논문 번역
- 이 글은 제가 읽는 논문을 번역해서 올려놓는 공간입니다.
- 번역은 LLM(현재는 GPT-4)를 통해 번역하고 있습니다.
- 대략의 pipeline은 mathpix를 통해 ocr후 gpt-4로 대략 1000토큰 단위로 나누어 번역하고 있습니다. 논문->ocr을 통한 markdown으로 변경 -> markdown로 작성된 논문을 gpt-4 api로 번역 및 markdown으로 작성
- 현재까지 완성된 파이프라인은 https://github.com/aeolian83/paper_translator 입니다
- 원문 링크는 다음과 같습니다.
대규모 대조적 언어-오디오 사전학습: 특징 융합 및 키워드-캡션 증강
Yusong , Ke Chen , Tianyu Zhang , Yuchen Hui , Taylor Berg-Kirkpatrick , Shlomo Dubnov
밀라(Mila), 퀘벡 인공지능 연구소(Quebec Artificial Intelligence Institute), 몬트리올 대학교(Université de Montréal)
캘리포니아 대학교 샌디에이고(University of California San Diego) LAION
초록(Abstract)
대조적 학습(Contrastive learning)은 다중 모달 표현 학습(multimodal representation learning) 분야에서 뛰어난 성공을 거두었습니다. 본 논문에서는 오디오 데이터와 자연어 설명을 결합하여 오디오 표현을 개발하기 위한 대조적 언어-오디오 사전학습(pipeline of contrastive language-audio pretraining)을 제안합니다. 이 목표를 달성하기 위해, 우리는 다양한 데이터 소스에서 633,526개의 오디오-텍스트 쌍으로 구성된 대규모 컬렉션인 LAION-Audio-630K를 처음으로 공개합니다. 두 번째로, 우리는 다양한 오디오 인코더(audio encoders)와 텍스트 인코더(text encoders)를 고려하여 대조적 언어-오디오 사전학습 모델을 구축합니다. 우리는 모델 설계에 특징 융합 메커니즘(feature fusion mechanism)과 키워드-캡션 증강(keyword-to-caption augmentation)을 통합하여 모델이 가변 길이의 오디오 입력을 처리하고 성능을 향상시킬 수 있도록 합니다. 세 번째로, 우리는 텍스트-오디오 검색(text-to-audio retrieval), 제로샷 오디오 분류(zero-shot audio classification), 그리고 지도 오디오 분류(supervised audio classification) 세 가지 작업에서 모델을 평가하기 위한 종합적인 실험을 수행합니다. 결과는 우리 모델이 텍스트-오디오 검색 작업에서 우수한 성능을 달성한다는 것을 보여줍니다. 오디오 분류 작업에서 모델은 제로샷 설정에서 최신 기술(state-of-the-art) 성능을 달성하며, 비제로샷 설정(non-zero-shot setting)에서는 모델들의 결과와 비교할 수 있는 성능을 얻을 수 있습니다. LAION-Audio-630K와 제안된 모델은 모두 공개적으로 이용 가능합니다.
색인 용어(Index Terms) - 대조적 학습(Contrastive Learning), 표현 학습(Representation Learning), 텍스트-오디오 검색(Text-to-Audio Retrieval), 오디오 분류(Audio Classification), 오디오 데이터셋(Audio Dataset)
1. 서론(INTRODUCTION)
오디오는 텍스트와 이미지 데이터와 함께 세계에서 가장 흔한 정보 유형 중 하나입니다. 그러나 다양한 오디오 작업은 일반적으로 세밀하게 주석이 달린 데이터(finely-annotated data)를 필요로 하며, 이는 노동 집약적인 수집 절차로 인해 사용 가능한 오디오 데이터의 양을 제한합니다. 따라서 많은 오디오 작업에 대해 많은 감독 없이 효과적인 오디오 표현을 설계하는 것은 여전히 도전 과제입니다.
대조 학습(contrastive learning) 패러다임은 인터넷에서 수집된 대규모의 잡음이 섞인 데이터에 대한 모델 학습을 위한 성공적인 해결책입니다. 최근 제안된 Contrastive Language-Image Pretraining(CLIP) [1]은 텍스트와 이미지를 공유 잠재 공간으로 투영하여 둘 사이의 대응 관계를 학습합니다. 학습은 정답 이미지-텍스트 쌍을 긍정적인 샘플로 간주하고 나머지를 부정적인 샘플로 취급하면서 진행됩니다. 단일 모달 데이터(unimodal data)에 대한 학습과는 달리, CLIP는 데이터 주석에 구애받지 않으며 ImageNet 데이터셋의 도메인 외 변형(out-of-domain variations)에서 제로샷(zero-shot) 설정으로 높은 정확도를 달성함으로써 큰 강인함을 보여줍니다 [2]. 또한, CLIP은 텍스트-이미지 검색(text-to-image retrieval) 및 텍스트 가이드 캡셔닝(textguided captioning)과 같은 하류 작업(downstream tasks)에서 큰 성공을 거두었습니다. 비전(vision)과 마찬가지로, 오디오(audio)와 자연 언어(natural languages)[^0]도 중첩된 정보를 포함하고 있습니다. 예를 들어, 오디오 이벤트 분류 작업(audio event classification task)에서는 이벤트의 일부 텍스트 설명을 해당 오디오와 매핑할 수 있습니다. 이러한 텍스트 설명은 유사한 의미를 공유하며 관련 오디오와 함께 학습되어 교차 모달 정보(crossmodal information)의 오디오 표현을 형성할 수 있습니다. 또한, 이러한 모델을 훈련시키는 데는 단순히 짝지어진 오디오와 텍스트 데이터만 필요하며, 이는 쉽게 수집할 수 있습니다.
최근 몇몇 연구들 [3-9]은 텍스트-오디오 검색 작업(text-to-audio retrieval task)을 위한 대조 언어-오디오 사전학습 모델(contrastive language-audio pretraining model)의 프로토타입을 제시했습니다. [6]은 오디오 인코더로 Pretrained Audio Neural Network(PANN) [10]를, 텍스트 인코더로 BERT [11]를 사용하고, 텍스트-오디오 검색 성능을 평가하기 위한 여러 손실 함수를 활용합니다. [5]는 성능을 더욱 향상시키기 위해 HTSAT [12]와 RoBERTa [13]를 인코더 목록에 추가로 결합합니다. 그리고 [4]는 하류 작업인 오디오 분류에서 학습된 표현의 효과를 조사합니다. AudioClip [3]과 WaveCLIP [9]과 같은 다른 연구들은 대조 이미지-오디오(또는 이미지-오디오-언어) 사전학습 모델에 더 초점을 맞춥니다. 이 모든 모델들은 오디오 분야에서 대조 학습의 큰 잠재력을 보여줍니다.
그럼에도 불구하고, 현재의 연구들은 언어-오디오 대조 학습(language-audio contrastive learning)의 전체적인 강점을 보여주지 못하고 있습니다. 첫째, 위에서 언급한 모델들은 상대적으로 작은 데이터셋에서 훈련되어, 훈련을 위한 대규모 데이터 수집 및 증강이 필요하다는 것을 보여줍니다. 둘째, 이전 연구들은 오디오/텍스트 인코더의 선택과 하이퍼파라미터 설정에 대한 전체적인 조사가 부족한데, 이는 기본 대조 언어-오디오 구조를 결정하는 데 필수적입니다. 셋째, 모델은 특히 트랜스포머 기반 오디오 인코더(transformer-based audio encoder)에 대해 다양한 오디오 길이를 수용하는 데 어려움을 겪습니다. 가변 길이의 오디오 입력을 처리할 수 있는 해결책이 있어야 합니다. 마지막으로, 대부분의 언어-오디오 모델 연구는 텍스트-오디오 검색에만 초점을 맞추고 있으며, 하류 작업에서의 오디오 표현을 평가하지 않습니다. 표현 모델로서, 우리는 더 많은 하류 작업에서의 일반화 능력에 대한 발견을 기대합니다.
