델의 평균 사이에 유의미한 차이가 있는지를 검정하고, 평균의 정규화된 차이(즉, -통계량)와 p-값을 보고합니다.
모델이 일관되게 인간의 기사보다 더 인상적인 텍스트를 생성한다면, 이 작업에 대한 인간의 성능이 50% 아래로 떨어질 가능성이 있습니다. 실제로 많은 개별 참가자들이 이 작업에서 미만을 기록했습니다.
추가적인 비뉴스(non-news) 샘플은 부록(Appendix)에서 찾아볼 수 있습니다.