이 논문에서는 이전 연구 [6]를 바탕으로, 위의 우려사항에서 데이터셋, 모델 설계 및 실험 설정을 개선하기 위한 기여를 합니다:
- 우리는 현재 가장 큰 공개 오디오 캡션 데이터셋인 LAION-Audio-630K를 출시했습니다. 이 데이터셋은 633,526개의 오디오-텍스트 쌍으로 구성되어 있습니다. 학습 과정을 용이하게 하기 위해, 우리는 AudioSet [14]의 레이블을 해당 캡션으로 확장하기 위한 키워드-캡션 모델(keyword-to-caption model)을 사용합니다. 이 데이터셋은 다른 오디오 작업에도 기여할 수 있습니다.
- 우리는 대조적 언어-오디오 사전학습(contrastive language-audio pretraining) 파이프라인을 구축합니다. 두 개의 오디오 인코더와 세 개의 텍스트 인코더를 테스트를 위해 선택했습니다. 우리는 성능을 향상시키고 가변 길이 입력을 처리할 수 있게 하는 특징 융합 기능(feature fusion mechanisms)을 사용합니다.
- 우리는 모델에 대한 포괄적인 실험을 수행합니다. 이에는 텍스트-오디오 검색 작업(text-to-audio retrieval task)뿐만 아니라 제로샷(zero-shot)과 지도 학습(supervised)
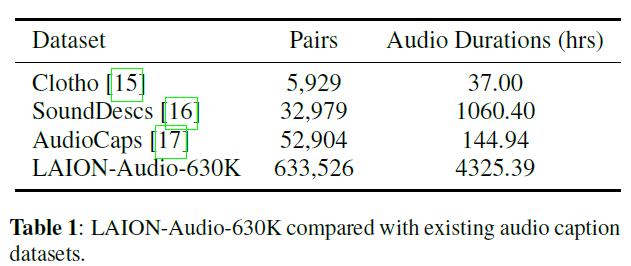
표 1: 기존 오디오 캡션 데이터셋과 비교한 LAION-Audio-630K.
오디오 분류 다운스트림 작업(audio classification downstream tasks)을 포함합니다. 우리는 데이터셋의 확장, 키워드-캡션 증강, 그리고 특징 융합이 다양한 관점에서 모델의 성능을 향상시킬 수 있음을 보여줍니다. 이는 텍스트-오디오 검색 및 오디오 분류 작업에서 최신 기술(state-of-the-art, SOTA)을 달성하며, 지도 학습 모델의 성능과 비교할 수 있습니다.
우리는 LAION-Audio-630K와 제안된 모델을 모두 공개합니다.
2. LAION-AUDIO-630K 및 학습 데이터셋
2.1. LAION-Audio-630K
우리는 총 4,325.39시간의 지속 시간을 가진 633,526쌍으로 구성된 대규모 오디오-텍스트 데이터셋인 LAION-Audio-630K를 수집했습니다. 이 데이터셋은 인간 활동, 자연 소리 및 오디오 효과의 오디오를 포함하며, 공개적으로 이용 가능한 웹사이트들로부터 8개의 데이터 소스를 포함하고 있습니다 우리는 오디오와 관련된 텍스트 설명을 다운로드하여 이 데이터셋을 수집했습니다. 현재 우리의 지식에 기반하여, LAION-Audio-630K는 공개적으로 이용 가능한 가장 큰 오디오-텍스트 데이터셋이며, 표 1에서 보여지듯 이전의 오디오-텍스트 데이터셋보다 훨씬 큰 규모입니다.
2.2. 학습 데이터셋
모델 성능이 다양한 크기와 유형의 데이터셋에서 어떻게 확장될지 테스트하기 위해, 이 논문에서는 작은 크기부터 큰 크기까지 다양한 세 가지 훈련 세트 설정을 사용합니다. 이 설정들은 세 가지 데이터셋을 사용합니다: 1) 오디오캡스+클로소(AudioCaps+Clotho, )[15, 17]는 약 개의 오디오-텍스트 쌍 훈련 샘플을 포함합니다. 2) 라이온-오디오-630K(LAION-Audio-630K, LA.)는 약 개의 오디오-텍스트 쌍을 포함합니다. 3) 오디오셋(Audioset)[14]은 각 샘플에 대해 레이블만 있는 190만 개의 오디오 샘플로 구성됩니다. 이 데이터셋들을 처리할 때, 평가 세트에 중복되는 모든 데이터를 제외합니다. 훈련 데이터셋의 더 자세한 내용은 온라인 부록에서 확인할 수 있습니다.
2.3. 데이터셋 형식 및 전처리
이 연구에서 사용된 모든 오디오 파일은 FLAC 형식으로 샘플 레이트가 인 모노 채널로 전처리됩니다. 태그나 레이블만 있는 데이터셋의 경우, "label-1, label-2, ..., 그리고 label-n의 소리"라는 템플릿이나 키워드-투-캡션 모델(3.5절에서 자세히 설명)을 사용하여 레이블을 캡션으로 확장합니다. 결과적으로, 우리는 대조적 언어-오디오 사전 훈련 모델의 훈련에 더 많은 데이터를 활용할 수 있습니다. 모든 데이터셋을 결합하여, 텍스트 캡션과 함께하는 오디오 샘플의 총 수를 250만 개로 늘립니다.
3. 모델 구조
3.1. 대조적 언어-오디오 사전 훈련
그림 1은 우리가 제안한 대조적 언어-오디오 인코더 모델의 일반적인 구조를 보여줍니다. CLIP[1]과 유사하게, 우리는 오디오 데이터 와 텍스트[^1] 데이터 의 입력을 각각 처리하는 두 개의 인코더를 가지고 있습니다. 여기서 는 로 색인된 오디오-텍스트 쌍 중 하나입니다. 오디오 임베딩 와 텍스트 임베딩 는 각각 오디오 인코더 와 텍스트 인코더 에 의해 획득되며, 프로젝션 레이어를 사용합니다:
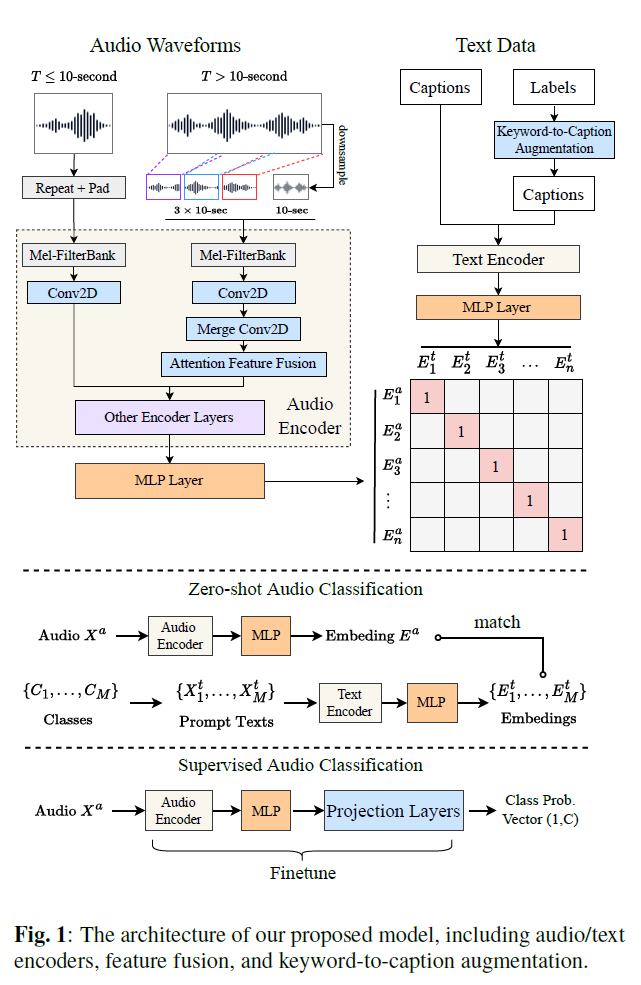
그림 1: 제안하는 모델의 구조, 오디오/텍스트 인코더, 특징 융합, 그리고 키워드-투-캡션 증강을 포함합니다.
여기서 오디오/텍스트 투영층(audio/text projection layer)은 ReLU [18]를 활성화 함수로 사용하는 2층 다층 퍼셉트론(MLP)으로, 인코더 출력을 동일한 차원 (즉, )으로 매핑합니다.
모델은 [1]의 손실 함수를 따르며, 오디오와 텍스트 임베딩 쌍 사이의 대조 학습 패러다임(contrastive learning paradigm)으로 훈련됩니다:
여기서 는 손실을 조정하기 위한 학습 가능한 온도 매개변수(temperature parameter)입니다. 두 로그 용어는 오디오에서 텍스트로의 로짓(audio-to-text logits) 또는 텍스트에서 오디오로의 로짓(text-to-audio logits)을 고려합니다. 은 보통 데이터의 수를 의미하지만, 훈련 단계에서는 전체 데이터의 행렬을 계산할 수 없기 때문에 배치 크기로 사용되며, 모델은 배치 경사 하강법(batch gradient descent)으로 업데이트됩니다.
모델을 훈련한 후에는 그림 1에 표시된 것처럼 다양한 작업에 임베딩 을 사용할 수 있으며, 아래 하위 섹션에 나열되어 있습니다.
3.2. 추론 단계에서의 하류 작업(Downstream Tasks in Inference Stage)
텍스트에서 오디오로 검색(Text-to-Audio Retrieval) 목표 오디오 임베딩 은 코사인 유사도 함수(cosine similarity function)를 사용하여 개의 텍스트 중에서 가장 가까운 텍스트 임베딩 을 찾아 최적의 매치를 결정할 수 있습니다.
제로샷 오디오 분류 개의 오디오 클래스 에 대해, 우리는 개의 프롬프트 텍스트 를 구성할 수 있습니다(예: "class-name의 소리"). 주어진 오디오 에 대해, 우리는 임베딩 상의 코사인 유사도 함수(cosine similarity function)를 통해 중에서 가장 잘 매치되는 를 결정합니다. 대조적 언어-오디오 사전학습(contrastive language-audio pretraining)을 사용하는 한 가지 장점은 오디오의 카테고리가 제한되지 않는다는 것입니다(즉, 제로샷(zero-shot)), 모델이 분류 작업을 텍스트-오디오 검색 작업으로 변환할 수 있기 때문입니다.
지도 오디오 분류 모델 학습 후, 주어진 오디오 에 대해, 그 임베딩 은 뒤쪽에 투영층(projection layer)을 추가하고 미세조정(finetuning)함으로써 고정된 카테고리 분류 작업으로 더 매핑될 수 있습니다(즉, 제로샷이 아닌 설정(non-zero-shot setting)).
3.3. 오디오 인코더와 텍스트 인코더
오디오 인코더를 구성하기 위해, 우리는 PANN [10]과 HTSAT [12] 두 모델을 선택했습니다. PANN은 7개의 다운샘플링 CNN 블록과 7개의 업샘플링 블록을 가진 CNN 기반 [19] 오디오 분류 모델입니다. HTSAT은 4개의 스윈트랜스포머 블록(swintransformer blocks) [20]을 가진 트랜스포머 기반 모델로, 세 개의 오디오 분류 데이터셋에서 최고의 성능을 달성했습니다(SOTAs). 두 모델 모두, 우리는 그들의 끝에서 두 번째 레이어의 출력인 -차원 벡터를 투영 MLP 층으로 보내는 출력으로 사용합니다. 여기서 이고 입니다.
텍스트 인코더를 구성하기 위해, 우리는 CLIP 트랜스포머 [1] (CLIP의 텍스트 인코더), BERT [11], 그리고 RoBERTa [13] 세 모델을 선택했습니다. 텍스트 인코더의 출력 차원은 각각 512, , 그리고 입니다. 우리는 ReLU 활성화 [18]를 가진 2층 MLP를 적용하여 오디오와 텍스트 출력을 모두 512 차원으로 매핑합니다. 이는 대조적 학습 패러다임(contrastive learning paradigm)으로 학습할 때 오디오/텍스트 표현의 크기입니다.
3.4. 가변 길이 오디오를 위한 특징 융합
RGB 이미지 데이터는 통일된 해상도로 크기를 조정할 수 있는 반면, 오디오는 길이가 가변적이라는 특성을 가지고 있습니다. 전통적으로는 전체 오디오를 오디오 인코더에 입력하고, 프레임별 또는 청크별 오디오 임베딩의 평균을 출력으로 취하는 방식(즉, 슬라이스 & 투표(slice & vote))을 사용했습니다. 그러나 이러한 전통적인 방법은 긴 오디오에서 계산 효율이 좋지 않습니다. 그림 1의 왼쪽에 나타난 것처럼, 우리는 대략적인 전체(global) 정보와 무작위로 샘플링된 지역(local) 정보를 결합함으로써, 다양한 길이의 오디오 입력에 대해 일정한 계산 시간으로 학습하고 추론합니다. 초 길이의 오디오와 고정된 청크 기간 초의 경우:
- : 입력을 먼저 반복한 다음, 0값으로 패딩합니다. 예를 들어, 3초 길이의 입력은 초로 반복되고 1초 길이의 0값으로 패딩됩니다.
- : 입력을 초에서 초로 다운샘플링하여 전체(global) 입력으로 사용합니다. 그 다음 입력의 앞 , 중간 , 뒤 에서 각각 초 길이의 클립을 무작위로 잘라내어 지역(local) 입력으로 사용합니다. 이 입력들을 오디오 인코더의 첫 번째 레이어로 보내 초기 특성을 얻은 다음, 세 개의 지역 특성은 시간 축에서 3-스트라이드(stride)를 가진 또 다른 2D-컨볼루션(2D-Convolution) 레이어를 통해 하나의 특성으로 변환됩니다. 마지막으로, 지역 특성 와 전체 특성 는 다음과 같이 융합됩니다:
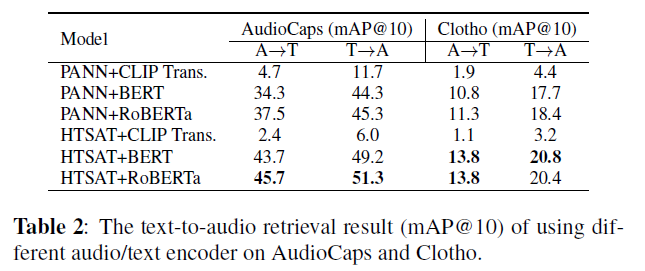
표 2: AudioCaps와 Clotho에서 다양한 오디오/텍스트 인코더를 사용한 텍스트-오디오 검색 결과(mAP@ 10).
여기서 는 주의 기능 융합(Attention Feature Fusion, AFF) [21]을 통해 얻은 요소로, 두 입력의 융합 요소를 학습하기 위한 두 가지 분기가 있는 CNN 모델입니다. "슬라이스 & 투표(slice & vote)" 방법과 비교할 때, 특징 융합은 처음 몇 층에서만 오디오 슬라이스를 처리하기 때문에 훈련 시간도 절약됩니다.
3.5. 키워드-캡션 증강
2.1절에서 언급했듯이 일부 데이터셋은 해당 오디오의 키워드로 합리적인 레이블이나 태그를 포함하고 있습니다. 그림 1의 오른쪽에 나타난 것처럼, 우리는 사전 훈련된 언어 모델 T5 [22]를 사용하여 이러한 키워드 위에 캡션을 만들었습니다. 또한, 출력 문장을 사후 처리로 편향을 제거합니다. 예를 들어, 성별 편향을 제거하기 위해 "woman"과 "man"을 'person'으로 대체합니다. 페이지 제한으로 인해, 증강의 예시는 온라인 부록에서 제공합니다.
4. 실험
이 섹션에서는 제안된 모델에 대한 세 가지 실험을 수행합니다. 먼저, 최고의 기본 조합을 찾기 위해 다양한 오디오 및 텍스트 인코더로 학습을 진행합니다. 그 다음, 제안된 방법의 효과를 검증하기 위해 다양한 데이터셋 크기에서 특징 융합(feature fusion)과 키워드-캡션 증강(keyword-to-caption augmentation)을 사용하여 모델을 학습합니다. 첫 두 실험에서는 오디오-텍스트 및 텍스트-오디오 검색에서 모델의 성능을 리콜(recall)과 평균 정밀도(mean average precision, mAP)를 통해 평가합니다. 마지막으로, 최고의 모델을 사용하여 제로샷(zero-shot) 및 지도 오디오 분류 실험을 수행하여 하류 작업(downstream tasks)으로의 일반화 능력을 평가합니다.
4.1. 하이퍼파라미터 및 학습 세부 사항
2.2절에서 언급한 바와 같이, 우리는 AudioCaps, Clotho, LAIONAudio-630K와 함께 추가 데이터셋인 AudioSet을 키워드-캡션 증강으로 사용하여 모델을 학습합니다. 오디오 데이터의 경우, 입력 길이는 10초, 홉 사이즈(hop size)는 480, 윈도우 사이즈(window size)는 1024, 멜-빈(mel-bins)은 64로 설정하여 STFTs와 멜-스펙트로그램(mel-spectrograms)을 계산합니다. 결과적으로, 오디오 인코더로 전송되는 각 입력은 의 형태를 가집니다. 텍스트 데이터의 경우, 최대 토큰 길이가 77인 텍스트를 토큰화합니다.
특징 융합 없이 모델을 학습할 때, 10초보다 긴 오디오는 무작위로 10초 구간으로 잘라집니다. 학습 중에는 의 Adam [23] 최적화기(optimizer)를 사용하며, 웜업(warm-up) [24]과 기본 학습률 에서 코사인 학습률 감소(cosine learning rate decay)를 적용합니다. 모델은 AudioCaps+Clotho 데이터셋에서 배치 크기 768로, LAION-Audio-630K를 포함하는 학습 데이터셋에서는 2304로, AudioSet을 포함하는 학습 데이터셋에서는 4608로 학습하며, 총 45 에폭(epoch) 동안 학습합니다.
4.2. 텍스트-오디오 검색
오디오 및 텍스트 인코더 먼저, 텍스트-오디오 검색 작업에 가장 적합한 오디오 인코더와 텍스트 인코더를 선택하기 위한 실험을 수행합니다. 3.3절에서 두 오디오 인코더와 세 텍스트 인코더를 결합하는데, 이때 둘 다 [5, 7, 8]과 같이 사전 학습된 체크포인트에서 로드됩니다. 이 실험에서는 AudioCaps에서만 학습을 진행합니다.
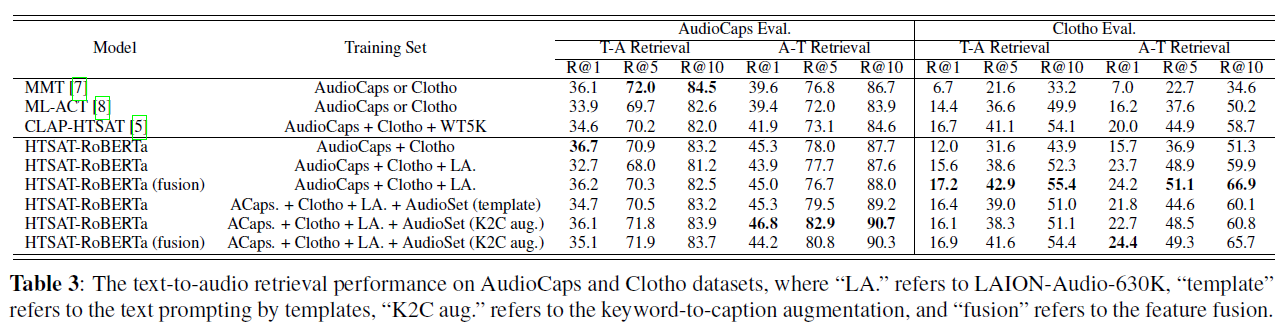
표 3: AudioCaps와 Clotho 데이터셋에서의 텍스트-오디오 검색 성능, 여기서 "LA."는 LAION-Audio-630K를, "template"는 템플릿을 이용한 텍스트 프롬프팅(text prompting)을, "K2C aug."는 키워드-캡션 증강(keyword-to-caption augmentation)을, "fusion"은 특징 융합(feature fusion)을 의미합니다.
그리고 Clotho 데이터셋(약 55K 데이터)에서 오디오-텍스트 및 텍스트-오디오 관점에서 최고의 mAP@10을 보고합니다.
표 2의 결과에 따르면, 오디오 인코더에 대해 HTSAT는 RoBERTa나 BERT 텍스트 인코더와 결합된 PANN보다 더 나은 성능을 보입니다. 텍스트 인코더의 경우, RoBERTa가 BERT보다 더 나은 성능을 달성하는 반면, CLIP 변환기(transformer)는 극도로 나쁜 성능을 보입니다. 이는 이전 연구들 [4, 8]에서 텍스트 인코더 선택과 일치합니다. CLIP 변환기 모델의 손실 수렴 경향을 더 분석할 때, RoBERTa는 과적합(over-fitting)이 적은 반면, CLIP 변환기는 고도의 과적합(high-over-fitting)을 보여, 낮은 일반화 성능을 초래합니다.
데이터셋 규모에 따라, 우리는 HTSAT-RoBERTa를 최고의 모델 설정으로 채택하여 표 3에서 텍스트-오디오 검색 실험을 종합적으로 평가하기 위해 수행합니다. 이 작업에서 다른 순위에서의 회상 점수를 계산하기 위해 [7][8]에서와 동일한 메트릭을 사용합니다. 훈련 세트에서, 우리는 데이터셋의 규모를 점진적으로 증가시킵니다. "AudioCaps + Clotho"에서 "LA."로 데이터셋을 확장하는 것이 AudioCaps 평가 세트에서는 결과를 개선하지 않지만 Clotho 평가 세트에서는 더 나은 성능을 얻는 것을 발견했으며, 이는 MMT [7]와 CLAP-HTSAT [5] 사이의 비교와 유사합니다. 한 가지 이유는 AudioCaps에는 오디오 인코더가 사전 훈련된 AudioSet과 유사한 오디오가 포함되어 있기 때문입니다. 모델이 다른 출처로부터 더 많은 데이터를 받을 때, 그것은 일반화를 증가시키지만 AudioSet 데이터의 분포를 벗어나게 합니다. 따라서 AudioCaps에서의 성능은 떨어지지만 Clotho에서는 많이 증가하여, 다양한 유형의 오디오 사이에서 성능을 유지하는 모델의 트레이드오프(trade-off)를 보여줍니다.
키워드-캡션 증강 및 특징 융합 모델에 특징 융합 메커니즘과 키워드-캡션 증강을 추가할 때, 둘 중 어느 것이든 성능을 향상시키는 것을 관찰할 수 있습니다. 특징 융합은 특히 Clotho 데이터셋에서 효과적입니다. 왜냐하면 그것은 더 긴 오디오 데이터(초)를 포함하기 때문입니다. 템플릿 프롬프팅이나 키워드-캡션 증강을 훈련 세트에 AudioSet과 함께 추가할 때, AudioCaps에서는 다시 성능이 증가하는 반면 Clotho에서는 감소하는 것을 볼 수 있습니다. 이는 위에서 언급한 AudioCaps와 Clotho 데이터셋 사이의 트레이드오프 성능을 더 확인시켜 줍니다. 그리고 키워드-캡션 증강은 대부분의 메트릭에서 단순한 템플릿 텍스트 프롬프팅 방법보다 더 나은 성능을 가져옵니다.
결과적으로, 우리의 최고 모델은 텍스트-오디오 검색(text-to-audio retrieval) 작업에서 대부분의 지표(주로 AudioCaps에서 R@1=36.7%, Clotho에서 R@1=18.2%)에서 이전 방법들을 능가합니다. 대규모 데이터셋(LAION-Audio-630K 및 AudioSet에 키워드-캡션 증강(keyword-to-caption augmentation)을 적용)에서의 학습과 특징 융합(feature fusion)이 모델 성능을 효과적으로 향상시킬 수 있음을 보여줍니다.
4.3. 제로샷 및 지도 오디오 분류
제로샷 오디오 분류(Zero-shot Audio Classification) 모델의 일반화와 견고성을 연구하기 위해, 이전 실험에서 성능이 가장 좋았던 세 모델을 대상으로 제로샷 오디오 분류 실험을 수행했습니다. 우리는
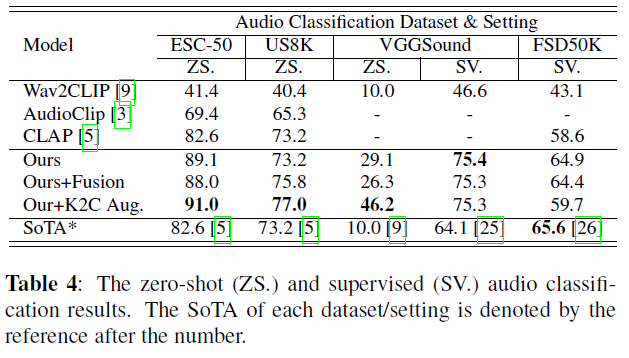
표 4: 제로샷(ZS.) 및 지도(SV.) 오디오 분류 결과. 각 데이터셋/설정의 최고 기록(SoTA)은 숫자 뒤의 참조로 표시됩니다.
세 가지 오디오 분류 데이터셋, 즉 ESC50 [27], VGGSound [28], 그리고 Urbansound8K (US8K) [29]에서 모델을 평가합니다. 우리는 상위 1위(top-1) 정확도를 지표로 사용합니다. 각 텍스트가 클래스 라벨에서 "This a sound of label."로 변환된 텍스트 프롬프트에 해당하는 오디오-텍스트 검색을 수행하여 오디오를 분류합니다. 우리는 훈련 데이터와 우리가 평가하고 있는 제로샷(zero-shot) 데이터셋 사이에 데이터 중복이 있다는 것을 알아차렸습니다. 우리는 모든 중복 샘플을 제외하고 남은 전체 데이터셋에 대해 제로샷 평가를 수행합니다.
지도 오디오 분류(Supervised Audio Classification) 우리는 FSD50K [30]와 VGGSound 데이터셋에서 오디오 인코더를 미세 조정(fine-tuning)하여 지도 오디오 분류를 수행합니다. ESC50과 Urbansound 8K에서는 이 실험을 수행하지 않습니다. 왜냐하면 해당 데이터셋의 잠재적인 데이터 유출 문제가 이전 방법들과 비교할 수 없는 결과를 초래할 수 있기 때문입니다. 특히, FSD50K를 평가하기 위해 mAP가 지표로 사용됩니다.
표 4에서 보여지듯이, 우리의 모델은 세 데이터셋 모두에서 제로샷 오디오 분류의 새로운 최고 기록(SoTAs)을 달성하여, 우리 모델이 보지 못한 데이터에 대한 높은 일반화 능력을 입증합니다. 키워드-캡션 증강(Keyword-to-Caption augmentation)은 "텍스트 임베딩 공간을 풍부하게(enrich)"하기 위해 더 많은 텍스트 캡션을 추가함으로써 VGGsound와 US8K의 성능을 크게 향상시킵니다. 특징 융합(Feature fusion)은 모델이 가변 길이 입력을 처리할 수 있게 할 뿐만 아니라 이전 모델들보다 더 나은 성능을 달성합니다. 우리의 최고 지도 오디오 분류 결과는 VGGSound 데이터셋에서 현재 최고 기록을 뛰어넘고, FSD50K 데이터셋에서 최고 기록에 근접합니다. 이 결과들은 제안된 모델이 대조 학습 패러다임(contrastive learning paradigm) 동안 효율적인 오디오 표현도 학습한다는 것을 확인시켜 줍니다.
5. 결론 및 향후 작업
이 논문에서, 우리는 대규모 오디오-텍스트 데이터셋과 현재 언어-오디오 대조 학습 패러다임에 대한 개선을 제안합니다. 우리는 LAION-Audio-630, 키워드-캡션 증강이 적용된 AudioSet, 그리고 특징 융합이 더 나은 오디오 이해, 작업 성능을 이끌어내고 가변 길이 데이터에 대한 효과적인 학습을 가능하게 한다는 것을 보여줍니다. 향후 작업에는 더 큰 데이터셋을 수집하여 훈련하고, 오디오 합성 및 분리와 같은 더 많은 하류 작업(downstream tasks)에 표현을 적용하는 것이 포함됩니다.
A. 부록
B. 감사의 말
Yusong Wu, Ke Chen, Tianyu Zhang은 LAION 프로젝트에 오픈소스 기여자입니다. 우리의 코드베이스는 다음과 같은 오픈소스 프로젝트를 기반으로 구축되었습니다: PANN HTSAI , open_clin PyTorch LAION, Stability.ai 및 Oak Ridge National Laboratory의 Summit 클러스터로부터의 계산 인프라 지원에 감사드립니다. 이 프로젝트는 몬트리올 대학교와 Mila의 Irina Rish 교수가 진행한 IFT-6167에서 제안되었습니다. Christoph Schuhmann, Richard Vencu, Romain Beaumon의 지원에 감사드리며, 그들이 없었다면 이 프로젝트는 불가능했을 것입니다. 음향학 및 음악 연구 조정 연구소(IRCAM )와 사이버-인간 음악성에서의 공동 창조성 증진 프로젝트(Project REACF )의 이 프로젝트 지원에 감사드립니다. LAION-630k 데이터셋 수집에 기여한 모든 커뮤니티 기여자들에게 감사드립니다. 이 커뮤니티 기여자들(Discord ids)에는 @marianna13#7139, @Chr0my#0173, @PiEquals4#1909, @Yuchen Hui#8574, @Antoniooooo#4758, @IYWO#9072, krishna#1648, @dicknascarsixtynine#3885, 그리고 @ turian#1607 등이 포함되지만 이에 국한되지 않습니다. 검색 메트릭스에 대한 설명과 도움을 준 Xinhao Mei에게 감사드립니다.
C. 검색 성능 평가의 세부 사항
이 연구에서는 R@1, R@5, R@10 및 평균 정밀도(Mean Average Precision, mAP)와 같은 메트릭을 활용하여 모델의 검색 성능의 효과를 평가하는 데 주요 초점을 맞추고 있습니다. 특히 Clotho와 AudioCaps 데이터셋은 각 오디오 샘플당 다섯 개의 텍스트 지상 진리(ground-truths)가 있는 것이 특징입니다. 따라서 이 데이터셋에서 검색 성능을 평가할 때, 이전 연구에서 사용된 것과 동일한 메트릭을 채택합니다, 특히 에서 개요된 메트릭을 사용합니다.
텍스트-오디오 검색(text-to-audio retrieval)에서는 오디오의 각 텍스트를 독립적인 테스트 샘플로 취급하고, 테스트 세트 크기의 다섯 배에 해당하는 테스트 샘플에서 텍스트-오디오 검색 메트릭스의 평균을 계산합니다. 오디오-텍스트 리콜(audio-to-text recall)을 평가할 때, 각 오디오의 리콜은 다섯 개의 텍스트 지상 진실(text ground-truths) 중 최고의 오디오-텍스트 검색 결과를 취함으로써 계산됩니다. 추가적으로, 오디오-텍스트 평균 평균 정밀도(Mean Average Precision, mAP)는 로 계산되며, 여기서 은 리콜 수준 에서의 정밀도를 나타내고, 은 리콜 수준 의 텍스트가 관련이 있는지 여부를 나타내는 이진 지표입니다.
Freesound와 같이 각 오디오 샘플에 하나의 텍스트만 연결된 다른 데이터셋의 경우, 리콜과 평균 평균 정밀도(mean average precision, )는 표준 방식으로 측정됩니다.
D. LAION-AUDIO-630K의 세부 사항
논문의 2.1절과 2.2절에 관하여:
- LAION-Audio-630K에 대한 오디오 샘플과 텍스트 캡션을 수집하는 웹사이트/출처의 사양을 표 5에 나열합니다.
- 표 6에 세 가지 데이터셋의 세부 사항을 나열합니다. 이들의 조합을 사용하여 제출물의 4절에서 모델을 훈련합니다.
- 논문의 3.4절에 관하여, LAION-Audio-630K의 일부로서 Epidemic Sound와 Freesound [31]에서 오디오 길이의 분포를 제시하여 오디오 데이터 처리와 모델 훈련에서 가변 길이 문제의 존재를 보여줍니다.
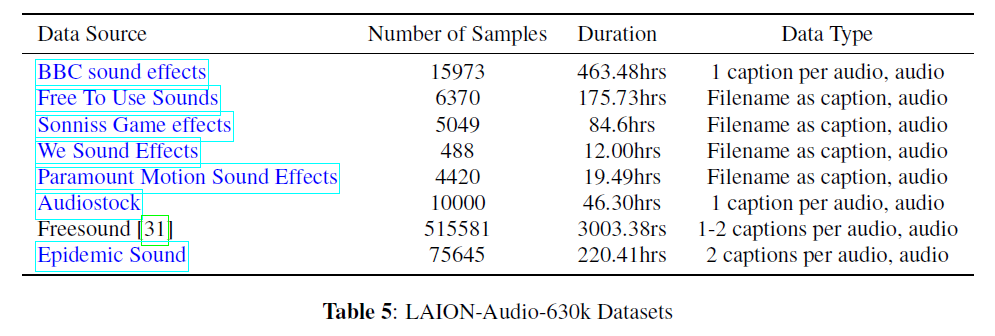
표 5: LAION-Audio-630k 데이터셋[^2] utils.PY#L74
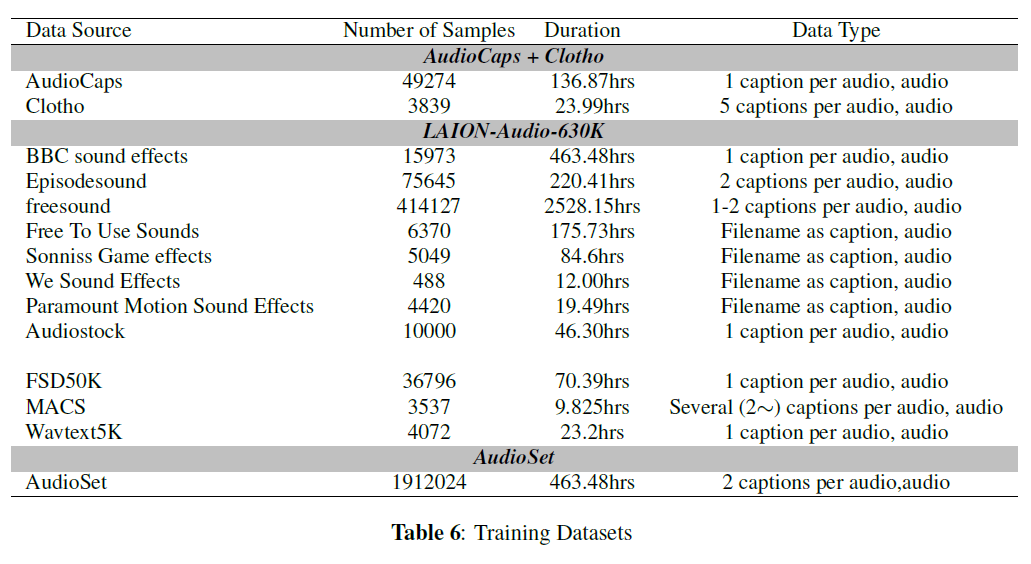
표 6: 훈련 데이터셋
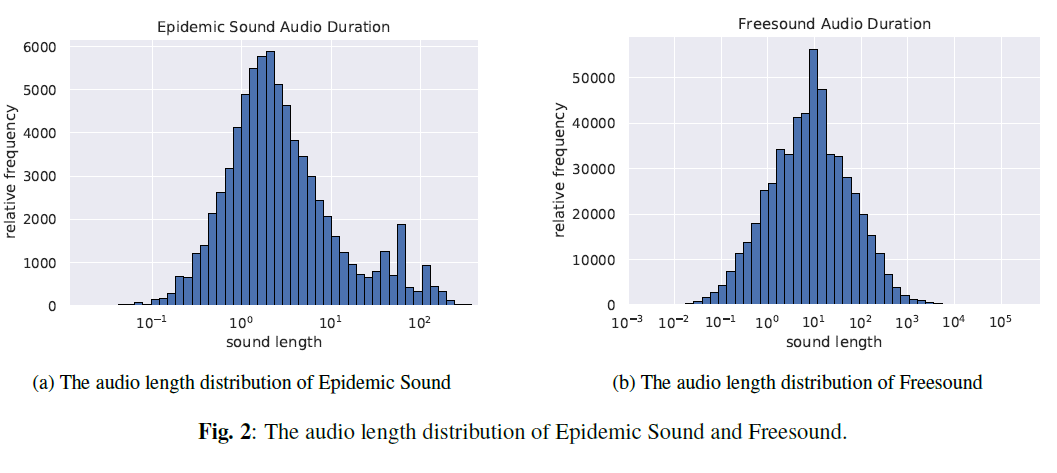
(a) Epidemic Sound의 오디오 길이 분포
(b) Freesound의 오디오 길이 분포
그림 2: Epidemic Sound와 Freesound의 오디오 길이 분포.
D.1. Freesound 데이터셋
Freesound 데이터셋의 샘플들은 Freesound [31]에서 수집되었습니다. Freesound의 모든 오디오 클립들은 크리에이티브 커먼즈(Creative Commons, CC) 라이선스 하에 공개되어 있으며, 각 클립은 Freesound에서 클립 업로더가 정의한 자체 라이선스를 가지고 있습니다. 이 중 일부는 원작자에 대한 어트리뷰션(attribution)을 요구하고, 일부는 추가적인 상업적 재사용을 금지합니다. 구체적으로, LAION-Audio-630K에 포함된 오디오 클립의 라이선스에 대한 통계는 다음과 같습니다:
- CC-BY: 196884
- CC-BY-NC: 63693
- CC0: 270843
- CC Sampling+: 11556
우리는 데이터셋 릴리스 페이지에서 각 샘플의 라이선스를 나열했습니다
E. 주의 기반 특징 융합(ATTENTIONAL FEATURE FUSION)
논문의 3.4절에서, 우리는 "주의 기반 특징 융합(attentional feature fusion)" 아키텍처를 소개합니다. 이는 두 개의 분기를 가진 CNN 네트워크로, 입력 오디오의 전역 정보(global information)와 지역 정보(local information)를 어떻게 결합하는지 보여줍니다.
그림 3에서 보여지듯이, 융합 아키텍처는 두 가지 입력을 받습니다: 는 전역 정보 이고, 는 병합된 지역 정보( )입니다. 두 입력은 각각 두 개의 CNN 네트워크로 전달되어 계수를 생성한 다음, 이 계수에 의해 와 가 더해집니다.[^3]
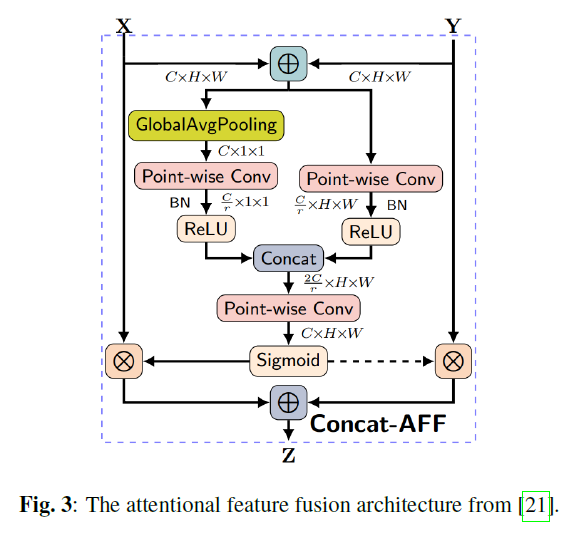
그림 3: [21]에서 가져온 주의 기반 특징 융합 아키텍처.
F. FREESOUND 데이터셋에서의 추가적인 특징 융합 실험(ADDITIONAL EXPERIMENT OF FEATURE FUSION ON FREESOUND DATASET)
논문의 4.2절에 대하여, 특징 융합의 효과를 더 평가하기 위해, AudioCaps와 Clotho 데이터셋 외에도, 우리는 Freesound 평가 세트에서 모델을 평가합니다. 이 세트는 10초 이상의 오디오 샘플을 포함하고 있으며(Clotho 데이터셋과 유사함).
결과는 표 7에 나타나 있으며, 표기법은 우리가 제출한 논문의 표 3과 동일합니다. Freesound 데이터셋에서의 성능은 Clotho 데이터셋에서의 성능과 유사한 추세를 보입니다:
- "AudioCaps + Clotho + LA."로 훈련된 성능은 "AudioCaps + Clotho + LA. + AudioSet"으로 훈련된 성능보다 더 좋습니다. 4.2절에서 설명한 것처럼, Clotho와 유사하게 Freesound 데이터셋은 AudioSet과 다른 오디오 샘플을 포함하고 있으며, AudioSet을 훈련에 추가하면 모델의 분포가 일반 오디오 데이터에서 AudioSet과 유사한 오디오 데이터로 이동하여 성능이 감소합니다.
- 특징 융합(feature fusion)을 사용한 성능이 그렇지 않은 경우보다 더 좋습니다. 왜냐하면 Freesound 데이터셋은 Clotho 데이터셋과 마찬가지로 10초 이상의 샘플을 포함하고 있기 때문입니다. 그들의 성능 추세는 유사합니다.
위의 실험을 통해, 우리는 특징 융합이 가변 길이의 오디오 샘플에서 텍스트-오디오 작업(text-to-audio task)의 성능(즉, 더 나은 오디오 표현을 생성)을 향상시킬 수 있다는 결론을 더욱 확신할 수 있습니다.

표 7: Freesound 평가 세트에서의 텍스트-오디오 검색 성능.
G. 키워드-캡션 증강의 예시
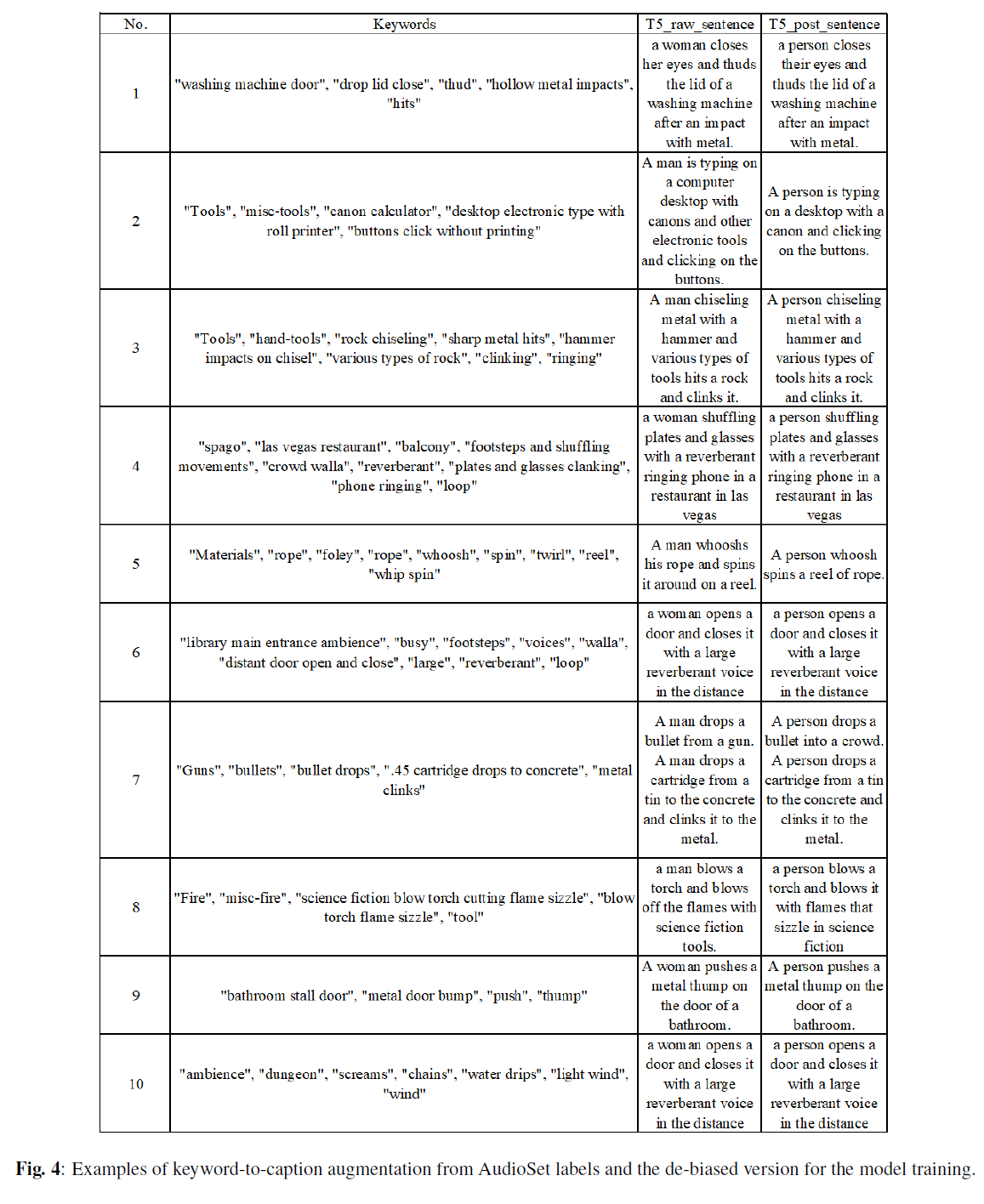
논문의 3.5절과 관련하여, 아래 표 4에서 AudioSet 레이블을 사용하여 T5 모델 로 생성된 키워드-캡션의 몇 가지 예시와 모델 훈련을 위한 편향 제거 버전을 보여줍니다.
또한, 키워드를 캡션에 적용할 때, 우리는 2초 미만의 샘플을 제외했습니다. 왜냐하면 그러한 경우 오디오는 단순히 단일 이벤트일 뿐이며, 생성된 캡션과 잘 매치되지 않기 때문입니다. AudioSet을 포함한 훈련 데이터셋에서 키워드를 캡션에 사용할 때, 우리는 키워드를 캡션으로 생성된 캡션만을 사용하고 템플릿으로 생성된 캡션은 제외합니다.[^4]
| 번호 | 키워드 | T5_raw_sentence | T5_post_sentence |
|---|---|---|---|
| 1 | "세탁기 문", "뚜껑 닫기", "쿵", "빈 금속 충격", "타격" | 여자가 눈을 감고 세탁기의 뚜껑을 금속과 충돌한 후 쿵하고 닫습니다. | 사람이 눈을 감고 세탁기의 뚜껑을 금속과 충돌한 후 쿵하고 닫습니다. |
| 2 | "도구", "misc-tools", "캐논 계산기", "롤 프린터가 있는 데스크탑 전자 타입", "버튼 클릭하지만 인쇄 안 함" | 남자가 컴퓨터 데스크탑에서 캐논과 다른 전자 도구들을 사용하여 버튼을 클릭하고 있습니다. | 사람이 데스크탑에서 캐논을 사용하여 버튼을 클릭하고 있습니다. |
| 3 | "도구", "손 도구", "바위 조각", "날카로운 금속 타격", "쇠집게에 망치 충격", "다양한 종류의 바위", "딸깍", "울림" | 남자가 망치와 다양한 종류의 도구로 금속을 조각하며 바위를 치고 딸깍거립니다. | 사람이 망치와 다양한 종류의 도구로 금속을 조각하며 바위를 치고 딸깍거립니다. |
| 4 | "스파고", "라스베가스 레스토랑", "발코니", "발걸음과 움직임", "군중 소리", "울림", "접시와 유리잔 부딪힘", "전화 울림", "루프" | 여자가 울리는 전화 소리와 함께 라스베가스의 레스토랑에서 접시와 유리잔을 옮기고 있습니다. | 사람이 울리는 전화 소리와 함께 라스베가스의 레스토랑에서 접시와 유리잔을 옮기고 있습니다. |
| 5 | "재료", "로프", "폴리", "로프", "휙", "회전", "돌리기", "릴", "채찍 회전" | 남자가 로프를 휙하고 릴 주위로 회전시킵니다. | 사람이 로프 릴을 휙 돌립니다. |
| 6 | "도서관 메인 입구 분위기", "바쁨", "발걸음", "목소리", "웅성거림", "멀리서 문 여닫는 소리", "큼직함", "울림", "루프" | 여자가 문을 열고 큰 울림을 가진 목소리로 멀리서 닫습니다. | 사람이 문을 열고 큰 울림을 가진 목소리로 멀리서 닫습니다. |
| 7 | "총", "총알", "총알 떨어짐", ".45 탄창이 콘크리트에 떨어짐", "금속 딸깍거림" | 남자가 총에서 총알을 떨어뜨립니다. 남자가 통에서 탄창을 콘크리트에 떨어뜨리고 금속에 딸깍 소리를 납니다. | 사람이 군중에 총알을 떨어뜨립니다. 사람이 통에서 탄창을 콘크리트에 떨어뜨리고 금속에 딸깍 소리를 납니다. |
| 8 | "불", "misc-fire", "과학 소설용 블로우 토치 절단 화염 지지직", "블로우 토치 화염 지지직", "도구" | 남자가 블로우 토치를 분사하고 과학 소설 도구로 화염을 끕니다. | 사람이 블로우 토치를 분사하고 과학 소설처럼 지지직 거리는 화염을 끕니다. |
| 9 | "화장실 칸막이 문", "금속 문 부딪힘", "밀기", "툭" | 여자가 화장실의 문에 금속 툭을 밀어냅니다. | 사람이 화장실의 문에 금속 툭을 밀어냅니다. |
| 10 | "분위기", "던전", "비명", "사슬", "물방울 떨어짐", "가벼운 바람", "바람" | 여자가 문을 열고 큰 울림을 가진 목소리로 멀리서 닫습니다. | 사람이 문을 열고 큰 울림을 가진 목소리로 멀리서 닫습니다. |
Fig. 4: 오디오셋(AudioSet) 레이블과 모델 훈련을 위한 편향 제거 버전에서 키워드-캡션 증강의 예시들입니다.
H. 데이터 제외에 대한 실험 설정
논문의 4.3절에 따르면, 우리는 모든 중복 샘플을 제외하고 남은 전체 데이터셋에 대해 제로샷(zero-shot) 평가를 수행했습니다. 아래 표 8은 그 세부사항을 보여줍니다.
| 데이터소스 A | 데이터소스 B | 데이터소스 A의 샘플 수 데이터소스 B에도 포함된 |
|---|---|---|
| ESC50-all | Clotho-train | 94 |
| ESC50-all | Clotho-valid | 27 |
| ESC50-all | Clotho-test | 34 |
| ESC50-all | FSD50K-train | 399 |
| ESC50-all | FSD50K-valid | 60 |
| ESC50-all | FSD50K-test | 171 |
| USD8K-all | Clotho-train | 411 |
| USD8K-all | Clotho-valid | 150 |
| USD8K-all | Clotho-test | 209 |
| USD8K-all | FSD50K-train | 697 |
| USD8K-all | FSD50K-valid | 180 |
| USD8K-all | FSD50K-test | 341 |
| Clotho-test | FSD50K-train | 54 |
| Clotho-test | FSD50K-valid | 15 |
| Clotho-test | FSD50K-test | 33 |
| FSD50K-test | Clotho-train | 137 |
| FSD50K-test | Clotho-valid | 31 |
| FSD50K-test | Clotho-test | 33 |
| Clotho-valid | FSD50K-train | 53 |
| Clotho-valid | FSD50K-valid | 10 |
| FSD50K-valid | Clotho-train | 38 |
| FSD50K-valid | Clotho-valid | 10 |
| Audiocaps-test | Audioset-unbalanced- train | 4875 |
| Audiocaps-test | Audioset-balanced- train | 0 |
| audioset-test | audiocaps-train | 0 |
| audioset-test | audiocaps-valid | 0 |
표 8: 훈련 데이터와 제로샷 평가 데이터 사이의 중복들입니다. 우리는 오디오 분류 메트릭스(audio classification metrics)를 계산하기 위해 평가 세트에서 이 모든 중복을 제외했습니다.
